
单元化架构的 CAP 分析
回顾 CAP
①CAP 的定义
CAP 原则是指任意一个分布式系统,同时最多只能满足其中的两项,而无法同时满足三项。
所谓的分布式系统,说白了就是一件事一个人做的,现在分给好几个人一起干。我们先简单回顾下 CAP 各个维度的含义:
Consistency(一致性),这个理解起来很简单,就是每时每刻每个节点上的同一份数据都是一致的。
这就要求任何更新都是原子的,即要么全部成功,要么全部失败。想象一下使用分布式事务来保证所有系统的原子性是多么低效的一个操作。
Availability(可用性),这个可用性看起来很容易理解,但真正说清楚的不多。我更愿意把可用性解释为:任意时刻系统都可以提供读写服务。
举个例子,当我们用事务将所有节点锁住来进行某种写操作时,如果某个节点发生不可用的情况,会让整个系统不可用。
对于分片式的 NoSQL 中间件集群(Redis,Memcached)来说,一旦一个分片歇菜了,整个系统的数据也就不完整了,读取宕机分片的数据就会没响应,也就是不可用了。
需要说明一点,哪些选择 CP 的分布式系统,并不是代表可用性就完全没有了,只是可用性没有保障了。
为了增加可用性保障,这类中间件往往都提供了”分片集群+复制集”的方案。
Partition tolerance(分区容忍性),这个可能也是很多文章都没说清楚的。P 并不是像 CA 一样是一个独立的性质,它依托于 CA 来进行讨论。
参考文献中的解释:”除非整个网络瘫痪,否则任何时刻系统都能正常工作”,言下之意是小范围的网络瘫痪,节点宕机,都不会影响整个系统的 CA。
我感觉这个解释听着还是有点懵逼,所以个人更愿意解释为当节点之间网络不通时(出现网络分区),可用性和一致性仍然能得到保障。
从个人角度理解,分区容忍性又分为“可用性分区容忍性”和“一致性分区容忍性”。
出现分区时会不会影响可用性的关键在于需不需要所有节点互相沟通协作来完成一次事务,不需要的话是铁定不影响可用性的。
庆幸的是应该不太会有分布式系统会被设计成完成一次事务需要所有节点联动,一定要举个例子的话,全同步复制技术下的 MySQL 是一个典型案例。
出现分区时会不会影响一致性的关键则在于出现脑裂时有没有保证一致性的方案,这对主从同步型数据库(MySQL、SQL Server)是致命的。
一旦网络出现分区,产生脑裂,系统会出现一份数据两个值的状态,谁都不觉得自己是错的。
需要说明的是,正常来说同一局域网内,网络分区的概率非常低,这也是为啥我们最熟悉的数据库(MySQL、SQL Server 等)也是不考虑 P 的原因。
下图为 CAP 之间的经典关系图:
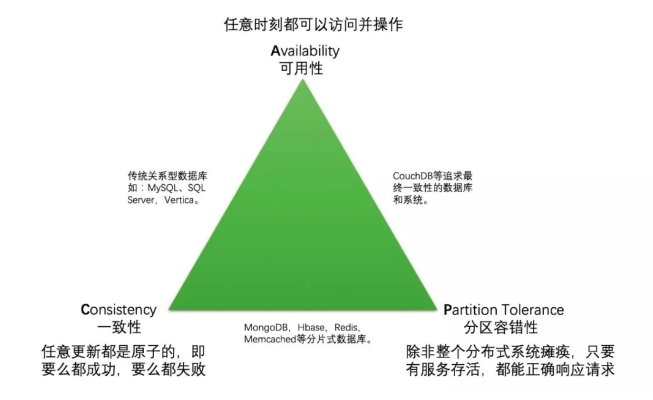
还有个需要说明的地方,其实分布式系统很难满足 CAP 的前提条件是这个系统一定是有读有写的,如果只考虑读,那么 CAP 很容易都满足。
比如一个计算器服务,接受表达式请求,返回计算结果,搞成水平扩展的分布式,显然这样的系统没有一致性问题,网络分区也不怕,可用性也是很稳的,所以可以满足 CAP。
②CAP 分析方法
先说下 CA 和 P 的关系,如果不考虑 P 的话,系统是可以轻松实现 CA 的。
而 P 并不是一个单独的性质,它代表的是目标分布式系统有没有对网络分区的情况做容错处理。
如果做了处理,就一定是带有 P 的,接下来再考虑分区情况下到底选择了 A 还是 C。所以分析 CAP,建议先确定有没有对分区情况做容错处理。
以下是个人总结的分析一个分布式系统 CAP 满足情况的一般方法:
if( 不存在分区的可能性 || 分区后不影响可用性或一致性 || 有影响但考虑了分区情况-P){
if(可用性分区容忍性-A under P))
return "AP";
else if(一致性分区容忍性-C under P)
return "CP";
}
else{ //分区有影响但没考虑分区情况下的容错
if(具备可用性-A && 具备一致性-C){
return AC;
}
}
这里说明下,如果考虑了分区容忍性,就不需要考虑不分区情况下的可用性和一致性了(大多是满足的)。
水平扩展应用+单数据库实例的 CAP 分析
让我们再来回顾下分布式应用系统的来由,早年每个应用都是单体的,跑在一个服务器上,服务器一挂,服务就不可用了。另外一方面,单体应用由于业务功能复杂,对机器的要求也逐渐变高,普通的微机无法满足这种性能和容量的要求。所以要拆!还在 IBM 大卖小型商用机的年代,阿里巴巴就提出要以分布式微机替代小型机。所以我们发现,分布式系统解决的最大的痛点,就是单体单机系统的可用性问题。要想高可用,必须分布式。一家互联网公司的发展之路上,第一次与分布式相遇应该都是在单体应用的水平扩展上。
也就是同一个应用启动了多个实例,连接着相同的数据库(为了简化问题,先不考虑数据库是否单点),如下图所示:
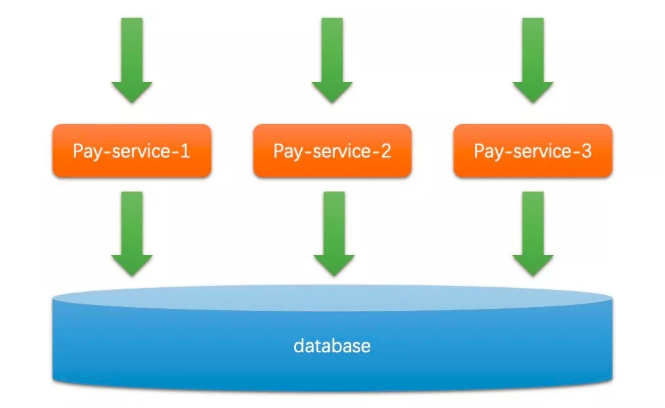
这样的系统天然具有的就是 AP(可用性和分区容忍性):
一方面解决了单点导致的低可用性问题。
另一方面无论这些水平扩展的机器间网络是否出现分区,这些服务器都可以各自提供服务,因为他们之间不需要进行沟通。
然而,这样的系统是没有一致性可言的,想象一下每个实例都可以往数据库 insert 和 update(注意这里还没讨论到事务),那还不乱了套。
于是我们转向了让 DB 去做这个事,这时候”数据库事务”就被用上了。用大部分公司会选择的 MySQL 来举例,用了事务之后会发现数据库又变成了单点和瓶颈。单点就像单机一样(本例子中不考虑从库模式),理论上就不叫分布式了,如果一定要分析其 CAP 的话,根据上面的步骤分析过程应该是这样的:
分区容忍性:先看有没有考虑分区容忍性,或者分区后是否会有影响。单台 MySQL 无法构成分区,要么整个系统挂了,要么就活着。
可用性分区容忍性:分区情况下,假设恰好是该节点挂了,系统也就不可用了,所以可用性分区容忍性不满足。
一致性分区容忍性:分区情况下,只要可用,单点单机的最大好处就是一致性可以得到保障。
因此这样的一个系统,个人认为只是满足了 CP。A 有但不出色,从这点可以看出,CAP 并不是非黑即白的。包括常说的 BASE (最终一致性)方案,其实只是 C 不出色,但最终也是达到一致性的,BASE 在一致性上选择了退让。
关于分布式应用+单点数据库的模式算不算纯正的分布式系统,这个可能每个人看法有点差异,上述只是我个人的一种理解,是不是分布式系统不重要,重要的是分析过程。
其实我们讨论分布式,就是希望系统的可用性是多个系统多活的,一个挂了另外的也能顶上,显然单机单点的系统不具备这样的高可用特性。
所以在我看来,广义的说 CAP 也适用于单点单机系统,单机系统是 CP 的。
说到这里,大家似乎也发现了,水平扩展的服务应用+数据库这样的系统的 CAP 魔咒主要发生在数据库层。
因为大部分这样的服务应用都只是承担了计算的任务(像计算器那样),本身不需要互相协作,所有写请求带来的数据的一致性问题下沉到了数据库层去解决。想象一下,如果没有数据库层,而是应用自己来保障数据一致性,那么这样的应用之间就涉及到状态的同步和交互了,ZooKeeper 就是这么一个典型的例子。
水平扩展应用+主从数据库集群的CAP分析
上一节我们讨论了多应用实例+单数据库实例的模式,这种模式是分布式系统也好,不是分布式系统也罢,整体是偏 CP 的。现实中,技术人员们也会很快发现这种架构的不合理性——可用性太低了。
于是如下图所示的模式成为了当下大部分中小公司所使用的架构:
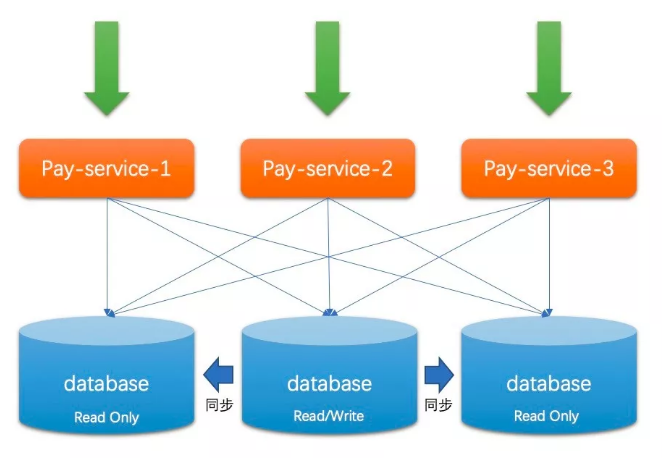
从上图我可以看到三个数据库实例中只有一个是主库,其他是从库。
一定程度上,这种架构极大的缓解了”读可用性”问题,而这样的架构一般会做读写分离来达到更高的”读可用性”,幸运的是大部分互联网场景中读都占了 80% 以上,所以这样的架构能得到较长时间的广泛应用。写可用性可以通过 Keepalived 这种 HA(高可用)框架来保证主库是活着的,但仔细一想就可以明白,这种方式并没有带来性能上的可用性提升。还好,至少系统不会因为某个实例挂了就都不可用了。
可用性勉强达标了,这时候的 CAP 分析如下:
分区容忍性:依旧先看分区容忍性,主从结构的数据库存在节点之间的通信,他们之间需要通过心跳来保证只有一个 Master。
然而一旦发生分区,每个分区会自己选取一个新的 Master,这样就出现了脑裂,常见的主从数据库(MySQL,Oracle 等)并没有自带解决脑裂的方案。所以分区容忍性是没考虑的。
一致性:不考虑分区,由于任意时刻只有一个主库,所以一致性是满足的。
可用性:不考虑分区,HA 机制的存在可以保证可用性,所以可用性显然也是满足的。
所以这样的一个系统,我们认为它是 AC 的。我们再深入研究下,如果发生脑裂产生数据不一致后有一种方式可以仲裁一致性问题,是不是就可以满足 P 了呢。还真有尝试通过预先设置规则来解决这种多主库带来的一致性问题的系统,比如 CouchDB,它通过版本管理来支持多库写入,在其仲裁阶段会通过 DBA 配置的仲裁规则(也就是合并规则,比如谁的时间戳最晚谁的生效)进行自动仲裁(自动合并),从而保障最终一致性(BASE),自动规则无法合并的情况则只能依赖人工决策了。
