java之collection总结
Collection
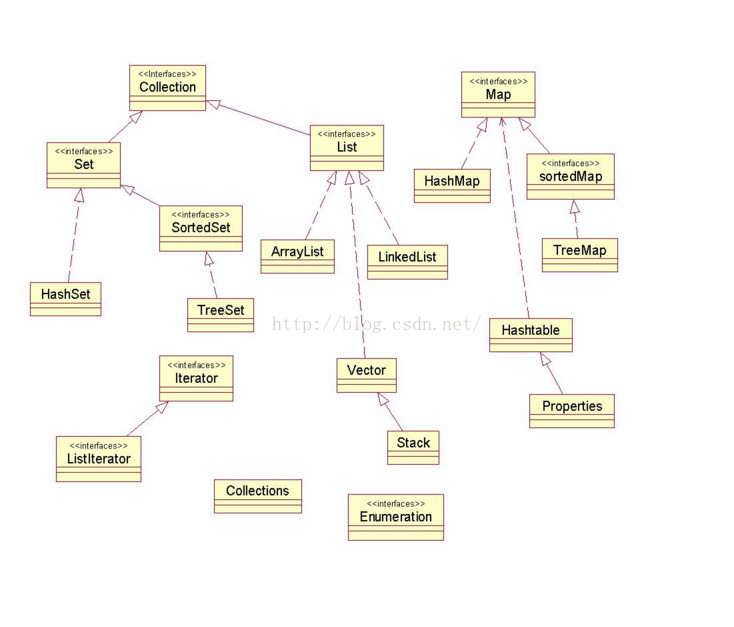
来源于Java.util包,是非常实用常用的数据结构!!!!!字面意思就是容器。具体的继承实现关系如下图,先整体有个印象,再依次介绍各个部分的方法,注意事项,以及应用场景。
--------------------------------------------------------------------------------------------
collection主要方法:
boolean add(Object o)添加对象到集合
boolean remove(Object o)删除指定的对象
int size()返回当前集合中元素的数量
boolean contains(Object o)查找集合中是否有指定的对象
boolean isEmpty()判断集合是否为空
Iterator iterator()返回一个迭代器
boolean containsAll(Collection c)查找集合中是否有集合c中的元素
boolean addAll(Collection c)将集合c中所有的元素添加给该集合
void clear()删除集合中所有元素
void removeAll(Collection c)从集合中删除c集合中也有的元素
void retainAll(Collection c)从集合中删除集合c中不包含的元素
--------------------------------------------------------------------------------------------
collection主要子接口对象:
├List(抽象接口,可重复有序)
list主要方法:
void add(int index,Object element)在指定位置上添加一个对象
boolean addAll(int index,Collection c)将集合c的元素添加到指定的位置
Object get(int index)返回List中指定位置的元素
int indexOf(Object o)返回第一个出现元素o的位置.
Object remove(int index)删除指定位置的元素
Object set(int index,Object element)用元素element取代位置index上的元素,返回被取代的元素
void sort()
--------------------------------------------------------------------------------------------
1.List主要子接口对象
│├LinkedList没有同步方法
│├ArrayList非同步的(unsynchronized)
│└Vector(同步) 非常类似ArrayList,但是Vector是同步的
└Stack 记住 push和pop方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。注意:Stack刚创建后是空栈。
--------------------------------------------------------------------------------------------
2.└Set不包含重复的元素
HashSet
SortSet
TreeSet
另外:-Queue(继承collection)---Deque
--------------------------------------------------------------------------------------------
3.Map
Map没有继承Collection接口,Map提供key到value的映射。
方法:
boolean equals(Object o)比较对象
boolean remove(Object o)删除一个对象
put(Object key,Object value)添加key和value
├Hashtable 任何非空(non-null)的对象。同步的
├HashMap 可空的对象。不同步的 ,但是效率高,较常用。 注:迭代子操作时间开销和HashMap的容量成比例。因此,如果迭代操作的性能相当重要的话,不要将HashMap的初始化容量设得过高,或者load factor过低。
└WeakHashMap 改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。
SortMap---TreeMap
4.总结:
a.如果涉及到堆栈,队列(先进后出)等操作,应该考虑用List,对于需要快速插入,删除元素,应该使用LinkedList,如果需要快速随机访问元素,应该使用ArrayList。
b.如果程序在单线程环境中,或者访问仅仅在一个线程中进行,考虑非同步的类,其效率较高,如果多个线程可能同时操作一个类,应该使用同步的类。
c.要特别注意对哈希表的操作,作为key的对象要正确复写equals和hashCode方法。
d.尽量返回接口而非实际的类型,如返回List而非ArrayList,这样如果以后需要将ArrayList换成LinkedList时,客户端代码不用改变。这就是针对抽象编程。
e.ArrayList、HashSet/LinkedHashSet、PriorityQueue、LinkedList是线程不安全的,
可以使用synchronized关键字,或者类似下面的方法解决:
- List list = Collections.synchronizedList(new ArrayList(...));
5.几个面试常见问题:
1.Q:ArrayList和Vector有什么区别?HashMap和HashTable有什么区别?
A:Vector和HashTable是线程同步的(synchronized)。性能上,ArrayList和HashMap分别比Vector和Hashtable要好。
2.Q:大致讲解java集合的体系结构
A:List、Set、Map是这个集合体系中最主要的三个接口。
其中List和Set继承自Collection接口。
Set不允许元素重复。HashSet和TreeSet是两个主要的实现类。
List有序且允许元素重复。ArrayList、LinkedList和Vector是三个主要的实现类。
Map也属于集合系统,但和Collection接口不同。Map是key对value的映射集合,其中key列就是一个集合。key不能重复,但是value可以重复。HashMap、TreeMap和Hashtable是三个主要的实现类。
SortedSet和SortedMap接口对元素按指定规则排序,SortedMap是对key列进行排序。
3.Q:Comparable和Comparator区别
A:调用java.util.Collections.sort(List list)方法来进行排序的时候,List内的Object都必须实现了Comparable接口。
java.util.Collections.sort(List list,Comparator c),可以临时声明一个Comparator 来实现排序。
- Collections.sort(imageList, new Comparator() {
- public int compare(Object a, Object b) {
- int orderA = Integer.parseInt( ( (Image) a).getSequence());
- int orderB = Integer.parseInt( ( (Image) b).getSequence());
- return orderA - orderB;
- }
- });
如果需要改变排列顺序
改成return orderb - orderA 即可。
6.其他注意点
List接口对Collection进行了简单的扩充,它的具体实现类常用的有ArrayList和LinkedList。你可以将任何东西放到一个List容器中,并在需要时从中取出。ArrayList从其命名中可以看出它是一种类似数组的形式进行存储,因此它的随机访问速度极快,而LinkedList的内部实现是链表,它适合于在链表中间需要频繁进行插入和删除操作。在具体应用时可以根据需要自由选择。前面说的Iterator只能对容器进行向前遍历,而ListIterator则继承了Iterator的思想,并提供了对List进行双向遍历的方法。
Set接口也是Collection的一种扩展,而与List不同的时,在Set中的对象元素不能重复,也就是说你不能把同样的东西两次放入同一个Set容器中。它的常用具体实现有HashSet和TreeSet类。HashSet能快速定位一个元素,但是你放到HashSet中的对象需要实现hashCode()方法,它使用了前面说过的哈希码的算法。而TreeSet则将放入其中的元素按序存放,这就要求你放入其中的对象是可排序的,这就用到了集合框架提供的另外两个实用类Comparable和Comparator。一个类是可排序的,它就应该实现Comparable接口。有时多个类具有相同的排序算法,那就不需要在每分别重复定义相同的排序算法,只要实现Comparator接口即可。集合框架中还有两个很实用的公用类:Collections和Arrays。Collections提供了对一个Collection容器进行诸如排序、复制、查找和填充等一些非常有用的方法,Arrays则是对一个数组进行类似的操作。
Map是一种把键对象和值对象进行关联的容器,而一个值对象又可以是一个Map,依次类推,这样就可形成一个多级映射。对于键对象来说,像Set一样,一个Map容器中的键对象不允许重复,这是为了保持查找结果的一致性;如果有两个键对象一样,那你想得到那个键对象所对应的值对象时就有问题了,可能你得到的并不是你想的那个值对象,结果会造成混乱,所以键的唯一性很重要,也是符合集合的性质的。当然在使用过程中,某个键所对应的值对象可能会发生变化,这时会按照最后一次修改的值对象与键对应。对于值对象则没有唯一性的要求。你可以将任意多个键都映射到一个值对象上,这不会发生任何问题(不过对你的使用却可能会造成不便,你不知道你得到的到底是那一个键所对应的值对象)。Map有两种比较常用的实现:HashMap和TreeMap。HashMap也用到了哈希码的算法,以便快速查找一个键,TreeMap则是对键按序存放,因此它便有一些扩展的方法,比如firstKey(),lastKey()等,你还可以从TreeMap中指定一个范围以取得其子Map。键和值的关联很简单,用pub(Object key,Object value)方法即可将一个键与一个值对象相关联。用get(Object key)可得到与此key对象所对应的值对象。
遍历Map的方式:
a.//最常规的一种遍历方法,最常规就是最常用的,虽然不复杂,但很重要,这是我们最熟悉的,就不多说了!!
- public static void work(Map<String, Student> map) {
- Collection<Student> c = map.values();
- Iterator it = c.iterator();
- for (; it.hasNext();) {
- System.out.println(it.next());
- }
- }
b.// 利用keyset进行遍历,它的优点在于可以根据你所想要的key值得到你想要的 values,更具灵活性!!
- public static void workByKeySet(Map<String, Student> map) {
- Set<String> key = map.keySet();
- for (Iterator it = key.iterator(); it.hasNext();) {
- String s = (String) it.next();
- System.out.println(map.get(s));
- }
- }
c.// 比较复杂的一种遍历在这里,暴力!!,它的灵活性太强了,想得到什么就能得到什么~~
- public static void workByEntry(Map<String, Student> map) {
- Set<Map.Entry<String, Student>> set = map.entrySet();
- for (Iterator<Map.Entry<String, Student>> it = set.iterator(); it
- .hasNext();) {
- Map.Entry<String, Student> entry = (Map.Entry<String, Student>) it
- .next();
- System.out.println(entry.getKey() + "—>" + entry.getValue());
- }
- }
d.//Map.Entry的另外一种简练写法(foreach遍历方式)
- public static void workByEntry(Map<String, Student> map) {
- Set<Map.Entry<String, Student>> set = map.entrySet();
- for (Map.Entry<String, Student> me : set) {
- System.out.println(me.getKey() + "—>" + me.getValue());
- }
- }
7.Queue
Queue和List有两个区别:
前者有“队头”的概念,取元素、移除元素、均为对“队头”的操作(通常但不总是FIFO,即先进先出),
而后者只有在插入时需要保证在尾部进行;前者对元素的一些同一种操作提供了两种方法,在特定情况下抛异常/返回特殊值——add()/offer()、remove()/poll()、element()/peek()。不难想到,在所谓的两种方法中,抛异常的方法完全可以通过包装不抛异常的方法来实现,这也是AbstractQueue所做的。
Deque接口继承了Queue,但是和AbstractQueue没有关系。Deque同时提供了在队头和队尾进行插入和删除的操作。
PriorityQueue
PriorityQueue用于存放含有优先级的元素,插入的对象必须可以比较。该类内部同样封装了一个数组。与其抽象父类AbstractQueue不同,PriorityQueue的offer()方法在插入null时会抛空指针异常——null是无法与其他元素比较通常意义下的优先级的;此外,add()方法是直接包装了offer(),没有附加的行为。
由于其内部的数据结构是数组的缘故,很多操作都需要先把元素通过indexOf()转化成对应的数组下标,再进行进一步的操作,如remove()、removeEq()、contains()等。其实这个数组保持优先级队列的方式,是采用堆(Heap)的方式,具体可以参考任意一本算法书籍,比如《算法导论》等,这里就不展开解释了。和堆的特性有关,在寻找指定元素时,必须从头至尾遍历,而不能使用二分查找。
LinkedList
LinkedList既是List,也是Queue(Deque),其原因是它是双向的,内部的元素(Entry)同时保留了上一个和下一个元素的引用。使用头部的引用header,取其previous,就可以获得尾部的引用。通过这一转换,可以很容易实现Deque所需要的行为。也正因此,可以支持栈的行为,天生就有push()和pop()方法。简而言之,是Java中的双向链表,其支持的操作和普通的双向链表一样。
和数组不同,根据下标查找特定元素时,只能遍历地获取了,因而在随机访问时效率不如ArrayList。尽管如此,作者还是尽可能地利用了LinkedList的特性做了点优化,尽量减少了访问次数:
- private Entry<E> entry(int index) {
- if (index < 0 || index >= size)
- throw new IndexOutOfBoundsException("Index: "+index+
- ", Size: "+size);
- Entry<E> e = header;
- if (index < (size >> 1)) {
- for (int i = 0; i <= index; i++)
- e = e.next;
- } else {
- for (int i = size; i > index; i--)
- e = e.previous;
- }
- return e;
- }
LinkedList对首部和尾部的插入都支持,但继承自Collection接口的add()方法是在尾部进行插入。
欢迎关注微信公众号“Java面试达人”,(id:javasuperman),收看更多精彩内容


 浙公网安备 33010602011771号
浙公网安备 33010602011771号