第18月第28天 百度开放研究社区-电影推荐系统
1.
百度开放研究社区-电影推荐系统算法创新大赛
关于竞赛
TASKS参赛对象:
本次大赛主要面向国内高等院校的高年级本科生和硕士,博士研究生,以及相关的从业人员,旨在通过竞赛激发更高的技术和应用创新能力,着力使百度为用户提供更好的搜索体验增添力量。
参赛选手在给定的数据集上针对赛题研究相应实现方法,编写程序运行实现,大奖赛评委会根据参赛选手程序运行所获得结果,按照预先制定的评比标准对参赛选手的作品进行评比。
任务描述:
本次创新大赛的任务是基于喜好和好友的电影推荐引擎,根据提供的包括关于用户的观看和评分记录数据,以及用户的社交关系数据,利用这些数据实现一个完整的个性化推荐算法,帮助用户发现可能喜欢的电影。
本次大赛数据集包含了14,000部电影对应的标签信息, 用户观看评分记录(User_id, Movie_id, Ratings)以及14,0000用户的社交关系,引入的社交元素,主要是微博好友关系,以及名人推荐;这些数据在保护用户隐私前提下,大部分都是明文,方便参赛者理解,更好的提升算法效果。Rating打分的范围是0-5分。分数越高,视为用户越喜欢这个电影。选手利用给定的数据来预测用户对电影的打分情况,帮助用户发现可能会喜欢的电影。
评价机制:
本次大赛评判标准我们采用参赛者的推荐预测评分值与实际评分值之间的均方根误差RMSE(Root Mean Squared Error),结果取四舍五入小数点后4位,精确到0.0001。
例如,参赛者的算法预测用户对某电影的预测评分是Y,而用户对此电影的实际评分是X,那么所得的RMSE=sqrt(sum(for all items(X-Y)^2)/n)
除此之外,参赛者根据参赛的过程,给出以下问题A和B的理解和解释,我们将作为评判的参考:
A) 协同滤波和基于内容的推荐算法的效果哪个更好?
B) 如何利用社交信息做提高推荐效果?
代码算法:
本次大赛允许选手使用任何算法,语言进行编写。
注册报名:
1. 参赛者必须于4月15日之前在百度开放研究社区上统一报名注册,注册时必须提供参赛者的基本介绍及联系方式,以供审核和后期大赛组委会联系;注册完毕后,进入“电影系统算法创新大赛”活动主页,点击右上角"我要参加活动";
2. 参赛者提交的参赛作品必须是有独立完成的原创作品,不得抄袭,不得违反任何相关法律法规;
重要时间:
(1) 报名时间:2013年3月1至4月15日;
(2) 比赛时间:2013年3月1日至5月3日;
(3) 结果公布:2013年5月4日。
数据描述
DATA数据描述
本次大赛数据集总容量是257MB,包含六个txt文件,文件名分别是:raining_set、movie_tag、user_social、distinct_movieId、distinct_userId、predict。
training_set.txt用户评分数据共四列,从左到右依次为userId、movieId、rating、createTime。即用户id、电影id、该用户对该电影的评分、创建时间。列之间以’\t’分隔,行之间以’\r\n’分隔。
movie_tag.txt电影的标签数据,共两列,从左到右依次是movieId,tags。即电影id,该电影对应的标签。列之间以’\t’分隔,行之间以’\r\n’分隔。标签之间以逗号分隔。根据电影的冷热门程度,好坏程度是有差别的,所以电影的标签数也是有差别的,有的电影有很多标签,有的电影甚至一个标签都没有。
user_social.txt用户的社交关系数据。共两列,从左到右依次是userId,follows。即用户id,用户关注的好友。列之间以’\t’分隔,行之间以’\r\n’分隔。关注的好友之间以逗号分隔。这里的好友关系,是单向关注的。
distinct_movieId.txt:电影id集合,行之间以’\r\n’分隔。为了方便参赛者,总结处理了所有涉及到的电影id集合。
distinct_userId.txt:用户id集合,行之间以’\r\n’分隔。为了方便参赛者,总结处理了所有涉及到的用户id集合。
predict.txt预测集合。共两列,从左到右依次是userId,movieId。即用户id,电影id.列之间以’\t’分隔,行之间以’\r\n’分隔。参赛者需要预测出第三列,即该用户对该电影的评分,作为第三列,并提交给评测平台。需要注意的是,参赛者最终提的predict.txt是三列,列之间以’\t’分隔,行之间以’\r\n’分隔。行之间的顺序不能乱,行的总数不能少。
数据文件位置:
本次大赛选手可以在大赛组委会提供的”百度开放研究云平台“上部署运行,选手也可在本机上运行。
1.数据存储于百度开放研究云平台的分布式文件系统中(HDFS),使用hadoop fs -ls /share/data/mr可以查看;
2.选手也可将数据下载到本机上做运算,数据下载地址。
测评方式:
1.在”百度开放研究云平台“上做计算的选手,请自行将输出的预测结果(predict_data.txt,包含userId,movieId,rating)放到自己的 工作目录下,然后调用evaluate -mr predict_data.txt,计算出算法的均方根误差(RSME);
2.在本机上做计算的选手,将得到的预测结果通过百度开放云平台的upload命令上载到个人的工作目录下,然后调用evaluate-mr predict_data.txt, 计算出算法的均方根误差(RSME)。
均方根误差最小的前十名参赛者的参赛结果反映在实时排行榜上。
作品提交
提交作品的规范性说明作品提交说明:
作品提交时,请务必包含以下内容,否则可能直接影响选手的作品成绩。(每份作品请以RAR或ZIP方式压缩打包后提交):
1) txt格式的预测数据和作品源代码。参赛者必须提交源代码,组委会承诺源代码只限于本次大赛评奖使用,作品知识产权归参赛团队所有。
2) 程序运行的详细说明文档;以便命题与评奖委员会专家对作品做进一步审查。
3) 自述文件(readme.txt),内容包括参赛者的信息(作品名称、参赛者姓名、联系方式等),以及需要对软件安装及运行做的特殊说明。
4) 程序设计概述文档,重点介绍算法设计思想、特色等,不超过 1 页。
要求:
1) 作品压缩包请以作者名字全拼的形式命名。
2) 上传作品及相关文件压缩后大小限100M以内(压缩文件格式为.zip或.rar)。
3) 在截止日期前,允许重复提交,后次提交会覆盖前次提交内容,请选手注意作品提交截止日期 。
☆ 注意:作品提交时间为开始于【2013-03-01 10:00:00】截止于【2013-04-15 14:49:12】。
竞赛评奖
本届大奖赛奖项设置及奖励办法如下:
在大赛预定的截止日期5月3日24:00时取出排行榜前十名的参赛选手,排行榜上1~4名的选手分别设立为一、二、三等奖,5~10名的选手分别设立突出奖、优胜奖和创意奖,具体设奖数量和奖励办法如下:
• 一等奖:1名,奖励现金1万元及获奖证书;
• 二等奖:1名,奖励现金5000元及获奖证书;
• 三等奖:2名,奖励现金2000元及获奖证书;
• 突出奖:2名,罗西尼手表一块以及获奖证书;
• 优胜奖:2名,派克笔一支以及获奖证书;
• 创意奖:2名,触控调光水LED音箱灯以及获奖证书;
https://blog.csdn.net/shaoqiangfan/article/details/8670046
https://www.cnblogs.com/sylvanas2012/archive/2013/05/07/3064025.html
3.
1.协同过滤
推荐系统发展至今已有相当长的历史,形成了一个庞大的算法和研发体系。推荐系统领域最早的算法是协同过滤,现在基本不被各大互联网公司作为线上系统使用,仅作为算法迭代的初始比较标准。
协同过滤包括基于用户的协同过滤(user-based collaborative filtering)和基于物品的协同过滤(item-based collaborative filtering)两种。
- 基于用户的协同过滤:算法思想是计算用户和用户之间的相似性,然后将与某个用户最相近的物品通过用户相似性加权计算,得分排序后推荐给用户。
- 基于物品的协同过滤:算法思想与此类似,只是首先计算物品和物品的相似性,然后再通过加权排序的方式计算用户的评分,并将得分高的物品推荐给用户。
为了提高推荐系统的效率,在推荐系统发展早年,亚马逊设计了 Slope-One 算法来进行商品推荐。
2.矩阵分解模型
如果说协同过滤是推荐系统发展的第一阶段,那么矩阵分解模型就是推荐系统发展的第二阶段。研究者和工程师们开始利用 SVD 分解,LDA 和 ALS 等其他的矩阵分解模型将用户对物品的评分矩阵分解为用户-隐变量矩阵和物品-隐变量矩阵,然后通过计算向量乘积完成用户评分矩阵的填充。
因为矩阵分解模型需要计算完整的用户-物品评分矩阵,所以时间复杂度比较高。Google 在 2010 年发表了论文介绍了 Google News 的新闻推荐系统,结合了协同过滤,矩阵分解以及统计兴趣趋势的方法。在这一阶段,出现了专门针对非评分矩阵的隐反馈的算法,其中比较著名的有 SVD++ 和 one-class collaborative filtering。
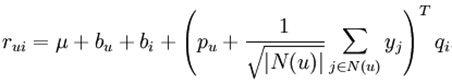
图2. SVD++ 评分计算公式
3.基于逻辑回归的点击率预估
4.排序学习
5.深度学习
http://developer.51cto.com/art/201710/555348.htm
6.advice for applying machine learning

 浙公网安备 33010602011771号
浙公网安备 33010602011771号