

flink开发环境执行sql及生产环境提交sql文件
flink提供了sql-client.sh工具可直接操作sql,该工具一般在开发环境用于调试,在生产环境还是要打成jar文件。为了避免在java文件中写大量sql,我们可以将sql提取出来放到一个后缀是.sql的文件中,自己编辑java代码读取该sql文件。然后将java代码与sql文件一块打成jar,部署到flink环境中。
一、安装flink及部署jar,参考下面两篇文章
二、开发环境使用sql-client.sh
1、启动flink
start-cluster.sh
2、启动sqlclient
sql-client.sh
3、测试sqlclient
1)启动kafka,并创建生产者与消费者
kafka-console-producer.sh --broker-list 192.168.23.190:9092 --topic topic_source
kafka-console-consumer.sh --bootstrap-server 192.168.23.190:9092 --topic topic_sink
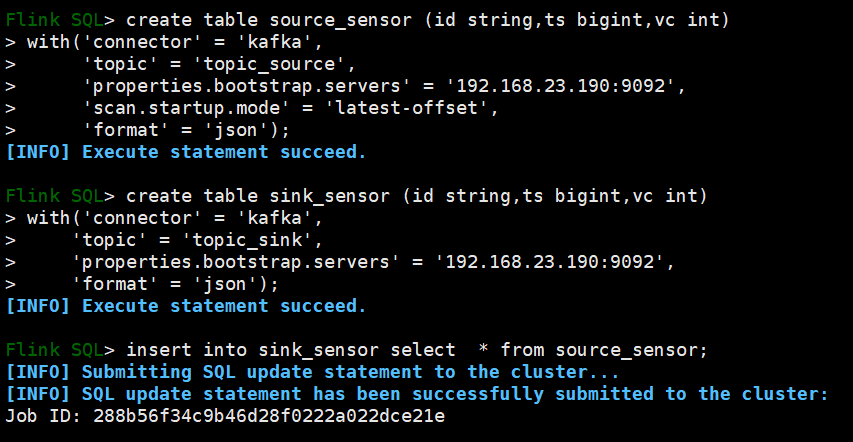
2)在sqlclient中创建表source_sensor,获取topic_source的数据
create table source_sensor (id string,ts bigint,vc int) with('connector' = 'kafka', 'topic' = 'topic_source', 'properties.bootstrap.servers' = '192.168.23.190:9092', 'scan.startup.mode' = 'latest-offset', 'format' = 'json');
3)在sqlclient中创建表sink_sensor,将数据传送给topic_sink
create table sink_sensor (id string,ts bigint,vc int) with('connector' = 'kafka', 'topic' = 'topic_sink', 'properties.bootstrap.servers' = '192.168.23.190:9092', 'format' = 'json');
4)将source_sensor的数据存储到sink_sensor
insert into sink_sensor select * from source_sensor;
5)kafka生产端输入消息,消费端可以获取到消息
{"id":"23","ts":23,"vc":29}
{"id":"23","ts":23,"vc":29}
{"id":"231","ts":23,"vc":23}
{"id":"23","ts":23,"vc":29}


四、生产环境将sql打成jar提交
1、java本地执行sql示例
1)java代码,在idea中运行

public class Main { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tabEnv = StreamTableEnvironment.create(env); tabEnv.executeSql("create table source_sensor (id string,ts bigint,vc int)\n" + "with('connector' = 'kafka',\n" + " 'topic' = 'topic_source',\n" + " 'properties.bootstrap.servers' = '192.168.23.190:9092',\n" + " 'scan.startup.mode' = 'latest-offset',\n" + " 'format' = 'json')"); tabEnv.executeSql("create table sink_sensor (id string,ts bigint,vc int)\n" + "with('connector' = 'kafka',\n" + " 'topic' = 'topic_sink',\n" + " 'properties.bootstrap.servers' = '192.168.23.190:9092',\n" + " 'format' = 'json')"); tabEnv.executeSql("insert into sink_sensor select * from source_sensor"); } }
2)同样开启kafka生产端、消费端进行测试


2、生产环境提交sql文件
1)编写java通用代码,读取.sql文件
public class Main2 { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tabEnv = StreamTableEnvironment.create(env); String path = "D:\\workset\\javaset\\tablesql\\test\\test.sql"; List<String> list = FileUtils.readLines(new File(path),"UTF-8"); StringBuilder stringBuilder = new StringBuilder(""); String sql = ""; for(String var : list){ if(StringUtils.isNotBlank(var)){ stringBuilder.append(var); if(var.contains(";")){ sql = stringBuilder.toString().replace(";",""); System.out.println(sql); tabEnv.executeSql(sql); stringBuilder = new StringBuilder(""); }else{ stringBuilder.append("\n"); } } } } }
注意:部署时修改test.sql的路径为:/usr/local/myroom/a_project/test.sql
2)编写test.sql文件
create table source_sensor (id string,ts bigint,vc int) with('connector' = 'kafka', 'topic' = 'topic_source', 'properties.bootstrap.servers' = '192.168.23.190:9092', 'scan.startup.mode' = 'latest-offset', 'format' = 'json'); create table sink_sensor (id string,ts bigint,vc int) with('connector' = 'kafka', 'topic' = 'topic_sink', 'properties.bootstrap.servers' = '192.168.23.190:9092', 'format' = 'json'); insert into sink_sensor select * from source_sensor;
将test.sql上传到路径/usr/local/myroom/a_project/
3)将1)中的通用类打成jar,并提交
<build>
<finalName>testSql</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<includes>
<include>com/leiyuke/flink/tablesql/test/Main2.class</include>
</includes>
</configuration>
</plugin>
</plugins>
</build>

4)测试如下:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)