线程池的拒绝策略及常见线程池
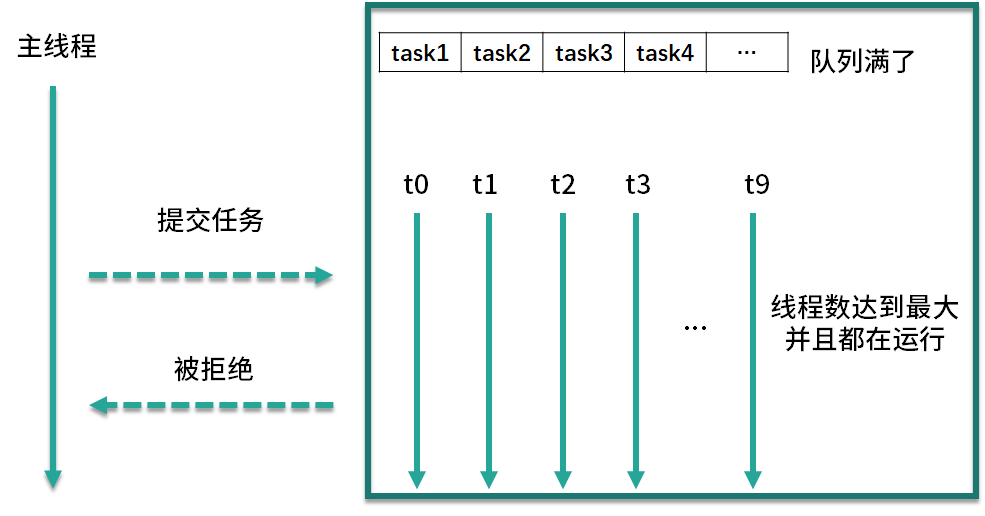
线程池拒绝提交任务的2种情况
- 调用 shutdown 等方法关闭线程池后,即便此时可能线程池内部依然有没执行完的任务正在执行,但是由于线程池已经关闭,此时如果再向线程池内提交任务,就会遭到拒绝
- 线程池没有能力继续处理新提交的任务,也就是工作已经非常饱和的时候
![]()
java 在 ThreadPoolExecutor 类中为我们提供了 4 种默认的拒绝策略来应对不同的场景,都实现了 RejectedExecutionHandler 接口,如图所示:
![]()

4种拒绝策略
- 第一种拒绝策略是 AbortPolicy,这种拒绝策略在拒绝任务时,会直接抛出一个类型为 RejectedExecutionException 的 RuntimeException,让你感知到任务被拒绝了,于是你便可以根据业务逻辑选择重试或者放弃提交等策略。
- 第二种拒绝策略是 DiscardPolicy,这种拒绝策略正如它的名字所描述的一样,当新任务被提交后直接被丢弃掉,也不会给你任何的通知,相对而言存在一定的风险,因为我们提交的时候根本不知道这个任务会被丢弃,可能造成数据丢失。
- 第三种拒绝策略是 DiscardOldestPolicy,如果线程池没被关闭且没有能力执行,则会丢弃任务队列中的头结点,通常是存活时间最长的任务,这种策略与第二种不同之处在于它丢弃的不是最新提交的,而是队列中存活时间最长的,这样就可以腾出空间给新提交的任务,但同理它也存在一定的数据丢失风险。
- 第四种拒绝策略是 CallerRunsPolicy,相对而言它就比较完善了,当有新任务提交后,如果线程池没被关闭且没有能力执行,则把这个任务交于提交任务的线程执行,也就是谁提交任务,谁就负责执行任务。这样做主要有两点好处。
- 第一点新提交的任务不会被丢弃,这样也就不会造成业务损失。
- 第二点好处是,由于谁提交任务谁就要负责执行任务,这样提交任务的线程就得负责执行任务,而执行任务又是比较耗时的,在这段期间,提交任务的线程被占用,也就不会再提交新的任务,减缓了任务提交的速度,相当于是一个负反馈。在此期间,线程池中的线程也可以充分利用这段时间来执行掉一部分任务,腾出一定的空间,相当于是给了线程池一定的缓冲期。
常用线程池及使用队列
| 线程池 | 队列 | 创建方式 | 适用场景 |
|---|---|---|---|
| FixedThreadPool | LinkedBlockingQueue | ThreadPoolExecutor | |
| SingleThreadExecutor | LinkedBlockingQueue | ThreadPoolExecutor | |
| CachedThreadPool | SynchronousQueue | ThreadPoolExecutor | |
| ScheduledThreadPoolExecutor | DelayedWorkQueue | ScheduledThreadPoolExecutor | |
| SingleThreadScheduledExecutor | DelayedWorkQueue | ScheduledThreadPoolExecutor | |
| ForkJoinPool |
FixedThreadPool
它的核心线程数和最大线程数是一样的,所以可以把它看作是固定线程数的线程池,它的特点是线程池中的线程数除了初始阶段需要从 0 开始增加外,之后的线程数量就是固定的,就算任务数超过线程数,线程池也不会再创建更多的线程来处理任务,而是会把超出线程处理能力的任务放到任务队列中进行等待。而且就算任务队列满了,到了本该继续增加线程数的时候,由于它的最大线程数和核心线程数是一样的,所以也无法再增加新的线程了。
CachedThreadPool
可以称作可缓存线程池,它的特点在于线程数是几乎可以无限增加的(实际最大可以达到 Integer.MAX_VALUE,为 2^31-1,这个数非常大,所以基本不可能达到),而当线程闲置时还可以对线程进行回收。也就是说该线程池的线程数量不是固定不变的,当然它也有一个用于存储提交任务的队列,但这个队列是 SynchronousQueue,队列的容量为0,实际不存储任何任务,它只负责对任务进行中转和传递,所以效率比较高。
ScheduledThreadPool
支持定时或周期性执行任务。比如每隔 10 秒钟执行一次任务,而实现这种功能的方法主要有 3 种,如代码所示:
ScheduledExecutorService service = Executors.newScheduledThreadPool(10);
service.schedule(new Task(), 10, TimeUnit.SECONDS);
service.scheduleAtFixedRate(new Task(), 10, 10, TimeUnit.SECONDS);
service.scheduleWithFixedDelay(new Task(), 10, 10, TimeUnit.SECONDS);
3种方法的区别
- 第一种方法 schedule 比较简单,表示延迟指定时间后执行一次任务,如果代码中设置参数为 10 秒,也就是 10 秒后执行一次任务后就结束。
- 第二种方法 scheduleAtFixedRate 表示以固定的频率执行任务,它的第二个参数 initialDelay 表示第一次延时时间,第三个参数 period 表示周期,也就是第一次延时后每次延时多长时间执行一次任务。
- 第三种方法 scheduleWithFixedDelay 与第二种方法类似,也是周期执行任务,区别在于对周期的定义,之前的 scheduleAtFixedRate 是以任务开始的时间为时间起点开始计时,时间到就开始执行第二次任务,而不管任务需要花多久执行;而 scheduleWithFixedDelay 方法以任务结束的时间为下一次循环的时间起点开始计时。
SingleThreadExecutor
使用唯一的线程去执行任务,原理和 FixedThreadPool 是一样的,只不过这里线程只有一个,如果线程在执行任务的过程中发生异常,线程池也会重新创建一个线程来执行后续的任务。这种线程池由于只有一个线程,所以非常适合用于所有任务都需要按被提交的顺序依次执行的场景,而前几种线程池不一定能够保障任务的执行顺序等于被提交的顺序,因为它们是多线程并行执行的。
SingleThreadScheduledExecutor
它实际和第三种 ScheduledThreadPool 线程池非常相似,它只是 ScheduledThreadPool 的一个特例,内部只有一个线程
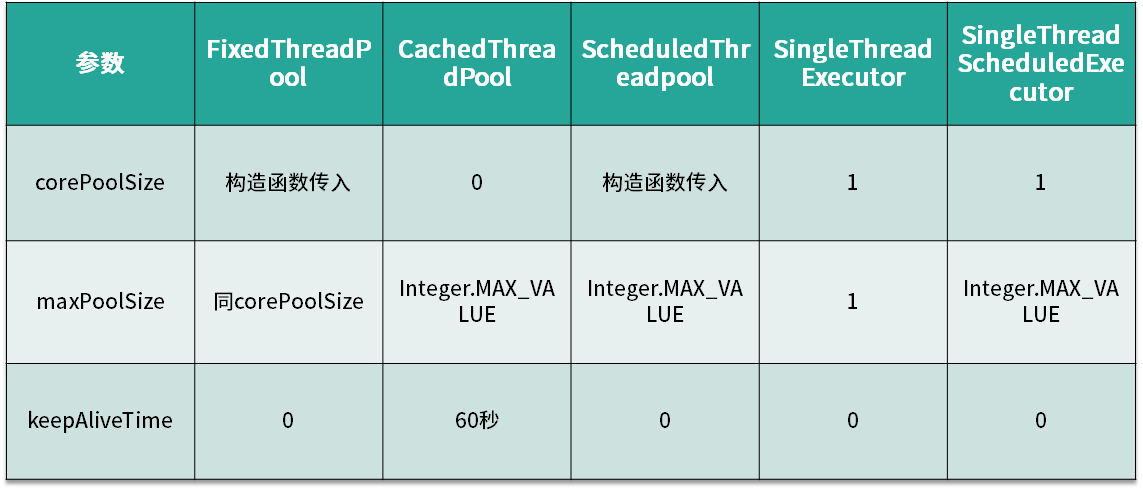
总结上述的五种线程池,我们以核心线程数、最大线程数,以及线程存活时间三个维度进行对比,如表格所示。
第一个线程池 FixedThreadPool,它的核心线程数和最大线程数都是由构造函数直接传参的,而且它们的值是相等的,所以最大线程数不会超过核心线程数,也就不需要考虑线程回收的问题,如果没有任务可执行,线程仍会在线程池中存活并等待任务。
第二个线程池 CachedThreadPool 的核心线程数是 0,而它的最大线程数是 Integer 的最大值,线程数一般是达不到这么多的,所以如果任务特别多且耗时的话,CachedThreadPool 就会创建非常多的线程来应对。
ForkJoinPool
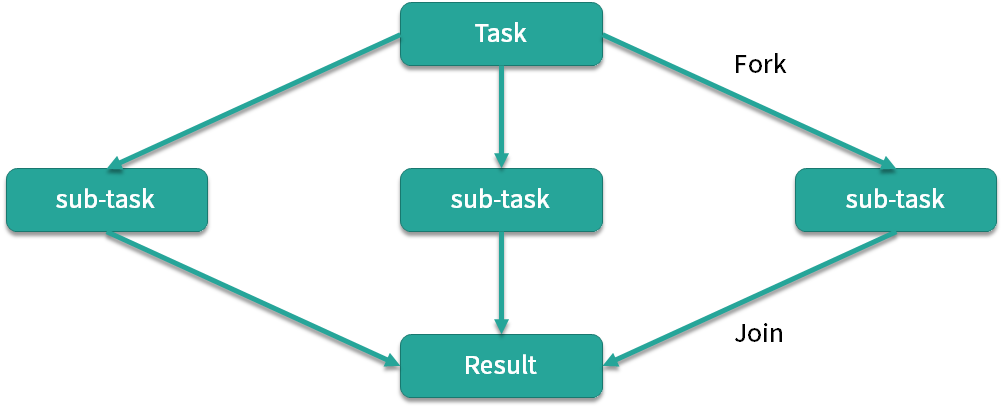
ForkJoinPool在 JDK 7 加入。与前面线程池区别是适合执行可以产生子任务的任务
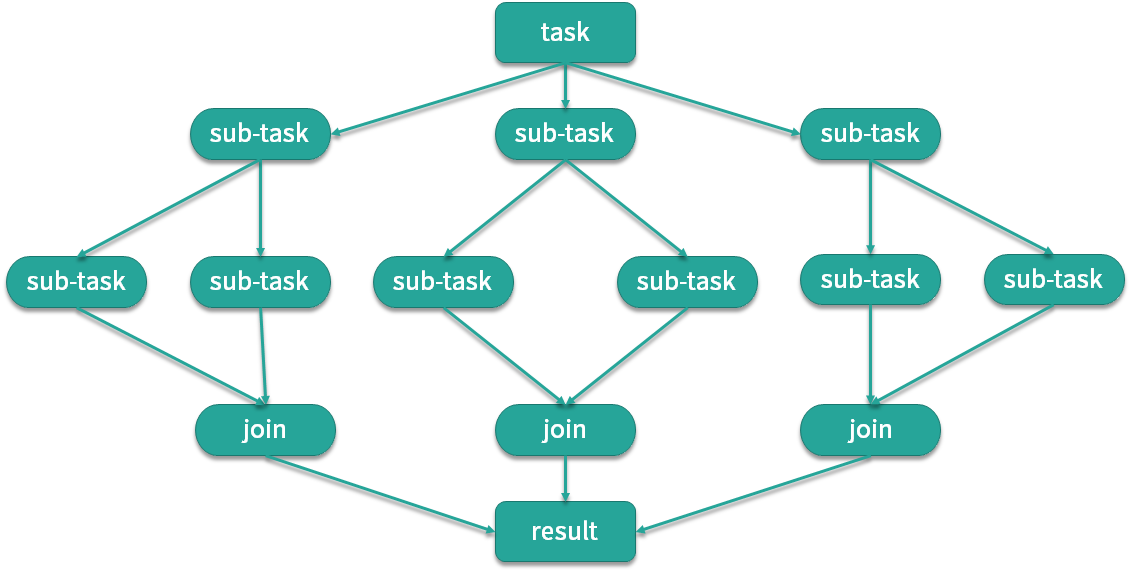
如图所示,我们有一个 Task,这个 Task 可以产生三个子任务,三个子任务并行执行完毕后将结果汇总给 Result,比如说主任务需要执行非常繁重的计算任务,我们就可以把计算拆分成三个部分,这三个部分是互不影响相互独立的,这样就可以利用 CPU 的多核优势,并行计算,然后将结果进行汇总。这里面主要涉及两个步骤,第一步是拆分也就是 Fork,第二步是汇总也就是 Join,到这里你应该已经了解到 ForkJoinPool 线程池名字的由来了
典型的斐波拉契数列
数列的特点就是后一项的结果等于前两项的和,第 0 项是 0,第 1 项是 1,那么第 2 项就是 0+1=1,以此类推。我们通常通过递归方式实现
if (n <= 1) {
return n;
} else {
Fib f1 = new Fib(n - 1);
Fib f2 = new Fib(n - 2);
f1.solve();
f2.solve();
number = f1.number + f2.number;
return number;
}
计算流程如下
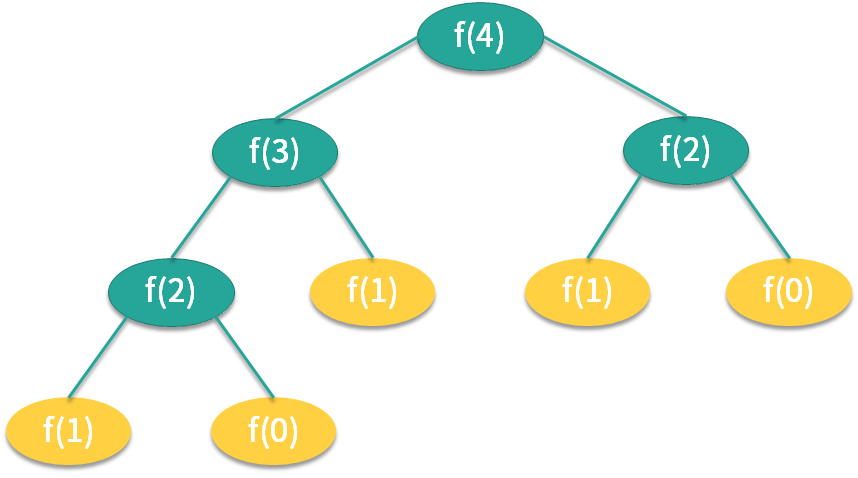
任务拆分结果
使用ForkJoinTask子类RecursiveTask实现
public class Fibonacci extends RecursiveTask<Integer> {
int n;
public Fibonacci(int n) {
this.n = n;
}
@Override
public Integer compute() {
if (n <= 1) {
return n;
}
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
f2.fork();
return f1.join() + f2.join();
}
}
public class ForkJoinPool01 {
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
for (int i = 0; i < 10; i++) {
ForkJoinTask<Integer> task = forkJoinPool.submit(new Fibonacci(i));
System.out.println(task.get());
}
}
}
结果
0
1
1
2
3
5
8
13
21
34
CountedCompleter
ForkJoinPool与其他线程池的不同
- ForkJoinPool采用分治策略
fork join拆分任务然后合并结果 - 内部结构不同,其他线程池共用一个队列,ForkJoinPool线程池每个线程有自己独立的任务队列
![]()
ForkJoinPool 线程池内部除了有一个共用的任务队列之外,每个线程还有一个对应的双端队列 deque,这时一旦线程中的任务被 Fork 分裂了,分裂出来的子任务放入线程自己的 deque 里,而不是放入公共的任务队列中。如果此时有三个子任务放入线程 t1 的 deque 队列中,对于线程 t1 而言获取任务的成本就降低了,可以直接在自己的任务队列中获取而不必去公共队列中争抢也不会发生阻塞(除了后面会讲到的 steal 情况外),减少了线程间的竞争和切换,是非常高效的
![]()
我们再考虑一种情况,此时线程有多个,而线程 t1 的任务特别繁重,分裂了数十个子任务,但是 t0 此时却无事可做,它自己的 deque 队列为空,这时为了提高效率,t0 就会想办法帮助 t1 执行任务,这就是“work-stealing”的含义。

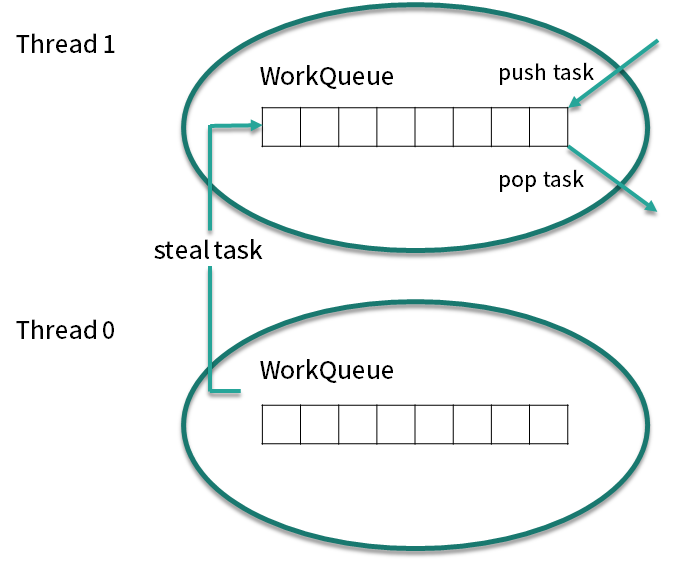
双端队列 deque 中,线程 t1 获取任务的逻辑是后进先出,也就是LIFO(Last In Frist Out),而线程 t0 在“steal”偷线程 t1 的 deque 中的任务的逻辑是先进先出,也就是FIFO(Fast In Frist Out),如图所示,图中很好的描述了两个线程使用双端队列分别获取任务的情景。你可以看到,使用 “work-stealing” 算法和双端队列很好地平衡了各线程的负载。

我们用一张全景图来描述 ForkJoinPool 线程池的内部结构,你可以看到 ForkJoinPool 线程池和其他线程池很多地方都是一样的,但重点区别在于它每个线程都有一个自己的双端队列来存储分裂出来的子任务。ForkJoinPool 非常适合用于递归的场景,例如树的遍历、最优路径搜索等场景
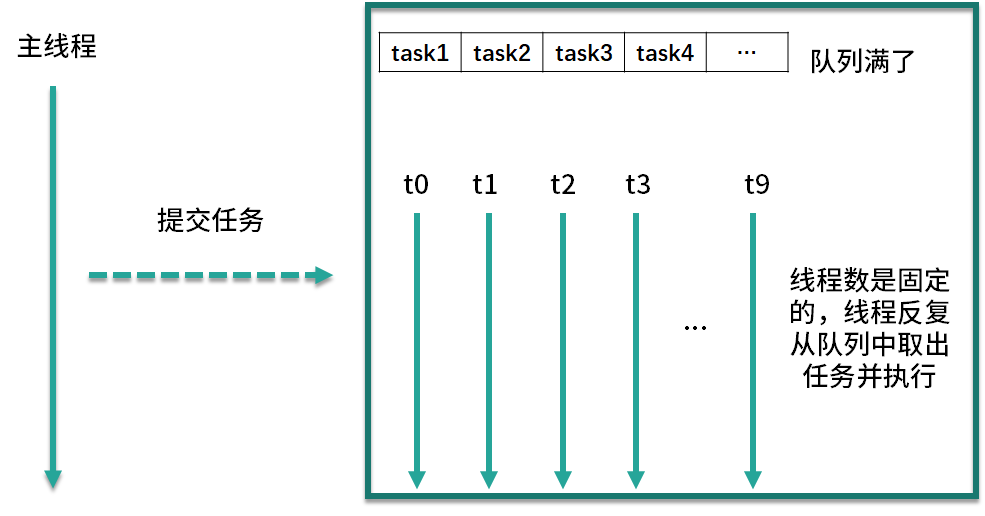
线程池的阻塞队列
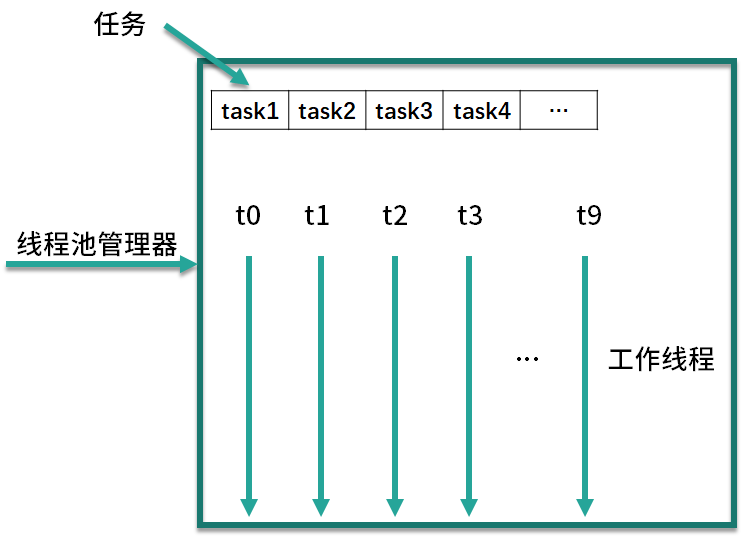
线程池内部结构由4部分组成
- 线程池管理器 : 负责管理线程池的创建、销毁、添加任务等管理操作,它是整个线程池的管家。
- 工作线程 : 图中的线程 t0~t9,这些线程勤勤恳恳地从任务队列中获取任务并执行。
- 任务队列 : 作为一种缓冲机制,线程池会把当下没有处理的任务放入任务队列中,由于多线程同时从任务队列中获取任务是并发场景,此时就需要任务队列满足线程安全的要求,所以线程池中任务队列采用 BlockingQueue 来保障线程安全
- 任务 : 任务要求实现统一的接口,以便工作线程可以处理和执行。
阻塞队列
| 线程池 | 队列 |
|---|---|
| FixedThreadPool | LinkedBlockingQueue |
| SingleThreadExecutor | LinkedBlockingQueue |
| CachedThreadPool | SynchrouousQueue |
| ScheduleThreadPool | DelayedWorkQueue |
| SingleThreadScheduledExecutor | DelayedWorkQueue |
LinkedBlockingQueue
对于 FixedThreadPool 和 SingleThreadExector 而言,它们使用的阻塞队列是容量为 Integer.MAX_VALUE 的 LinkedBlockingQueue,可以认为是无界队列。由于 FixedThreadPool 线程池的线程数是固定的,所以没有办法增加特别多的线程来处理任务,这时就需要 LinkedBlockingQueue 这样一个没有容量限制的阻塞队列来存放任务。这里需要注意,由于线程池的任务队列永远不会放满,所以线程池只会创建核心线程数量的线程,所以此时的最大线程数对线程池来说没有意义,因为并不会触发生成多于核心线程数的线程。
SynchrouousQueue
第二种阻塞队列是 SynchronousQueue,对应的线程池是 CachedThreadPool。线程池 CachedThreadPool 的最大线程数是 Integer 的最大值,可以理解为线程数是可以无限扩展的。CachedThreadPool 和上一种线程池 FixedThreadPool 的情况恰恰相反,FixedThreadPool 的情况是阻塞队列的容量是无限的,而这里 CachedThreadPool 是线程数可以无限扩展,所以 CachedThreadPool 线程池并不需要一个任务队列来存储任务,因为一旦有任务被提交就直接转发给线程或者创建新线程来执行,而不需要另外保存它们。
DelayedWorkQueue
第三种阻塞队列是DelayedWorkQueue,它对应的线程池分别是 ScheduledThreadPool 和 SingleThreadScheduledExecutor,这两种线程池的最大特点就是可以延迟执行任务,比如说一定时间后执行任务或是每隔一定的时间执行一次任务。DelayedWorkQueue 的特点是内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构。之所以线程池 ScheduledThreadPool 和 SingleThreadScheduledExecutor 选择 DelayedWorkQueue,是因为它们本身正是基于时间执行任务的,而延迟队列正好可以把任务按时间进行排序,方便任务的执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号