Doris数据表设计
数据模型
本文主要从逻辑层面,描述Doris的数据模型,以帮助用户更好的使用 Doris 应对不同的业务场景。
基本概念
在 Doris 中,数据以表(Table)的形式进行逻辑上的描述。 一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列
Doris的数据模型主要分为3类:
- Aggregate
- Unique
- Duplicate
下面我们分别介绍
Aggregate
| ColumnName | Type | AggregationType | Comment |
|---|---|---|---|
| user_id | LARGEINT | 用户id | |
| date | DATE | 数据灌入日期 | |
| city | VARCHAR(20) | 用户所在城市 | |
| age | SMALLINT | 用户年龄 | |
| sex | TINYINT | 用户性别 | |
| last_visit_date | DATETIME | REPLACE | 用户最后一次访问时间 |
| cost | BIGINT | SUM | 用户总消费 |
| max_dwell_time | INT | MAX | 用户最大停留时间 |
| min_dwell_time | INT | MIN | 用户最小停留时间 |
转换为SQL语句如下:
CREATE TABLE IF NOT EXISTS example_db.example_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
当我们插入两次这条数据:
INSERT INTO example_tbl(user_id,DATE,city,age,sex,last_visit_date,cost,max_dwell_time,min_dwell_time)
VALUES(10004,'2017/10/03','深圳',35,0,'2019/10/03 10:00:00',20,9,9)
得到的结果是这样的:

可以看出cost字段对两条数据进行了求和。而求和的依据是根据相同的key来的。
Unique模型
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了Unique的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。
也举例说明,我们新建一个用户基础信息表。这类数据没有聚合需求,只需保证主键唯一性。
建表语句如下:
CREATE TABLE IF NOT EXISTS example_tb2
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
这个模型名字叫Unique模型,但跟Mysql中的唯一约束不同。Mysql中同一个key多次插入会报错,而这个模型同一个key插入,后面插入的总是会覆盖之前的。相当于聚合模型(Aggregate)的字段都是REPLACE类型。
Duplicate模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此,我们引入 Duplicate 数据模型来满足这类需求。举例说明:
CREATE TABLE IF NOT EXISTS example_tb3
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`, `error_code`)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
此种模式下,插入两条完全一样的数据会保留2条数据。而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序
INSERT INTO example_tb3 (TIMESTAMP,TYPE,error_code,error_msg,op_id,op_time) VALUES('2022-12-04 00:00:00',1,1,'重复数据',3,'2022-12-05 00:00:00');

聚合模型的局限性
Aggregate模型的局限性
在聚合模型中,模型对外展现的就是最终聚合后的数据。也就是说任何还未聚合的数据必须通过某种方式来保证对外展示的一致性。
| ColumnName | Type | AggregationType | Comment |
|---|---|---|---|
| user_id | LARGEINT | 用户id | |
| date | DATE | 数据灌入日期 | |
| cost | BIGINT | SUM | 用户总消费 |
假设导入两批数据:
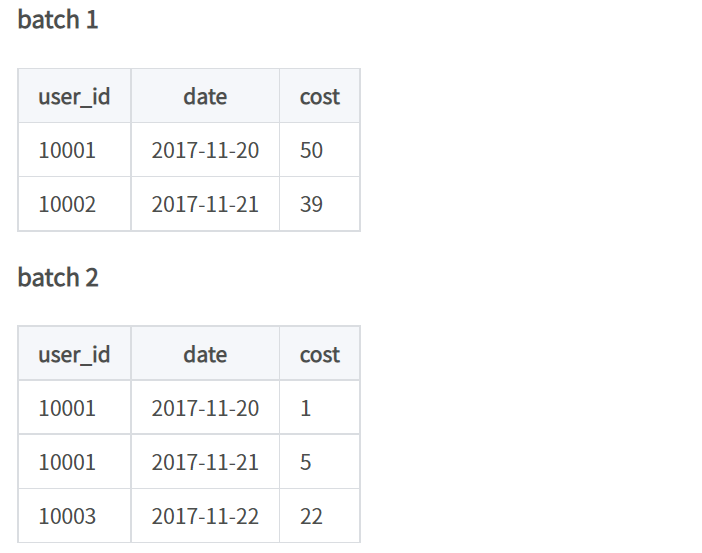
我们再去查询,查询到的结果一定是聚合以后的,如user10001 date:2017-11-20这个数据的cost应该是51。这是doris在查询引擎中加入了聚合算子,来保证数据对外的一致性。
这种一致性的保证,就让某些查询效率很低。如:
SELECT COUNT(*) FROM table;
如果是mysql这种,它只需要对扫描某一列数据就能获得count值,但是在Doris的聚合模型中,开销就很大。他如果只扫描user_id列的话,不加查询聚合结果为5,加上聚合结果为3,都是不对的,正确结果应该为4.因为它要想正确的结果必须同时取user_id、date这两列数据,再加上查询时聚合,才能返回正确的结果。
因此,当业务上有频繁的 count(* )查询时,我们建议用户通过增加一个值恒为 1 的,聚合类型为 REPLACE的列来模拟 count(*)
| ColumnName | Type | AggregationType | Comment |
|---|---|---|---|
| user_id | LARGEINT | 用户id | |
| date | DATE | 数据灌入日期 | |
| cost | BIGINT | SUM | 用户总消费 |
| count | BIGINT | REPLACE | 用于计算count |
这样的话,通过这个语句就能得到之前count(*)的结果
select sum(count) from table;
数据模型选择的建议
数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
-
Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
-
Unique 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势(因为本质是 REPLACE,没有 SUM 这种聚合方式)。
- 【注意】Unique 模型仅支持整行更新,如果用户既需要唯一主键约束,又需要更新部分列(例如将多张源表导入到一张 doris 表的情形),则可以考虑使用 Aggregate 模型,同时将非主键列的聚合类型设置为 REPLACE_IF_NOT_NULL。具体的用法可以参考语法手册
- Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号