Flink体系架构
Flink的重要角色
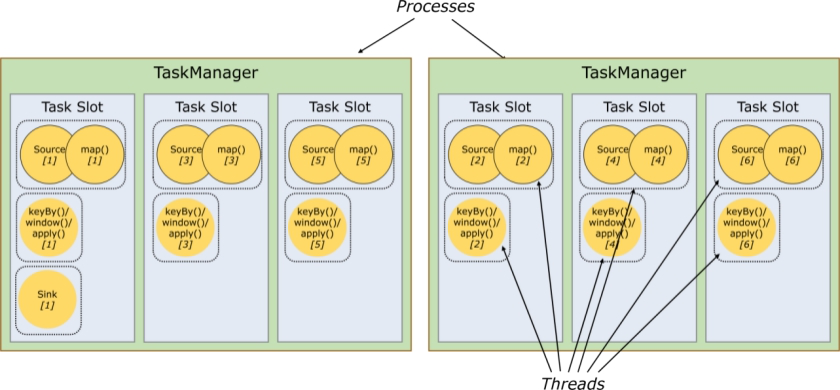
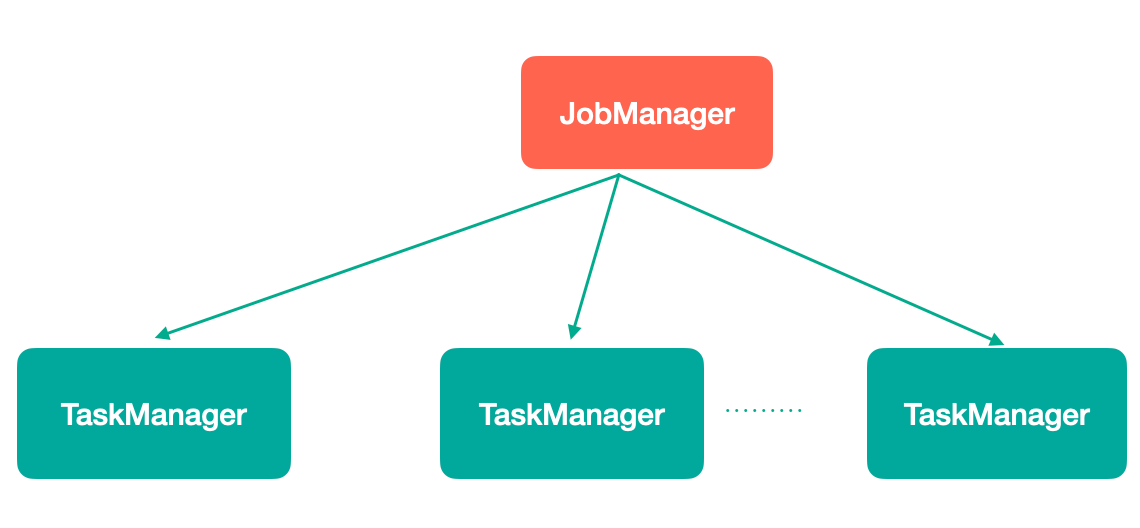
Flink是非常经典的Master/Slave结构实现,JobManager是Master,TaskManager是Slave。
-
JobManager处理器(Master)
- 协调分布式执行,它们用来调度task,协调检查点(CheckPoint),协调失败时恢复等
- Flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master处理器,它们其中有一个是leader,而其他的都是standby。
-
TaskManager处理器(Slave)
也称之为Worker
- 主要职责是从JobManager处接收任务, 并部署和启动任务, 接收上游的数据并处理
- Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点
Flink运行架构
1.Flink程序结构
Flink程序的基本构建块是流和转换(请注意,Flink的DataSet API中使用的DataSet也是内部流 )。从概念上讲,流是(可能永无止境的)数据记录流,而转换是将一个或多个流输入,并产生一个或多个输出流。
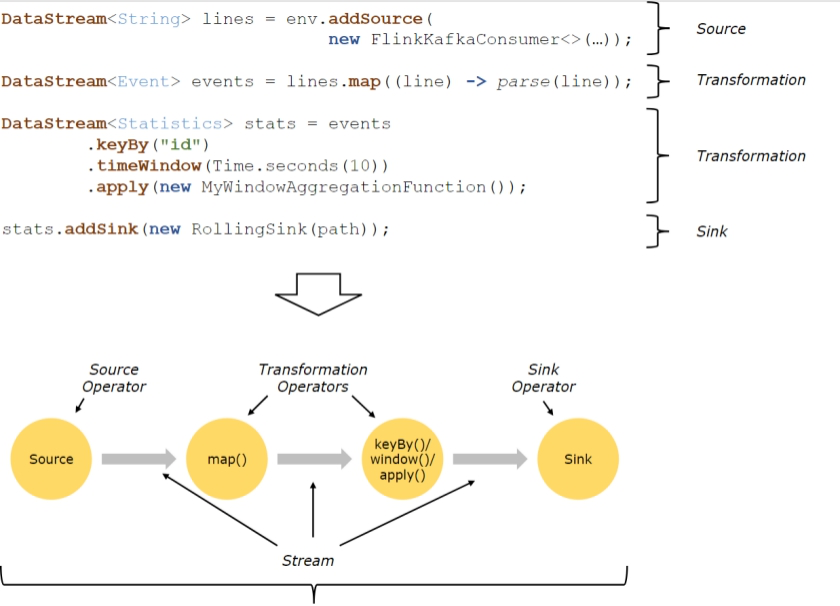
上图表述了Flink的应用程序结构,有Source(源头)、Transformation(转换)、Sink(接收器)三个重要组成部分
Source
数据源,定义Flink从哪里加载数据,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、RabbitMQ 等。
Transformation
数据转换的各种操作,也称之为算子,有 Map / FlatMap / Filter / KeyBy / Reduce / Window等,可以将数据转换计算成你想要的数据。
Sink
接收器,Flink 将转换计算后的数据发送的地点 ,定义了结果数据的输出方向,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、HDFS等。
2.Task和SubTask
Task 是一个阶段多个功能相同 SubTask 的集合,类似于 Spark 中的 TaskSet。
SubTask(子任务)
-
SubTask 是 Flink 中任务最小执行单元,是一个 Java 类的实例,这个 Java 类中有属性和方法,完成具体的计算逻辑
-
比如一个执行操作map,分布式的场景下会在多个线程中同时执行,每个线程中执行的都叫做一个SubTask(在第3节的图中也能够体现)
3.Operator chain(操作器链)
Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。
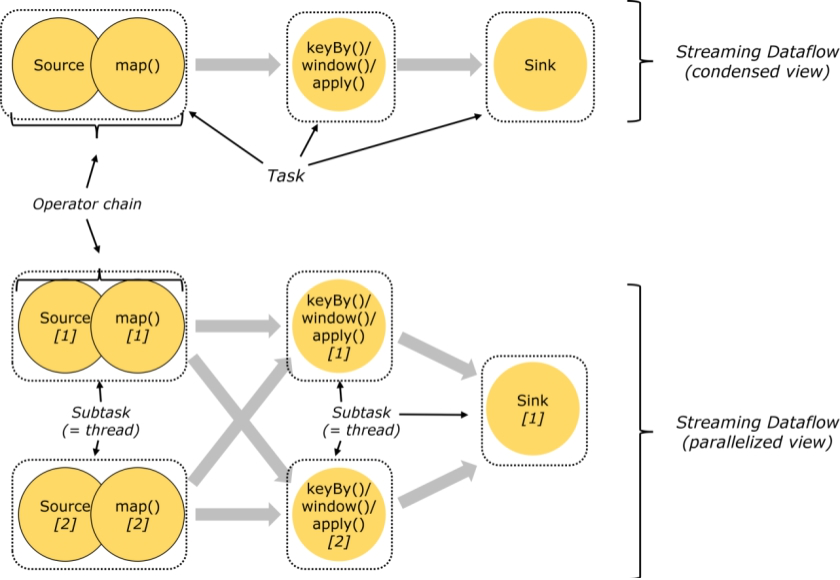
4.任务槽和槽共享
任务槽也叫做task-slot、槽共享也叫做slot sharing
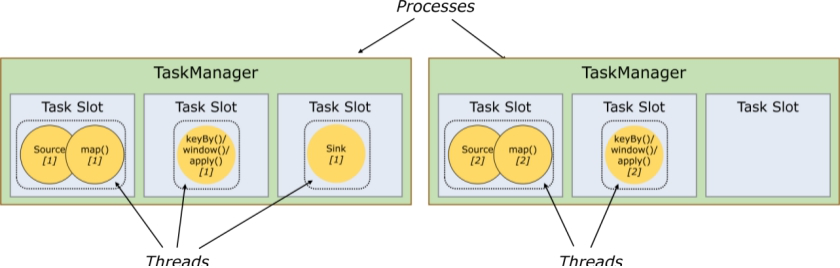
每个TaskManager是一个JVM的进程, 可以在不同的线程中执行一个或多个子任务。 为了控制一个worker能接收多少个task。worker通过task slot来进行控制(一个worker至少有一个task slot)
任务槽
每个task slot表示TaskManager拥有资源的一个固定大小的子集。 一般来说:我们分配槽的个数都是和CPU的核数相等,比如6核,那么就分配6个槽.
Flink将进程的内存进行了划分到多个Slot中。假设一个TaskManager机器有3个slot,那么每个slot占有1/3的内存(平分)。
内存被划分到不同的slot之后可以获得如下好处:
- TaskManager最多能同时并发执行的任务是可以控制的,那就是3个,因为不能超过slot的数量
- slot有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响
槽共享
默认情况下,Flink允许子任务subtask(map[1] map[2] keyby[1] keyby[2]) 共享插槽,即使它们是不同任务的子任务,只要它们来自同一个作业。结果是一个槽可以保存作业的整个管道。