HDFS基础入门
HDFS简介
HDFS(全称:Hadoop Distribute File System)分布式文件系统,是Hadoop核心组成。
HDFS中的重要概念
分块存储
HDFS中的文件在物理上是分块存储的,块的大小可以通过配置参数来规定;Hadoop2.x版本默认的block大小是128M
命名空间
HDFS支持传统的层次性文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名这些文件。
NameNode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都被NameNode记录下来。
NameNode元数据
我们把目录结构及文件分块位置信息叫做元数据。NameNode的元数据记录每一个文件对应的block信息。
DataNode数据存储
文件的各个block的具体存储管理由DataNode负责。一个block会有多个DataNode来存储,DataNode会定时向NameNode来汇报自己持有的block信息。
副本机制
为了容错,文件的所有block都会有副本。每隔文件的block大小和副本数都是可配置的。副本数默认是3个。
一次写入,多次读出
HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的随机修改。正因为如此,HDFS适合用来做大数据分析的底层存储服务,而不适合做网盘等应用。(修改不方便,延迟大)
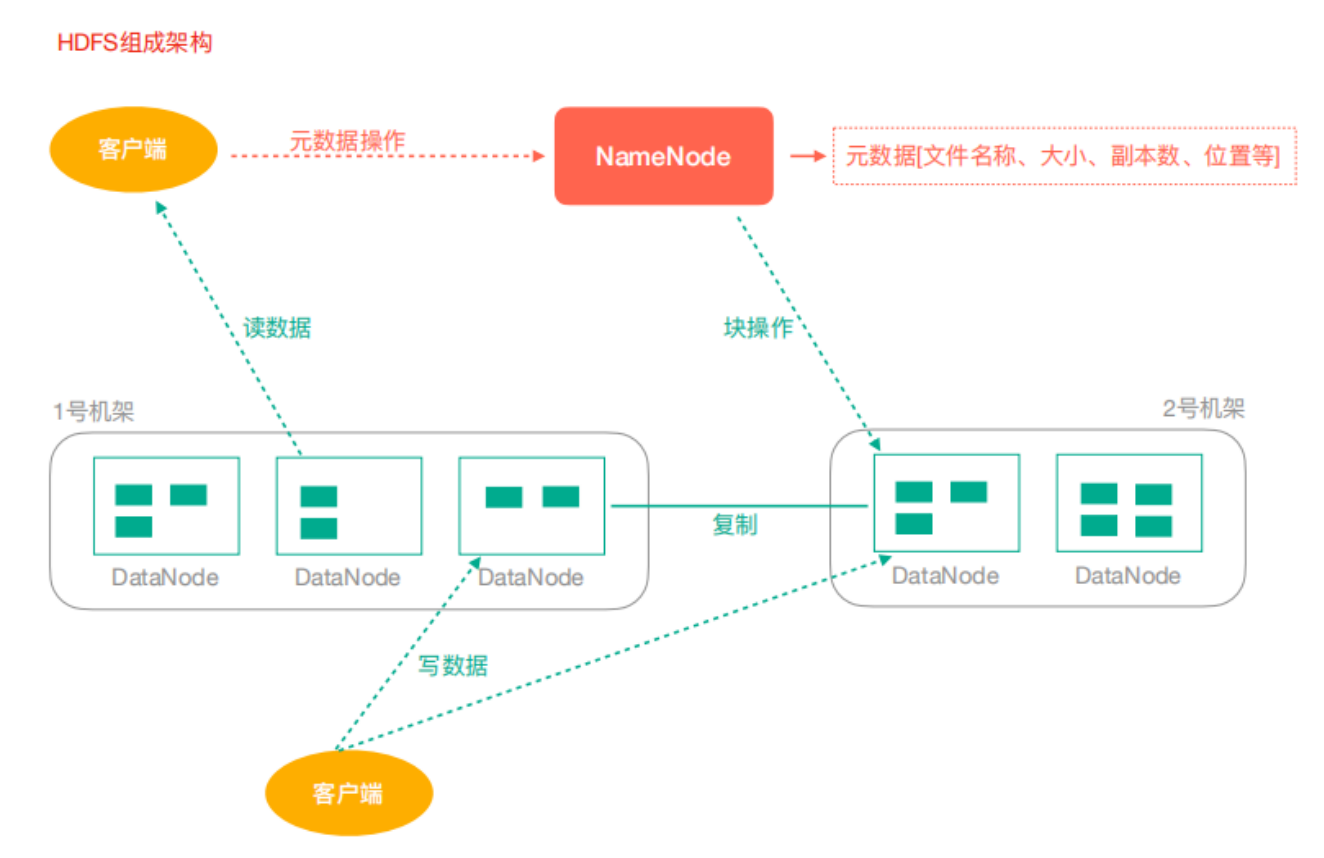
HDFS架构
-
NameNode:Hdfs集群的管理者
- 维护管理Hdfs的名称空间
- 维护副本策略
- 记录文件块的映射关系
- 负责处理客户端读写请求
-
DataNode:NameNode下达命令,DataNode执行实际操作
- 保存实际的数据块
- 负责数据块的读写
-
Client:客户端
- 上传文件到HDFS的时候,Client负责将文件切分成Block,然后进行上传
- 请求NameNode交互,获取文件的位置信息
- 读取或写入文件,与DataNode交互
- Client可以使用一些命令来管理HDFS或者访问HDFS
HDFS客户端操作
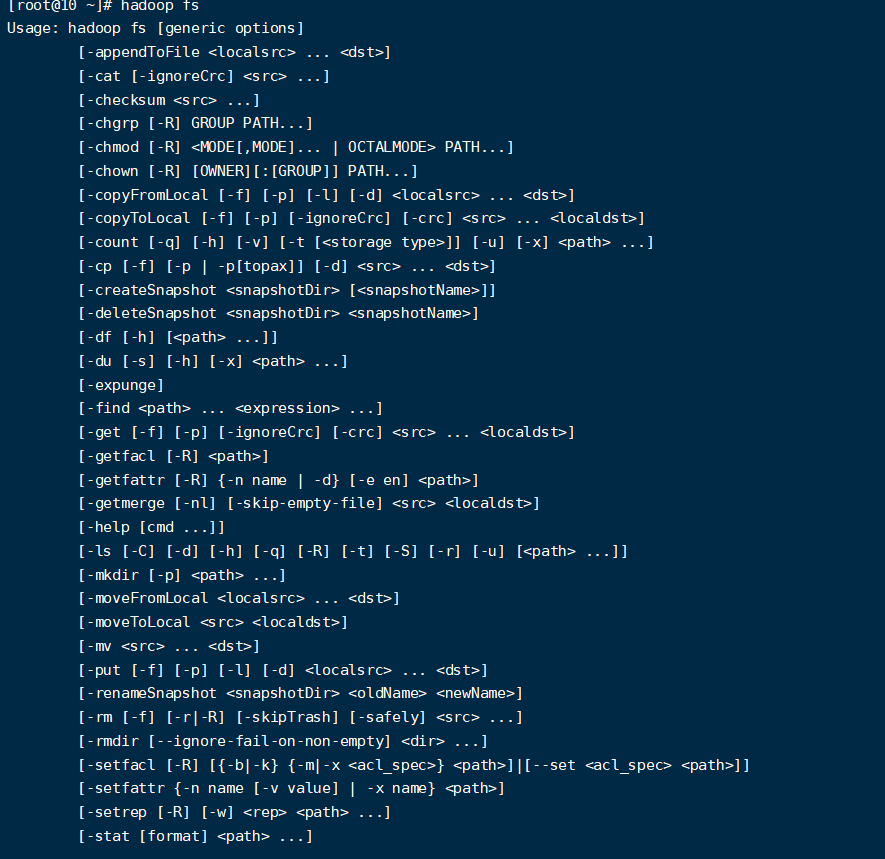
Shell客户端
- 查看所有命令
hadoop fs
- 查看命令帮助
#查看rm的帮助信息
hadoop fs -help rm
- 显示目录信息
hadoop fs -ls /
- 创建目录
hadoop fs -mkdir -p /test/data
- 从本地剪切到HDFS
hadoop fs -moveFromLocal ./word.txt /test/data
- 追加文件内容到指定文件
hadoop fs -appendToFile test.txt /test/data/word.txt
- 显示文件内容
hadoop fs -cat /test/data/word.txt
- 修改文件所属权限
hadoop fs -chmod 666 /test/data/word.txt
hadoop fs -chown root:root /test/data/word.txt
- 从本地文件系统拷贝文件到HDFS路径去
hadoop fs -copyFromLocal test.txt /test
- 从HDFS拷贝到本地
hadoop fs -copyToLocal /test/data/word.txt /opt
- 从HDFS的一个路径拷贝到HDFS的另一个路径
hadoop fs -cp /test/data/word.txt /test/input/t.txt
- 在HDFS目录中移动文件
hadoop fs -mv /test/input/t.txt /
- 从HDFS中下载文件,等同于copyToLocal
hadoop fs -get /t.txt ./
- 从本地上传文件到HDFS,等同于copyFromLocal
hadoop fs -put ./yarn.txt /user/root/test/
- 显示一个文件的末尾
hadoop fs -tail /t.txt
- 删除文件或文件夹
hadoop fs -rm /t.txt
- 删除空目录
hadoop fs -rmdir /test
- 统计文件夹的大小信息
hadoop fs -du -s -h /test
hadoop fs -du -h /test

- 设置HDFS的副本数量
hadoop fs -setrep 10 /lagou/bigdata/hadoop.txt
注意:这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10.
Java客户端
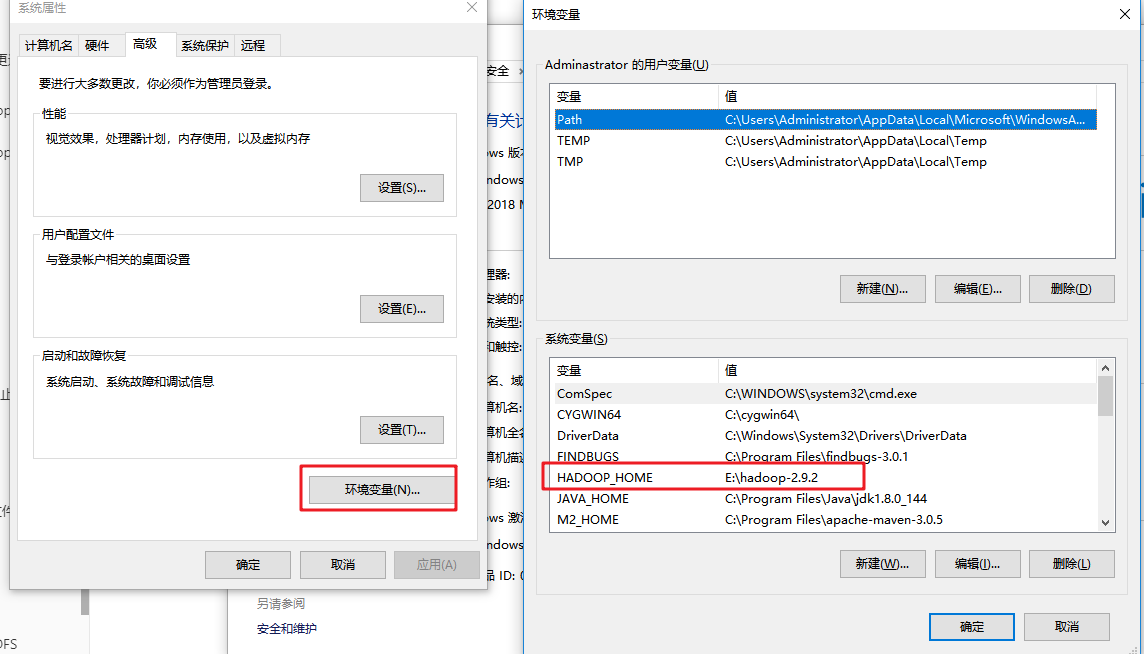
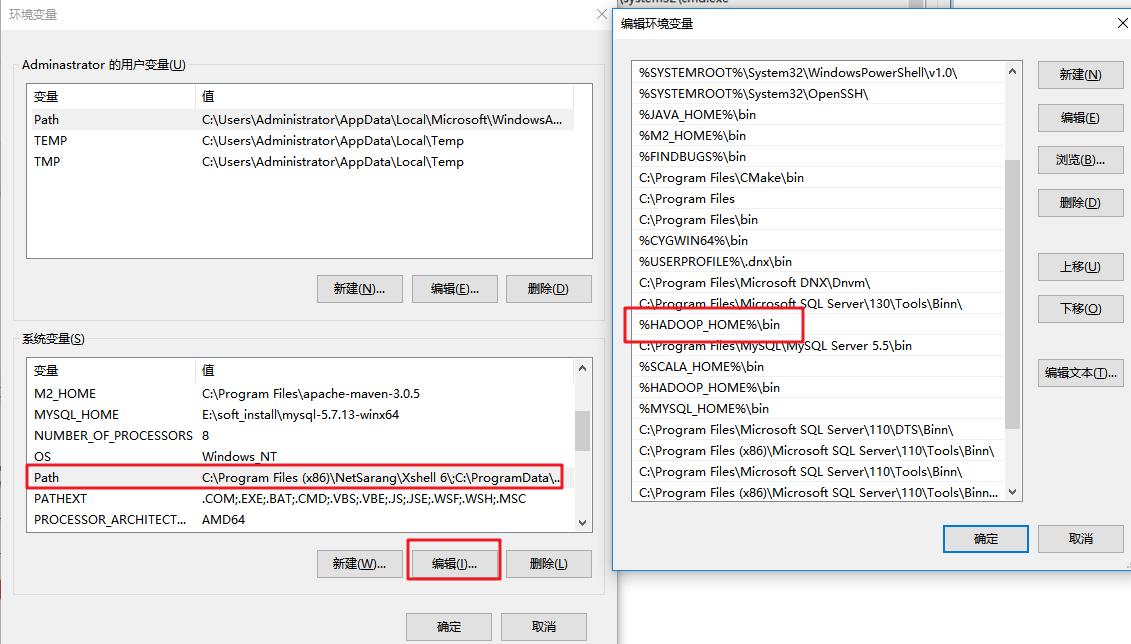
环境准备
- 将Hadoop安装包解压到非中文路径
- 配置环境变量
- 依赖导入
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop-version}</version>
</dependency>
- 配置文件(可选步骤)
将hdfs-site.xml(内容如下)拷贝到项目的resources下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
参数优先级排序:(1)代码中设置的值 >(2)用户自定义配置文件 >(3)服务器的默认配置
HDFS Java API
- 上传文件
@Test
public void testCopyFromLocalFile() throws Exception{
Configuration conf = new Configuration();
FileSystem fs=FileSystem.get(new URI("hdfs://192.168.56.103:9000"),conf,"root");
fs.copyFromLocalFile(new Path("e://aa.txt"),new Path("/cc.txt"));
fs.close();
}
为了方便,下面的示例就隐藏构建FileSystem的过程
- 下载文件
@Test
public void testCopyToLocalFile() throws Exception{
fs.copyToLocalFile(false,new Path("/aa.txt"),new Path("e://cd.txt"),true);
}
- 删除文件
@Test
public void testDelete() throws Exception{
fs.delete(new Path("/aa.txt"),true);
}
- 查看文件名称、权限、长度、块信息等
public void testList() throws IOException {
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()){
LocatedFileStatus status = listFiles.next();
//文件名称
System.out.println(status.getPath().getName());
System.out.println(status.getLen());
System.out.println(status.getPermission());
System.out.println(status.getGroup());
BlockLocation[] blockLocations = status.getBlockLocations();
Stream.of(blockLocations).forEach(
block->{
String[] hosts = new String[0];
try {
hosts = block.getHosts();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(Arrays.asList(hosts));
}
);
System.out.println("-----------华丽的分割线----------");
}
}
- 文件夹判断
@Test
public void testListStatus() throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
Stream.of(fileStatuses).forEach(fileStatus -> {
String name = fileStatus.isFile() ? "文件:" + fileStatus.getPath().getName() : "文件夹:"+fileStatus.getPath().getName();
System.out.println(name);
});
}
- 通过I/O流操作HDFS
- IO流上传文件
@Test
public void testIOUpload() throws IOException {
FileInputStream fis = new FileInputStream(new File("e://11.txt"));
FSDataOutputStream fos = fs.create(new Path("/io_upload.txt"));
IOUtils.copyBytes(fis,fos,new Configuration());
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
- IO流下载文件
@Test
public void testDownload() throws IOException{
FSDataInputStream fis = fs.open(new Path("/io_upload.txt"));
FileOutputStream fos = new FileOutputStream(new File("e://11_copy.txt"));
IOUtils.copyBytes(fis,fos,new Configuration());
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
- seek定位读取
@Test
public void readFileSeek() throws IOException{
FSDataInputStream fis = fs.open(new Path("/io_upload.txt"));
IOUtils.copyBytes(fis,System.out,1024,false);
//从头再次读取
fis.seek(0);
IOUtils.copyBytes(fis,System.out,1024,false);
IOUtils.closeStream(fis);
}
HDFS文件权限问题
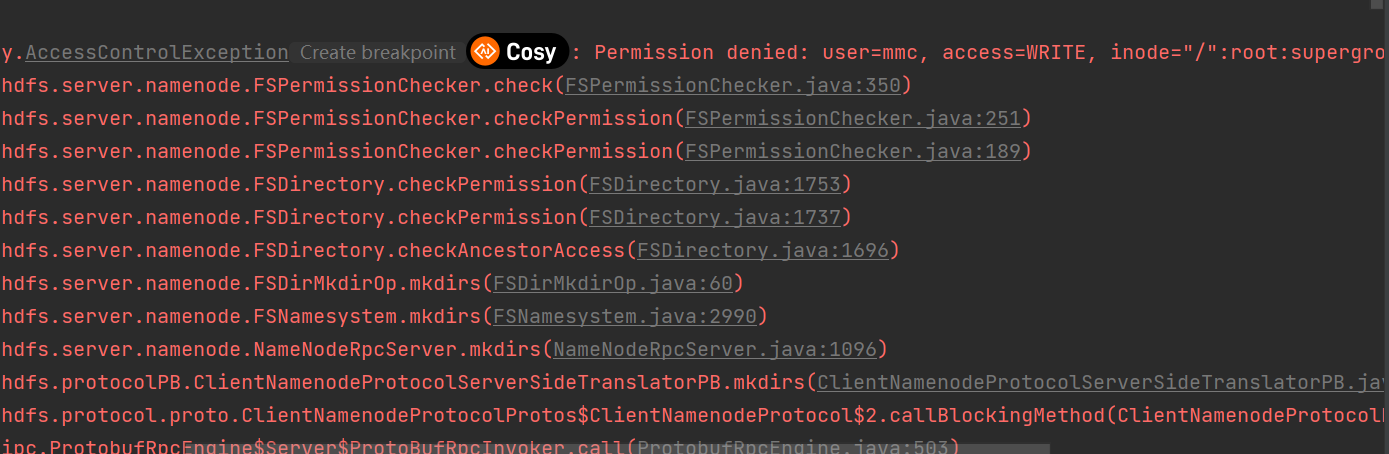
HDFS的文件权限和linux系统的文件权限机制类似。如果在linux系统中root用户使用hadoop命令创建了一个文件,那么该文件的owner就是root。
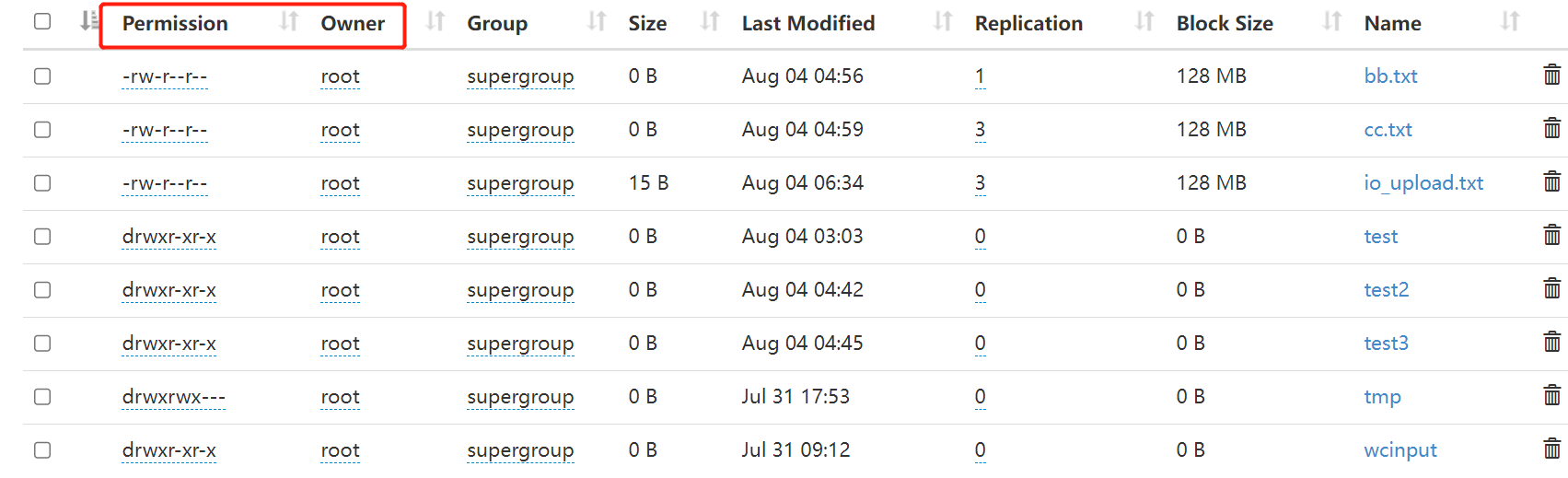
当出现权限问题时,解决方法有如下几种:
- 获取FileSystem对象时指定有权限的用户
- 关闭HDFS权限校验,修改hdfs-site.xml
#添加如下属性
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
- 直接修改HDFS的文件或目录权限为777,允许所有用户操作
hadoop fs -chmod -R 777 /


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)