Hadoop基础入门
Hadoop 简介
什么是 Hadoop
Hadoop 是一个适合大数据的分布式存储和计算平台。
狭义上来说 Hadoop 就是一个框架平台,广义上讲 Hadoop 代表大数据的一个技术生态圈,包括很多其他软件框架。
Hadoop 生态圈技术栈:
| Hadoop 技术栈 |
|---|
| Hadoop(HDFS+MapReduce+Yarn) |
| Hive 数据仓库工具 |
| HBase 海量列式非关系型数据库 |
| Flume 数据采集工具 |
| Sqoop ETL 工具 |
| Kafka 消息中间件 |
Hadoop 起源
- Hadoop 最早起源于 Nutch,Nutch 的创始人是 Doug Cutting,Nutch 是一个开源的 java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需要的全部工具。包括全文搜索和 Web 爬虫,但随着抓取的网页数量的增加,海量数据的存储和索引就成了严重的问题。
- 受到谷歌发布的论文的方案的影响,Doug Cutting 等人用 2 年业余时间实现了 DFS 和 MapReduce 机制,使 Nutch 性能飙升
- 2005 年,Hadoop 作为 Lucene 的子项目 Nutch 的一部分引入 Apache
- 2006 年,Hadoop 从 Nutch 剥离出来独立
- 2008 年,Hadoop 成为 Apache 的顶级项目
Hadoop 这个名字的来源是作者 Doug Cutting 儿子的毛绒玩具象
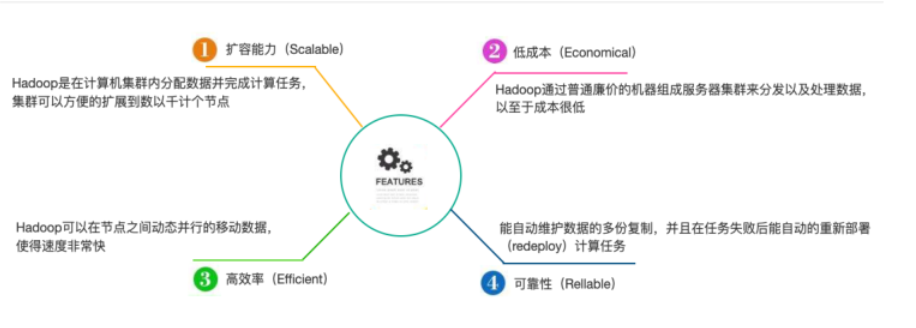
Hadoop 的特点
Hadoop 的版本
目前 Hadoop 发行版非常多,有 Cloudera 发行版(CDH)、Hortonworks 发行版、华为发行版、Intel 发行版等,所有这些发行版均是基于 ApacheHadoop 衍生出来的,之所以有这么多的版本,是由 ApacheHadoop 的开源协议决定的(任何人可以对其进行修改,并作为开源或商业产品发布/销售)。
企业中用到的三个版本分别是:Apache Hadoop、Cloudera 版本、Hortonworks 版本。
- Apache Hadoop 原始版本
官网地址:http://hadoop.apache.org/
优点:拥有全世界的开源贡献,代码更新版本比较快
缺点:版本的升级,版本的维护,以及版本之间的兼容性,学习非常方便
- 软件收费版本 ClouderaManager CDH 版本 --生产环境使用
官网地址:https://www.cloudera.com/
Cloudera 主要是美国一家大数据公司在 Apache 开源 Hadoop 的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题,生产环境强烈推荐使用
- 免费开源版本 HortonWorks HDP 版本--生产环境使用
hortonworks 主要是雅虎主导 Hadoop 开发的副总裁,带领二十几个核心成员成立 Hortonworks,核心产品软件 HDP(ambari),HDF 免费开源,并且提供一整套的 web 管理界面,供我们可以通过 web 界面管理我们的集群状态,web 管理界面软件 HDF 网址( http://ambari.apache.org/ )
Apache Hadoop 版本介绍
0.x 系列版本:Hadoop 当中最早的开源版本
1.x 系列版本:Hadoop 版本当中的第二代开源版本,主要修复 0.x 版本的 bug
2.x 系列版本:架构产生重大变化,引入了 yarn 平台等许多新特性
3.x 系列版本: EC 技术、Yarn 的时间轴服务等新特性
Hadoop 的优缺点
Hadoop 的优点:
- Hadoop 具有存储和处理数据能力的高可靠性
- Hadoop 通过可用的计算机集群分配数据,完成存储和计算任务,这些集群可以方便地扩展到数以千计的节点中,具有高扩展性
- Hadoop 能够在节点之间进行动态的移动数据,并保证各个节点的动态平衡,处理速度非常快,具有高效性
- Hadoop 能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配,具有高容错性。
Hadoop 的缺点:
- Hadoop 不适用于低延迟数据访问
- Hadoop 不能高效存储大量小文件
- Hadoop 不支持多用户写入并任意修改文件
Apache Hadoop 的重要组成
Hadoop = HDFS(分布式文件系统)+MapReduce(分布式计算框架)+Yarn(资源协调框架)+Common 模块
1. Hadoop HDFS
HDFS (Hadoop Distribute File System)一个高可靠、高吞吐量的分布式文件系统。它的思想是”分而治之“,将数据切割、制作副本进行分散存储。

图中涉及的角色:
- NameNode(nn) :存储文件的元数据,比如文件名、文件目录结构、文件属性,以及每个文件的块列表和块所在的 DataNode 等
- SecondaryNameNode(2nn):辅助 NameNode 更好的工作,用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据快照
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验
注意:NN、2NN、DN 这些既是角色名称又是进程名称。
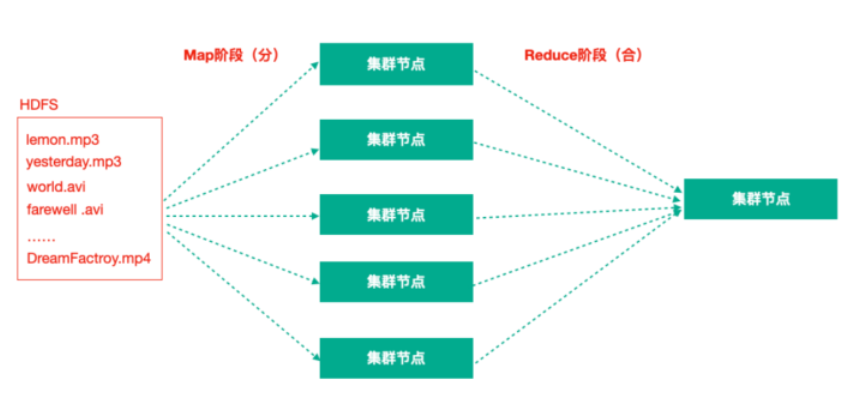
2. Hadoop MapReduce
MapReduce 是一个分布式的离线并行计算框架,思想是拆解任务、分散处理然后汇整结果。
MapReduce = Map 阶段 + Reduce 阶段
Map 阶段就是”分“的阶段,并行处理输入数据;Reduce 阶段就是”合“的阶段,对 Map 阶段的结果进行汇总。
3. Hadoop YARN
Yarn 是作业调度与集群资源管理的框架,
Yarn 有如下几个主要角色:
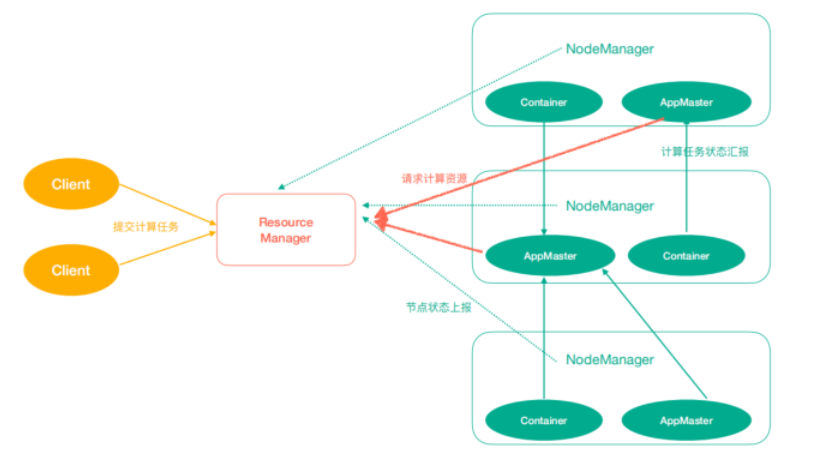
- ResourceManager(rm):处理客户端请求、启动/监控 ApplicationMaster、监控 NodeManager、资源分配与调度
- NodeManager(nm):单个节点上的资源管理、处理来自 ResourceManager 的命令、处理来自 ApplicationMaster 的命令
- ApplicationMaster(am):数据切分、为应用程序申请资源,并分配内部任务、任务监控与容错。
- Container:对任务运行环境的抽象,封装了 CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
通俗的说:ResourceManager 是老大,NodeManager 是小弟,ApplicationMaster 是计算任务专员

 浙公网安备 33010602011771号
浙公网安备 33010602011771号