Lucene高级技术
Lucene存储结构

Lucene的索引结构是有层次结构的,主要分为以下几个层次:
- 索引(Index)
一个目录一个索引,在Lucene中一个索引是放在一个文件夹中的。同一个文件夹中的文件构成一个Lucene索引
- 段(Segment)
一个索引包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以合并。在建立索引的时候对性能影响最大的地方就是在向索引写入文档的时候,所以在具体应用的时候就需要对此加以控制,段就是实现这种控制的。Lucene中默认每加入10个文档就从内存往index文件写入并生成一个段。
| 属性 | 默认值 | 描述 |
|---|---|---|
| MergeFactory | 10 | 控制segment合并的频率和大小 |
| MaxMergeDocs | Int.MaxValue | 限制每个segment中包含的文档数 |
| MinMergeDocs | 10 | 当内存中的文档达到多少的时候再写入segment |
- 文档(Document)
文档是我们建索引的基本单位,一个段可以包含多篇文档。新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中.
- 域(Field)
一篇文档包含不同类型的信息,可以分开索引,比如标题、内容、作者等,可以保存在不同的域中
- 词(Term)
词是索引的最小单位,是经过词法分析和语言处理后的字符串。
为何Lucene大数据量搜索快, 要分两部分来看:
- 因为底层的倒排索引存储结构
- 因为词典的索引结构,查询关键字的时候速度快
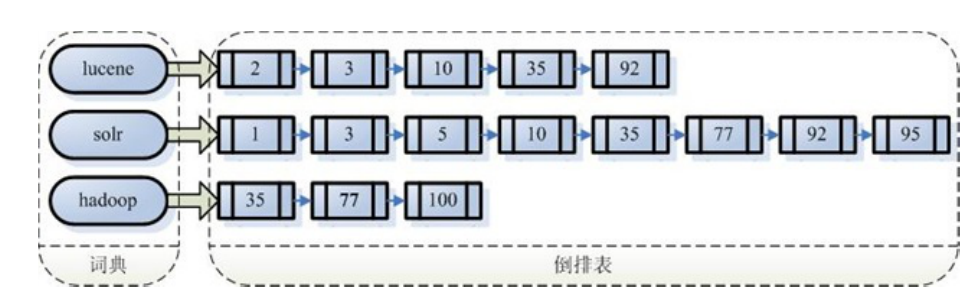
Lucene的索引结构中,即保存了正向信息,也保存了反向信息。
- 正向信息
按层次保存了从索引一直到词的包含关系:索引(Index) –> 段(segment) –> 文档(Document)–> 域(Field) –> 词(Term)
- 反向信息
保存了词典到倒排表的映射:词(Term) –> 文档(Document)
字典的数据结构对比:
| 数据结构 | 说明 |
|---|---|
| 排序列表Array/List | 使用二分法查找,不平衡 |
| HashMap/TreeMap | 性能高,内存消耗大,几乎是原始数据的三倍 |
| Skip List | 跳跃表,可快速查找词语,在lucene、redis、Hbase等均有实现。相对于TreeMap等结构,特别适合高并发场景 |
| Trie | 适合英文词典,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存 |
| Double Array Trie | 适合做中文词典,内存占用小,很多分词工具均采用此种算法 |
| Ternary Search Tree | 三叉树,每一个node有3个节点,兼具省空间和查询快的优点 |
| Finite State Transducers (FST) | 一种有限状态转移机,Lucene 4有开源实现,并大量使用 |
TST的结构:
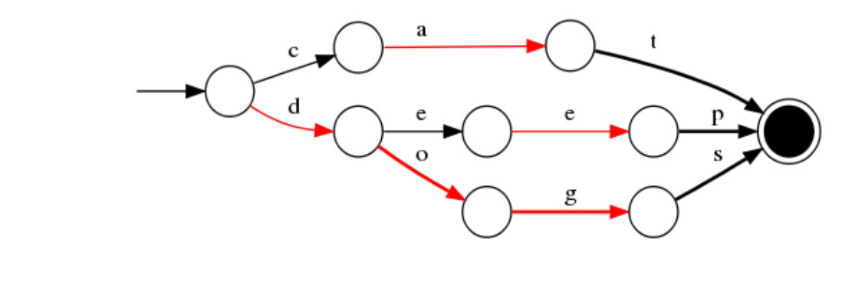
- 优点:内存占用率低,压缩率一般在3倍~20倍之间、模糊查询支持好、查询快
- 缺点:结构复杂、输入要求有序、更新不易
Lucene优化
- 过滤请求
有些单词不在索引库里,但还需要进索引库查询,发起不必要的IO请求。
使用布隆过滤器,预先判断单词是不是在该索引库里。布隆过滤器原理很简单,对一单词哈希,并映射到相应bit,设置为1,判断时同样做哈希,并去相应bit位取值,若为1,则可能存在,进库查询,若为0,则肯定不存在,不需进库查询。
- 通过设置IndexWriter的参数优化
maxBufferedDocs、maxMergeDocs、mergeFactor
- 选择合适的分词器
不同的分词器分词效果不同,所用时间也不同。虽然StandardAnalyzer切分词速度快过IKAnalyzer,但是由于StandardAnalyzer对中文支持不好,所以为了追求好的分词效果, 为了追求查询时的准确率,最好用IKAnalyzer分词器,IKAnalyzer支持停用词典和扩展词典,可以通过调整两个词典中的内容,来提升查询匹配的精度。
4. 屏蔽打分、排序机制(如果业务上不需要的话)
indexSearcher.setSimilarity(indexSearcher.getSimilarity(false));
- 选择合适的对应存放索引库
| 类 | 写操作 | 读操作 | 特点 |
|---|---|---|---|
| SimpleFSDirectory | RandomAccessFile | RandomAccessFile | 简单实现、并发能力差 |
| NIOFSDirectory | FileChannel | FSDirectory.FSIndexOutput | 并发能力强,但windows系统下有bug |
| MMapDirectory | 内存映射 | FSDirectory.FSIndexOutput | 读取操作基于内存 |
注意事项
-
关键词区分大小写
OR AND TO等关键词是区分大小写的,lucene只认大写的,小写的当做普通单词。 -
读写互斥性
同一时刻只能有一个对索引的写操作,在写的同时可以进行搜索
- 文件锁
写索引的过程中强行退出将在tmp目录留下一个lock文件,使以后的写操作无法进行,可以将其手工删除
- 时间格式
lucene只支持一种时间格式yyMMddHHmmss,所以你传一个yy-MM-dd HH:mm:ss的时间给lucene,它是不会当作时间来处理的。
使用工具类可以把日期处理成yyMMdd
DateTools.dateToString(new Date(), DateTools.Resolution.DAY)
- 设置 boost
有些时候在搜索时某个字段的权重需要大一些,例如你可能认为标题中出现关键词的文章比正文中出现关键词的文章更有价值,你可以把标题的boost设置的更大,那么搜索结果会优先显示标题中出现关键词的文章.
Query termQuery = new TermQuery(new Term("name","lucene"));
BoostQuery query =new BoostQuery(termQuery, 3.5f);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号