三千字介绍Redis主从+哨兵+集群
一、Redis持久化策略
1.RDB
每隔几分钟或者一段时间会将redis内存中的数据全量的写入到一个文件中去。
优点:
- 因为他是每隔一段时间的全量备份,代表了每个时间段的数据。所以适合做冷备份。
- RDB对redis的读写影响非常小,因为redis主进程只需要fork一个子进程进行磁盘IO操作就行了。
- 相对于AOF来说,恢复较快,因为一个RDB就是数据文件,而AOF存的是指令日志。
缺点:
- 因为是一段时间才备份,所以容易丢数据。
- 如果一次写入的文件大,会导致读写服务暂停几毫秒,甚至几秒。
2.AOF
会将每条写入指令都写入到linux os缓存中去,然后每秒钟会将linux os中的指令作为日志追加到AOF的文件里面。
当redis内存大小达到一定的量,会通过LRU(最近最少使用)淘汰机制淘汰掉数据,然后再重写一个新的AOF文件出来。这样也保证了AOF文件不会无限制的增大。
优点:
- 不易丢数据
- AOF日志文件是以append-only的模式写入,没有磁盘寻址的开销,写入性能高,文件也不易破损
- AOF文件过大的时候,后台重写操作,也不会影响客户端。再rewrite的时候,会对指令压缩,创建出一份需要恢复的最小日志出来,再创建新日志文件时,老的文件照常写入,当新文件准备好了,再交换新老日志文件就行了
- 日志文件的命令是可读的,可以作为误删的紧急恢复。停了服务,再把那条删除指令删除,再恢复就行了。
缺点:
- AOF日志文件占用的磁盘空间比较大
- 开启AOF后,写操作的QPS会下降
- 以前出过bug,恢复的数据和原来不一样,健壮性没有RDB高
- 恢复数据慢,且不适合做冷备(需要手动写脚本)
3.混合持久化(Redis 4.0)
开启混合持久化
aof-use-rdb-preamble yes
综合来说:
我们可以采用两种都用的的方案,RDB做冷备,为了保证数据不丢失,AOF做数据恢复的第一选择。
如何配置持久化?
-
找到/usr/local/package/redis-4.0.9/redis.conf
-
RDB的配置
//每隔60秒,如果有10000个key发生改变就持久化一次
save 60 10000
- AOF的配置
# redis默认关闭AOF机制,可以将no改成yes实现AOF持久化
appendonly no
# AOF文件
appendfilename "appendonly.aof"
# AOF持久化同步频率,always表示每个Redis写命令都要同步fsync写入到磁盘中,但是这种方式会严重降低redis的速度;everysec表示每秒执行一次同步fsync,显示的将多个写命令同步到磁盘中;no表示让操作系统来决定应该何时进行同步fsync,Linux系统往往可能30秒才会执行一次
# appendfsync always
appendfsync everysec
# appendfsync no
# 在日志进行BGREWRITEAOF时,如果设置为yes表示新写操作不进行同步fsync,只是暂存在缓冲区里,避免造成磁盘IO操作冲突,等重写完成后在写入。redis中默认为no
no-appendfsync-on-rewrite no
# 当前AOF文件大小是上次日志重写时的AOF文件大小两倍时,发生BGREWRITEAOF操作。
auto-aof-rewrite-percentage 100
#当前AOF文件执行BGREWRITEAOF命令的最小值,避免刚开始启动Reids时由于文件尺寸较小导致频繁的BGREWRITEAOF。
auto-aof-rewrite-min-size 64mb
# Redis再恢复时,忽略最后一条可能存在问题的指令(因为最后一条指令可能存在问题,比如写一半时突然断电了)
aof-load-truncated yes
#Redis4.0新增RDB-AOF混合持久化格式,在开启了这个功能之后,AOF重写产生的文件将同时包含RDB格式的内容和AOF格式的内容,其中RDB格式的内容用于记录已有的数据,而AOF格式的内存则用于记录最近发生了变化的数据,这样Redis就可以同时兼有RDB持久化和AOF持久化的优点(既能够快速地生成重写文件,也能够在出现问题时,快速地载入数据)。
aof-use-rdb-preamble no
-
AOF rewrite过程
- redis fork一个子进程
- 子进程基于当前内存中的数据开始写入一个新的aof的文件
- 这时新的命令进来,会存在内存中,也会存在旧的aof文件中
- 当新的aof文件写好了,这个过程中的新的命令也会追加到aof里来
- 然后用新日志文件替换掉旧的日志文件
注意:当使用shutdown命令关闭redis服务时,会自动备份一个快照
。
当RDB生成快照时,AOF不会rewrite。反之亦然。
redis如果遇到断电或机器故障问题时怎么办?
答:一般使用持久化加服务器文件(将文件备份到阿里云)备份的方案
二、Redis淘汰策略
LRU:(least recently used)最近最少使用
- 标准的LRU算法:
使用HashMap+双向链表
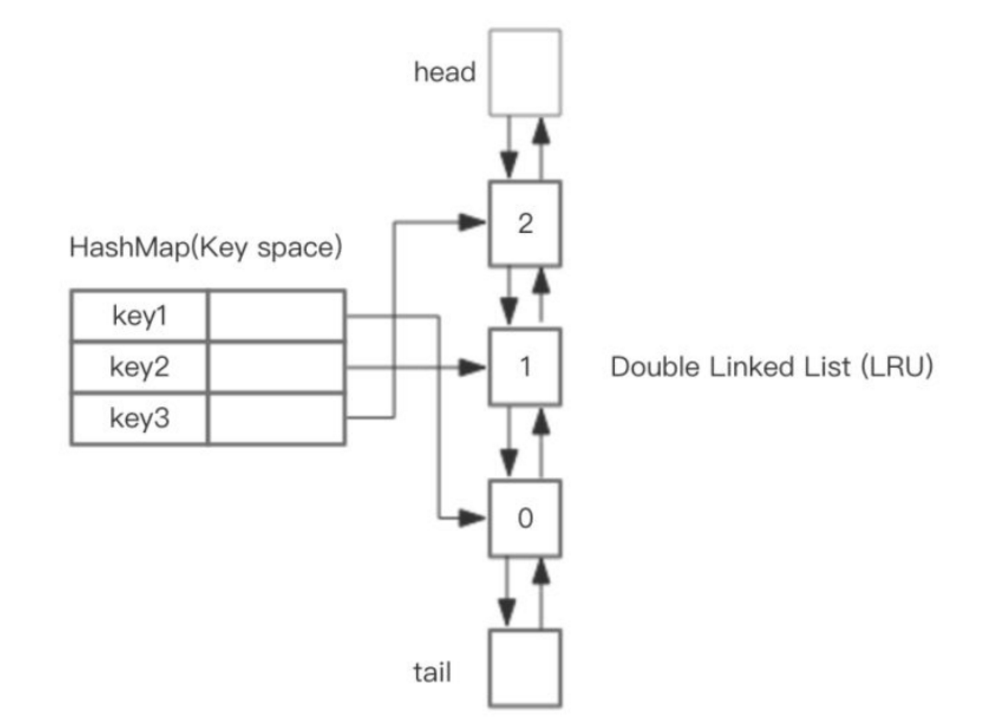
核心步骤:
- save操作时,在hashmap中找对应的key值,如果存在,更新他并移到队头,如果不存在,则构建新节点,并移到队头,如果队列满了,则移除队尾的节点,并在hashmap中移除该key
- get操作时,在hashmap中找到对应的节点,将他移到队头
redis里面没有使用双向链表的实现方式,而是使用了一个pool池.
- Redis的LRU实现
常用策略:allkeys-lru
Redis使用的是近似LRU算法
- 给每个 key 增加一个额外 24bit 长度的小字段, 存储该 key 的最后一次访问时间戳
- 当空间满时, 随机采样取出 5 个 key (数量可配置), 按时间戳淘汰掉最旧的 key
- 循环第二步, 直到内存低于 maxmemory 值
- 随机采样的范围取决于配置的策略是 volatile 还是 allkeys
Redis 3.0 开始, 增加了淘汰池进一步提升了近似 LRU 的效果:
- 上一次随机采样后未淘汰的 key, 会放入 淘汰池 留待下一次循环,
- 下一次随机采样的key会先和淘汰池中的key合并后, 再计算淘汰最旧的key
三、Redis主从架构
1.主从特性
- 采用异步的方式复制到slave节点,不过redis2.8之后,每个slave节点会周期性的确认自己每次复制的数据量
- 一个master可以配置多个slave
- slave node也可以连接其他的slave node
- slave复制时不影响master的工作
- slave复制时也不会影响slave的查询操作,他会用旧的数据提供服务。但是当复制完成,需要删除旧数据,加载新数据集时,会暂停服务。
- slave主要用来做横向扩容,做读写分离
2.主从复制步骤
- 当slave第一次连接时,master会生成一个全量RDB文件给他做恢复,并将这个过程中新的写入命令缓存在内存中,等slave把RDB文件读入之后发给他
- 当slave断开一段时间后重连,master会将缺失的数据发给他
- 平时情况下,master收到一个指令,都会马上复制给slave
3.断点续传
从redis2.8开始,就支持主从复制的断点续传
master中存了backlog,master和slave都会保存一个replica offset,还有一个master id。如果中途网络断了,slave会让master从上次的replica offset开始继续复制。
4.过期key处理
slave不会过期key,只会等master过期key之后或者根据,模LRU淘汰了key之后拟一个del命令发给slave
5.配置主从服务器
- 安装redis
- cp utils/redis_init_script /etc/init.d/redis_6379
- redis自启动 chkconfig redis_6379 on
- mkdir /etc/redis
- mkdir -p /var/redis/6379
- cp redis.conf /etc/redis/6379.conf
- 修改配置文件6379.conf
- daemonize yes //让redis以daemon进程运行
- dir /var/redis/6379
- slaveof CentOS01 6379
- slave 服务器的配置文件上配 masterauth 123456
- master服务器的配置文件上配
requirepass 123456- 每个6379.conf里都要将bind 127.0.0.1改成bind 自己本机的ip
- 让redis跟随系统启动自动启动
在redis_6379脚本中,最上面,加入两行注释
#chkconfig: 2345 90 10
#description: Redis is a persistent key-value database
然后执行
chkconfig redis_6379 on
8. 压测性能 ./redis-benchmark -c 50 -n 10000
复制原理图:

注意:主从架构建议必须开启master节点的持久化。
四、哨兵模式
1.概念介绍
介绍:
- 集群监控,监控master和slave是否正常
- 消息通知,如果某个redis实例故障了,负责发消息给管理员
- 故障转移,如果master节点挂掉了,会自动转移到slave上
- 配置中心,如果故障转移发生了,通知client新的master地址
2.故障转移
哨兵至少要3个实例
如图:

如果只有2个哨兵会如何呢?
master宕机,s1和s2中只要有1个哨兵认为master宕机就可以进行切换,同时s1和s2中会选举出一个哨兵来执行故障转移
同时这个时候,需要majority,也就是大多数哨兵都是运行的,2个哨兵的majority就是2(2的majority=2,3的majority=2,5的majority=3,4的majority=2),2个哨兵都运行着,就可以允许执行故障转移
但是如果整个M1和S1运行的机器宕机了,那么哨兵只有1个了,此时就没有majority来允许执行故障转移,虽然另外一台机器还有一个R1,但是故障转移不会执行
3.解决异步复制和脑裂导致的数据丢失
min-slaves-to-write 1
min-slaves-max-lag 10
要求至少有1个slave,数据复制和同步的延迟不能超过10秒
4.sdown和odown转换机制
sdown:主观宕机,即一个哨兵觉得master宕机了
odown:客观宕机,即quorum数量的哨兵觉得master宕机了
5.哨兵集群的自动发现机制
哨兵互相之间的发现,是通过redis的pub/sub系统实现的,每个哨兵都会往__sentinel__:hello这个channel里发送一个消息,这时候所有其他哨兵都可以消费到这个消息,并感知到其他的哨兵的存在
每隔两秒钟,每个哨兵都会往自己监控的某个master+slaves对应的__sentinel__:hello channel里发送一个消息,内容是自己的host、ip和runid还有对这个master的监控配置
每个哨兵也会去监听自己监控的每个master+slaves对应的__sentinel__:hello channel,然后去感知到同样在监听这个master+slaves的其他哨兵的存在
每个哨兵还会跟其他哨兵交换对master的监控配置,互相进行监控配置的同步
6.选举算法
如果一个master被认为odown了,而且majority哨兵都允许了主备切换,那么某个哨兵就会执行主备切换操作,此时首先要选举一个slave来
会考虑slave的一些信息
(1)跟master断开连接的时长
(2)slave优先级
(3)复制offset
(4)run id
7.部署哨兵
- 复制配置文件
mkdir -p /var/sentinel/5000
mkdir /etc/sentinel
mkdir -p /var/log/sentinal/5000
mv /usr/local/package/redis-4.0.9/sentinel.conf /etc/sentinel/5000.conf
- 修改配置文件
port 5000
bind 192.168.1.14
sentinel monitor mymaster 192.168.1.12 6379 2
dir /var/sentinel/5000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 60000
sentinel down-after-milliseconds mymaster 30000
sentinel auth-pass mymaster 123456
daemonize yes
logfile /var/log/sentinal/5000/sentinel.log
注意:sentinel monitor mymaster 192.168.1.12 6379 2 这行要放在使用mymaster的那些其他配置之前
- 启动哨兵
./redis-sentinel /etc/sentinel/5000.conf
五、redis集群
1.概念介绍
- 自动对数据进行分片,每个master上存放一部分数据
- 提供内置的高可用支持,部分master不可用了,还是可以继续工作的
2.部署选型
redis cluster VS replication + sentinel
当数据量少,主要承载的是高并发时,单机就足够了。一个master多个slave,在搭建一个sentinel集群来保证高可用性
redis cluster主要还是用来做海量数据的缓存。
3.分布式Hash算法
当需要把数据分到不同的几个机器存储时,就需要一个算法了。
- 方法一:取模
对数据的hash值取模,比如有3台集器,那么就用hash%3,得到的就是0-2的三个数字,就可以确定将数据存在哪一台上面了
缺点:如果有一台机器挂掉了,那么数据会对2取模,那么得到的机器号就错乱了,导致大量数据不能从正确的机器上去取
- 方法二:一致性hash算法(圆环算法)
将3台机器放在一个圆环上,然后要缓存的数据经过计算也落在圆环的某一个点,然后顺时针去环上找离他最近的那个机器。
优点:当一台机器挂掉,不影响其他的机器上存的数据
缺点:具有热点问题,可能某一个机器会有大量数据,这就需要将每个机器都多设置几个虚拟节点,均匀分布在圆环上。
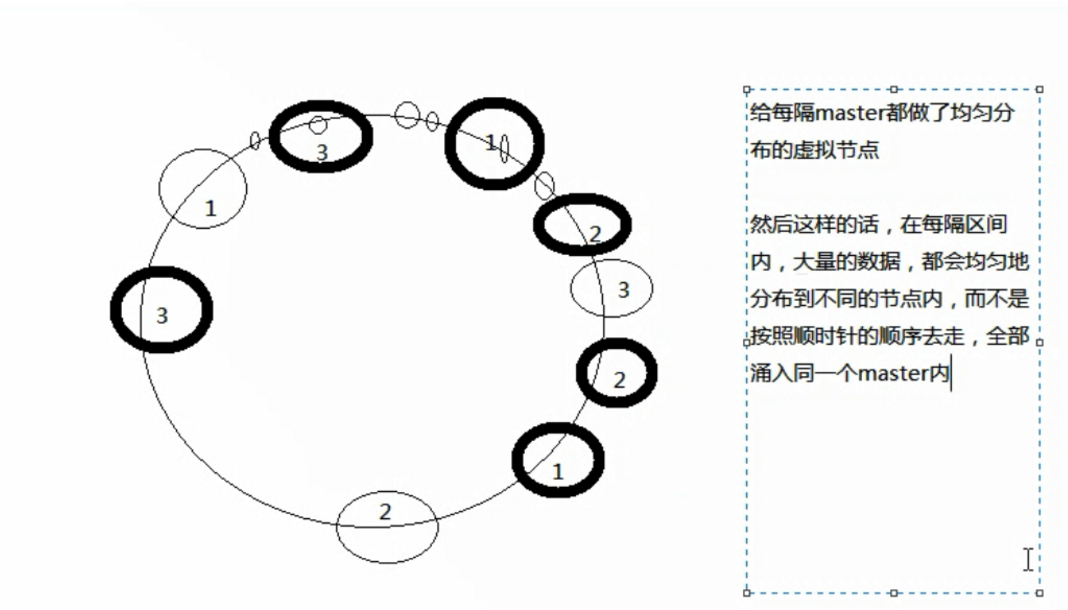
- 方法三:redis cluster的hash slot算法
redis cluster有固定的16384个slot,对每个key计算CRC16值,然后对16384取模,获取对应的slot,每个master都有部分的slot。这样的话如果增加一个master,就将其他master上的slot分点给她就行了。
4.部署redis集群
- 创建目录
mkdir -p /etc/redis-cluster
mkdir -p /var/log/redis
mkdir /var/redis/7001
mkdir /var/redis/7002
- 修改配置文件 7001.conf
port 7001
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7001.conf
cluster-node-timeout 15000
pidfile "/var/run/redis_7001.pid"
dir "/var/redis/7001"
logfile "/var/log/redis/7001.log"
- 修改配置文件
vi /usr/local/share/gems/gems/redis-3.2.1/lib/redis/client.rb
password=123456
- 执行
echo never > /sys/kernel/mm/transparent_hugepage/enabled
- 启动脚本
cd /etc/init.d/
cp redis_6379 redis_7001
修改redis_7001配置
REDISPORT=7001
- 安装ruby
yum install -y ruby
下载一个redis-3.2.1.gem,然后执行
gem install redis
cp /usr/local/package/redis-4.0.9/src/redis-trib.rb /usr/local/bin
/usr/local/bin/redis-trib.rb create --replicas 1 192.168.1.12:7001 192.168.1.12:7002 192.168.1.13:7003 192.168.1.13:7004 192.168.1.14:7005 192.168.1.14:7006
- 检查节点状态
./redis-trib.rb check 192.168.1.12 7001
