高性能Mysql阅读笔记
一、Mysql架构和历史
略
二、Mysql基准测试
略
三、服务器性能剖析
- 使用new relic工具可以进行sql性能剖析
- 慢查询首先要确认是单条查询的问题还是服务器的问题。
- 性能的优化应该是基于高质量全方位的响应时间测量
四、Schema和数据类型优化
- 更小的通常更好,他们占用更小的内存、磁盘等
- 简单就好 例如整型比字符串操作代价就更低
- 尽量避免null 查询中包含null的列,对mysql来说更难优化,null的列使得索引和索引统计和值比较都更复杂。如果计划建索引,就应该避免设计为可为null的列
- mysql可以为整型指定宽度。例如int(11),但是对于应用来说是没有意义的,他不限制值的合法范围,只是规定了mysql的交互显示工具显示字符的个数而已,对于存储来说,int(1)和int(20)是相同的。
- 只有对小数进行精确计算时才使用decimal,但是这样需要额外的开销。如果数据量比较大的时候,可以考虑bigint代替decimal,将需要存储的值根据小数位乘以相应的倍数即可。
- varchar varchar类型用于存储可变长字符串,他比定长的更节省空间。
- char类型是定长的,适合存储很短的或者所有值都接近同一个长度的值,对于经常变更的数据,char比varchar更好,不易产生碎片。另外对于非常短的列,char也比varchar好,比如性别。char(1)需要一个字节,但是varchar(1)却需要两个,因为还有一个记录长度的额外字节
- datetime和timestamp的区别。除了特殊行为外我们应该使用timestamp,因为它空间效率更高。
- datetime能表示的值:1001到9999年,精度为秒,封装到YYYYMMDDHHMMSS的整数中,与时区无关。
- timestamp类型保存了从1970年1月1日以来的秒数,它和UNIX时间戳相同。timestamp只使用4个字节存储,只能表示1970年到2038年。
- 应该使用无符号整数存储ip,使用函数可以转换。
SELECT INET_ATON('192.168.1.1')
SELECT INET_NTOA(3232235777)
五、创建高性能的索引
- 索引的优点
- 减少扫描的数据量
- 可以帮助服务器避免排序和临时表
- 将随机I/O变成顺序IO
- 查询中应使用独立的列,否则mysql不会使用索引。
例如以下错误示例:
select actor_id from actor where actor_id+1=5
- 表film_actor在film_id和actor_id上各有一个单列索引。在mysql老版本中,mysql会使用全表查询
select * from film_actor where film_id =1 or actor_id =1
除非改成
select * from film_actor where film_id =1 union all actor_id =1 and film_id <> 1
在mysql5.0和更新的版本中,查询能够同时使用这两个单列索引进行扫描,并将结果进行合并
- 聚集索引 聚集索引并不是一个单独的索引类型,而是一种数据存储实现方式。具体细节依赖于其实现方式,但InnoDB的聚集索引实际上是在同一个结构中保存了索引和数据行。
InnoDb使用UUID作为主键值的缺点:
- 写入的目标页可能已经刷到磁盘上并从缓存中删除,或是还没有加入到缓存中,Innodb在插入之前不得不先找到并从磁盘读取目标页到缓存中,导致了大量的随机IO。
- 因为写入是乱序的,InnoDB不得不频繁的做页分裂操作
- 由于频繁的页分裂,页会变得稀疏并被不规则的填充,导致数据有碎片。
- 使用索引扫描来做排序
- 当索引的列顺序和order by子句的顺序完全一致,并且所有列的排序方向都一样时,mysql才能使用索引来对结果做排序。
- 冗余索引和重复索引
- 如果创建了索引(A、B),又创建了索引(A)就是冗余索引,因为A是前一个索引的前缀索引。
- 未使用的索引 建议用工具排查然后删除
- 当建立了(sex、country)列作为索引,如果不需要过滤性别(sex),那么就用不到索引,但是我们可以使用sex in('男','女')的方法使他使用到索引。
- 尽可能将范围查询的列放在索引的后面,以便优化器能使用尽可能多的索引列。
- 避免多个范围条件 如下
where sex in('M','F') and last_online > DATE_SUB(NOW(),INTERVAL 7 DAY) and age between 18 and 25
他有两个范围条件,last_online和age,mysql可以使用last_online列索引或者age列索引,但无法同时使用他们。
- 优化排序
select * from profiles where sex='m' order by rating limit 10
这个查询同时使用了order by 和limit,如果没有索引会很慢。即使有索引,当翻页到很后面的时候也会很慢。如:
select * from profiles where sex='m' order by rating limit 100000,10
解决方法1:限制用户能够翻页的数量
解决方法2:通过覆盖索引返回需要的主键,再根据主键取查询所需要的数据
select * from profiles inner join (select id from profiles where x.sex='m' order by rating limit 10000,10) as x USING (id);
六、查询性能优化
- 是否向数据库请求了不需要的数据
- 查询不需要的记录
- 多表关联时返回全部列
- 重复查询相同的数据
- 扫描行数的问题
select actor_id,count(*) from film_actor group by actor_id
这个查询需要读取几千行数据,但是仅返回200行。没有什么索引可以让这样的查询减少扫描的行数
- 使用索引覆盖扫描,把需要的列都放在索引里
- 改变表结构。例如:单独的汇总表
- 重写这个复杂的查询
- 一个复杂查询还是多个简单查询
mysql对于连接和断开连接都是很轻量的,而且现在网络速度比以前要快很多。在一个通用服务器上,每秒能运行超过10万的查询,千兆网卡也可以支持每秒2000次的查询。所以拆成多个简单查询是没问题的,但是如果一个查询能够胜任时还写成多个独立查询是不明智的。
4. 切分查询
如删除数据,如果用一个大语句一次性完成,可能会一次性锁住很多数据,占用系统资源,阻塞查询。所以可以拆分为多个小的语句来处理。
5. 分解关联查询

分解查询的优势:
- 让缓存的效率更高
- 将查询分解后,执行单个查询可以减少锁的竞争
- 在应用层做关联可以更容易对数据库进行拆分
- 查询本身的效率会提升,这个例子中使用IN()代替关联查询,让mysql按照id顺序进行查询,比随机关联更高效
- 可以减少冗余数据查询,在应用层做关联,意味着某条记录应用只需要查询一次,而在数据库关联,可能会重复地访问一部分数据。
- 更进一步,这样做相当于在应用中实现了哈希关联,而不是使用mysql的嵌套循环。
- 查询执行的基础
查询执行的路径
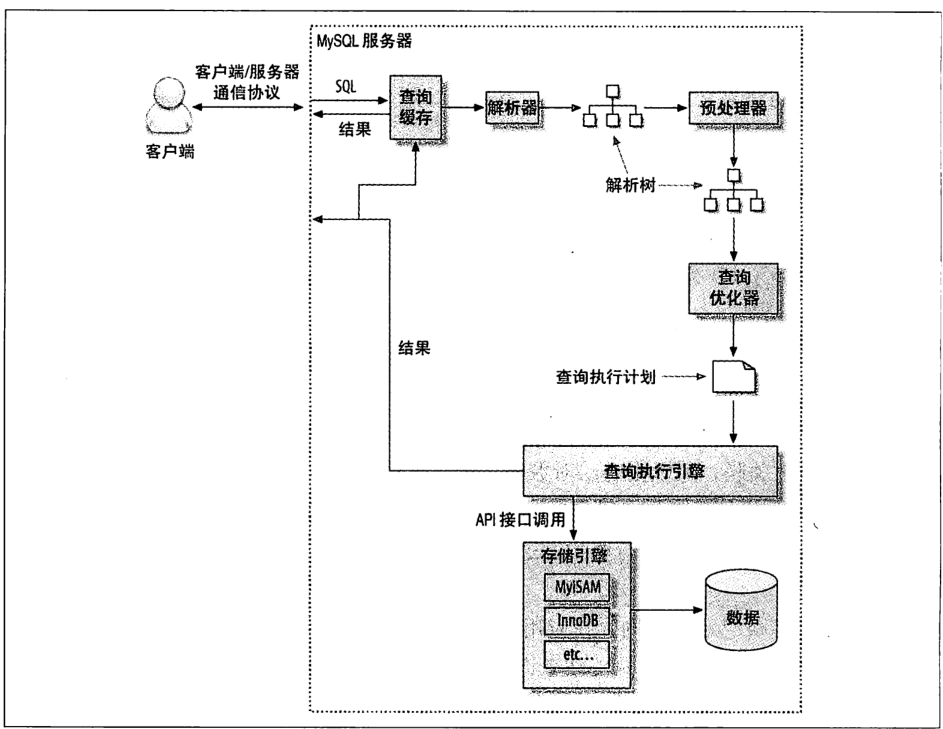
- Mysql客户端/服务端通信协议
Mysql客户端和服务端之间的协议是"半双工"的,这意味着任何一个时刻,要么是由服务器向客户端发送数据,要么是由客户端向服务端发送数据,这两个动作不能同时发生。这样的一个明显的限制是一旦一端开始发生消息,另一端要接收完整个消息才能响应它。
8. 查询优化器
可以通过Last_query_cost的值得知Mysql计算的当前查询的成本。
SELECT SQL_NO_CACHE COUNT(*) FROM trade_order;
SHOW STATUS LIKE 'Last_query_cost';
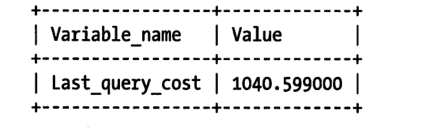
这样的结果是认为1040个数据页的随机查找才能完成以上的查询。
有如下原因导致Mysql选择错误的执行计划,如下所示:
- 统计信息不准确
- 执行计划中的成本估算不等同于实际执行的成本
- Mysql的最优可能跟你想的不一样。你可能希望执行时间最短,但是Mysql只是基于成本模型选择最优的执行计划
- Mysql不考虑其他并发执行的查询
- Mysql不是任何时候都基于成本的优化,有时有一些固定规则。例如:存在全文搜索的MATCH()子句,则存在全文索引的时候就使用全文索引。即使有时候使用其他索引更快
- Mysql不会考虑不受其控制的操作的成本,例如执行存储过程或者用户自定义函数的成本
- 优化器有时候无法估算所有可能的执行计划
- 查询优化的类型
- 重新定义关联表的顺序
- 将外连接转化为内连接 并不是所有的OUTER JOIN都必须以外连接的方式执行。有时因为库表结构外连接等价于内连接,mysql能够识别到并重写查询
- 使用等价变换规则 如:(5=5 and a>5)等价与a>5
- 优化COUNT(),MIN(),MAX() 例如要找到某一列的最小值,只需要找到对应B Tree索引最左端的记录。
- 预估并转化为常数表达式
- 覆盖索引扫描
- 子查询优化
- 提前终止查询 如:使用了limit子句的时候
- 等值传播
select film.film_id from film inner join film_actor using(film_id) where film.film_id>500
mysql知道这个>500不仅适用于film表还适用于film_actor表,它会自动取优化,没必要这样写,反而更难维护
select film.film_id from film inner join film_actor using(film_id) where film.film_id>500 and film_actor.film_id>500
- 列表IN()的比较
在很多数据库中,IN()完全等同于多个OR条件的子句。但是Mysql中不一样,Mysql会将IN()列表中的数据先排序,然后通过二分查找的方式确定列表中的值是否满足条件。这是O(log n),而OR条件是O(n)
- Mysql如何执行关联查询
Mysql对任何关联都执行嵌套循环关联操作,即Mysql先在一个表中取出单条数据,再嵌套循环到下一个表寻找匹配的行。依次下去,直到找出所有的行为止
11. 关联查询优化器
可以优化关联表的顺序
12. 排序优化
排序是一个成本很高的操作,尽可能避免排序或尽可能避免大量数据的排序。如果不能使用索引排序,就需要mysql自己排序,数据量小则在内存中进行,大的话则需要使用磁盘。先读取查询所需要的所有列,然后根据给定列进行排序,最后返回排序结果。
关联查询的时候,如果排序的所有列都来自一个表,那么在处理这个表时会先进行排序。Explain 的Extra字段会有"Using filesort" 除此之外的情况,Mysql会将关联查询后的结果放在临时表里,然后进行排序。
13. 返回结果给客户端
查询执行的最后一个阶段是将结果返回给客户端。如果查询可以被缓存,那么Mysql在这个阶段放结果到缓存中。Mysql将结果集返回客户端是一个增量、逐步返回的过程。这样优点是服务端无须存储太多的结果,另外客户端可以在第一时间收到返回结果。
结果中的每一行都会以满足Mysql通信协议的封包发送,在通过TCP协议进行传输。
14. 关联子查询优化
select * from film where film_id in(select film_id from film_actor where actor_id=1)
Mysql有时不会先查询in里面的结果,会将外层表压到子查询中。所以我们可以这样改写:
select film.* from film inner join film_actor USING(film_id) where actor_id=1
另一种优化方法:
select * from film where exists(select * from film_actor where actor_id=1 and film_actor.film_id=film.film_id)
不同的案例会有不同,有时用子查询也很快。我们应该通过测试来确定。
-
UNION的限制

-
等值传递
有些时候等值传递会带来一些意想不到的额外损耗。例如有一个非常大的IN()列表,而mysql优化器发现存在Where、ON或者USING的子句,将这个列表的值跟另一个表的某个列相关联。
17. 并行执行 Mysql无法利用多核特性进行并行执行。
18. 在同一个表上查询和更新
Mysql不允许在同一个表进行查询和更新
update tb1 as outer_tb1 set cnt=(select count(*) from tb1 as inner_tb1 where inner_tb1.type=outer_tb1.type);
可以通过生成表的形式来绕过上面的限制。
update tb1 inner join (select type,count(*) as cnt from tb1 group by type) as der using(type) set tb1.cnt=der.cnt
- 优化COUNT()函数
count()函数是一个特殊函数,可以统计列的数量也可以统计行的数量。我们在使用count()的时候,这种情况通配符不会扩展成所有的列,实际上他会忽略所有的列直接统计所有行数。所以,统计行数最好使用count(*),意义清晰,性能也会很好。
如果在count函数中指定了列值,则统计的就是这个列有值的结果数。
19.1 简单的优化
例1:
有时候可以使用MyISAM在count(*)全表非常快的特性,来加快一些特定条件的count()查询。
比如要查找id>5的城市,我们可以条件反转。以减少扫描的条数
select count(*) from city >5;
select (select count(*) from city) -count(*) from city where id<=5;
例2:在同一个查询中统计同一列不同值的数量
查询不同颜色的商品数量,有以下两种写法:
select sum(if(color='blue',1,0)) as blue,sum(if(color='red',1,0)) as red from items;
select count(color ='blue' or null) as blue,count(color='red' or null) as red from items;
19.2 使用近似值
有的业务不需要准确的值的时候,可以使用近似值,explain 出来的优化器估算行数就是不错的近似值,执行explain不会真正的去执行查询,所以成本很低。
19.3 使用缓存或汇总表
- 优化关联查询
特别注意:
- 确保ON或者USING子句中的列上有索引。当表A和B用列c关联,如果优化器的关联顺序是B、A,那么就不需要在B表的对应列上建立索引。除非其他理由,则只需要在关联顺序的第二个表的对应列上建立索引。
- 确保group by和order by中的表达式只涉及一个表中的列,这样Mysql才有可能用索引优化这个过程
- 升级Mysql的时候需要注意:关联语法、运算符优先级等可能会发生变化的地方。
- 优化Group by和Distinct
在很多场景下,Mysql都使用同样的办法优化这两种查询。Mysql优化器会在内部处理的时候相互转化这两类查询。他们都可以使用索引来优化。
在Mysql中,当无法使用索引的时候,Group by使用两种策略来完成:使用临时表或者文件排序来做分组。
如果需要对关联查询分组,那么通常采用查找表的标识列分组效率会比较高。
反例:
select actor.first_name,actor.last_name,count(*) from film_actor inner join actor using(actor_id) group by actor.first_name,actor.last_name
正例:
select first_name,last_name,count(*) from film_actor inner join actor using(actor_id) group by actor.actor_id
这个查询利用了id和演员姓名的直接相关的特点,因此改写后结果不受影响,但显然不是所有的关联语句分组查询都可以改写成非分组列的形式。
在使用group by的时候如果后面不跟order by,他会根据分组列的字段进行排序。如果不需要排序可以加个order by null.
- 优化limit分页
在系统需要分页的时候,我们通常用limit实现,同时加上合适的order by语句,如果有对应的索引,效率通常还不错。
但是如果偏移量非常大的时候,例如limit 10000,20。这时mysql需要查询10020条记录,然后返回最后20条,这样的代价非常高。
解决方法:
- 限制分页数量
- 优化大偏移量的查询
考虑改写下面的查询:
select film_id,description from film order by title limit 50,5;
先获取需要访问的记录再根据关联列去查询
select film.film_id,film.description from film inner join(select film_id from film order by title limit 50,5) as lim using(film_id);
- 有时候可以将limit查询转换为已知位置的查询
select film_id,description from film where position between 50 and 54 order by position;
- 书签记录上次读取位置
select * from rental order by rental_id desc limit 20;
假设上面返回的是主键为16049到16030的租借记录,那么下一页查询就可以从16030开始。
select * from rental where rental_id <16030 order by rental_id desc limit 20;
- 优化UNION查询
Mysql总是通过创建并填充临时表的方式执行UNION查询。
- 经常需要手工的把where、limit、order by等子句下推到union的各个子查询去。
- 除非确实需要服务器消除重复的行,否则一定要使用union all,如果不加All的话,Mysql会给临时表加Distinct选项,这会对整个临时表做唯一性检查,这样做的代价非常高。
- 编写偷懒的UNION查询
下面的查询会在两个地方查询同一个用户,一个主用户表,一个长时间不活跃的用户表。
select id from user where id=123
union all
select id from user_archived where id=123;
上面的查询可以正常工作,但是即使在user表里找到了数据,他还是会去扫描user_archived。
select GREATEST(@found := -1,id) as id,'users' as which_tb1 from users where id=1 union all select id ,'users_archived' from users_archived where id=1 and @found is null union all select 1 ,'reset' from dual where (@found := null) is not null;
在查询的末尾将变量重置为null,保证遍历时不干扰后面的结果。
- 综合案例学习
通常我们要做的不是查询优化,不是库表结构优化,也不是索引优化,实际情况中要面对的是所有这些都搅在一起的情况。
24.1 一个表包含多种类型的记录:未处理记录、已处理记录、正在处理记录等。随着表越来越大和索引深度加深,找到未处理记录就会变慢,可以将已处理记录归档或者移到历史表。
24.2 使用数据库计算两地的经纬度?这类查询耗费cpu资源,且无法使用索引,建议不用数据库来做。
七、Mysql高级特性
- 外键操作
如果想确保两个表始终有一致的数据,那么使用外键比在应用程序中检查一致性性能高得多。如果只是使用外键做约束,通常在应用程序里实现约束会比较好。外键会带来很大的额外消耗。
2. 分布式(XA)事务
Mysql在5.0之后开始支持XA事务了。实际上,在Mysql中有两种XA事务了。
- 内部XA事务
Mysql中各个存储引擎是完全独立的,彼此不知道对方的存在。所以一个跨存储引擎的事务就需要一个外部的协调者。如果不使用XA协议,就会破坏事务的特性。即使是同一个存储引擎,他在提交的时候还需要将提交信息写入二进制日志,这也是一个分布式事务。
-外部XA事务
Mysql能够作为参与者完成一个外部的分布式事务。但他对XA协议支持并不完整。而且很耗费性能,只有在Mysql性能不是瓶颈的时候可以尝试使用。
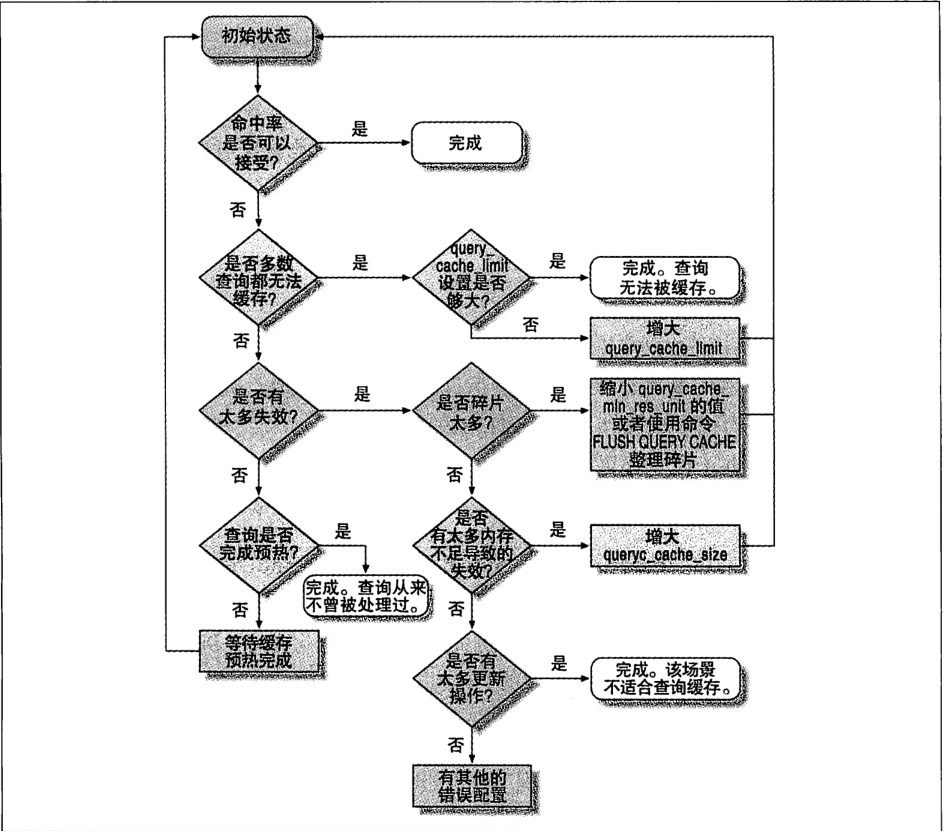
3. 查询缓存
很多数据库产品能够缓存查询的执行计划,相同类型的sql就可以跳过sql解析和执行计划生成阶段。
- 3.1 Mysql如何判断缓存命中
Mysql会根据sql语句和客户端发送过来的其他原始信息去判断,任何的字符上的不同,注释、空格都会导致缓存不命中。如何查询之中包含任何不确定的函数,那么查询缓存之中是不可能找到缓存的。
- 3.2 如何配置和维护缓存
query_cache_type 是否打开查询缓存
query_cache_size 查询缓存使用的总字节空间。
query_cache_min_res_unit 查询缓存中分配内存块时的最小单位
query_cache_limit mysql能够缓存的最大查询结果
八、优化服务器设置
- 查看mysql安装位置
which mysqld
- 查看系统变量
show global variables
- 不建议使用调优脚本。
九、操作系统和硬件优化
- 什么限制了Mysql性能?
CPU、IO、网络带宽
后面内容略

