Hadoop最简单入门实战
一、部署Hadoop本地模式
- 搭建linux环境
我用的centos7 - 在/opt目录下创建目录
mkdir module
- 安装jdk
- 下载hadoop https://hadoop.apache.org/releases.html 并解压到/opt/module目录
- 配置hadoop环境变量
vi /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_151
HADOOP_HOME=/opt/module/hadoop-2.10.0
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin
export JAVA_HOME CLASSPATH PATH
配置完毕,刷新
source /etc/profile
这就安装完毕了,简单吧。。。
二、运行Demo
- 建立一个测试用的输入文件
echo 'hadoop mapreduce hivehbase spark stormsqoop hadoop hivespark' > data/wc.input
- 运行命令
官方提供的计算单词数量的程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount ../data/wc.input output
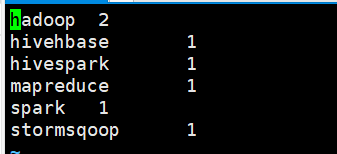
- 运行完成后,会创建一个output目录,里面中有 _SUCCESS 文件说明 JOB 运行成功,part-r-00000 是输出结果文件。结果示例如下:
三、伪分布式部署
进入hadoop目录
cd /opt/module/hadoop-2.10.0/etc/hadoop
- 配置hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_151
- 配置core-site.xml
<configuration>
<!-- 指定HDFS中namenode的路径 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://eshop01:9000</value>
</property>
<!-- 指定HDFS运行时产生的文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.10.0/data/tmp</value>
</property>
</configuration>
- 配置hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
- 启动集群
- 格式化NameNode(第一次启动格式化)
bin/hdfs namenode -format
- 启动namenode
sbin/hadoop-daemon.sh start namenode
- 启动datanode
sbin/hadoop-daemon.sh start datanode
- 输入地址: http://192.168.1.21(虚拟机ip):50070/ 查看启动效果
四、HDFS操作
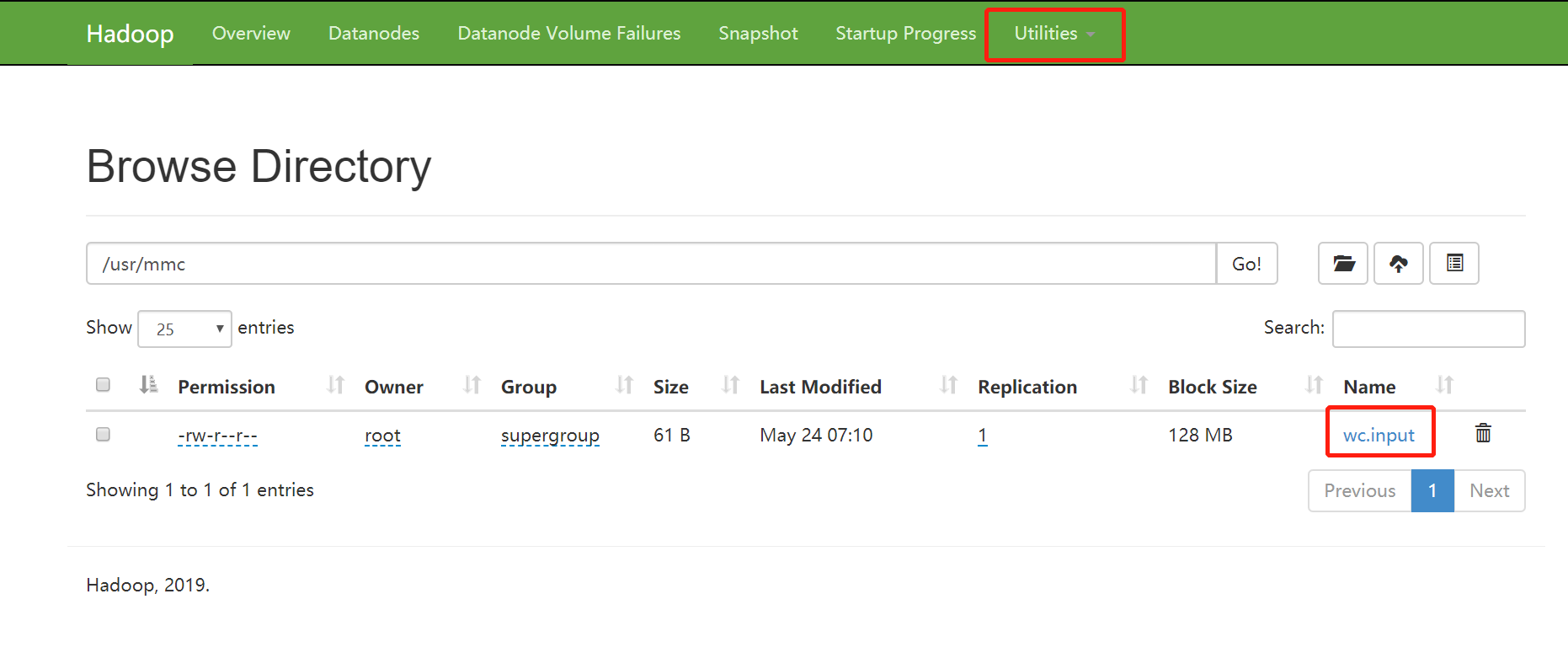
- hdfs创建目录
bin/hdfs dfs -mkdir -p /usr/mmc
- 上传本地文件到hdfs
bin/hdfs dfs -put /opt/module/data/wc.input /usr/mmc
- 删除文件
bin/hdfs dfs -rm -r /usr/mmc
网页上查看效果:
五、启动YARN
- 配置yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_151
- 配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
</configuration>
hadoop101那里要配置为你虚拟机的hostname
- 配置mapred-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_151
- 配置mapred-site.xml(由mapred-site.xml.template重命名得到)
mv mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 启动yarn
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
- 运行mapreduce程序
- 先传一个文件到hdfs上
hdfs dfs -mkdir -p /usr/mmc/input
hdfs dfs -put ../data/wc.input /usr/mmc/input
- 运行程序
注意:运行之前用jps查看下,这些都启动没有NameNode、NodeManager 、DataNode、ResourceManager
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount /usr/mmc/input /usr/mmc/output
- 查看运行进度
http://192.168.1.21:8088/cluster
此时可以看到执行的进度了,但是那个History链接还是点不动,需要启动历史服务器

- 配置历史服务器
- 打开mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>eshop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>eshop01:19888</value>
</property>
</configuration>
- 启动
sbin/mr-jobhistory-daemon.sh start historyserver
六、日志聚集
注意:开启日志聚集需要重启Nodemanager,resourcemanager,historymanager
- 配置yarn-site.xml,增加如下配置
<!--开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
-
启动Nodemanager,resourcemanager,historymanager
-
运行实例程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount /usr/mmc/input /usr/mmc/output
- 查看log
http://192.168.1.21:19888/jobhistory 点击指定job进去,点log

