
JAVA线程池
线程池
为什么采用线程池
在Java中创建线程看着就像创建一个对象,继承Thread或者实现Runnable接口都可以实现,但其实并不是那么简单,创建对象需要JVM分配内存空间,而创建线程则需要调用操作系统API来实现,同时操作系统还需要分配资源给线程使用,非常的消耗资源同时线程的销毁也是如此,所以线程是一个重量级的对象,应该避免经常性的创建和销毁。
所以这时候就需要用到线程池这个概念,池化思想在很多中间件都有使用数据库连接池,常量池等等,池化思想的主要目的就是复用,减少资源的重复创建。
提到池化思想,大多数池化思想都是先向资源池acquire申请资源,使用完毕后release释放资源
// 资源池
class XXXPool{
// 获取资源池中的资源
XXX acquire() {
}
// 释放资源
void release(XXX x){
}
}
按照这种思想,线程池的使用应该是如下逻辑,但是很明显Thread没有这种用法
ThreadPool pool;
Thread T1=pool.acquire();
// 传入Runnable对象
T1.execute(()->{
// 省略业务逻辑
});
JAVA实现池化思想
java采用的池化思想实现方式其实是生产者-消费者模式,其中生产者是线程池的使用方,消费者是线程池本身,实现原理如下。
public class Test {
public static void main(String[] args) {
ArrayBlockingQueue blockingQueue = new ArrayBlockingQueue<>(2);
MyThreadPool myThreadPool = new MyThreadPool(10,blockingQueue);
myThreadPool.execute(()->{
System.out.println("test");
});
}
}
class MyThreadPool{
// 阻塞队列
private BlockingQueue<Runnable> workQueue;
// 保存内部工作线程 线程销毁时使用这里是占个坑位
List<WorkerThread> threads = new ArrayList<>();
// 构造方法
public MyThreadPool(int poolSize,BlockingQueue<Runnable> workQueue){
this.workQueue = workQueue;
for (int i = 0; i <poolSize ; i++) {
WorkerThread workerThread = new WorkerThread();
workerThread.start();
threads.add(workerThread);
}
}
// 提交任务 就是简单的入队到阻塞队列中
public void execute(Runnable command){
try {
workQueue.put(command);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
class WorkerThread extends Thread{
@Override
public void run() {
//循环取任务并执行
while(true){
Runnable task = null;
try {
task = workQueue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
task.run();
}
}
}
}
MyThreadPool是自定义的线程池,内部保存属性阻塞队列workQueue,工作线程集合threads(在这里无它用,在线程销毁时会使用),线程池构造方法内部构造poolSize个线程,同时启动线程,线程的run方法都是去阻塞队列中出队(在没有执行execute方法前阻塞队列都是空,所以都会阻塞),调用execute提交任务,就是入队到阻塞队列中,所有的线程就能自动竞争获取任务执行task.run()方法。
线程池创建
线程池的创建主要依赖ThreadPoolExecutor方法,这个方法配置了七个常用参数,说明如下
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {}
- corePoolSize 核心线程数,线程池保留的最少线程数,就算线程空闲也不会回收。
- maximumPoolSize 最大线程数,线程池在超过核心线程数后,需要扩充,但是不能无限制的扩充最大值就是maximumPoolSize,当线程空闲下来又将扩充的线程回收。
- keepAliveTime & unit 线程存活时间和单位
- workQueue 工作队列。
- threadFactory 线程工厂,可以自定义如何创建线程,例如你可以给线程指定一个有意义的名字。
- handler 阻塞策略,当请求线程数超过(最大线程数+工作队列数)之和后,线程池采用什么策略处理请求的线程。
- AbortPolicy:默认的拒绝策略,会 throws RejectedExecutionException。
- DiscardPolicy:直接丢弃任务,没有任何异常抛出。
- DiscardOldestPolicy:丢弃最老的任务,其实就是把最早进入工作队列的任务丢弃,然后把新任务加入到工作队列。
- CallerRunsPolicy:提交任务的线程自己去执行该任务(哪里来回哪里去)。
ThreadPoolExecutor的构造方法属实有点复杂,对于初学者不太友好,考虑到这点Java并发包提供了静态类Executors
public static ExecutorService newFixedThreadPool(int nThreads)
public static ExecutorService newCachedThreadPool()
public static ExecutorService newSingleThreadExecutor()
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
并发包的静态类Executors虽然好用,但是生产中却并不建议采用Executors创建线程池,还是推荐采用ThreadPoolExecutor
线程池使用的注意点
- 静态类创建线程池,其中任务队列默认采用无界队列LinkedBlockingQueue(没有指定队列大小),生产中容易造成OOM。
- 静态类创建线程池拒绝策略一般采用默认的AbortPolicy,丢弃线程后抛出异常RejectedExecutionException,线程池的调用方无法感知,会导致某些重要业务丢失。
- 通过ThreadPoolExecutor 对象的 execute() 方法提交任务时,如果任务在执行的过程中出现运行时异常,会导致执行任务的线程终止,这时线程池收不到任何异常通知,导致业务异常。
线程池补充点
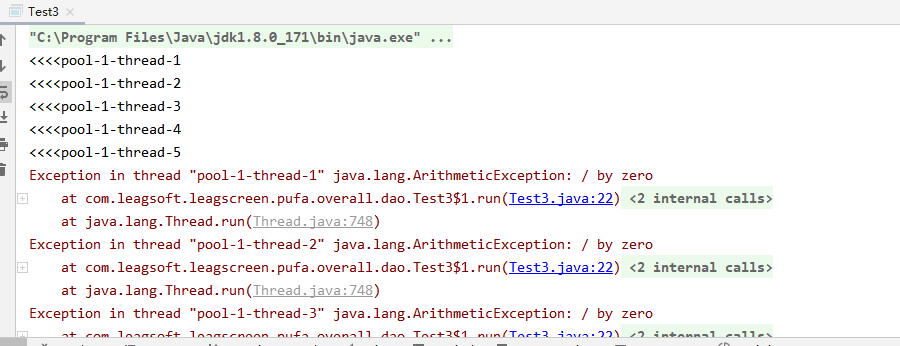
当线程池中的线程执行方法异常时,会重新启动新的线程执行任务。
public class Test3 {
// 线程池初始化时只有一个核心线程
private static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
1,
1,
1,
TimeUnit.SECONDS,
new LinkedBlockingQueue(5),
new ThreadPoolExecutor.AbortPolicy());
// 线程池某个线程执行任务出现异常,线程终止,那么线程池会重新启动一个线程加入线程队列
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println("<<<<" + Thread.currentThread().getName());
int a = 1 / 0;
}
});
}
}
}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~