
并发生产者消费者模式
并发生产者消费者模式
前言引入
并发分工问题可以采用三大模式解决,Thread-Pre-Message模式、Worker Thread模式另外一种就是生产者消费者模式,这种模式的核心其实就是任务队列(阻塞队列),如下所示。
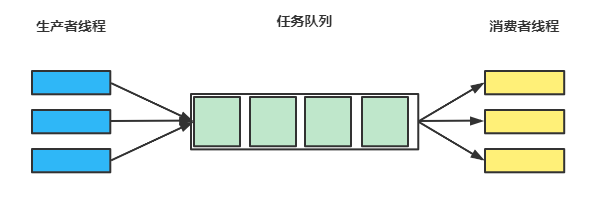
只要涉及到异步编程在生产上我们一般都会使用线程池来执行业务,其实线程池的本质就是生产者消费者模式,不过我们需要注意的是线程池是消费者,调用线程池的线程是生产者,那么这种模式有什么优势呢?
生产者消费者模式优势
生产者消费者模式在Java中的实现就是线程池,那么这有何优势呢?
- 生产者线程池的使用方不再需要同步等待线程执行完毕,只要提交给线程池也就是放入任务队列中就不需要再关心是否线程执行,这就是异步。
- 生产者消费者之间唯一的桥梁只有任务队列,那么这实现了解耦功能。
看到这里不知道大家有没有疑问,生产者消费者通过任务队列实现了异步操作,那么直接创建一个线程(new Thread)不也能实现异步吗?为什么还要通过任务队列去实现异步呢?我们可以如下思考
假设生产者消费者的速度为1:3,也就是相同时间内生产者生产一个任务,消费者就能消费3个任务,这种情况下如果生产者有3个线程,采用直接创建线程的方式那么需要三个消费者线程与之对应,但采用生产者消费者模式的话就只用一个线程就可以搞定,所以在Java语言这种创建线程对象成本较高的环境下,生产者消费者模式无疑是最好的选择,它平衡了生产者消费者间的速度差异。
不过这里有个特殊点,如果Java采用类似OpenJDK的Loom项目提供的轻量级线程Fiber(轻量级线程创建成本极低,线程的创建成本基本上和普通的对象差不多,这种轻量级线程主要应用于Go语言和Lua语言),那么就无需考虑线程创建销毁成本,采用直接创建线程的方式也是可以的。
生产者消费者模式优化性能
生产者消费者模式应用最多的自然是线程池,但是线程池限制了线程每次只能从任务队列中消费一个任务,这对于一些特殊场景反而是对性能的损耗,所以我们需要拓展生产者消费者模式来提升性能。
批量执行拓展
例如现在需要将一批数据大概1000条入库,这些数据不是一次性请求来的,而是断断续续从各个请求中来,现在有两种方案第一种方案是采用线程池,请求来了就将任务提交到线程池一次性插入一条记录,请求多少次就插入多少条,频繁插入数据就需要频繁的建立数据库链接等操作明显十分消耗性能,第二种将这些请求来的数据入队到任务队列中,然后批量入库,这时只需要采用少量的消费者就可以解决性能问题。
原理很简单,角色还是生产者、消费者、任务队列,这个场景生产者是将数据插入数据库的线程,生产者将任务入队到任务队列,而消费者循环消费任务队列中的任务即可。
消费者代码如下
public class TestConsumer {
private BlockingQueue<Task> taskBlockingQueue;
public TestConsumer(BlockingQueue<Task> taskBlockingQueue) {
this.taskBlockingQueue = taskBlockingQueue;
}
// 消费者线程
public void consumerThread(){
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i <5 ; i++) {
executorService.execute(()->{
while (true){
try {
List<Task> tasks = taskPoll();
consumerTask(tasks);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
// 从任务队列中批量出队
public List<Task> taskPoll() throws InterruptedException {
List<Task> list = new ArrayList<>();
// 阻塞式出队 避免不必要的轮询
Task take = taskBlockingQueue.take();
while (take != null){
list.add(take);
// 非阻塞式出队
take = taskBlockingQueue.poll();
}
return list;
}
// 消费批量任务
public void consumerTask(List<Task> list) throws InterruptedException {
System.out.println(Thread.currentThread().getName()+"===开始批量处理==="+list.size());
Thread.sleep(2000);
}
}
/**
* 模拟任务
*/
class Task{
private String name;
public Task(String name) {
this.name = name;
}
@Override
public String toString() {
return "Task{" +
"name='" + name + '\'' +
'}';
}
}
生产者
public static void main(String[] args) throws InterruptedException {
BlockingQueue<Task> blockingQueue = new ArrayBlockingQueue<>(2000);
TestConsumer consumer = new TestConsumer(blockingQueue);
consumer.consumerThread();
for (int i = 0; i <1000 ; i++) {
Task task = new Task(String.valueOf(i));
blockingQueue.put(task);
}
Thread.sleep(12000);
System.out.println("=======二阶段=======");
Task task = new Task(String.valueOf(222));
blockingQueue.put(task);
}
执行结果如下
分阶段提交扩展
假如我们需要自定义一个Logger类想要记录项目中的日志,那么这个日志记录肯定是异步执行,也就是说用字符流写数据时最后刷盘需要异步执行,刷盘规则定义如下:
- Error级别日志需要立即刷盘。
- 存在未刷盘数据,5秒内未刷盘自动刷盘。
- 未刷盘数量超过500条自动刷盘。
有了如上规则那么代码化如下所示
public class Logger {
private BlockingQueue<LogMsg> blockingQueue = new ArrayBlockingQueue<>(2000);
// 记录未刷盘数量
private int noFlush = 0;
public void start() throws IOException {
// 只需要一个线程写入
ExecutorService executorService = Executors.newSingleThreadExecutor();
// 创建临时文件以flush开头.log结尾,文件目录一般在
// C:\Users\登录名\AppData\Local\Temp
File flush = File.createTempFile("flush", ".log");
System.out.println("文件名======"+flush.getName());
FileWriter fileWriter = new FileWriter(flush);
executorService.execute(()->{
try {
// 一定要加时间判断,需要自动落盘
long start = System.currentTimeMillis();
while (true){
LogMsg logmsg = blockingQueue.poll(5, TimeUnit.SECONDS);
// 阻塞队列采用poll 出队有可能logmsg为空
if (logmsg != null){
fileWriter.write(logmsg.toString());
++noFlush;
}
// 不需要落盘
if (noFlush <= 0){
System.out.println("==进行下一次循环===");
continue;
}
// 校验是否符合刷盘条件
if (logmsg != null && LEVEL.ERROR.equals(logmsg.getLevel()) ||
noFlush>=500 ||
System.currentTimeMillis()-start>=5000){
System.out.println("=====准备落盘====");
fileWriter.flush();
System.out.println("=====落盘完成====");
}
}
}catch (Exception e){
e.printStackTrace();
}finally {
try {
System.out.println("=====finally准备落盘====");
fileWriter.flush();
fileWriter.close();
System.out.println("=====finally落盘完成====");
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
// 入队任务队列
public LogMsg putError(String msg) throws InterruptedException {
LogMsg logMsg = new LogMsg(LEVEL.ERROR,msg);
blockingQueue.put(logMsg);
return logMsg;
}
public LogMsg putInfo(String msg) throws InterruptedException {
LogMsg logMsg = new LogMsg(LEVEL.INFO,msg);
blockingQueue.put(logMsg);
return logMsg;
}
}
enum LEVEL{
INFO,ERROR
}
class LogMsg{
private LEVEL level;
private String msg;
// 省略toString get set方法
}
生产者消费者优雅终止方案
生产者消费者的线程终止方案完全可以采用二阶段终止方案实现(interrupt和标志位),但在这个模式下有个更加直观的方案称为毒丸对象,其实就是一个特殊的任务对象当需要停止时将毒丸对象入队,消费者线程读取到毒丸对象后break退出循环,终止当前线程即可,具体实现如下。
public class Logger {
private BlockingQueue<LogMsg> blockingQueue = new ArrayBlockingQueue<>(2000);
// 创建毒丸对象 特殊的日志对象
private LogMsg kill = new LogMsg(LEVEL.ERROR,"");
public void start() throws IOException {
// 只需要一个线程写入
ExecutorService executorService = Executors.newSingleThreadExecutor();
// 省略定义代码
executorService.execute(()->{
try {
while (true){
LogMsg logmsg = blockingQueue.poll(5, TimeUnit.SECONDS);
// 判断任务队列出队对象是否为 毒丸对象
if (kill.equals(logmsg)){
break;
}
}
}finally {
// 关闭线程池
executorService.shutdown();
}
});
}
// 停止线程就是将毒丸对象入队
public void stop() throws InterruptedException {
blockingQueue.put(kill);
}
}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~