
Disruptor一个高性能队列
Disruptor一个高性能队列
前言
说到队列比较熟悉的可能是ArrayBlockingQueue、LinkedBlockingQueue这两个有界队列,大多应用在线程池中使用能保证线程安全,但其安全性都是通过ReentrantLock实现,而锁的效率较低,所以这里引出高性能的Disruptor队列。
Disruptor对速度的把控只能说NB,Disruptor官网也是牛逼哄哄的这样描述
At LMAX we have built an order matching engine, real-time risk management
and a highly available in-memory transaction processing system all on this pattern to great success.
Each of these systems has set new performance standards that, as far as we can tell, are unsurpassed.
译:
在LMAX,我们建立了一个订单匹配引擎,实时风险管理,
一个高可用的内存事务处理系统都在这种模式上取得了巨大的成功。
每一个系统都设定了新的性能标准,据我们所知,这些标准是无与伦比的。
为什么Disruptor性能如此优越呢?这个在Disruptor的项目团队论文有提到
- 内存分配更加合理,使用RingBuffer数据结构,数组元素在初始化时一次性全部创建,提升缓存命中率。对象循环使用,避免频繁GC。
- 能够避免伪共享,提升缓存利用率。
- 采用无锁算法,避免频繁加锁解锁的性能消耗。
- 支持批量消费,消费者可以无锁方式消费多个消息。
Disruptor入门程序
白看不如一练,先跑一个Disruptor程序体验
引入依赖
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.4</version>
</dependency>
入门程序
public class DisruptorDemo {
public static void main(String[] args) throws InterruptedException {
// RingBuffer大小必须要是2的N次方 IllegalArgumentException: bufferSize must be a power of 2
int bufferSize = 2;
// 构建disruptor
Disruptor<Event> disruptor = new Disruptor<>(
Event::new,
bufferSize,
// 守护线程工厂,和线程池中7大参数中的线程池工厂类似
// DaemonThreadFactory implements ThreadFactory
DaemonThreadFactory.INSTANCE);
// 注册事件处理器
disruptor.handleEventsWith((event, sequence, endOfBatch) -> {
System.out.println("E:"+event+"====sequence:"+sequence+"====endOfBatch:"+endOfBatch);
});
// 启动Disruptor
disruptor.start();
// 获取RingBuffer
RingBuffer<Event> ringBuffer = disruptor.getRingBuffer();
// 生产Event 分配缓冲区 单位字节byte
ByteBuffer byteBuffer = ByteBuffer.allocate(8);
for (int i = 0; true ; i++) {
byteBuffer.putLong(0,i);
// 生产者生产消息 发布
ringBuffer.publishEvent((event, sequence, buffer) -> {
event.setValue(buffer.getLong(0));
},byteBuffer);
Thread.sleep(2000);
}
}
}
class Event{
private long value;
public Event(){
System.out.println("创建了");
}
public void setValue(long value){
this.value = value;
}
@Override
public String toString() {
return "Event{" +
"value=" + value +
'}'+"===hashcode="+hashCode();
}
}
运行结果如下
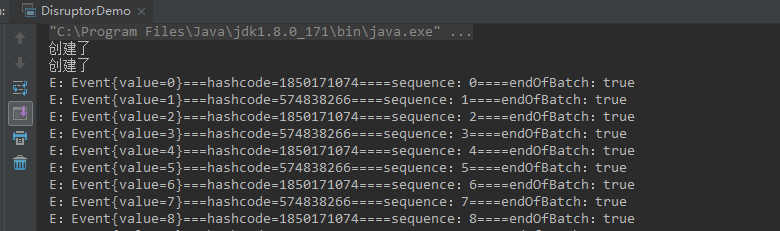
从上诉结果可以得出如下结论
- bufferSize是ringBuffer的大小,定义多大那么程序启动就创建多少个事件对象。
- 生产者发布消息都是沿用初始化的对象,不再重新创建对象,利用set方法改变其属性值。
- bufferSize值必须是2的整数次幂,不然程序会抛出异常(IllegalArgumentException: bufferSize must be a power of 2)。
- 生产者的对象必须要自定义,如上诉代码中的Event。
Disruptor如何提升性能
Disruptor的数据存储底层是RingBuffer,而我们熟知的ArrayBlockingQueue队列底层实现是对象数组,那是不是就是说将ArrayBlockingQueue的底层换成RingBuffer效率就提升了呢?显然并不是这样RingBuffer底层还是由数组构成,但是Disruptor在RingBuffer基础上还做了需要优化,比如内存分配方面,了解这个之前我们需要先了解下程序的局部性原理。
程序的局部性原理
程序的局部性原理指在一段时间内程序的执行会限定在某一个局部范围内,这里的局部性可以分为两种情况
- 时间局部性:程序的某条指令一旦执行,不久之后这条指令很大几率再次执行。
- 空间局部性:某块内存一旦访问,不久之后这块内存的附近内存也会得到访问。
CPU缓存就很好的利用了这个原理,当CPU需要从内存中加载数据X时,会将X周围的数据都加载进入高速缓存中,根据局部性原理,访问X后大概率会访问X周围的值,所以程序利用好这一点就能提升性能,RingBuffer就是这样,我们这里对比ArrayBlockingQueue学习理解。
ArrayBlockingQueue存储
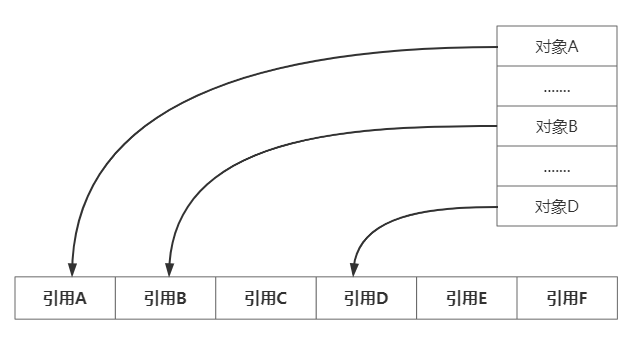
ArrayBlockingQueue底层采用数组存储,但是每次入队都需要创建一个对象入队操作,那么极有可能内存空间不是连续的,一定一定需要注意的是,这里指的不连续是内存空间,并不是指引用地址,因为底层存储的是数组所以引用地址是有序存放。如 下所示
RingBuffer存储
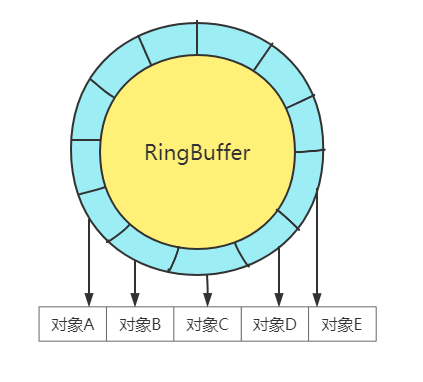
而RingBuffer存储有所不同,虽然和ArrayBlockingQueue本质上都是数组存储,但是RingBuffer采用的是环形数组存储,并且程序启动所有对象就已经创建所以大概率这些对象大概率会分配到同一片内存空间也就是说这些对应存储位置应该满足程序局部性原理中的空间原理,赋值代码如下所示。
// RingBuffer 构造函数调用super父类RingBufferFields构造方法
private void fill(EventFactory<E> eventFactory) {
for(int i = 0; i < this.bufferSize; ++i) {
// RingBuffer的底层实现entries
// eventFactory就是前面示例代码中传入的Event::new 事件对象
this.entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}
RingBuffer结构示意图如下所示
Disruptor如何避免伪共享
什么是伪共享
伪共享其实和CPU内存的Catch有关,Catch是按照缓存行进行存储,一个缓存行的大小为64KB,当CPU从内存中缓存一个数据X时,同时会将X后面的64-size(X)字节的数据同时缓存进Catch中。
以ArrayBlockingQueue队列为例,其内部维护了如下四个属性
/** 数组底层存储元素 */
final Object[] items;
/** 出队索引 */
int takeIndex;
/** 入队索引 */
int putIndex;
/** 队列元素的个数 */
int count;
假设CPU加载takeIndex时就会将putIndex、count的值同时加入Catch中,示例图如下所示
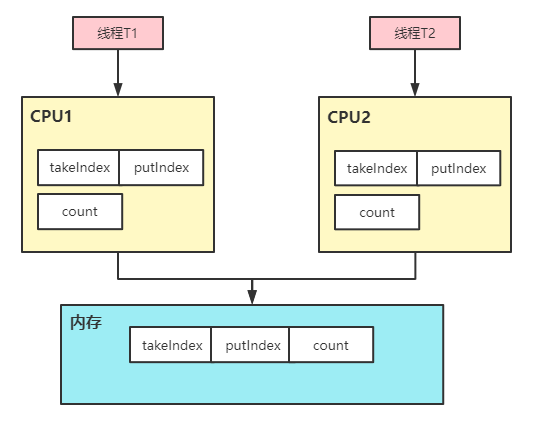
线程T1需要执行入队操作修改putIndex属性,修改后整个缓存行就会失效,这时线程T2执行出队操作需要修改takeIndex,由于缓存行已经失效所以只能从内存中再次读取,但线程T1入队操作并没有修改takeIndex,但是由于takeIndex、putIndex、count存在同一个缓存行,所以修改任意一个都有可能导致缓存行失效,这就是伪共享,简单总结说就是,由于共享缓存行导致缓存失效这就是伪共享。
如何解决伪共享
从伪共享的定义出发,既然是因为缓存行导致的缓存失效也就是入队修改putIndex属性导致takeIndex属性失效,这种场景能不能将两个变量独立成两个缓存行,这样不论哪个失效都不会对另外一个有影响,当然是可以的RingBuffer便是采用的这种思想。
takeIndex是int类型占4个字节,想要takeIndex独立一行那么就要前后填充60个字节才能保证takeIndex占用独立一行,RingBuffer中数组对象也是采用这种方式填充如下所示
// 前:long类型占8个字节填充56个字节
class LhsPadding {
protected long p1,p2,p3,p4,p5,p6,p7;
}
class Value extends LhsPadding {
protected volatile long value;
}
// 后:添加56个字节
class RhsPadding extends Value {
protected long p9,p10,p11,p12,p13,p14,p15;
}
public class Sequence extends RhsPadding {
}
Disruptor无锁方案
ArrayBlockingQueue采用的是Lock+Condition的结合解决线程安全问题,但是效率太低,Disruptor利用简单的自旋+CAS实现线程安全,虽然实现逻辑比ArrayBlockingQueue来的复杂,不过还是生产消费两大逻辑,因为底层是环形数组所以需要注意两点
- 入队需要保证不能覆盖没有消费的元素。
- 出队需要保证不能读取没有生产的元素。
所以Disruptor肯定会去维护出队索引和入队索引,但是这里需要保证多个消费者同时消费,所以RingBuffer只需要维护入队索引即可,每个消费者会维护一个出队索引,所以RingBuffer只需要取其中最小的一个即可。
入队核心代码如下所示
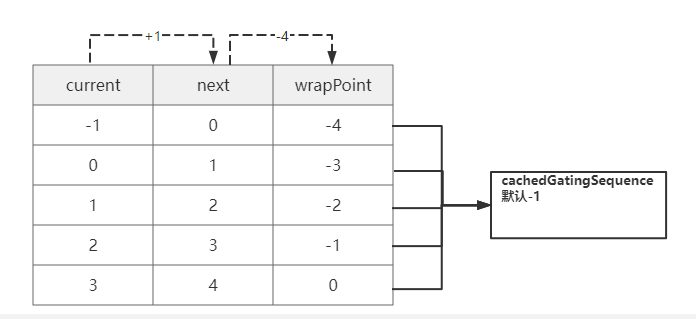
do{
// cursor类似于入队索引,指的是上次生产到这里
current = cursor.get();
// n一般入队一个就是1 next下次访问的数组坐标
next = current + n;
// bufferSize:环形数组的大小
long wrapPoint = next - bufferSize;
// 获取上一次的最小消费位置
long cachedGatingSequence = gatingSequenceCache.get();
// 条件1:生产一圈又达到消费者消费的最小位置,继续生产将会覆盖还未消费的消息
// 条件2:最小消费位置大于生产者当前生产位置,说明消费者消费到了生产者还未生产的消息位置
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
// 获取最慢的消费者的位置
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
// 表示生产者从后面追过消费者,这个是不允许的。这里等待1纳秒,再重新开始
if (wrapPoint > gatingSequence)
{
LockSupport.parkNanos( 1 );
continue ;
}
gatingSequenceCache.set(gatingSequence);
}
// 生产者可以正常去抢位置,compareAndSet不能保证一定成功,所以
// 可以看到 while (true),其实是会不断去尝试,直到成功.
else if (cursor.compareAndSet(current, next)){
break ;
}
} while ( true );
假设bufferSize环形数据的大小为4,n为1每次添加一个元素,消费者cachedGatingSequence默认-1并没有消费可以得到如下图,结合代码理解



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~