谷粒商城分布式高级(二)—— ElasticSearch全文检索
一、ElasticSearch-全文检索
1、简介
https://www.elastic.co/cn/what-is/elasticsearch 全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。 它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它
2、基本概念
1、Index(索引)
动词,相当于 MySQL 中的 insert;
名词,相当于 MySQL 中的 Database
2、Type(类型)
在 Index(索引)中,可以定义一个或多个类型。
类似于 MySQL 中的 Table;每一种类型的数据放在一起;
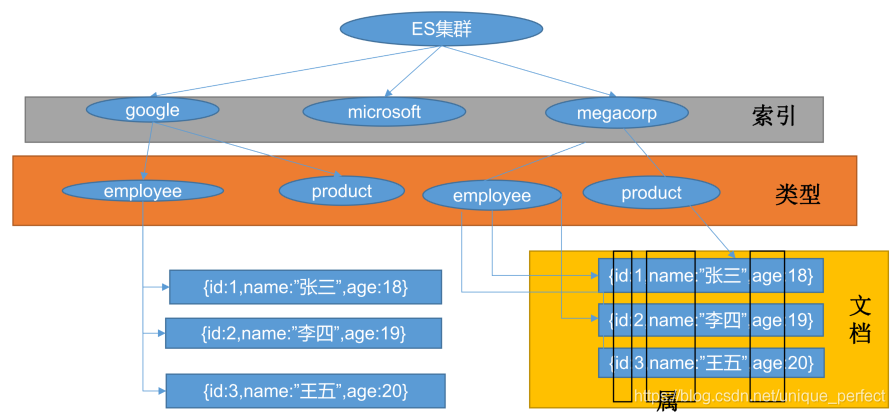
3、Document(文档)
保存在某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是 JSON 格 式的,
Document 就像是 MySQL 中的某个 Table 里面的内容;
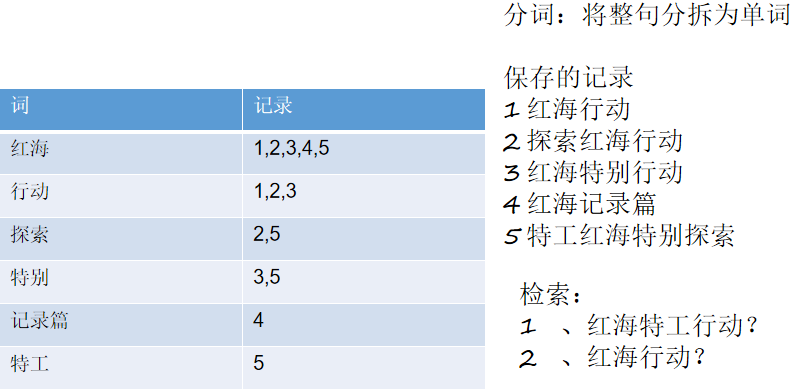
4、倒排索引机制
3、Docker 安装 Es
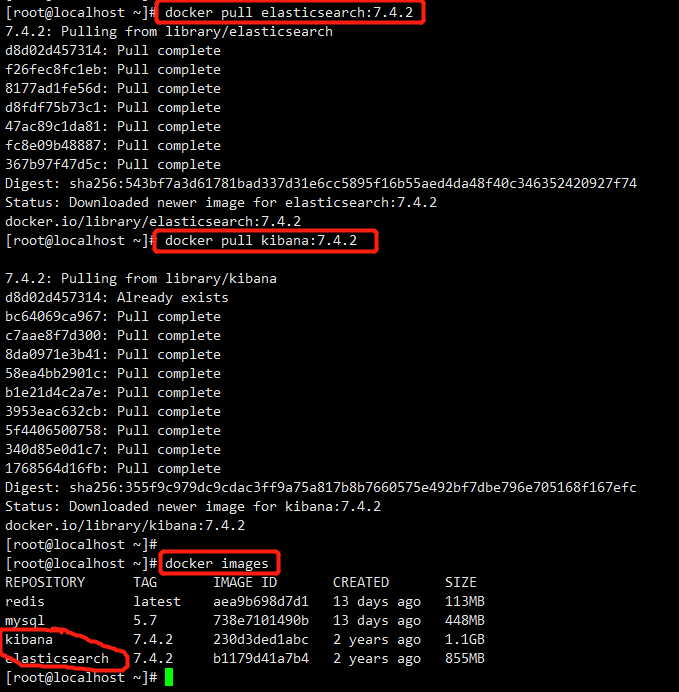
1、下载镜像文件
docker pull elasticsearch:7.4.2 存储和检索数据
docker pull kibana:7.4.2 可视化检索数据
注意:版本要统一
先检查一下虚拟机的可用内存

2、安装 ElasticSearch
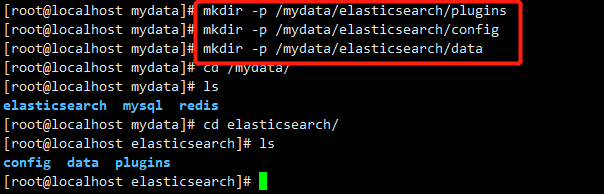
(1)创建挂载目录
mkdir -p /mydata/elasticsearch/plugins
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
(2)设置es可以被远程任何机器访问
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml

(3)递归更改权限,es需要访问
chmod -R 777 /mydata/elasticsearch
注意:一定要授权,否则后面启动的时候会访问拒绝,没权限

(4)创建实例,启动 Elastic search
注意:
# 9200是用户交互端口 9300是集群心跳端口
# -e指定是单阶段运行
# -e指定占用的内存大小,生产时可以设置32G

以后再外面装好插件重启即可;
特别注意:
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" \ 测试环境下,设置 ES 的初始内存和最大内存,否则导致过大启动不了 ES
(5)设置随docker自启动 docker update elasticsearch --restart=always
(6)测试访问
查看elasticsearch版本信息:http://192.168.56.10:9200/
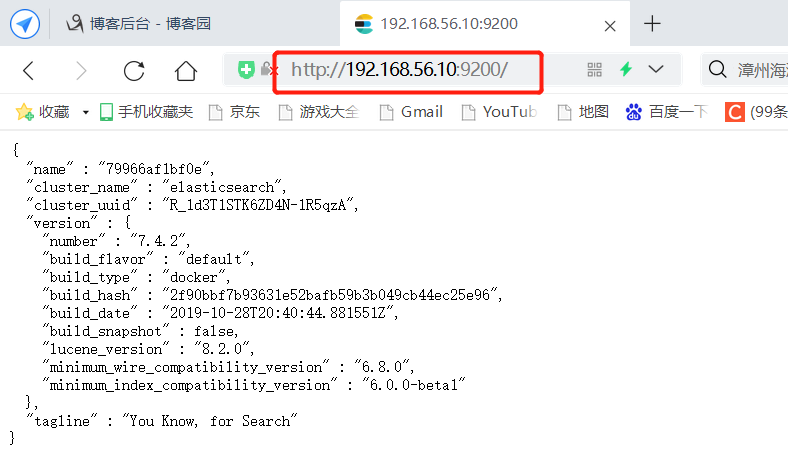
显示elasticsearch 节点信息http://192.168.11.129:9200/_cat/nodes
127.0.0.1 69 99 9 1.07 0.78 0.56 dilm * 79966af1bf0e
79966af1bf0e代表上面的节点,*代表是主节点
3、安装 kibana
(1)创建实例并启动
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 -p 5601:5601 -d kibana:7.4.2
注意:http://192.168.56.10:9200 一定改为自己虚拟机的地址

(2)设置随docker自启动 docker update kibana --restart=always
(3)测试
访问:http://192.168.56.10:5601/app/kibana
4、初步检索
1、_cat
(1)GET /_cat/nodes:查看所有节点
请求:http://192.168.56.10:9200/_cat/nodes
返回:127.0.0.1 53 99 18 1.64 1.34 0.89 dilm * 79966af1bf0e
注意:79966af1bf0e代表上面的节点,*代表是主节点
(2)GET /_cat/health:查看es健康状况
请求:http://192.168.56.10:9200/_cat/health
返回:1639660246 13:10:46 elasticsearch green 1 1 2 2 0 0 0 0 - 100.0%
注意:green表示健康值正常
(3)GET /_cat/master:查看主节点
请求:http://192.168.56.10:9200/_cat/master
返回:yV_3GAgSRlCZRbsaZGmwvg 127.0.0.1 127.0.0.1 79966af1bf0e
注意:主节点唯一编号、虚拟机地址
(4)GET /_cat/indices:查看所有索引,等价于mysql的show database;
请求:http://192.168.56.10:9200/_cat/indices
返回:green open .kibana_task_manager_1 TgtHkBPEQa27TRzx7csj_A 1 0 2 0 38.3kb 38.3kb
green open .kibana_1 WX3cdamiRh-ylxDECyU5qg 1 0 3 0 14.8kb 14.8kb
2、索引一个文档(保存)
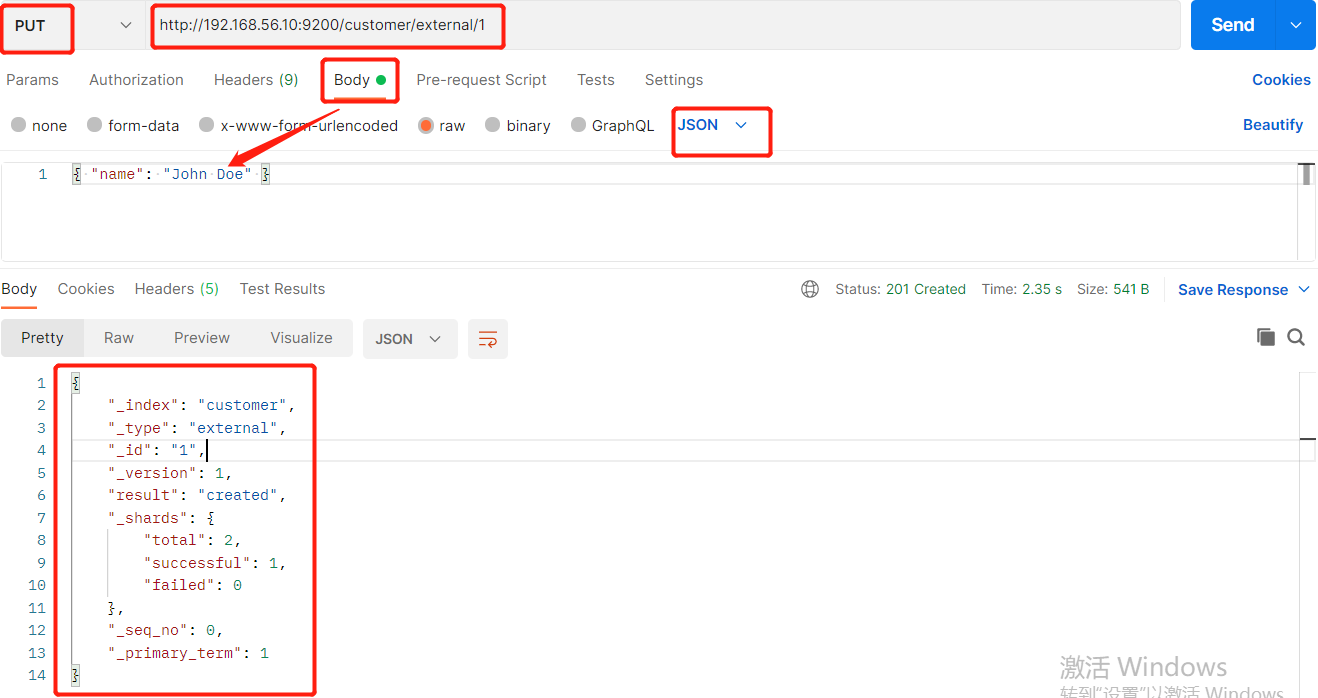
创建数据成功后,显示201 created表示插入记录成功。 返回数据: 带有下划线开头的,称为元数据,反映了当前的基本信息。 { "_index": "customer", 表明该数据在哪个数据库下; "_type": "external", 表明该数据在哪个类型下; "_id": "1", 表明被保存数据的id; "_version": 1, 被保存数据的版本 "result": "created", 这里是创建了一条数据,如果重新put一条数据,则该状态会变为updated,并且版本号也会发生变化。 "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 } 下面选用POST方式: 添加数据的时候,不指定ID,会自动的生成id,并且类型是新增: { "_index": "customer", "_type": "external", "_id": "5MIjvncBKdY1wAQm-wNZ", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 11, "_primary_term": 6 } 再次使用POST插入数据,不指定ID,仍然是新增的: { "_index": "customer", "_type": "external", "_id": "5cIkvncBKdY1wAQmcQNk", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 12, "_primary_term": 6 } 添加数据的时候,指定ID,会使用该id,并且类型是新增: { "_index": "customer", "_type": "external", "_id": "2", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 13, "_primary_term": 6 } 再次使用POST插入数据,指定同样的ID,类型为updated { "_index": "customer", "_type": "external", "_id": "2", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 14, "_primary_term": 6 }
3、查询文档 & 乐观锁字段
(1)GET /customer/external/1:查询文档
请求:http://192.168.56.10:9200/customer/external/1
返回:{ "_index": "customer", "_type": "external", "_id": "1", "_version": 10, "_seq_no": 18,//并发控制字段,每次更新都会+1,用来做乐观锁 "_primary_term": 6,//同上,主分片重新分配,如重启,就会变化 "found": true, "_source": { "name": "John Doe" } }
通过“if_seq_no=1&if_primary_term=1”,当序列号匹配的时候,才进行修改,否则不修改。
(2)实例:将id=1的数据更新为name=1,然后再次更新为name=2,起始1_seq_no=24,_primary_term=1
(a)将name更新为1
PUT http://192.168.56.10:9200/customer/external/1
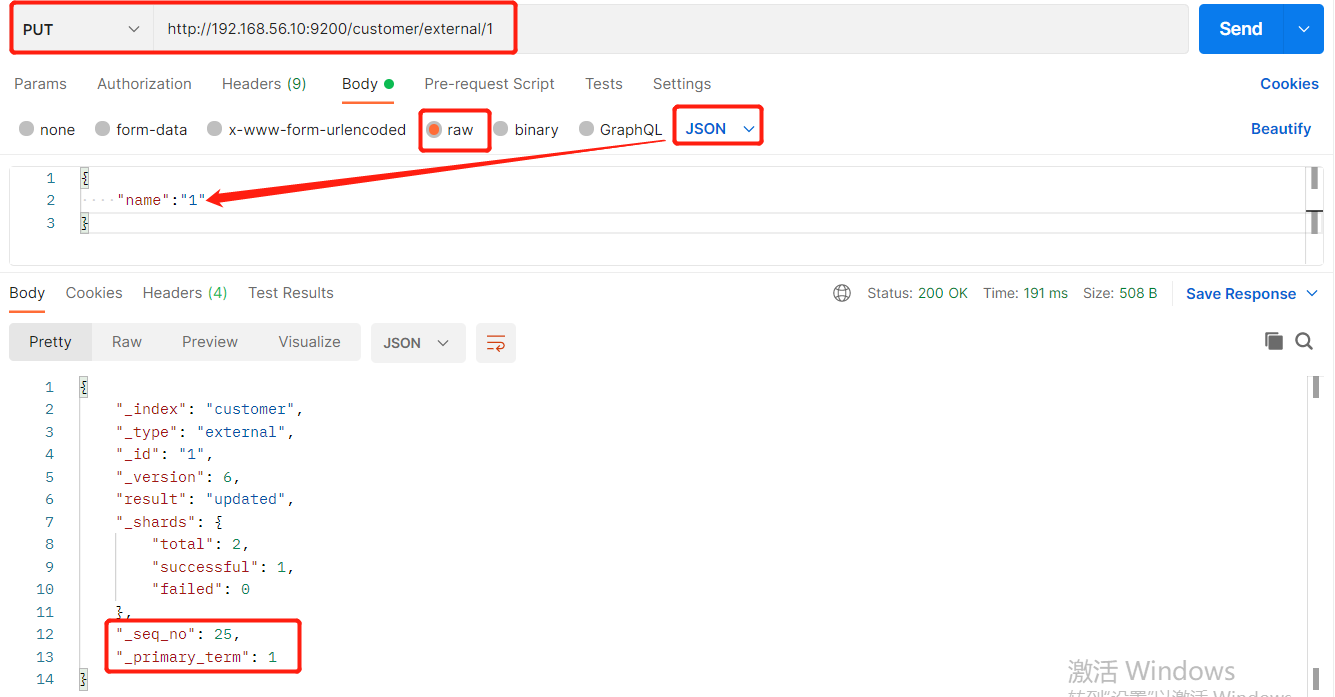

(b)将name更新为2,更新过程中使用seq_no=24
PUT http://192.168.56.10:9200/customer/external/1?if_seq_no=24&if_primary_term=1
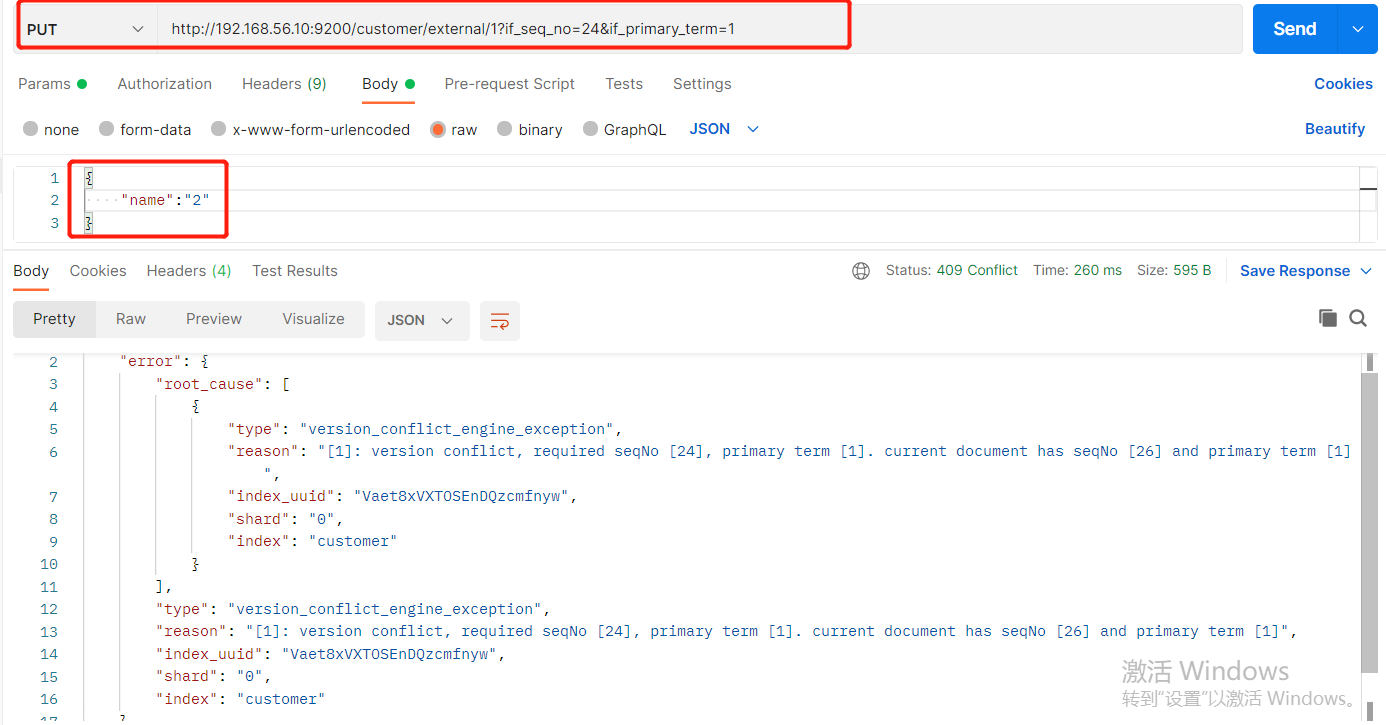
出现更新错误
查询新的数据,发现_seq_no=25,是第一次更新完毕之后的_seq_no
再次更新,更新成功
PUT http://192.168.56.10:9200/customer/external/1?if_seq_no=26&if_primary_term=1
4、更新文档 (1)更新文档_update (a)带有update的POST
POST customer/externel/1/_update { "doc":{ "name":"111" } } 或者 (b)不带update的POST
POST customer/externel/1 { "doc":{ "name":"222" } } 或者 (c)不带update的PUT
PUT customer/externel/1 { "doc":{ "name":"222" } }
(2)不同
(a)POST操作会对比源文档数据,如果相同不会有什么操作,文档version不增加。
(b)PUT操作总会将数据重新保存并增加version版本
(3)POST时带_update对比元数据如果一样就不进行任何操作。
(3)看场景
(a)对于大并发更新,不带update
(b)对于大并发查询偶尔更新,带update;对比更新,重新计算分配规则
(4)实例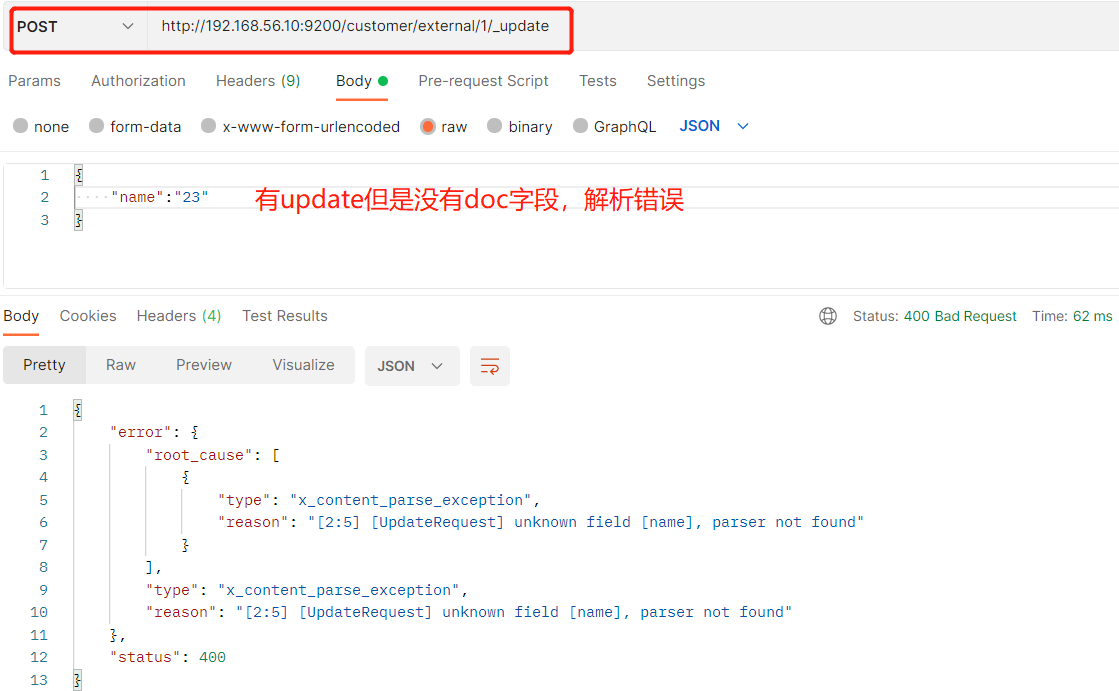
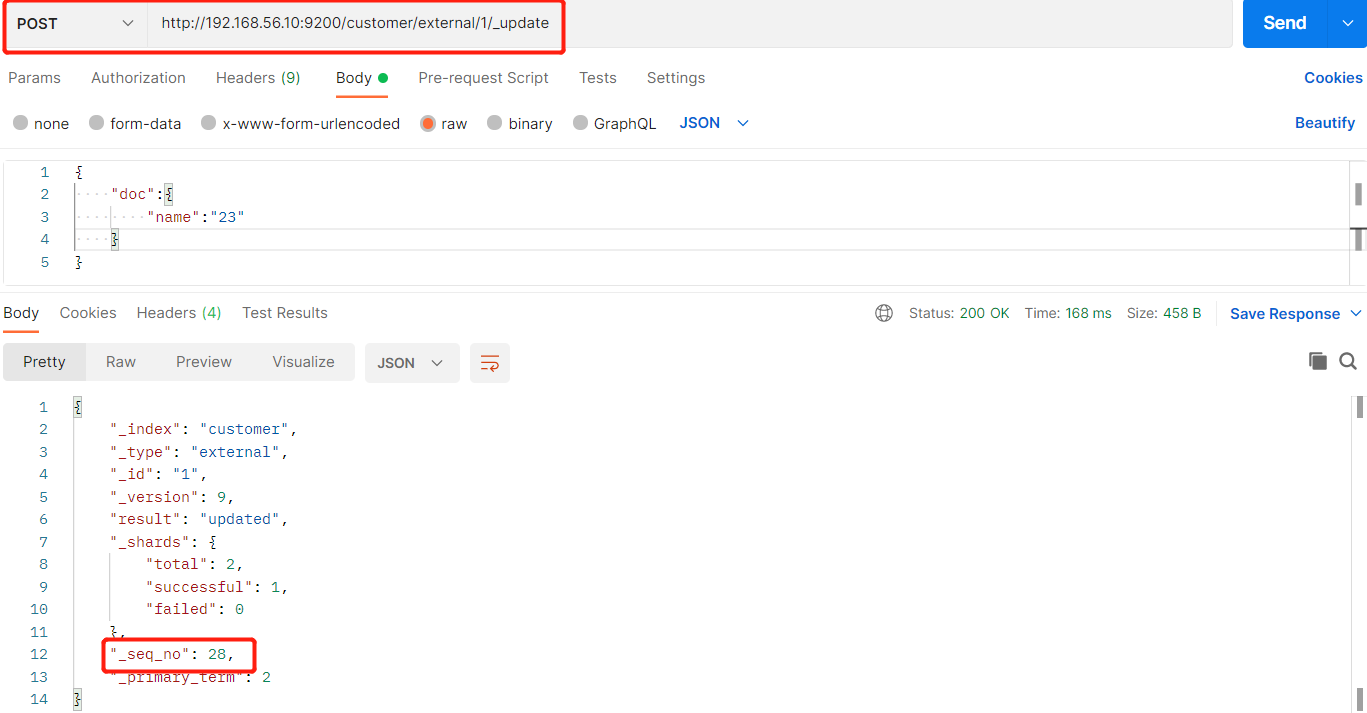
如果再次执行更新,则不执行任何操作,序列号也不发生变化,返回:
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 9,
"result": "noop",
"_shards": {
"total": 0,
"successful": 0,
"failed": 0
},
"_seq_no": 28,
"_primary_term": 2
}
POST更新方式,会对比原来的数据,和原来的相同,则不执行任何操作(version和_seq_no)都不变。
POST更新文档,不带_update
在更新过程中,重复执行更新操作,数据也能够更新成功,不会和原来的数据进行对比。_seq_no会变化
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 13,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 32,
"_primary_term": 2
}
5、删除文档 & 索引
(1)语法
DELETE customer/external/1
DELETE customer
注:elasticsearch并没有提供删除类型的操作,只提供了删除索引和文档的操作。
(2)实例
删除id=1的数据,删除后继续查询
DELETE http://192.168.56.10:9200/customer/external/1
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 14,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 33,
"_primary_term": 2
}
再次执行DELETE http://192.168.56.10:9200/customer/external/1
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 1,
"result": "not_found",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 34,
"_primary_term": 2
}
GET http://192.168.56.10:9200/customer/external/1
{
"_index": "customer",
"_type": "external",
"_id": "1",
"found": false
}
(3)删除整个customer索引数据
删除前,所有的索引http://192.168.56.10:9200/_cat/indices
green open .kibana_task_manager_1 TgtHkBPEQa27TRzx7csj_A 1 0 2 0 30.4kb 30.4kb
green open .kibana_1 WX3cdamiRh-ylxDECyU5qg 1 0 5 0 18.3kb 18.3kb
yellow open customer Vaet8xVXTOSEnDQzcmfnyw 1 1 6 4 13.9kb 13.9kb
删除“ customer ”索引 DELTE http://192.168.56.10:9200/customer
响应
{
"acknowledged": true
}
删除后,所有的索引http://192.168.56.10:9200/_cat/indices
green open .kibana_task_manager_1 TgtHkBPEQa27TRzx7csj_A 1 0 2 0 30.4kb 30.4kb
green open .kibana_1 WX3cdamiRh-ylxDECyU5qg 1 0 5 0 18.3kb 18.3kb
6、bulk 批量 API
(1)匹配导入数据 POST http://192.168.56.10:9200/customer/external/_bulk 两行为一个整体 {"index":{"_id":"1"}} {"name":"a"} {"index":{"_id":"2"}} {"name":"b"} 注意格式json和text均不可,要去kibana里Dev Tools
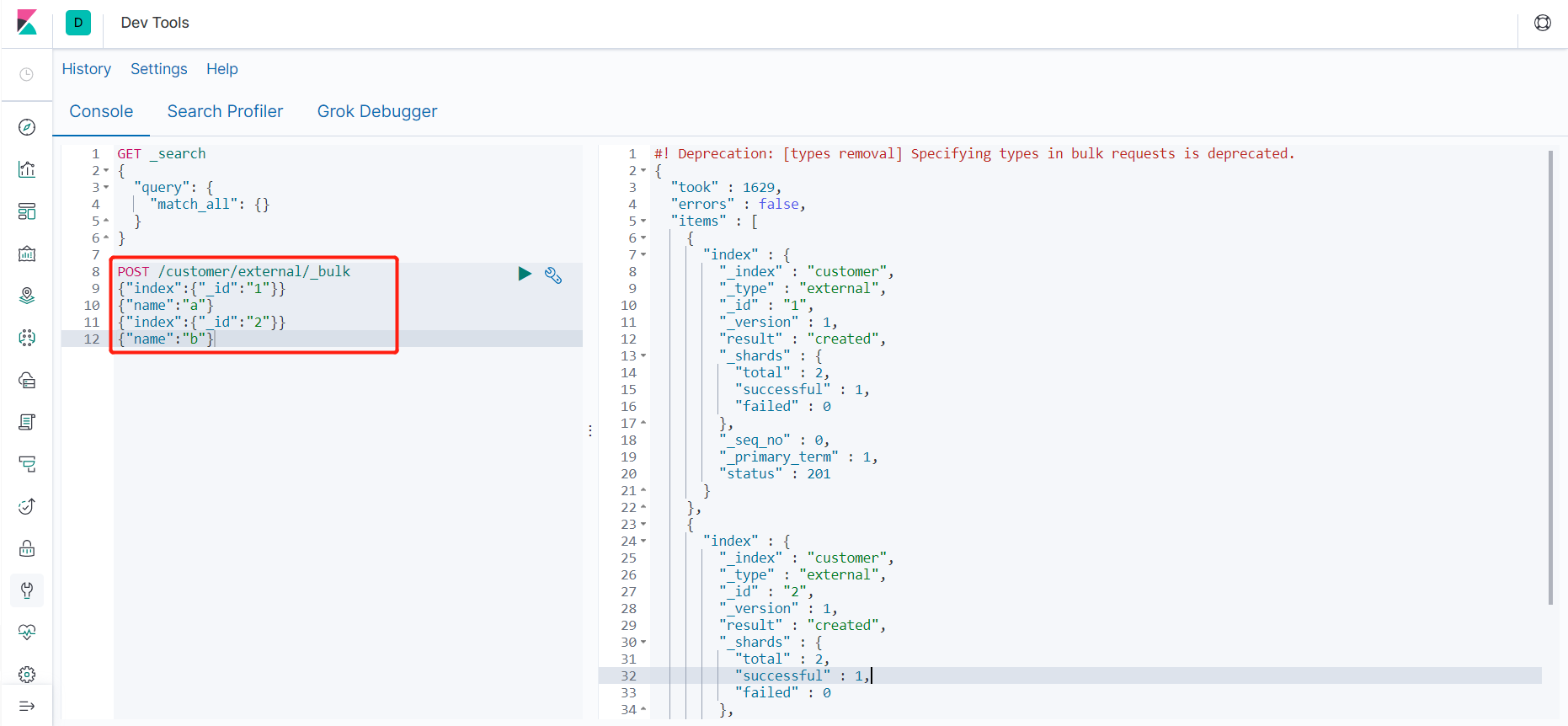
语法格式:
7、样本测试数据
准备了一份顾客银行账户信息的虚构的JSON文档样本。每个文档都有下列的schema(模式)。
{ "account_number": 1, "balance": 39225, "firstname": "Amber", "lastname": "Duke", "age": 32, "gender": "M", "address": "880 Holmes Lane", "employer": "Pyrami", "email": "amberduke@pyrami.com", "city": "Brogan", "state": "IL" }
https://gitee.com/xlh_blog/common_content/blob/master/es%E6%B5%8B%E8%AF%95%E6%95%B0%E6%8D%AE.json,导入数据
POST bank/account/_bulk 上面的数据
http://192.168.56.10:9200/_cat/indices 刚导入了1000条 yellow open bank GAry5upkQga9NZ6gY2Gyfw 1 1 1000 0 427.7kb 427.7kb
数据内容
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
{"index":{"_id":"6"}}
{"account_number":6,"balance":5686,"firstname":"Hattie","lastname":"Bond","age":36,"gender":"M","address":"671 Bristol Street","employer":"Netagy","email":"hattiebond@netagy.com","city":"Dante","state":"TN"}
{"index":{"_id":"13"}}
{"account_number":13,"balance":32838,"firstname":"Nanette","lastname":"Bates","age":28,"gender":"F","address":"789 Madison Street","employer":"Quility","email":"nanettebates@quility.com","city":"Nogal","state":"VA"}
{"index":{"_id":"18"}}
{"account_number":18,"balance":4180,"firstname":"Dale","lastname":"Adams","age":33,"gender":"M","address":"467 Hutchinson Court","employer":"Boink","email":"daleadams@boink.com","city":"Orick","state":"MD"}
{"index":{"_id":"20"}}
{"account_number":20,"balance":16418,"firstname":"Elinor","lastname":"Ratliff","age":36,"gender":"M","address":"282 Kings Place","employer":"Scentric","email":"elinorratliff@scentric.com","city":"Ribera","state":"WA"}
{"index":{"_id":"25"}}
{"account_number":25,"balance":40540,"firstname":"Virginia","lastname":"Ayala","age":39,"gender":"F","address":"171 Putnam Avenue","employer":"Filodyne","email":"virginiaayala@filodyne.com","city":"Nicholson","state":"PA"}
{"index":{"_id":"32"}}
{"account_number":32,"balance":48086,"firstname":"Dillard","lastname":"Mcpherson","age":34,"gender":"F","address":"702 Quentin Street","employer":"Quailcom","email":"dillardmcpherson@quailcom.com","city":"Veguita","state":"IN"}
{"index":{"_id":"37"}}
{"account_number":37,"balance":18612,"firstname":"Mcgee","lastname":"Mooney","age":39,"gender":"M","address":"826 Fillmore Place","employer":"Reversus","email":"mcgeemooney@reversus.com","city":"Tooleville","state":"OK"}
{"index":{"_id":"44"}}
{"account_number":44,"balance":34487,"firstname":"Aurelia","lastname":"Harding","age":37,"gender":"M","address":"502 Baycliff Terrace","employer":"Orbalix","email":"aureliaharding@orbalix.com","city":"Yardville","state":"DE"}
{"index":{"_id":"49"}}
{"account_number":49,"balance":29104,"firstname":"Fulton","lastname":"Holt","age":23,"gender":"F","address":"451 Humboldt Street","employer":"Anocha","email":"fultonholt@anocha.com","city":"Sunriver","state":"RI"}
{"index":{"_id":"51"}}
{"account_number":51,"balance":14097,"firstname":"Burton","lastname":"Meyers","age":31,"gender":"F","address":"334 River Street","employer":"Bezal","email":"burtonmeyers@bezal.com","city":"Jacksonburg","state":"MO"}
{"index":{"_id":"56"}}
{"account_number":56,"balance":14992,"firstname":"Josie","lastname":"Nelson","age":32,"gender":"M","address":"857 Tabor Court","employer":"Emtrac","email":"josienelson@emtrac.com","city":"Sunnyside","state":"UT"}
{"index":{"_id":"63"}}
{"account_number":63,"balance":6077,"firstname":"Hughes","lastname":"Owens","age":30,"gender":"F","address":"510 Sedgwick Street","employer":"Valpreal","email":"hughesowens@valpreal.com","city":"Guilford","state":"KS"}
{"index":{"_id":"68"}}
{"account_number":68,"balance":44214,"firstname":"Hall","lastname":"Key","age":25,"gender":"F","address":"927 Bay Parkway","employer":"Eventex","email":"hallkey@eventex.com","city":"Shawmut","state":"CA"}
{"index":{"_id":"70"}}
{"account_number":70,"balance":38172,"firstname":"Deidre","lastname":"Thompson","age":33,"gender":"F","address":"685 School Lane","employer":"Netplode","email":"deidrethompson@netplode.com","city":"Chestnut","state":"GA"}
{"index":{"_id":"75"}}
{"account_number":75,"balance":40500,"firstname":"Sandoval","lastname":"Kramer","age":22,"gender":"F","address":"166 Irvington Place","employer":"Overfork","email":"sandovalkramer@overfork.com","city":"Limestone","state":"NH"}
{"index":{"_id":"82"}}
{"account_number":82,"balance":41412,"firstname":"Concetta","lastname":"Barnes","age":39,"gender":"F","address":"195 Bayview Place","employer":"Fitcore","email":"concettabarnes@fitcore.com","city":"Summerfield","state":"NC"}
{"index":{"_id":"87"}}
{"account_number":87,"balance":1133,"firstname":"Hewitt","lastname":"Kidd","age":22,"gender":"M","address":"446 Halleck Street","employer":"Isologics","email":"hewittkidd@isologics.com","city":"Coalmont","state":"ME"}
{"index":{"_id":"94"}}
{"account_number":94,"balance":41060,"firstname":"Brittany","lastname":"Cabrera","age":30,"gender":"F","address":"183 Kathleen Court","employer":"Mixers","email":"brittanycabrera@mixers.com","city":"Cornucopia","state":"AZ"}
{"index":{"_id":"99"}}
{"account_number":99,"balance":47159,"firstname":"Ratliff","lastname":"Heath","age":39,"gender":"F","address":"806 Rockwell Place","employer":"Zappix","email":"ratliffheath@zappix.com","city":"Shaft","state":"ND"}
{"index":{"_id":"102"}}
{"account_number":102,"balance":29712,"firstname":"Dena","lastname":"Olson","age":27,"gender":"F","address":"759 Newkirk Avenue","employer":"Hinway","email":"denaolson@hinway.com","city":"Choctaw","state":"NJ"}
{"index":{"_id":"107"}}
{"account_number":107,"balance":48844,"firstname":"Randi","lastname":"Rich","age":28,"gender":"M","address":"694 Jefferson Street","employer":"Netplax","email":"randirich@netplax.com","city":"Bellfountain","state":"SC"}
{"index":{"_id":"114"}}
{"account_number":114,"balance":43045,"firstname":"Josephine","lastname":"Joseph","age":31,"gender":"F","address":"451 Oriental Court","employer":"Turnabout","email":"josephinejoseph@turnabout.com","city":"Sedley","state":"AL"}
{"index":{"_id":"119"}}
{"account_number":119,"balance":49222,"firstname":"Laverne","lastname":"Johnson","age":28,"gender":"F","address":"302 Howard Place","employer":"Senmei","email":"lavernejohnson@senmei.com","city":"Herlong","state":"DC"}
{"index":{"_id":"121"}}
{"account_number":121,"balance":19594,"firstname":"Acevedo","lastname":"Dorsey","age":32,"gender":"M","address":"479 Nova Court","employer":"Netropic","email":"acevedodorsey@netropic.com","city":"Islandia","state":"CT"}
{"index":{"_id":"126"}}
{"account_number":126,"balance":3607,"firstname":"Effie","lastname":"Gates","age":39,"gender":"F","address":"620 National Drive","employer":"Digitalus","email":"effiegates@digitalus.com","city":"Blodgett","state":"MD"}
{"index":{"_id":"133"}}
{"account_number":133,"balance":26135,"firstname":"Deena","lastname":"Richmond","age":36,"gender":"F","address":"646 Underhill Avenue","employer":"Sunclipse","email":"deenarichmond@sunclipse.com","city":"Austinburg","state":"SC"}
{"index":{"_id":"138"}}
{"account_number":138,"balance":9006,"firstname":"Daniel","lastname":"Arnold","age":39,"gender":"F","address":"422 Malbone Street","employer":"Ecstasia","email":"danielarnold@ecstasia.com","city":"Gardiner","state":"MO"}
{"index":{"_id":"140"}}
{"account_number":140,"balance":26696,"firstname":"Cotton","lastname":"Christensen","age":32,"gender":"M","address":"878 Schermerhorn Street","employer":"Prowaste","email":"cottonchristensen@prowaste.com","city":"Mayfair","state":"LA"}
{"index":{"_id":"145"}}
{"account_number":145,"balance":47406,"firstname":"Rowena","lastname":"Wilkinson","age":32,"gender":"M","address":"891 Elton Street","employer":"Asimiline","email":"rowenawilkinson@asimiline.com","city":"Ripley","state":"NH"}
{"index":{"_id":"152"}}
{"account_number":152,"balance":8088,"firstname":"Wolfe","lastname":"Rocha","age":21,"gender":"M","address":"457 Guernsey Street","employer":"Hivedom","email":"wolferocha@hivedom.com","city":"Adelino","state":"MS"}
{"index":{"_id":"157"}}
{"account_number":157,"balance":39868,"firstname":"Claudia","lastname":"Terry","age":20,"gender":"F","address":"132 Gunnison Court","employer":"Lumbrex","email":"claudiaterry@lumbrex.com","city":"Castleton","state":"MD"}
{"index":{"_id":"164"}}
{"account_number":164,"balance":9101,"firstname":"Cummings","lastname":"Little","age":26,"gender":"F","address":"308 Schaefer Street","employer":"Comtrak","email":"cummingslittle@comtrak.com","city":"Chaparrito","state":"WI"}
{"index":{"_id":"169"}}
{"account_number":169,"balance":45953,"firstname":"Hollie","lastname":"Osborn","age":34,"gender":"M","address":"671 Seaview Court","employer":"Musaphics","email":"hollieosborn@musaphics.com","city":"Hanover","state":"GA"}
{"index":{"_id":"171"}}
{"account_number":171,"balance":7091,"firstname":"Nelda","lastname":"Hopper","age":39,"gender":"M","address":"742 Prospect Place","employer":"Equicom","email":"neldahopper@equicom.com","city":"Finderne","state":"SC"}
{"index":{"_id":"176"}}
{"account_number":176,"balance":18607,"firstname":"Kemp","lastname":"Walters","age":28,"gender":"F","address":"906 Howard Avenue","employer":"Eyewax","email":"kempwalters@eyewax.com","city":"Why","state":"KY"}
{"index":{"_id":"183"}}
{"account_number":183,"balance":14223,"firstname":"Hudson","lastname":"English","age":26,"gender":"F","address":"823 Herkimer Place","employer":"Xinware","email":"hudsonenglish@xinware.com","city":"Robbins","state":"ND"}
{"index":{"_id":"188"}}
{"account_number":188,"balance":41504,"firstname":"Tia","lastname":"Miranda","age":24,"gender":"F","address":"583 Ainslie Street","employer":"Jasper","email":"tiamiranda@jasper.com","city":"Summerset","state":"UT"}
{"index":{"_id":"190"}}
{"account_number":190,"balance":3150,"firstname":"Blake","lastname":"Davidson","age":30,"gender":"F","address":"636 Diamond Street","employer":"Quantasis","email":"blakedavidson@quantasis.com","city":"Crumpler","state":"KY"}
{"index":{"_id":"195"}}
{"account_number":195,"balance":5025,"firstname":"Kaye","lastname":"Gibson","age":31,"gender":"M","address":"955 Hopkins Street","employer":"Zork","email":"kayegibson@zork.com","city":"Ola","state":"WY"}
{"index":{"_id":"203"}}
{"account_number":203,"balance":21890,"firstname":"Eve","lastname":"Wyatt","age":33,"gender":"M","address":"435 Furman Street","employer":"Assitia","email":"evewyatt@assitia.com","city":"Jamestown","state":"MN"}
{"index":{"_id":"208"}}
{"account_number":208,"balance":40760,"firstname":"Garcia","lastname":"Hess","age":26,"gender":"F","address":"810 Nostrand Avenue","employer":"Quiltigen","email":"garciahess@quiltigen.com","city":"Brooktrails","state":"GA"}
{"index":{"_id":"210"}}
{"account_number":210,"balance":33946,"firstname":"Cherry","lastname":"Carey","age":24,"gender":"M","address":"539 Tiffany Place","employer":"Martgo","email":"cherrycarey@martgo.com","city":"Fairacres","state":"AK"}
{"index":{"_id":"215"}}
{"account_number":215,"balance":37427,"firstname":"Copeland","lastname":"Solomon","age":20,"gender":"M","address":"741 McDonald Avenue","employer":"Recognia","email":"copelandsolomon@recognia.com","city":"Edmund","state":"ME"}
{"index":{"_id":"222"}}
{"account_number":222,"balance":14764,"firstname":"Rachelle","lastname":"Rice","age":36,"gender":"M","address":"333 Narrows Avenue","employer":"Enaut","email":"rachellerice@enaut.com","city":"Wright","state":"AZ"}
{"index":{"_id":"227"}}
{"account_number":227,"balance":19780,"firstname":"Coleman","lastname":"Berg","age":22,"gender":"M","address":"776 Little Street","employer":"Exoteric","email":"colemanberg@exoteric.com","city":"Eagleville","state":"WV"}
{"index":{"_id":"234"}}
{"account_number":234,"balance":44207,"firstname":"Betty","lastname":"Hall","age":37,"gender":"F","address":"709 Garfield Place","employer":"Miraclis","email":"bettyhall@miraclis.com","city":"Bendon","state":"NY"}
{"index":{"_id":"239"}}
{"account_number":239,"balance":25719,"firstname":"Chang","lastname":"Boyer","age":36,"gender":"M","address":"895 Brigham Street","employer":"Qaboos","email":"changboyer@qaboos.com","city":"Belgreen","state":"NH"}
{"index":{"_id":"241"}}
{"account_number":241,"balance":25379,"firstname":"Schroeder","lastname":"Harrington","age":26,"gender":"M","address":"610 Tapscott Avenue","employer":"Otherway","email":"schroederharrington@otherway.com","city":"Ebro","state":"TX"}
{"index":{"_id":"246"}}
{"account_number":246,"balance":28405,"firstname":"Katheryn","lastname":"Foster","age":21,"gender":"F","address":"259 Kane Street","employer":"Quantalia","email":"katherynfoster@quantalia.com","city":"Bath","state":"TX"}
{"index":{"_id":"253"}}
{"account_number":253,"balance":20240,"firstname":"Melissa","lastname":"Gould","age":31,"gender":"M","address":"440 Fuller Place","employer":"Buzzopia","email":"melissagould@buzzopia.com","city":"Lumberton","state":"MD"}
{"index":{"_id":"258"}}
{"account_number":258,"balance":5712,"firstname":"Lindsey","lastname":"Hawkins","age":37,"gender":"M","address":"706 Frost Street","employer":"Enormo","email":"lindseyhawkins@enormo.com","city":"Gardners","state":"AK"}
{"index":{"_id":"260"}}
{"account_number":260,"balance":2726,"firstname":"Kari","lastname":"Skinner","age":30,"gender":"F","address":"735 Losee Terrace","employer":"Singavera","email":"kariskinner@singavera.com","city":"Rushford","state":"WV"}
{"index":{"_id":"265"}}
{"account_number":265,"balance":46910,"firstname":"Marion","lastname":"Schneider","age":26,"gender":"F","address":"574 Everett Avenue","employer":"Evidends","email":"marionschneider@evidends.com","city":"Maplewood","state":"WY"}
{"index":{"_id":"272"}}
{"account_number":272,"balance":19253,"firstname":"Lilly","lastname":"Morgan","age":25,"gender":"F","address":"689 Fleet Street","employer":"Biolive","email":"lillymorgan@biolive.com","city":"Sunbury","state":"OH"}
{"index":{"_id":"277"}}
{"account_number":277,"balance":29564,"firstname":"Romero","lastname":"Lott","age":31,"gender":"M","address":"456 Danforth Street","employer":"Plasto","email":"romerolott@plasto.com","city":"Vincent","state":"VT"}
{"index":{"_id":"284"}}
{"account_number":284,"balance":22806,"firstname":"Randolph","lastname":"Banks","age":29,"gender":"M","address":"875 Hamilton Avenue","employer":"Caxt","email":"randolphbanks@caxt.com","city":"Crawfordsville","state":"WA"}
{"index":{"_id":"289"}}
{"account_number":289,"balance":7798,"firstname":"Blair","lastname":"Church","age":29,"gender":"M","address":"370 Sutton Street","employer":"Cubix","email":"blairchurch@cubix.com","city":"Nile","state":"NH"}
{"index":{"_id":"291"}}
{"account_number":291,"balance":19955,"firstname":"Lynn","lastname":"Pollard","age":40,"gender":"F","address":"685 Pierrepont Street","employer":"Slambda","email":"lynnpollard@slambda.com","city":"Mappsville","state":"ID"}
{"index":{"_id":"296"}}
{"account_number":296,"balance":24606,"firstname":"Rosa","lastname":"Oliver","age":34,"gender":"M","address":"168 Woodbine Street","employer":"Idetica","email":"rosaoliver@idetica.com","city":"Robinson","state":"WY"}
{"index":{"_id":"304"}}
{"account_number":304,"balance":28647,"firstname":"Palmer","lastname":"Clark","age":35,"gender":"M","address":"866 Boulevard Court","employer":"Maximind","email":"palmerclark@maximind.com","city":"Avalon","state":"NH"}
{"index":{"_id":"309"}}
{"account_number":309,"balance":3830,"firstname":"Rosemarie","lastname":"Nieves","age":30,"gender":"M","address":"206 Alice Court","employer":"Zounds","email":"rosemarienieves@zounds.com","city":"Ferney","state":"AR"}
{"index":{"_id":"311"}}
{"account_number":311,"balance":13388,"firstname":"Vinson","lastname":"Ballard","age":23,"gender":"F","address":"960 Glendale Court","employer":"Gynk","email":"vinsonballard@gynk.com","city":"Fairforest","state":"WY"}
{"index":{"_id":"316"}}
{"account_number":316,"balance":8214,"firstname":"Anita","lastname":"Ewing","age":32,"gender":"M","address":"396 Lombardy Street","employer":"Panzent","email":"anitaewing@panzent.com","city":"Neahkahnie","state":"WY"}
{"index":{"_id":"323"}}
{"account_number":323,"balance":42230,"firstname":"Chelsea","lastname":"Gamble","age":34,"gender":"F","address":"356 Dare Court","employer":"Isosphere","email":"chelseagamble@isosphere.com","city":"Dundee","state":"MD"}
{"index":{"_id":"328"}}
{"account_number":328,"balance":12523,"firstname":"Good","lastname":"Campbell","age":27,"gender":"F","address":"438 Hicks Street","employer":"Gracker","email":"goodcampbell@gracker.com","city":"Marion","state":"CA"}
{"index":{"_id":"330"}}
{"account_number":330,"balance":41620,"firstname":"Yvette","lastname":"Browning","age":34,"gender":"F","address":"431 Beekman Place","employer":"Marketoid","email":"yvettebrowning@marketoid.com","city":"Talpa","state":"CO"}
{"index":{"_id":"335"}}
{"account_number":335,"balance":35433,"firstname":"Vera","lastname":"Hansen","age":24,"gender":"M","address":"252 Bushwick Avenue","employer":"Zanilla","email":"verahansen@zanilla.com","city":"Manila","state":"TN"}
{"index":{"_id":"342"}}
{"account_number":342,"balance":33670,"firstname":"Vivian","lastname":"Wells","age":36,"gender":"M","address":"570 Cobek Court","employer":"Nutralab","email":"vivianwells@nutralab.com","city":"Fontanelle","state":"OK"}
{"index":{"_id":"347"}}
{"account_number":347,"balance":36038,"firstname":"Gould","lastname":"Carson","age":24,"gender":"F","address":"784 Pulaski Street","employer":"Mobildata","email":"gouldcarson@mobildata.com","city":"Goochland","state":"MI"}
{"index":{"_id":"354"}}
{"account_number":354,"balance":21294,"firstname":"Kidd","lastname":"Mclean","age":22,"gender":"M","address":"691 Saratoga Avenue","employer":"Ronbert","email":"kiddmclean@ronbert.com","city":"Tioga","state":"ME"}
{"index":{"_id":"359"}}
{"account_number":359,"balance":29927,"firstname":"Vanessa","lastname":"Harvey","age":28,"gender":"F","address":"679 Rutledge Street","employer":"Zentime","email":"vanessaharvey@zentime.com","city":"Williston","state":"IL"}
{"index":{"_id":"361"}}
{"account_number":361,"balance":23659,"firstname":"Noreen","lastname":"Shelton","age":36,"gender":"M","address":"702 Tillary Street","employer":"Medmex","email":"noreenshelton@medmex.com","city":"Derwood","state":"NH"}
{"index":{"_id":"366"}}
{"account_number":366,"balance":42368,"firstname":"Lydia","lastname":"Cooke","age":31,"gender":"M","address":"470 Coleman Street","employer":"Comstar","email":"lydiacooke@comstar.com","city":"Datil","state":"TN"}
{"index":{"_id":"373"}}
{"account_number":373,"balance":9671,"firstname":"Simpson","lastname":"Carpenter","age":21,"gender":"M","address":"837 Horace Court","employer":"Snips","email":"simpsoncarpenter@snips.com","city":"Tolu","state":"MA"}
{"index":{"_id":"378"}}
{"account_number":378,"balance":27100,"firstname":"Watson","lastname":"Simpson","age":36,"gender":"F","address":"644 Thomas Street","employer":"Wrapture","email":"watsonsimpson@wrapture.com","city":"Keller","state":"TX"}
{"index":{"_id":"380"}}
{"account_number":380,"balance":35628,"firstname":"Fernandez","lastname":"Reid","age":33,"gender":"F","address":"154 Melba Court","employer":"Cosmosis","email":"fernandezreid@cosmosis.com","city":"Boyd","state":"NE"}
{"index":{"_id":"385"}}
{"account_number":385,"balance":11022,"firstname":"Rosalinda","lastname":"Valencia","age":22,"gender":"M","address":"933 Lloyd Street","employer":"Zoarere","email":"rosalindavalencia@zoarere.com","city":"Waverly","state":"GA"}
{"index":{"_id":"392"}}
{"account_number":392,"balance":31613,"firstname":"Dotson","lastname":"Dean","age":35,"gender":"M","address":"136 Ford Street","employer":"Petigems","email":"dotsondean@petigems.com","city":"Chical","state":"SD"}
{"index":{"_id":"397"}}
{"account_number":397,"balance":37418,"firstname":"Leonard","lastname":"Gray","age":36,"gender":"F","address":"840 Morgan Avenue","employer":"Recritube","email":"leonardgray@recritube.com","city":"Edenburg","state":"AL"}
{"index":{"_id":"400"}}
{"account_number":400,"balance":20685,"firstname":"Kane","lastname":"King","age":21,"gender":"F","address":"405 Cornelia Street","employer":"Tri@Tribalog","email":"kaneking@tri@tribalog.com","city":"Gulf","state":"VT"}
{"index":{"_id":"405"}}
{"account_number":405,"balance":5679,"firstname":"Strickland","lastname":"Fuller","age":26,"gender":"M","address":"990 Concord Street","employer":"Digique","email":"stricklandfuller@digique.com","city":"Southmont","state":"NV"}
{"index":{"_id":"412"}}
{"account_number":412,"balance":27436,"firstname":"Ilene","lastname":"Abbott","age":26,"gender":"M","address":"846 Vine Street","employer":"Typhonica","email":"ileneabbott@typhonica.com","city":"Cedarville","state":"VT"}
{"index":{"_id":"417"}}
{"account_number":417,"balance":1788,"firstname":"Wheeler","lastname":"Ayers","age":35,"gender":"F","address":"677 Hope Street","employer":"Fortean","email":"wheelerayers@fortean.com","city":"Ironton","state":"PA"}
{"index":{"_id":"424"}}
{"account_number":424,"balance":36818,"firstname":"Tracie","lastname":"Gregory","age":34,"gender":"M","address":"112 Hunterfly Place","employer":"Comstruct","email":"traciegregory@comstruct.com","city":"Onton","state":"TN"}
{"index":{"_id":"429"}}
{"account_number":429,"balance":46970,"firstname":"Cantu","lastname":"Lindsey","age":31,"gender":"M","address":"404 Willoughby Avenue","employer":"Inquala","email":"cantulindsey@inquala.com","city":"Cowiche","state":"IA"}
{"index":{"_id":"431"}}
{"account_number":431,"balance":13136,"firstname":"Laurie","lastname":"Shaw","age":26,"gender":"F","address":"263 Aviation Road","employer":"Zillanet","email":"laurieshaw@zillanet.com","city":"Harmon","state":"WV"}
{"index":{"_id":"436"}}
{"account_number":436,"balance":27585,"firstname":"Alexander","lastname":"Sargent","age":23,"gender":"M","address":"363 Albemarle Road","employer":"Fangold","email":"alexandersargent@fangold.com","city":"Calpine","state":"OR"}
{"index":{"_id":"443"}}
{"account_number":443,"balance":7588,"firstname":"Huff","lastname":"Thomas","age":23,"gender":"M","address":"538 Erskine Loop","employer":"Accufarm","email":"huffthomas@accufarm.com","city":"Corinne","state":"AL"}
{"index":{"_id":"448"}}
{"account_number":448,"balance":22776,"firstname":"Adriana","lastname":"Mcfadden","age":35,"gender":"F","address":"984 Woodside Avenue","employer":"Telequiet","email":"adrianamcfadden@telequiet.com","city":"Darrtown","state":"WI"}
{"index":{"_id":"450"}}
{"account_number":450,"balance":2643,"firstname":"Bradford","lastname":"Nielsen","age":25,"gender":"M","address":"487 Keen Court","employer":"Exovent","email":"bradfordnielsen@exovent.com","city":"Hamilton","state":"DE"}
{"index":{"_id":"455"}}
{"account_number":455,"balance":39556,"firstname":"Lynn","lastname":"Tran","age":36,"gender":"M","address":"741 Richmond Street","employer":"Optyk","email":"lynntran@optyk.com","city":"Clinton","state":"WV"}
{"index":{"_id":"462"}}
{"account_number":462,"balance":10871,"firstname":"Calderon","lastname":"Day","age":27,"gender":"M","address":"810 Milford Street","employer":"Cofine","email":"calderonday@cofine.com","city":"Kula","state":"OK"}
{"index":{"_id":"467"}}
{"account_number":467,"balance":6312,"firstname":"Angelica","lastname":"May","age":32,"gender":"F","address":"384 Karweg Place","employer":"Keeg","email":"angelicamay@keeg.com","city":"Tetherow","state":"IA"}
{"index":{"_id":"474"}}
{"account_number":474,"balance":35896,"firstname":"Obrien","lastname":"Walton","age":40,"gender":"F","address":"192 Ide Court","employer":"Suremax","email":"obrienwalton@suremax.com","city":"Crucible","state":"UT"}
{"index":{"_id":"479"}}
{"account_number":479,"balance":31865,"firstname":"Cameron","lastname":"Ross","age":40,"gender":"M","address":"904 Bouck Court","employer":"Telpod","email":"cameronross@telpod.com","city":"Nord","state":"MO"}
{"index":{"_id":"481"}}
{"account_number":481,"balance":20024,"firstname":"Lina","lastname":"Stanley","age":33,"gender":"M","address":"361 Hanover Place","employer":"Strozen","email":"linastanley@strozen.com","city":"Wyoming","state":"NC"}
{"index":{"_id":"486"}}
{"account_number":486,"balance":35902,"firstname":"Dixie","lastname":"Fuentes","age":22,"gender":"F","address":"991 Applegate Court","employer":"Portico","email":"dixiefuentes@portico.com","city":"Salix","state":"VA"}
{"index":{"_id":"493"}}
{"account_number":493,"balance":5871,"firstname":"Campbell","lastname":"Best","age":24,"gender":"M","address":"297 Friel Place","employer":"Fanfare","email":"campbellbest@fanfare.com","city":"Kidder","state":"GA"}
{"index":{"_id":"498"}}
{"account_number":498,"balance":10516,"firstname":"Stella","lastname":"Hinton","age":39,"gender":"F","address":"649 Columbia Place","employer":"Flyboyz","email":"stellahinton@flyboyz.com","city":"Crenshaw","state":"SC"}
{"index":{"_id":"501"}}
{"account_number":501,"balance":16572,"firstname":"Kelley","lastname":"Ochoa","age":36,"gender":"M","address":"451 Clifton Place","employer":"Bluplanet","email":"kelleyochoa@bluplanet.com","city":"Gouglersville","state":"CT"}
{"index":{"_id":"506"}}
{"account_number":506,"balance":43440,"firstname":"Davidson","lastname":"Salas","age":28,"gender":"M","address":"731 Cleveland Street","employer":"Sequitur","email":"davidsonsalas@sequitur.com","city":"Lloyd","state":"ME"}
{"index":{"_id":"513"}}
{"account_number":513,"balance":30040,"firstname":"Maryellen","lastname":"Rose","age":37,"gender":"F","address":"428 Durland Place","employer":"Waterbaby","email":"maryellenrose@waterbaby.com","city":"Kiskimere","state":"RI"}
{"index":{"_id":"518"}}
{"account_number":518,"balance":48954,"firstname":"Finch","lastname":"Curtis","age":29,"gender":"F","address":"137 Ryder Street","employer":"Viagrand","email":"finchcurtis@viagrand.com","city":"Riverton","state":"MO"}
{"index":{"_id":"520"}}
{"account_number":520,"balance":27987,"firstname":"Brandy","lastname":"Calhoun","age":32,"gender":"M","address":"818 Harden Street","employer":"Maxemia","email":"brandycalhoun@maxemia.com","city":"Sidman","state":"OR"}
{"index":{"_id":"525"}}
{"account_number":525,"balance":23545,"firstname":"Holly","lastname":"Miles","age":25,"gender":"M","address":"746 Ludlam Place","employer":"Xurban","email":"hollymiles@xurban.com","city":"Harold","state":"AR"}
{"index":{"_id":"532"}}
{"account_number":532,"balance":17207,"firstname":"Hardin","lastname":"Kirk","age":26,"gender":"M","address":"268 Canarsie Road","employer":"Exposa","email":"hardinkirk@exposa.com","city":"Stouchsburg","state":"IL"}
{"index":{"_id":"537"}}
{"account_number":537,"balance":31069,"firstname":"Morin","lastname":"Frost","age":29,"gender":"M","address":"910 Lake Street","employer":"Primordia","email":"morinfrost@primordia.com","city":"Rivera","state":"DE"}
{"index":{"_id":"544"}}
{"account_number":544,"balance":41735,"firstname":"Short","lastname":"Dennis","age":21,"gender":"F","address":"908 Glen Street","employer":"Minga","email":"shortdennis@minga.com","city":"Dale","state":"KY"}
{"index":{"_id":"549"}}
{"account_number":549,"balance":1932,"firstname":"Jacqueline","lastname":"Maxwell","age":40,"gender":"M","address":"444 Schenck Place","employer":"Fuelworks","email":"jacquelinemaxwell@fuelworks.com","city":"Oretta","state":"OR"}
{"index":{"_id":"551"}}
{"account_number":551,"balance":21732,"firstname":"Milagros","lastname":"Travis","age":27,"gender":"F","address":"380 Murdock Court","employer":"Sloganaut","email":"milagrostravis@sloganaut.com","city":"Homeland","state":"AR"}
{"index":{"_id":"556"}}
{"account_number":556,"balance":36420,"firstname":"Collier","lastname":"Odonnell","age":35,"gender":"M","address":"591 Nolans Lane","employer":"Sultraxin","email":"collierodonnell@sultraxin.com","city":"Fulford","state":"MD"}
{"index":{"_id":"563"}}
{"account_number":563,"balance":43403,"firstname":"Morgan","lastname":"Torres","age":30,"gender":"F","address":"672 Belvidere Street","employer":"Quonata","email":"morgantorres@quonata.com","city":"Hollymead","state":"KY"}
{"index":{"_id":"568"}}
{"account_number":568,"balance":36628,"firstname":"Lesa","lastname":"Maynard","age":29,"gender":"F","address":"295 Whitty Lane","employer":"Coash","email":"lesamaynard@coash.com","city":"Broadlands","state":"VT"}
{"index":{"_id":"570"}}
{"account_number":570,"balance":26751,"firstname":"Church","lastname":"Mercado","age":24,"gender":"F","address":"892 Wyckoff Street","employer":"Xymonk","email":"churchmercado@xymonk.com","city":"Gloucester","state":"KY"}
{"index":{"_id":"575"}}
{"account_number":575,"balance":12588,"firstname":"Buchanan","lastname":"Pope","age":39,"gender":"M","address":"581 Sumner Place","employer":"Stucco","email":"buchananpope@stucco.com","city":"Ellerslie","state":"MD"}
{"index":{"_id":"582"}}
{"account_number":582,"balance":33371,"firstname":"Manning","lastname":"Guthrie","age":24,"gender":"F","address":"271 Jodie Court","employer":"Xerex","email":"manningguthrie@xerex.com","city":"Breinigsville","state":"NM"}
{"index":{"_id":"587"}}
{"account_number":587,"balance":3468,"firstname":"Carly","lastname":"Johns","age":33,"gender":"M","address":"390 Noll Street","employer":"Gallaxia","email":"carlyjohns@gallaxia.com","city":"Emison","state":"DC"}
{"index":{"_id":"594"}}
{"account_number":594,"balance":28194,"firstname":"Golden","lastname":"Donovan","age":26,"gender":"M","address":"199 Jewel Street","employer":"Organica","email":"goldendonovan@organica.com","city":"Macdona","state":"RI"}
{"index":{"_id":"599"}}
{"account_number":599,"balance":11944,"firstname":"Joanna","lastname":"Jennings","age":36,"gender":"F","address":"318 Irving Street","employer":"Extremo","email":"joannajennings@extremo.com","city":"Bartley","state":"MI"}
{"index":{"_id":"602"}}
{"account_number":602,"balance":38699,"firstname":"Mcgowan","lastname":"Mcclain","age":33,"gender":"M","address":"361 Stoddard Place","employer":"Oatfarm","email":"mcgowanmcclain@oatfarm.com","city":"Kapowsin","state":"MI"}
{"index":{"_id":"607"}}
{"account_number":607,"balance":38350,"firstname":"White","lastname":"Small","age":38,"gender":"F","address":"736 Judge Street","employer":"Immunics","email":"whitesmall@immunics.com","city":"Fairfield","state":"HI"}
{"index":{"_id":"614"}}
{"account_number":614,"balance":13157,"firstname":"Salazar","lastname":"Howard","age":35,"gender":"F","address":"847 Imlay Street","employer":"Retrack","email":"salazarhoward@retrack.com","city":"Grill","state":"FL"}
{"index":{"_id":"619"}}
{"account_number":619,"balance":48755,"firstname":"Grimes","lastname":"Reynolds","age":36,"gender":"M","address":"378 Denton Place","employer":"Frenex","email":"grimesreynolds@frenex.com","city":"Murillo","state":"LA"}
{"index":{"_id":"621"}}
{"account_number":621,"balance":35480,"firstname":"Leslie","lastname":"Sloan","age":26,"gender":"F","address":"336 Kansas Place","employer":"Dancity","email":"lesliesloan@dancity.com","city":"Corriganville","state":"AR"}
{"index":{"_id":"626"}}
{"account_number":626,"balance":19498,"firstname":"Ava","lastname":"Richardson","age":31,"gender":"F","address":"666 Nautilus Avenue","employer":"Cinaster","email":"avarichardson@cinaster.com","city":"Sutton","state":"AL"}
{"index":{"_id":"633"}}
{"account_number":633,"balance":35874,"firstname":"Conner","lastname":"Ramos","age":34,"gender":"M","address":"575 Agate Court","employer":"Insource","email":"connerramos@insource.com","city":"Madaket","state":"OK"}
{"index":{"_id":"638"}}
{"account_number":638,"balance":2658,"firstname":"Bridget","lastname":"Gallegos","age":31,"gender":"M","address":"383 Wogan Terrace","employer":"Songlines","email":"bridgetgallegos@songlines.com","city":"Linganore","state":"WA"}
{"index":{"_id":"640"}}
{"account_number":640,"balance":35596,"firstname":"Candace","lastname":"Hancock","age":25,"gender":"M","address":"574 Riverdale Avenue","employer":"Animalia","email":"candacehancock@animalia.com","city":"Blandburg","state":"KY"}
{"index":{"_id":"645"}}
{"account_number":645,"balance":29362,"firstname":"Edwina","lastname":"Hutchinson","age":26,"gender":"F","address":"892 Pacific Street","employer":"Essensia","email":"edwinahutchinson@essensia.com","city":"Dowling","state":"NE"}
{"index":{"_id":"652"}}
{"account_number":652,"balance":17363,"firstname":"Bonner","lastname":"Garner","age":26,"gender":"M","address":"219 Grafton Street","employer":"Utarian","email":"bonnergarner@utarian.com","city":"Vandiver","state":"PA"}
{"index":{"_id":"657"}}
{"account_number":657,"balance":40475,"firstname":"Kathleen","lastname":"Wilder","age":34,"gender":"F","address":"286 Sutter Avenue","employer":"Solgan","email":"kathleenwilder@solgan.com","city":"Graniteville","state":"MI"}
{"index":{"_id":"664"}}
{"account_number":664,"balance":16163,"firstname":"Hart","lastname":"Mccormick","age":40,"gender":"M","address":"144 Guider Avenue","employer":"Dyno","email":"hartmccormick@dyno.com","city":"Carbonville","state":"ID"}
{"index":{"_id":"669"}}
{"account_number":669,"balance":16934,"firstname":"Jewel","lastname":"Estrada","age":28,"gender":"M","address":"896 Meeker Avenue","employer":"Zilla","email":"jewelestrada@zilla.com","city":"Goodville","state":"PA"}
{"index":{"_id":"671"}}
{"account_number":671,"balance":29029,"firstname":"Antoinette","lastname":"Cook","age":34,"gender":"M","address":"375 Cumberland Street","employer":"Harmoney","email":"antoinettecook@harmoney.com","city":"Bergoo","state":"VT"}
{"index":{"_id":"676"}}
{"account_number":676,"balance":23842,"firstname":"Lisa","lastname":"Dudley","age":34,"gender":"M","address":"506 Vanderveer Street","employer":"Tropoli","email":"lisadudley@tropoli.com","city":"Konterra","state":"NY"}
{"index":{"_id":"683"}}
{"account_number":683,"balance":4381,"firstname":"Matilda","lastname":"Berger","age":39,"gender":"M","address":"884 Noble Street","employer":"Fibrodyne","email":"matildaberger@fibrodyne.com","city":"Shepardsville","state":"TN"}
{"index":{"_id":"688"}}
{"account_number":688,"balance":17931,"firstname":"Freeman","lastname":"Zamora","age":22,"gender":"F","address":"114 Herzl Street","employer":"Elemantra","email":"freemanzamora@elemantra.com","city":"Libertytown","state":"NM"}
{"index":{"_id":"690"}}
{"account_number":690,"balance":18127,"firstname":"Russo","lastname":"Swanson","age":35,"gender":"F","address":"256 Roebling Street","employer":"Zaj","email":"russoswanson@zaj.com","city":"Hoagland","state":"MI"}
{"index":{"_id":"695"}}
{"account_number":695,"balance":36800,"firstname":"Gonzales","lastname":"Mcfarland","age":26,"gender":"F","address":"647 Louisa Street","employer":"Songbird","email":"gonzalesmcfarland@songbird.com","city":"Crisman","state":"ID"}
{"index":{"_id":"703"}}
{"account_number":703,"balance":27443,"firstname":"Dona","lastname":"Burton","age":29,"gender":"M","address":"489 Flatlands Avenue","employer":"Cytrex","email":"donaburton@cytrex.com","city":"Reno","state":"VA"}
{"index":{"_id":"708"}}
{"account_number":708,"balance":34002,"firstname":"May","lastname":"Ortiz","age":28,"gender":"F","address":"244 Chauncey Street","employer":"Syntac","email":"mayortiz@syntac.com","city":"Munjor","state":"ID"}
{"index":{"_id":"710"}}
{"account_number":710,"balance":33650,"firstname":"Shelton","lastname":"Stark","age":37,"gender":"M","address":"404 Ovington Avenue","employer":"Kraggle","email":"sheltonstark@kraggle.com","city":"Ogema","state":"TN"}
{"index":{"_id":"715"}}
{"account_number":715,"balance":23734,"firstname":"Tammi","lastname":"Hodge","age":24,"gender":"M","address":"865 Church Lane","employer":"Netur","email":"tammihodge@netur.com","city":"Lacomb","state":"KS"}
{"index":{"_id":"722"}}
{"account_number":722,"balance":27256,"firstname":"Roberts","lastname":"Beasley","age":34,"gender":"F","address":"305 Kings Hwy","employer":"Quintity","email":"robertsbeasley@quintity.com","city":"Hayden","state":"PA"}
{"index":{"_id":"727"}}
{"account_number":727,"balance":27263,"firstname":"Natasha","lastname":"Knapp","age":36,"gender":"M","address":"723 Hubbard Street","employer":"Exostream","email":"natashaknapp@exostream.com","city":"Trexlertown","state":"LA"}
{"index":{"_id":"734"}}
{"account_number":734,"balance":20325,"firstname":"Keri","lastname":"Kinney","age":23,"gender":"M","address":"490 Balfour Place","employer":"Retrotex","email":"kerikinney@retrotex.com","city":"Salunga","state":"PA"}
{"index":{"_id":"739"}}
{"account_number":739,"balance":39063,"firstname":"Gwen","lastname":"Hardy","age":33,"gender":"F","address":"733 Stuart Street","employer":"Exozent","email":"gwenhardy@exozent.com","city":"Drytown","state":"NY"}
{"index":{"_id":"741"}}
{"account_number":741,"balance":33074,"firstname":"Nielsen","lastname":"Good","age":22,"gender":"M","address":"404 Norfolk Street","employer":"Kiggle","email":"nielsengood@kiggle.com","city":"Cumberland","state":"WA"}
{"index":{"_id":"746"}}
{"account_number":746,"balance":15970,"firstname":"Marguerite","lastname":"Wall","age":28,"gender":"F","address":"364 Crosby Avenue","employer":"Aquoavo","email":"margueritewall@aquoavo.com","city":"Jeff","state":"MI"}
{"index":{"_id":"753"}}
{"account_number":753,"balance":33340,"firstname":"Katina","lastname":"Alford","age":21,"gender":"F","address":"690 Ross Street","employer":"Intrawear","email":"katinaalford@intrawear.com","city":"Grimsley","state":"OK"}
{"index":{"_id":"758"}}
{"account_number":758,"balance":15739,"firstname":"Berta","lastname":"Short","age":28,"gender":"M","address":"149 Surf Avenue","employer":"Ozean","email":"bertashort@ozean.com","city":"Odessa","state":"UT"}
{"index":{"_id":"760"}}
{"account_number":760,"balance":40996,"firstname":"Rhea","lastname":"Blair","age":37,"gender":"F","address":"440 Hubbard Place","employer":"Bicol","email":"rheablair@bicol.com","city":"Stockwell","state":"LA"}
{"index":{"_id":"765"}}
{"account_number":765,"balance":31278,"firstname":"Knowles","lastname":"Cunningham","age":23,"gender":"M","address":"753 Macdougal Street","employer":"Thredz","email":"knowlescunningham@thredz.com","city":"Thomasville","state":"WA"}
{"index":{"_id":"772"}}
{"account_number":772,"balance":37849,"firstname":"Eloise","lastname":"Sparks","age":21,"gender":"M","address":"608 Willow Street","employer":"Satiance","email":"eloisesparks@satiance.com","city":"Richford","state":"NY"}
{"index":{"_id":"777"}}
{"account_number":777,"balance":48294,"firstname":"Adkins","lastname":"Mejia","age":32,"gender":"M","address":"186 Oxford Walk","employer":"Datagen","email":"adkinsmejia@datagen.com","city":"Faywood","state":"OK"}
{"index":{"_id":"784"}}
{"account_number":784,"balance":25291,"firstname":"Mabel","lastname":"Thornton","age":21,"gender":"M","address":"124 Louisiana Avenue","employer":"Zolavo","email":"mabelthornton@zolavo.com","city":"Lynn","state":"AL"}
{"index":{"_id":"789"}}
{"account_number":789,"balance":8760,"firstname":"Cunningham","lastname":"Kerr","age":27,"gender":"F","address":"154 Sharon Street","employer":"Polarium","email":"cunninghamkerr@polarium.com","city":"Tuskahoma","state":"MS"}
{"index":{"_id":"791"}}
{"account_number":791,"balance":48249,"firstname":"Janine","lastname":"Huber","age":38,"gender":"F","address":"348 Porter Avenue","employer":"Viocular","email":"janinehuber@viocular.com","city":"Fivepointville","state":"MA"}
{"index":{"_id":"796"}}
{"account_number":796,"balance":23503,"firstname":"Mona","lastname":"Craft","age":35,"gender":"F","address":"511 Henry Street","employer":"Opticom","email":"monacraft@opticom.com","city":"Websterville","state":"IN"}
{"index":{"_id":"804"}}
{"account_number":804,"balance":23610,"firstname":"Rojas","lastname":"Oneal","age":27,"gender":"M","address":"669 Sandford Street","employer":"Glukgluk","email":"rojasoneal@glukgluk.com","city":"Wheaton","state":"ME"}
{"index":{"_id":"809"}}
{"account_number":809,"balance":47812,"firstname":"Christie","lastname":"Strickland","age":30,"gender":"M","address":"346 Bancroft Place","employer":"Anarco","email":"christiestrickland@anarco.com","city":"Baden","state":"NV"}
{"index":{"_id":"811"}}
{"account_number":811,"balance":26007,"firstname":"Walls","lastname":"Rogers","age":28,"gender":"F","address":"352 Freeman Street","employer":"Geekmosis","email":"wallsrogers@geekmosis.com","city":"Caroleen","state":"NV"}
{"index":{"_id":"816"}}
{"account_number":816,"balance":9567,"firstname":"Cornelia","lastname":"Lane","age":20,"gender":"F","address":"384 Bainbridge Street","employer":"Sulfax","email":"cornelialane@sulfax.com","city":"Elizaville","state":"MS"}
{"index":{"_id":"823"}}
{"account_number":823,"balance":48726,"firstname":"Celia","lastname":"Bernard","age":33,"gender":"F","address":"466 Amboy Street","employer":"Mitroc","email":"celiabernard@mitroc.com","city":"Skyland","state":"GA"}
{"index":{"_id":"828"}}
{"account_number":828,"balance":44890,"firstname":"Blanche","lastname":"Holmes","age":33,"gender":"F","address":"605 Stryker Court","employer":"Motovate","email":"blancheholmes@motovate.com","city":"Loomis","state":"KS"}
{"index":{"_id":"830"}}
{"account_number":830,"balance":45210,"firstname":"Louella","lastname":"Chan","age":23,"gender":"M","address":"511 Heath Place","employer":"Conferia","email":"louellachan@conferia.com","city":"Brookfield","state":"OK"}
{"index":{"_id":"835"}}
{"account_number":835,"balance":46558,"firstname":"Glover","lastname":"Rutledge","age":25,"gender":"F","address":"641 Royce Street","employer":"Ginkogene","email":"gloverrutledge@ginkogene.com","city":"Dixonville","state":"VA"}
{"index":{"_id":"842"}}
{"account_number":842,"balance":49587,"firstname":"Meagan","lastname":"Buckner","age":23,"gender":"F","address":"833 Bushwick Court","employer":"Biospan","email":"meaganbuckner@biospan.com","city":"Craig","state":"TX"}
{"index":{"_id":"847"}}
{"account_number":847,"balance":8652,"firstname":"Antonia","lastname":"Duncan","age":23,"gender":"M","address":"644 Stryker Street","employer":"Talae","email":"antoniaduncan@talae.com","city":"Dawn","state":"MO"}
{"index":{"_id":"854"}}
{"account_number":854,"balance":49795,"firstname":"Jimenez","lastname":"Barry","age":25,"gender":"F","address":"603 Cooper Street","employer":"Verton","email":"jimenezbarry@verton.com","city":"Moscow","state":"AL"}
{"index":{"_id":"859"}}
{"account_number":859,"balance":20734,"firstname":"Beulah","lastname":"Stuart","age":24,"gender":"F","address":"651 Albemarle Terrace","employer":"Hatology","email":"beulahstuart@hatology.com","city":"Waiohinu","state":"RI"}
{"index":{"_id":"861"}}
{"account_number":861,"balance":44173,"firstname":"Jaime","lastname":"Wilson","age":35,"gender":"M","address":"680 Richardson Street","employer":"Temorak","email":"jaimewilson@temorak.com","city":"Fidelis","state":"FL"}
{"index":{"_id":"866"}}
{"account_number":866,"balance":45565,"firstname":"Araceli","lastname":"Woodward","age":28,"gender":"M","address":"326 Meadow Street","employer":"Olympix","email":"araceliwoodward@olympix.com","city":"Dana","state":"KS"}
{"index":{"_id":"873"}}
{"account_number":873,"balance":43931,"firstname":"Tisha","lastname":"Cotton","age":39,"gender":"F","address":"432 Lincoln Road","employer":"Buzzmaker","email":"tishacotton@buzzmaker.com","city":"Bluetown","state":"GA"}
{"index":{"_id":"878"}}
{"account_number":878,"balance":49159,"firstname":"Battle","lastname":"Blackburn","age":40,"gender":"F","address":"234 Hendrix Street","employer":"Zilphur","email":"battleblackburn@zilphur.com","city":"Wanamie","state":"PA"}
{"index":{"_id":"880"}}
{"account_number":880,"balance":22575,"firstname":"Christian","lastname":"Myers","age":35,"gender":"M","address":"737 Crown Street","employer":"Combogen","email":"christianmyers@combogen.com","city":"Abrams","state":"OK"}
{"index":{"_id":"885"}}
{"account_number":885,"balance":31661,"firstname":"Valdez","lastname":"Roberson","age":40,"gender":"F","address":"227 Scholes Street","employer":"Delphide","email":"valdezroberson@delphide.com","city":"Chilton","state":"MT"}
{"index":{"_id":"892"}}
{"account_number":892,"balance":44974,"firstname":"Hill","lastname":"Hayes","age":29,"gender":"M","address":"721 Dooley Street","employer":"Fuelton","email":"hillhayes@fuelton.com","city":"Orason","state":"MT"}
{"index":{"_id":"897"}}
{"account_number":897,"balance":45973,"firstname":"Alyson","lastname":"Irwin","age":25,"gender":"M","address":"731 Poplar Street","employer":"Quizka","email":"alysonirwin@quizka.com","city":"Singer","state":"VA"}
{"index":{"_id":"900"}}
{"account_number":900,"balance":6124,"firstname":"Gonzalez","lastname":"Watson","age":23,"gender":"M","address":"624 Sullivan Street","employer":"Marvane","email":"gonzalezwatson@marvane.com","city":"Wikieup","state":"IL"}
{"index":{"_id":"905"}}
{"account_number":905,"balance":29438,"firstname":"Schultz","lastname":"Moreno","age":20,"gender":"F","address":"761 Cedar Street","employer":"Paragonia","email":"schultzmoreno@paragonia.com","city":"Glenshaw","state":"SC"}
{"index":{"_id":"912"}}
{"account_number":912,"balance":13675,"firstname":"Flora","lastname":"Alvarado","age":26,"gender":"M","address":"771 Vandervoort Avenue","employer":"Boilicon","email":"floraalvarado@boilicon.com","city":"Vivian","state":"ID"}
{"index":{"_id":"917"}}
{"account_number":917,"balance":47782,"firstname":"Parks","lastname":"Hurst","age":24,"gender":"M","address":"933 Cozine Avenue","employer":"Pyramis","email":"parkshurst@pyramis.com","city":"Lindcove","state":"GA"}
{"index":{"_id":"924"}}
{"account_number":924,"balance":3811,"firstname":"Hilary","lastname":"Leonard","age":24,"gender":"M","address":"235 Hegeman Avenue","employer":"Metroz","email":"hilaryleonard@metroz.com","city":"Roosevelt","state":"ME"}
{"index":{"_id":"929"}}
{"account_number":929,"balance":34708,"firstname":"Willie","lastname":"Hickman","age":35,"gender":"M","address":"430 Devoe Street","employer":"Apextri","email":"williehickman@apextri.com","city":"Clay","state":"MS"}
{"index":{"_id":"931"}}
{"account_number":931,"balance":8244,"firstname":"Ingrid","lastname":"Garcia","age":23,"gender":"F","address":"674 Indiana Place","employer":"Balooba","email":"ingridgarcia@balooba.com","city":"Interlochen","state":"AZ"}
{"index":{"_id":"936"}}
{"account_number":936,"balance":22430,"firstname":"Beth","lastname":"Frye","age":36,"gender":"M","address":"462 Thatford Avenue","employer":"Puria","email":"bethfrye@puria.com","city":"Hiseville","state":"LA"}
{"index":{"_id":"943"}}
{"account_number":943,"balance":24187,"firstname":"Wagner","lastname":"Griffin","age":23,"gender":"M","address":"489 Ellery Street","employer":"Gazak","email":"wagnergriffin@gazak.com","city":"Lorraine","state":"HI"}
{"index":{"_id":"948"}}
{"account_number":948,"balance":37074,"firstname":"Sargent","lastname":"Powers","age":40,"gender":"M","address":"532 Fiske Place","employer":"Accuprint","email":"sargentpowers@accuprint.com","city":"Umapine","state":"AK"}
{"index":{"_id":"950"}}
{"account_number":950,"balance":30916,"firstname":"Sherrie","lastname":"Patel","age":32,"gender":"F","address":"658 Langham Street","employer":"Futurize","email":"sherriepatel@futurize.com","city":"Garfield","state":"OR"}
{"index":{"_id":"955"}}
{"account_number":955,"balance":41621,"firstname":"Klein","lastname":"Kemp","age":33,"gender":"M","address":"370 Vanderbilt Avenue","employer":"Synkgen","email":"kleinkemp@synkgen.com","city":"Bonanza","state":"FL"}
{"index":{"_id":"962"}}
{"account_number":962,"balance":32096,"firstname":"Trujillo","lastname":"Wilcox","age":21,"gender":"F","address":"914 Duffield Street","employer":"Extragene","email":"trujillowilcox@extragene.com","city":"Golconda","state":"MA"}
{"index":{"_id":"967"}}
{"account_number":967,"balance":19161,"firstname":"Carrie","lastname":"Huffman","age":36,"gender":"F","address":"240 Sands Street","employer":"Injoy","email":"carriehuffman@injoy.com","city":"Leroy","state":"CA"}
{"index":{"_id":"974"}}
{"account_number":974,"balance":38082,"firstname":"Deborah","lastname":"Yang","age":26,"gender":"F","address":"463 Goodwin Place","employer":"Entogrok","email":"deborahyang@entogrok.com","city":"Herald","state":"KY"}
{"index":{"_id":"979"}}
{"account_number":979,"balance":43130,"firstname":"Vaughn","lastname":"Pittman","age":29,"gender":"M","address":"446 Tompkins Place","employer":"Phormula","email":"vaughnpittman@phormula.com","city":"Fingerville","state":"WI"}
{"index":{"_id":"981"}}
{"account_number":981,"balance":20278,"firstname":"Nolan","lastname":"Warner","age":29,"gender":"F","address":"753 Channel Avenue","employer":"Interodeo","email":"nolanwarner@interodeo.com","city":"Layhill","state":"MT"}
{"index":{"_id":"986"}}
{"account_number":986,"balance":35086,"firstname":"Norris","lastname":"Hubbard","age":31,"gender":"M","address":"600 Celeste Court","employer":"Printspan","email":"norrishubbard@printspan.com","city":"Cassel","state":"MI"}
{"index":{"_id":"993"}}
{"account_number":993,"balance":26487,"firstname":"Campos","lastname":"Olsen","age":37,"gender":"M","address":"873 Covert Street","employer":"Isbol","email":"camposolsen@isbol.com","city":"Glendale","state":"AK"}
{"index":{"_id":"998"}}
{"account_number":998,"balance":16869,"firstname":"Letha","lastname":"Baker","age":40,"gender":"F","address":"206 Llama Court","employer":"Dognosis","email":"lethabaker@dognosis.com","city":"Dunlo","state":"WV"}
{"index":{"_id":"2"}}
{"account_number":2,"balance":28838,"firstname":"Roberta","lastname":"Bender","age":22,"gender":"F","address":"560 Kingsway Place","employer":"Chillium","email":"robertabender@chillium.com","city":"Bennett","state":"LA"}
{"index":{"_id":"7"}}
{"account_number":7,"balance":39121,"firstname":"Levy","lastname":"Richard","age":22,"gender":"M","address":"820 Logan Street","employer":"Teraprene","email":"levyrichard@teraprene.com","city":"Shrewsbury","state":"MO"}
{"index":{"_id":"14"}}
{"account_number":14,"balance":20480,"firstname":"Erma","lastname":"Kane","age":39,"gender":"F","address":"661 Vista Place","employer":"Stockpost","email":"ermakane@stockpost.com","city":"Chamizal","state":"NY"}
{"index":{"_id":"19"}}
{"account_number":19,"balance":27894,"firstname":"Schwartz","lastname":"Buchanan","age":28,"gender":"F","address":"449 Mersereau Court","employer":"Sybixtex","email":"schwartzbuchanan@sybixtex.com","city":"Greenwich","state":"KS"}
{"index":{"_id":"21"}}
{"account_number":21,"balance":7004,"firstname":"Estella","lastname":"Paul","age":38,"gender":"M","address":"859 Portal Street","employer":"Zillatide","email":"estellapaul@zillatide.com","city":"Churchill","state":"WV"}
{"index":{"_id":"26"}}
{"account_number":26,"balance":14127,"firstname":"Lorraine","lastname":"Mccullough","age":39,"gender":"F","address":"157 Dupont Street","employer":"Zosis","email":"lorrainemccullough@zosis.com","city":"Dennard","state":"NH"}
{"index":{"_id":"33"}}
{"account_number":33,"balance":35439,"firstname":"Savannah","lastname":"Kirby","age":30,"gender":"F","address":"372 Malta Street","employer":"Musanpoly","email":"savannahkirby@musanpoly.com","city":"Muse","state":"AK"}
{"index":{"_id":"38"}}
{"account_number":38,"balance":10511,"firstname":"Erna","lastname":"Fields","age":32,"gender":"M","address":"357 Maple Street","employer":"Eweville","email":"ernafields@eweville.com","city":"Twilight","state":"MS"}
{"index":{"_id":"40"}}
{"account_number":40,"balance":33882,"firstname":"Pace","lastname":"Molina","age":40,"gender":"M","address":"263 Ovington Court","employer":"Cytrak","email":"pacemolina@cytrak.com","city":"Silkworth","state":"OR"}
{"index":{"_id":"45"}}
{"account_number":45,"balance":44478,"firstname":"Geneva","lastname":"Morin","age":21,"gender":"F","address":"357 Herkimer Street","employer":"Ezent","email":"genevamorin@ezent.com","city":"Blanco","state":"AZ"}
{"index":{"_id":"52"}}
{"account_number":52,"balance":46425,"firstname":"Kayla","lastname":"Bradshaw","age":31,"gender":"M","address":"449 Barlow Drive","employer":"Magnemo","email":"kaylabradshaw@magnemo.com","city":"Wawona","state":"AZ"}
{"index":{"_id":"57"}}
{"account_number":57,"balance":8705,"firstname":"Powell","lastname":"Herring","age":21,"gender":"M","address":"263 Merit Court","employer":"Digiprint","email":"powellherring@digiprint.com","city":"Coral","state":"MT"}
{"index":{"_id":"64"}}
{"account_number":64,"balance":44036,"firstname":"Miles","lastname":"Battle","age":35,"gender":"F","address":"988 Homecrest Avenue","employer":"Koffee","email":"milesbattle@koffee.com","city":"Motley","state":"ID"}
{"index":{"_id":"69"}}
{"account_number":69,"balance":14253,"firstname":"Desiree","lastname":"Harrison","age":24,"gender":"M","address":"694 Garland Court","employer":"Barkarama","email":"desireeharrison@barkarama.com","city":"Hackneyville","state":"GA"}
{"index":{"_id":"71"}}
{"account_number":71,"balance":38201,"firstname":"Sharpe","lastname":"Hoffman","age":39,"gender":"F","address":"450 Conklin Avenue","employer":"Centree","email":"sharpehoffman@centree.com","city":"Urbana","state":"WY"}
{"index":{"_id":"76"}}
{"account_number":76,"balance":38345,"firstname":"Claudette","lastname":"Beard","age":24,"gender":"F","address":"748 Dorset Street","employer":"Repetwire","email":"claudettebeard@repetwire.com","city":"Caln","state":"TX"}
{"index":{"_id":"83"}}
{"account_number":83,"balance":35928,"firstname":"Mayo","lastname":"Cleveland","age":28,"gender":"M","address":"720 Brooklyn Road","employer":"Indexia","email":"mayocleveland@indexia.com","city":"Roberts","state":"ND"}
{"index":{"_id":"88"}}
{"account_number":88,"balance":26418,"firstname":"Adela","lastname":"Tyler","age":21,"gender":"F","address":"737 Clove Road","employer":"Surelogic","email":"adelatyler@surelogic.com","city":"Boling","state":"SD"}
{"index":{"_id":"90"}}
{"account_number":90,"balance":25332,"firstname":"Herman","lastname":"Snyder","age":22,"gender":"F","address":"737 College Place","employer":"Lunchpod","email":"hermansnyder@lunchpod.com","city":"Flintville","state":"IA"}
{"index":{"_id":"95"}}
{"account_number":95,"balance":1650,"firstname":"Dominguez","lastname":"Le","age":20,"gender":"M","address":"539 Grace Court","employer":"Portica","email":"dominguezle@portica.com","city":"Wollochet","state":"KS"}
{"index":{"_id":"103"}}
{"account_number":103,"balance":11253,"firstname":"Calhoun","lastname":"Bruce","age":33,"gender":"F","address":"731 Clarkson Avenue","employer":"Automon","email":"calhounbruce@automon.com","city":"Marienthal","state":"IL"}
{"index":{"_id":"108"}}
{"account_number":108,"balance":19015,"firstname":"Christensen","lastname":"Weaver","age":21,"gender":"M","address":"398 Dearborn Court","employer":"Quilk","email":"christensenweaver@quilk.com","city":"Belvoir","state":"TX"}
{"index":{"_id":"110"}}
{"account_number":110,"balance":4850,"firstname":"Daphne","lastname":"Byrd","age":23,"gender":"F","address":"239 Conover Street","employer":"Freakin","email":"daphnebyrd@freakin.com","city":"Taft","state":"MN"}
{"index":{"_id":"115"}}
{"account_number":115,"balance":18750,"firstname":"Nikki","lastname":"Doyle","age":31,"gender":"F","address":"537 Clara Street","employer":"Fossiel","email":"nikkidoyle@fossiel.com","city":"Caron","state":"MS"}
{"index":{"_id":"122"}}
{"account_number":122,"balance":17128,"firstname":"Aurora","lastname":"Fry","age":31,"gender":"F","address":"227 Knapp Street","employer":"Makingway","email":"aurorafry@makingway.com","city":"Maybell","state":"NE"}
{"index":{"_id":"127"}}
{"account_number":127,"balance":48734,"firstname":"Diann","lastname":"Mclaughlin","age":33,"gender":"F","address":"340 Clermont Avenue","employer":"Enomen","email":"diannmclaughlin@enomen.com","city":"Rutherford","state":"ND"}
{"index":{"_id":"134"}}
{"account_number":134,"balance":33829,"firstname":"Madelyn","lastname":"Norris","age":30,"gender":"F","address":"176 Noel Avenue","employer":"Endicil","email":"madelynnorris@endicil.com","city":"Walker","state":"NE"}
{"index":{"_id":"139"}}
{"account_number":139,"balance":18444,"firstname":"Rios","lastname":"Todd","age":35,"gender":"F","address":"281 Georgia Avenue","employer":"Uberlux","email":"riostodd@uberlux.com","city":"Hannasville","state":"PA"}
{"index":{"_id":"141"}}
{"account_number":141,"balance":20790,"firstname":"Liliana","lastname":"Caldwell","age":29,"gender":"M","address":"414 Huron Street","employer":"Rubadub","email":"lilianacaldwell@rubadub.com","city":"Hiwasse","state":"OK"}
{"index":{"_id":"146"}}
{"account_number":146,"balance":39078,"firstname":"Lang","lastname":"Kaufman","age":32,"gender":"F","address":"626 Beverley Road","employer":"Rodeomad","email":"langkaufman@rodeomad.com","city":"Mahtowa","state":"RI"}
{"index":{"_id":"153"}}
{"account_number":153,"balance":32074,"firstname":"Bird","lastname":"Cochran","age":31,"gender":"F","address":"691 Bokee Court","employer":"Supremia","email":"birdcochran@supremia.com","city":"Barrelville","state":"NE"}
{"index":{"_id":"158"}}
{"account_number":158,"balance":9380,"firstname":"Natalie","lastname":"Mcdowell","age":27,"gender":"M","address":"953 Roder Avenue","employer":"Myopium","email":"nataliemcdowell@myopium.com","city":"Savage","state":"ND"}
{"index":{"_id":"160"}}
{"account_number":160,"balance":48974,"firstname":"Hull","lastname":"Cherry","age":23,"gender":"F","address":"275 Beaumont Street","employer":"Noralex","email":"hullcherry@noralex.com","city":"Whipholt","state":"WA"}
{"index":{"_id":"165"}}
{"account_number":165,"balance":18956,"firstname":"Sims","lastname":"Mckay","age":40,"gender":"F","address":"205 Jackson Street","employer":"Comtour","email":"simsmckay@comtour.com","city":"Tilden","state":"DC"}
{"index":{"_id":"172"}}
{"account_number":172,"balance":18356,"firstname":"Marie","lastname":"Whitehead","age":20,"gender":"M","address":"704 Monaco Place","employer":"Sultrax","email":"mariewhitehead@sultrax.com","city":"Dragoon","state":"IL"}
{"index":{"_id":"177"}}
{"account_number":177,"balance":48972,"firstname":"Harris","lastname":"Gross","age":40,"gender":"F","address":"468 Suydam Street","employer":"Kidstock","email":"harrisgross@kidstock.com","city":"Yettem","state":"KY"}
{"index":{"_id":"184"}}
{"account_number":184,"balance":9157,"firstname":"Cathy","lastname":"Morrison","age":27,"gender":"M","address":"882 Pine Street","employer":"Zytrek","email":"cathymorrison@zytrek.com","city":"Fedora","state":"FL"}
{"index":{"_id":"189"}}
{"account_number":189,"balance":20167,"firstname":"Ada","lastname":"Cortez","age":38,"gender":"F","address":"700 Forest Place","employer":"Micronaut","email":"adacortez@micronaut.com","city":"Eagletown","state":"TX"}
{"index":{"_id":"191"}}
{"account_number":191,"balance":26172,"firstname":"Barr","lastname":"Sharpe","age":28,"gender":"M","address":"428 Auburn Place","employer":"Ziggles","email":"barrsharpe@ziggles.com","city":"Springdale","state":"KS"}
{"index":{"_id":"196"}}
{"account_number":196,"balance":29931,"firstname":"Caldwell","lastname":"Daniel","age":28,"gender":"F","address":"405 Oliver Street","employer":"Furnigeer","email":"caldwelldaniel@furnigeer.com","city":"Zortman","state":"NE"}
{"index":{"_id":"204"}}
{"account_number":204,"balance":27714,"firstname":"Mavis","lastname":"Deleon","age":39,"gender":"F","address":"400 Waldane Court","employer":"Lotron","email":"mavisdeleon@lotron.com","city":"Stollings","state":"LA"}
{"index":{"_id":"209"}}
{"account_number":209,"balance":31052,"firstname":"Myers","lastname":"Noel","age":30,"gender":"F","address":"691 Alton Place","employer":"Greeker","email":"myersnoel@greeker.com","city":"Hinsdale","state":"KY"}
{"index":{"_id":"211"}}
{"account_number":211,"balance":21539,"firstname":"Graciela","lastname":"Vaughan","age":22,"gender":"M","address":"558 Montauk Court","employer":"Fishland","email":"gracielavaughan@fishland.com","city":"Madrid","state":"PA"}
{"index":{"_id":"216"}}
{"account_number":216,"balance":11422,"firstname":"Price","lastname":"Haley","age":35,"gender":"M","address":"233 Portland Avenue","employer":"Zeam","email":"pricehaley@zeam.com","city":"Titanic","state":"UT"}
{"index":{"_id":"223"}}
{"account_number":223,"balance":9528,"firstname":"Newton","lastname":"Fletcher","age":26,"gender":"F","address":"654 Dewitt Avenue","employer":"Assistia","email":"newtonfletcher@assistia.com","city":"Nipinnawasee","state":"AK"}
{"index":{"_id":"228"}}
{"account_number":228,"balance":10543,"firstname":"Rosella","lastname":"Albert","age":20,"gender":"M","address":"185 Gotham Avenue","employer":"Isoplex","email":"rosellaalbert@isoplex.com","city":"Finzel","state":"NY"}
{"index":{"_id":"230"}}
{"account_number":230,"balance":10829,"firstname":"Chris","lastname":"Raymond","age":28,"gender":"F","address":"464 Remsen Street","employer":"Cogentry","email":"chrisraymond@cogentry.com","city":"Bowmansville","state":"SD"}
{"index":{"_id":"235"}}
{"account_number":235,"balance":17729,"firstname":"Mcpherson","lastname":"Mueller","age":31,"gender":"M","address":"541 Strong Place","employer":"Tingles","email":"mcphersonmueller@tingles.com","city":"Brantleyville","state":"AR"}
{"index":{"_id":"242"}}
{"account_number":242,"balance":42318,"firstname":"Berger","lastname":"Roach","age":21,"gender":"M","address":"125 Wakeman Place","employer":"Ovium","email":"bergerroach@ovium.com","city":"Hessville","state":"WI"}
{"index":{"_id":"247"}}
{"account_number":247,"balance":45123,"firstname":"Mccormick","lastname":"Moon","age":37,"gender":"M","address":"582 Brighton Avenue","employer":"Norsup","email":"mccormickmoon@norsup.com","city":"Forestburg","state":"DE"}
{"index":{"_id":"254"}}
{"account_number":254,"balance":35104,"firstname":"Yang","lastname":"Dodson","age":21,"gender":"M","address":"531 Lott Street","employer":"Mondicil","email":"yangdodson@mondicil.com","city":"Enoree","state":"UT"}
{"index":{"_id":"259"}}
{"account_number":259,"balance":41877,"firstname":"Eleanor","lastname":"Gonzalez","age":30,"gender":"M","address":"800 Sumpter Street","employer":"Futuris","email":"eleanorgonzalez@futuris.com","city":"Jenkinsville","state":"ID"}
{"index":{"_id":"261"}}
{"account_number":261,"balance":39998,"firstname":"Millicent","lastname":"Pickett","age":34,"gender":"F","address":"722 Montieth Street","employer":"Gushkool","email":"millicentpickett@gushkool.com","city":"Norwood","state":"MS"}
{"index":{"_id":"266"}}
{"account_number":266,"balance":2777,"firstname":"Monique","lastname":"Conner","age":35,"gender":"F","address":"489 Metrotech Courtr","employer":"Flotonic","email":"moniqueconner@flotonic.com","city":"Retsof","state":"MD"}
{"index":{"_id":"273"}}
{"account_number":273,"balance":11181,"firstname":"Murphy","lastname":"Chandler","age":20,"gender":"F","address":"569 Bradford Street","employer":"Zilch","email":"murphychandler@zilch.com","city":"Vicksburg","state":"FL"}
{"index":{"_id":"278"}}
{"account_number":278,"balance":22530,"firstname":"Tamra","lastname":"Navarro","age":27,"gender":"F","address":"175 Woodruff Avenue","employer":"Norsul","email":"tamranavarro@norsul.com","city":"Glasgow","state":"VT"}
{"index":{"_id":"280"}}
{"account_number":280,"balance":3380,"firstname":"Vilma","lastname":"Shields","age":26,"gender":"F","address":"133 Berriman Street","employer":"Applidec","email":"vilmashields@applidec.com","city":"Adamstown","state":"ME"}
{"index":{"_id":"285"}}
{"account_number":285,"balance":47369,"firstname":"Hilda","lastname":"Phillips","age":28,"gender":"F","address":"618 Nixon Court","employer":"Comcur","email":"hildaphillips@comcur.com","city":"Siglerville","state":"NC"}
{"index":{"_id":"292"}}
{"account_number":292,"balance":26679,"firstname":"Morrow","lastname":"Greene","age":20,"gender":"F","address":"691 Nassau Street","employer":"Columella","email":"morrowgreene@columella.com","city":"Sanborn","state":"FL"}
{"index":{"_id":"297"}}
{"account_number":297,"balance":20508,"firstname":"Tucker","lastname":"Patrick","age":35,"gender":"F","address":"978 Whitwell Place","employer":"Valreda","email":"tuckerpatrick@valreda.com","city":"Deseret","state":"CO"}
{"index":{"_id":"300"}}
{"account_number":300,"balance":25654,"firstname":"Lane","lastname":"Tate","age":26,"gender":"F","address":"632 Kay Court","employer":"Genesynk","email":"lanetate@genesynk.com","city":"Lowell","state":"MO"}
{"index":{"_id":"305"}}
{"account_number":305,"balance":11655,"firstname":"Augusta","lastname":"Winters","age":29,"gender":"F","address":"377 Paerdegat Avenue","employer":"Vendblend","email":"augustawinters@vendblend.com","city":"Gwynn","state":"MA"}
{"index":{"_id":"312"}}
{"account_number":312,"balance":8511,"firstname":"Burgess","lastname":"Gentry","age":25,"gender":"F","address":"382 Bergen Court","employer":"Orbixtar","email":"burgessgentry@orbixtar.com","city":"Conestoga","state":"WI"}
{"index":{"_id":"317"}}
{"account_number":317,"balance":31968,"firstname":"Ruiz","lastname":"Morris","age":31,"gender":"F","address":"972 Dean Street","employer":"Apex","email":"ruizmorris@apex.com","city":"Jacksonwald","state":"WV"}
{"index":{"_id":"324"}}
{"account_number":324,"balance":44976,"firstname":"Gladys","lastname":"Erickson","age":22,"gender":"M","address":"250 Battery Avenue","employer":"Eternis","email":"gladyserickson@eternis.com","city":"Marne","state":"IA"}
{"index":{"_id":"329"}}
{"account_number":329,"balance":31138,"firstname":"Nellie","lastname":"Mercer","age":25,"gender":"M","address":"967 Ebony Court","employer":"Scenty","email":"nelliemercer@scenty.com","city":"Jardine","state":"AK"}
{"index":{"_id":"331"}}
{"account_number":331,"balance":46004,"firstname":"Gibson","lastname":"Potts","age":34,"gender":"F","address":"994 Dahill Road","employer":"Zensus","email":"gibsonpotts@zensus.com","city":"Frizzleburg","state":"CO"}
{"index":{"_id":"336"}}
{"account_number":336,"balance":40891,"firstname":"Dudley","lastname":"Avery","age":25,"gender":"M","address":"405 Powers Street","employer":"Genmom","email":"dudleyavery@genmom.com","city":"Clarksburg","state":"CO"}
{"index":{"_id":"343"}}
{"account_number":343,"balance":37684,"firstname":"Robbie","lastname":"Logan","age":29,"gender":"M","address":"488 Linden Boulevard","employer":"Hydrocom","email":"robbielogan@hydrocom.com","city":"Stockdale","state":"TN"}
{"index":{"_id":"348"}}
{"account_number":348,"balance":1360,"firstname":"Karina","lastname":"Russell","age":37,"gender":"M","address":"797 Moffat Street","employer":"Limozen","email":"karinarussell@limozen.com","city":"Riegelwood","state":"RI"}
{"index":{"_id":"350"}}
{"account_number":350,"balance":4267,"firstname":"Wyatt","lastname":"Wise","age":22,"gender":"F","address":"896 Bleecker Street","employer":"Rockyard","email":"wyattwise@rockyard.com","city":"Joes","state":"MS"}
{"index":{"_id":"355"}}
{"account_number":355,"balance":40961,"firstname":"Gregory","lastname":"Delacruz","age":38,"gender":"M","address":"876 Cortelyou Road","employer":"Oulu","email":"gregorydelacruz@oulu.com","city":"Waterloo","state":"WV"}
{"index":{"_id":"362"}}
{"account_number":362,"balance":14938,"firstname":"Jimmie","lastname":"Dejesus","age":26,"gender":"M","address":"351 Navy Walk","employer":"Ecolight","email":"jimmiedejesus@ecolight.com","city":"Berlin","state":"ME"}
{"index":{"_id":"367"}}
{"account_number":367,"balance":40458,"firstname":"Elaine","lastname":"Workman","age":20,"gender":"M","address":"188 Ridge Boulevard","employer":"Colaire","email":"elaineworkman@colaire.com","city":"Herbster","state":"AK"}
{"index":{"_id":"374"}}
{"account_number":374,"balance":19521,"firstname":"Blanchard","lastname":"Stein","age":30,"gender":"M","address":"313 Bartlett Street","employer":"Cujo","email":"blanchardstein@cujo.com","city":"Cascades","state":"OR"}
{"index":{"_id":"379"}}
{"account_number":379,"balance":12962,"firstname":"Ruthie","lastname":"Lamb","age":21,"gender":"M","address":"796 Rockaway Avenue","employer":"Incubus","email":"ruthielamb@incubus.com","city":"Hickory","state":"TX"}
{"index":{"_id":"381"}}
{"account_number":381,"balance":40978,"firstname":"Sophie","lastname":"Mays","age":31,"gender":"M","address":"261 Varanda Place","employer":"Uneeq","email":"sophiemays@uneeq.com","city":"Cressey","state":"AR"}
{"index":{"_id":"386"}}
{"account_number":386,"balance":42588,"firstname":"Wallace","lastname":"Barr","age":39,"gender":"F","address":"246 Beverly Road","employer":"Concility","email":"wallacebarr@concility.com","city":"Durham","state":"IN"}
{"index":{"_id":"393"}}
{"account_number":393,"balance":43936,"firstname":"William","lastname":"Kelly","age":24,"gender":"M","address":"178 Lawrence Avenue","employer":"Techtrix","email":"williamkelly@techtrix.com","city":"Orin","state":"PA"}
{"index":{"_id":"398"}}
{"account_number":398,"balance":8543,"firstname":"Leticia","lastname":"Duran","age":35,"gender":"F","address":"305 Senator Street","employer":"Xleen","email":"leticiaduran@xleen.com","city":"Cavalero","state":"PA"}
{"index":{"_id":"401"}}
{"account_number":401,"balance":29408,"firstname":"Contreras","lastname":"Randolph","age":38,"gender":"M","address":"104 Lewis Avenue","employer":"Inrt","email":"contrerasrandolph@inrt.com","city":"Chesapeake","state":"CT"}
{"index":{"_id":"406"}}
{"account_number":406,"balance":28127,"firstname":"Mccarthy","lastname":"Dunlap","age":28,"gender":"F","address":"684 Seacoast Terrace","employer":"Canopoly","email":"mccarthydunlap@canopoly.com","city":"Elliott","state":"NC"}
{"index":{"_id":"413"}}
{"account_number":413,"balance":15631,"firstname":"Pugh","lastname":"Hamilton","age":39,"gender":"F","address":"124 Euclid Avenue","employer":"Techade","email":"pughhamilton@techade.com","city":"Beaulieu","state":"CA"}
{"index":{"_id":"418"}}
{"account_number":418,"balance":10207,"firstname":"Reed","lastname":"Goff","age":32,"gender":"M","address":"959 Everit Street","employer":"Zillan","email":"reedgoff@zillan.com","city":"Hiko","state":"WV"}
{"index":{"_id":"420"}}
{"account_number":420,"balance":44699,"firstname":"Brandie","lastname":"Hayden","age":22,"gender":"M","address":"291 Ash Street","employer":"Digifad","email":"brandiehayden@digifad.com","city":"Spelter","state":"NM"}
{"index":{"_id":"425"}}
{"account_number":425,"balance":41308,"firstname":"Queen","lastname":"Leach","age":30,"gender":"M","address":"105 Fair Street","employer":"Magneato","email":"queenleach@magneato.com","city":"Barronett","state":"NH"}
{"index":{"_id":"432"}}
{"account_number":432,"balance":28969,"firstname":"Preston","lastname":"Ferguson","age":40,"gender":"F","address":"239 Greenwood Avenue","employer":"Bitendrex","email":"prestonferguson@bitendrex.com","city":"Idledale","state":"ND"}
{"index":{"_id":"437"}}
{"account_number":437,"balance":41225,"firstname":"Rosales","lastname":"Marquez","age":29,"gender":"M","address":"873 Ryerson Street","employer":"Ronelon","email":"rosalesmarquez@ronelon.com","city":"Allendale","state":"CA"}
{"index":{"_id":"444"}}
{"account_number":444,"balance":44219,"firstname":"Dolly","lastname":"Finch","age":24,"gender":"F","address":"974 Interborough Parkway","employer":"Zytrac","email":"dollyfinch@zytrac.com","city":"Vowinckel","state":"WY"}
{"index":{"_id":"449"}}
{"account_number":449,"balance":41950,"firstname":"Barnett","lastname":"Cantrell","age":39,"gender":"F","address":"945 Bedell Lane","employer":"Zentility","email":"barnettcantrell@zentility.com","city":"Swartzville","state":"ND"}
{"index":{"_id":"451"}}
{"account_number":451,"balance":31950,"firstname":"Mason","lastname":"Mcleod","age":31,"gender":"F","address":"438 Havemeyer Street","employer":"Omatom","email":"masonmcleod@omatom.com","city":"Ryderwood","state":"NE"}
{"index":{"_id":"456"}}
{"account_number":456,"balance":21419,"firstname":"Solis","lastname":"Kline","age":33,"gender":"M","address":"818 Ashford Street","employer":"Vetron","email":"soliskline@vetron.com","city":"Ruffin","state":"NY"}
{"index":{"_id":"463"}}
{"account_number":463,"balance":36672,"firstname":"Heidi","lastname":"Acosta","age":20,"gender":"F","address":"692 Kenmore Terrace","employer":"Elpro","email":"heidiacosta@elpro.com","city":"Ezel","state":"SD"}
{"index":{"_id":"468"}}
{"account_number":468,"balance":18400,"firstname":"Foreman","lastname":"Fowler","age":40,"gender":"M","address":"443 Jackson Court","employer":"Zillactic","email":"foremanfowler@zillactic.com","city":"Wakarusa","state":"WA"}
{"index":{"_id":"470"}}
{"account_number":470,"balance":20455,"firstname":"Schneider","lastname":"Hull","age":35,"gender":"M","address":"724 Apollo Street","employer":"Exospeed","email":"schneiderhull@exospeed.com","city":"Watchtower","state":"ID"}
{"index":{"_id":"475"}}
{"account_number":475,"balance":24427,"firstname":"Morales","lastname":"Jacobs","age":22,"gender":"F","address":"225 Desmond Court","employer":"Oronoko","email":"moralesjacobs@oronoko.com","city":"Clayville","state":"CT"}
{"index":{"_id":"482"}}
{"account_number":482,"balance":14834,"firstname":"Janie","lastname":"Bass","age":39,"gender":"M","address":"781 Grattan Street","employer":"Manglo","email":"janiebass@manglo.com","city":"Kenwood","state":"IA"}
{"index":{"_id":"487"}}
{"account_number":487,"balance":30718,"firstname":"Sawyer","lastname":"Vincent","age":26,"gender":"F","address":"238 Lancaster Avenue","employer":"Brainquil","email":"sawyervincent@brainquil.com","city":"Galesville","state":"MS"}
{"index":{"_id":"494"}}
{"account_number":494,"balance":3592,"firstname":"Holden","lastname":"Bowen","age":30,"gender":"M","address":"374 Elmwood Avenue","employer":"Endipine","email":"holdenbowen@endipine.com","city":"Rosine","state":"ID"}
{"index":{"_id":"499"}}
{"account_number":499,"balance":26060,"firstname":"Lara","lastname":"Perkins","age":26,"gender":"M","address":"703 Monroe Street","employer":"Paprikut","email":"laraperkins@paprikut.com","city":"Barstow","state":"NY"}
{"index":{"_id":"502"}}
{"account_number":502,"balance":31898,"firstname":"Woodard","lastname":"Bailey","age":31,"gender":"F","address":"585 Albee Square","employer":"Imperium","email":"woodardbailey@imperium.com","city":"Matheny","state":"MT"}
{"index":{"_id":"507"}}
{"account_number":507,"balance":27675,"firstname":"Blankenship","lastname":"Ramirez","age":31,"gender":"M","address":"630 Graham Avenue","employer":"Bytrex","email":"blankenshipramirez@bytrex.com","city":"Bancroft","state":"CT"}
{"index":{"_id":"514"}}
{"account_number":514,"balance":30125,"firstname":"Solomon","lastname":"Bush","age":34,"gender":"M","address":"409 Harkness Avenue","employer":"Snacktion","email":"solomonbush@snacktion.com","city":"Grayhawk","state":"TX"}
{"index":{"_id":"519"}}
{"account_number":519,"balance":3282,"firstname":"Lorna","lastname":"Franco","age":31,"gender":"F","address":"722 Schenck Court","employer":"Zentia","email":"lornafranco@zentia.com","city":"National","state":"FL"}
{"index":{"_id":"521"}}
{"account_number":521,"balance":16348,"firstname":"Josefa","lastname":"Buckley","age":34,"gender":"F","address":"848 Taylor Street","employer":"Mazuda","email":"josefabuckley@mazuda.com","city":"Saranap","state":"NM"}
{"index":{"_id":"526"}}
{"account_number":526,"balance":35375,"firstname":"Sweeney","lastname":"Fulton","age":33,"gender":"F","address":"550 Martense Street","employer":"Cormoran","email":"sweeneyfulton@cormoran.com","city":"Chalfant","state":"IA"}
{"index":{"_id":"533"}}
{"account_number":533,"balance":13761,"firstname":"Margarita","lastname":"Diaz","age":23,"gender":"M","address":"295 Tapscott Street","employer":"Zilodyne","email":"margaritadiaz@zilodyne.com","city":"Hondah","state":"ID"}
{"index":{"_id":"538"}}
{"account_number":538,"balance":16416,"firstname":"Koch","lastname":"Barker","age":21,"gender":"M","address":"919 Gerry Street","employer":"Xplor","email":"kochbarker@xplor.com","city":"Dixie","state":"WY"}
{"index":{"_id":"540"}}
{"account_number":540,"balance":40235,"firstname":"Tammy","lastname":"Wiggins","age":32,"gender":"F","address":"186 Schenectady Avenue","employer":"Speedbolt","email":"tammywiggins@speedbolt.com","city":"Salvo","state":"LA"}
{"index":{"_id":"545"}}
{"account_number":545,"balance":27011,"firstname":"Lena","lastname":"Lucas","age":20,"gender":"M","address":"110 Lamont Court","employer":"Kindaloo","email":"lenalucas@kindaloo.com","city":"Harleigh","state":"KY"}
{"index":{"_id":"552"}}
{"account_number":552,"balance":14727,"firstname":"Kate","lastname":"Estes","age":39,"gender":"M","address":"785 Willmohr Street","employer":"Rodeocean","email":"kateestes@rodeocean.com","city":"Elfrida","state":"HI"}
{"index":{"_id":"557"}}
{"account_number":557,"balance":3119,"firstname":"Landry","lastname":"Buck","age":20,"gender":"M","address":"558 Schweikerts Walk","employer":"Protodyne","email":"landrybuck@protodyne.com","city":"Edneyville","state":"AL"}
{"index":{"_id":"564"}}
{"account_number":564,"balance":43631,"firstname":"Owens","lastname":"Bowers","age":22,"gender":"M","address":"842 Congress Street","employer":"Nspire","email":"owensbowers@nspire.com","city":"Machias","state":"VA"}
{"index":{"_id":"569"}}
{"account_number":569,"balance":40019,"firstname":"Sherri","lastname":"Rowe","age":39,"gender":"F","address":"591 Arlington Place","employer":"Netility","email":"sherrirowe@netility.com","city":"Bridgetown","state":"SC"}
{"index":{"_id":"571"}}
{"account_number":571,"balance":3014,"firstname":"Ayers","lastname":"Duffy","age":28,"gender":"F","address":"721 Wortman Avenue","employer":"Aquasseur","email":"ayersduffy@aquasseur.com","city":"Tilleda","state":"MS"}
{"index":{"_id":"576"}}
{"account_number":576,"balance":29682,"firstname":"Helena","lastname":"Robertson","age":33,"gender":"F","address":"774 Devon Avenue","employer":"Vicon","email":"helenarobertson@vicon.com","city":"Dyckesville","state":"NV"}
{"index":{"_id":"583"}}
{"account_number":583,"balance":26558,"firstname":"Castro","lastname":"West","age":34,"gender":"F","address":"814 Williams Avenue","employer":"Cipromox","email":"castrowest@cipromox.com","city":"Nescatunga","state":"IL"}
{"index":{"_id":"588"}}
{"account_number":588,"balance":43531,"firstname":"Martina","lastname":"Collins","age":31,"gender":"M","address":"301 Anna Court","employer":"Geekwagon","email":"martinacollins@geekwagon.com","city":"Oneida","state":"VA"}
{"index":{"_id":"590"}}
{"account_number":590,"balance":4652,"firstname":"Ladonna","lastname":"Tucker","age":31,"gender":"F","address":"162 Kane Place","employer":"Infotrips","email":"ladonnatucker@infotrips.com","city":"Utting","state":"IA"}
{"index":{"_id":"595"}}
{"account_number":595,"balance":12478,"firstname":"Mccall","lastname":"Britt","age":36,"gender":"F","address":"823 Hill Street","employer":"Cablam","email":"mccallbritt@cablam.com","city":"Vernon","state":"CA"}
{"index":{"_id":"603"}}
{"account_number":603,"balance":28145,"firstname":"Janette","lastname":"Guzman","age":31,"gender":"F","address":"976 Kingston Avenue","employer":"Splinx","email":"janetteguzman@splinx.com","city":"Boomer","state":"NC"}
{"index":{"_id":"608"}}
{"account_number":608,"balance":47091,"firstname":"Carey","lastname":"Whitley","age":32,"gender":"F","address":"976 Lawrence Street","employer":"Poshome","email":"careywhitley@poshome.com","city":"Weogufka","state":"NE"}
{"index":{"_id":"610"}}
{"account_number":610,"balance":40571,"firstname":"Foster","lastname":"Weber","age":24,"gender":"F","address":"323 Rochester Avenue","employer":"Firewax","email":"fosterweber@firewax.com","city":"Winston","state":"NY"}
{"index":{"_id":"615"}}
{"account_number":615,"balance":28726,"firstname":"Delgado","lastname":"Curry","age":28,"gender":"F","address":"706 Butler Street","employer":"Zoxy","email":"delgadocurry@zoxy.com","city":"Gracey","state":"SD"}
{"index":{"_id":"622"}}
{"account_number":622,"balance":9661,"firstname":"Paulette","lastname":"Hartman","age":38,"gender":"M","address":"375 Emerald Street","employer":"Locazone","email":"paulettehartman@locazone.com","city":"Canterwood","state":"OH"}
{"index":{"_id":"627"}}
{"account_number":627,"balance":47546,"firstname":"Crawford","lastname":"Sears","age":37,"gender":"F","address":"686 Eastern Parkway","employer":"Updat","email":"crawfordsears@updat.com","city":"Bison","state":"VT"}
{"index":{"_id":"634"}}
{"account_number":634,"balance":29805,"firstname":"Deloris","lastname":"Levy","age":38,"gender":"M","address":"838 Foster Avenue","employer":"Homelux","email":"delorislevy@homelux.com","city":"Kempton","state":"PA"}
{"index":{"_id":"639"}}
{"account_number":639,"balance":28875,"firstname":"Caitlin","lastname":"Clements","age":32,"gender":"F","address":"627 Aster Court","employer":"Bunga","email":"caitlinclements@bunga.com","city":"Cetronia","state":"SC"}
{"index":{"_id":"641"}}
{"account_number":641,"balance":18345,"firstname":"Sheppard","lastname":"Everett","age":39,"gender":"F","address":"791 Norwood Avenue","employer":"Roboid","email":"sheppardeverett@roboid.com","city":"Selma","state":"AK"}
{"index":{"_id":"646"}}
{"account_number":646,"balance":15559,"firstname":"Lavonne","lastname":"Reyes","age":31,"gender":"F","address":"983 Newport Street","employer":"Parcoe","email":"lavonnereyes@parcoe.com","city":"Monument","state":"LA"}
{"index":{"_id":"653"}}
{"account_number":653,"balance":7606,"firstname":"Marcia","lastname":"Bennett","age":33,"gender":"F","address":"455 Bragg Street","employer":"Opticall","email":"marciabennett@opticall.com","city":"Magnolia","state":"NC"}
{"index":{"_id":"658"}}
{"account_number":658,"balance":10210,"firstname":"Bass","lastname":"Mcconnell","age":32,"gender":"F","address":"274 Ocean Avenue","employer":"Combot","email":"bassmcconnell@combot.com","city":"Beyerville","state":"OH"}
{"index":{"_id":"660"}}
{"account_number":660,"balance":46427,"firstname":"Moon","lastname":"Wood","age":33,"gender":"F","address":"916 Amersfort Place","employer":"Olucore","email":"moonwood@olucore.com","city":"Como","state":"VA"}
{"index":{"_id":"665"}}
{"account_number":665,"balance":15215,"firstname":"Britney","lastname":"Young","age":36,"gender":"M","address":"766 Sackman Street","employer":"Geoforma","email":"britneyyoung@geoforma.com","city":"Tuttle","state":"WI"}
{"index":{"_id":"672"}}
{"account_number":672,"balance":12621,"firstname":"Camille","lastname":"Munoz","age":36,"gender":"F","address":"959 Lewis Place","employer":"Vantage","email":"camillemunoz@vantage.com","city":"Whitmer","state":"IN"}
{"index":{"_id":"677"}}
{"account_number":677,"balance":8491,"firstname":"Snider","lastname":"Benton","age":26,"gender":"M","address":"827 Evans Street","employer":"Medicroix","email":"sniderbenton@medicroix.com","city":"Kaka","state":"UT"}
{"index":{"_id":"684"}}
{"account_number":684,"balance":46091,"firstname":"Warren","lastname":"Snow","age":25,"gender":"M","address":"756 Oakland Place","employer":"Bizmatic","email":"warrensnow@bizmatic.com","city":"Hatteras","state":"NE"}
{"index":{"_id":"689"}}
{"account_number":689,"balance":14985,"firstname":"Ines","lastname":"Chaney","age":28,"gender":"M","address":"137 Dikeman Street","employer":"Zidant","email":"ineschaney@zidant.com","city":"Nettie","state":"DC"}
{"index":{"_id":"691"}}
{"account_number":691,"balance":10792,"firstname":"Mclean","lastname":"Colon","age":22,"gender":"M","address":"876 Classon Avenue","employer":"Elentrix","email":"mcleancolon@elentrix.com","city":"Unionville","state":"OK"}
{"index":{"_id":"696"}}
{"account_number":696,"balance":17568,"firstname":"Crane","lastname":"Matthews","age":32,"gender":"F","address":"721 Gerritsen Avenue","employer":"Intradisk","email":"cranematthews@intradisk.com","city":"Brewster","state":"WV"}
{"index":{"_id":"704"}}
{"account_number":704,"balance":45347,"firstname":"Peters","lastname":"Kent","age":22,"gender":"F","address":"871 Independence Avenue","employer":"Extragen","email":"peterskent@extragen.com","city":"Morriston","state":"CA"}
{"index":{"_id":"709"}}
{"account_number":709,"balance":11015,"firstname":"Abbott","lastname":"Odom","age":29,"gender":"M","address":"893 Union Street","employer":"Jimbies","email":"abbottodom@jimbies.com","city":"Leeper","state":"NJ"}
{"index":{"_id":"711"}}
{"account_number":711,"balance":26939,"firstname":"Villarreal","lastname":"Horton","age":35,"gender":"F","address":"861 Creamer Street","employer":"Lexicondo","email":"villarrealhorton@lexicondo.com","city":"Lydia","state":"MS"}
{"index":{"_id":"716"}}
{"account_number":716,"balance":19789,"firstname":"Paul","lastname":"Mason","age":34,"gender":"F","address":"618 Nichols Avenue","employer":"Slax","email":"paulmason@slax.com","city":"Snowville","state":"OK"}
{"index":{"_id":"723"}}
{"account_number":723,"balance":16421,"firstname":"Nixon","lastname":"Moran","age":27,"gender":"M","address":"569 Campus Place","employer":"Cuizine","email":"nixonmoran@cuizine.com","city":"Buxton","state":"DC"}
{"index":{"_id":"728"}}
{"account_number":728,"balance":44818,"firstname":"Conley","lastname":"Preston","age":28,"gender":"M","address":"450 Coventry Road","employer":"Obones","email":"conleypreston@obones.com","city":"Alden","state":"CO"}
{"index":{"_id":"730"}}
{"account_number":730,"balance":41299,"firstname":"Moore","lastname":"Lee","age":30,"gender":"M","address":"797 Turner Place","employer":"Orbean","email":"moorelee@orbean.com","city":"Highland","state":"DE"}
{"index":{"_id":"735"}}
{"account_number":735,"balance":3984,"firstname":"Loraine","lastname":"Willis","age":32,"gender":"F","address":"928 Grove Street","employer":"Gadtron","email":"lorainewillis@gadtron.com","city":"Lowgap","state":"NY"}
{"index":{"_id":"742"}}
{"account_number":742,"balance":24765,"firstname":"Merle","lastname":"Wooten","age":26,"gender":"M","address":"317 Pooles Lane","employer":"Tropolis","email":"merlewooten@tropolis.com","city":"Bentley","state":"ND"}
{"index":{"_id":"747"}}
{"account_number":747,"balance":16617,"firstname":"Diaz","lastname":"Austin","age":38,"gender":"M","address":"676 Harway Avenue","employer":"Irack","email":"diazaustin@irack.com","city":"Cliff","state":"HI"}
{"index":{"_id":"754"}}
{"account_number":754,"balance":10779,"firstname":"Jones","lastname":"Vega","age":25,"gender":"F","address":"795 India Street","employer":"Gluid","email":"jonesvega@gluid.com","city":"Tyhee","state":"FL"}
{"index":{"_id":"759"}}
{"account_number":759,"balance":38007,"firstname":"Rose","lastname":"Carlson","age":27,"gender":"M","address":"987 Navy Street","employer":"Aquasure","email":"rosecarlson@aquasure.com","city":"Carlton","state":"CT"}
{"index":{"_id":"761"}}
{"account_number":761,"balance":7663,"firstname":"Rae","lastname":"Juarez","age":34,"gender":"F","address":"560 Gilmore Court","employer":"Entropix","email":"raejuarez@entropix.com","city":"Northchase","state":"ID"}
{"index":{"_id":"766"}}
{"account_number":766,"balance":21957,"firstname":"Thomas","lastname":"Gillespie","age":38,"gender":"M","address":"993 Williams Place","employer":"Octocore","email":"thomasgillespie@octocore.com","city":"Defiance","state":"MS"}
{"index":{"_id":"773"}}
{"account_number":773,"balance":31126,"firstname":"Liza","lastname":"Coffey","age":36,"gender":"F","address":"540 Bulwer Place","employer":"Assurity","email":"lizacoffey@assurity.com","city":"Gilgo","state":"WV"}
{"index":{"_id":"778"}}
{"account_number":778,"balance":46007,"firstname":"Underwood","lastname":"Wheeler","age":28,"gender":"M","address":"477 Provost Street","employer":"Decratex","email":"underwoodwheeler@decratex.com","city":"Sardis","state":"ID"}
{"index":{"_id":"780"}}
{"account_number":780,"balance":4682,"firstname":"Maryanne","lastname":"Hendricks","age":26,"gender":"F","address":"709 Wolcott Street","employer":"Sarasonic","email":"maryannehendricks@sarasonic.com","city":"Santel","state":"NH"}
{"index":{"_id":"785"}}
{"account_number":785,"balance":25078,"firstname":"Fields","lastname":"Lester","age":29,"gender":"M","address":"808 Chestnut Avenue","employer":"Visualix","email":"fieldslester@visualix.com","city":"Rowe","state":"PA"}
{"index":{"_id":"792"}}
{"account_number":792,"balance":13109,"firstname":"Becky","lastname":"Jimenez","age":40,"gender":"F","address":"539 Front Street","employer":"Isologia","email":"beckyjimenez@isologia.com","city":"Summertown","state":"MI"}
{"index":{"_id":"797"}}
{"account_number":797,"balance":6854,"firstname":"Lindsay","lastname":"Mills","age":26,"gender":"F","address":"919 Quay Street","employer":"Zoinage","email":"lindsaymills@zoinage.com","city":"Elliston","state":"VA"}
{"index":{"_id":"800"}}
{"account_number":800,"balance":26217,"firstname":"Candy","lastname":"Oconnor","age":28,"gender":"M","address":"200 Newel Street","employer":"Radiantix","email":"candyoconnor@radiantix.com","city":"Sandston","state":"OH"}
{"index":{"_id":"805"}}
{"account_number":805,"balance":18426,"firstname":"Jackson","lastname":"Sampson","age":27,"gender":"F","address":"722 Kenmore Court","employer":"Daido","email":"jacksonsampson@daido.com","city":"Bellamy","state":"ME"}
{"index":{"_id":"812"}}
{"account_number":812,"balance":42593,"firstname":"Graves","lastname":"Newman","age":32,"gender":"F","address":"916 Joralemon Street","employer":"Ecrater","email":"gravesnewman@ecrater.com","city":"Crown","state":"PA"}
{"index":{"_id":"817"}}
{"account_number":817,"balance":36582,"firstname":"Padilla","lastname":"Bauer","age":36,"gender":"F","address":"310 Cadman Plaza","employer":"Exoblue","email":"padillabauer@exoblue.com","city":"Ahwahnee","state":"MN"}
{"index":{"_id":"824"}}
{"account_number":824,"balance":6053,"firstname":"Dyer","lastname":"Henson","age":33,"gender":"M","address":"650 Seaview Avenue","employer":"Nitracyr","email":"dyerhenson@nitracyr.com","city":"Gibsonia","state":"KS"}
{"index":{"_id":"829"}}
{"account_number":829,"balance":20263,"firstname":"Althea","lastname":"Bell","age":37,"gender":"M","address":"319 Cook Street","employer":"Hyplex","email":"altheabell@hyplex.com","city":"Wadsworth","state":"DC"}
{"index":{"_id":"831"}}
{"account_number":831,"balance":25375,"firstname":"Wendy","lastname":"Savage","age":37,"gender":"M","address":"421 Veranda Place","employer":"Neurocell","email":"wendysavage@neurocell.com","city":"Fresno","state":"MS"}
{"index":{"_id":"836"}}
{"account_number":836,"balance":20797,"firstname":"Lloyd","lastname":"Lindsay","age":25,"gender":"F","address":"953 Dinsmore Place","employer":"Suretech","email":"lloydlindsay@suretech.com","city":"Conway","state":"VA"}
{"index":{"_id":"843"}}
{"account_number":843,"balance":15555,"firstname":"Patricia","lastname":"Barton","age":34,"gender":"F","address":"406 Seabring Street","employer":"Providco","email":"patriciabarton@providco.com","city":"Avoca","state":"RI"}
{"index":{"_id":"848"}}
{"account_number":848,"balance":15443,"firstname":"Carmella","lastname":"Cash","age":38,"gender":"M","address":"988 Exeter Street","employer":"Bristo","email":"carmellacash@bristo.com","city":"Northridge","state":"ID"}
{"index":{"_id":"850"}}
{"account_number":850,"balance":6531,"firstname":"Carlene","lastname":"Gaines","age":37,"gender":"F","address":"753 Monroe Place","employer":"Naxdis","email":"carlenegaines@naxdis.com","city":"Genoa","state":"OR"}
{"index":{"_id":"855"}}
{"account_number":855,"balance":40170,"firstname":"Mia","lastname":"Stevens","age":31,"gender":"F","address":"326 Driggs Avenue","employer":"Aeora","email":"miastevens@aeora.com","city":"Delwood","state":"IL"}
{"index":{"_id":"862"}}
{"account_number":862,"balance":38792,"firstname":"Clayton","lastname":"Golden","age":38,"gender":"F","address":"620 Regent Place","employer":"Accusage","email":"claytongolden@accusage.com","city":"Ona","state":"NC"}
{"index":{"_id":"867"}}
{"account_number":867,"balance":45453,"firstname":"Blanca","lastname":"Ellison","age":23,"gender":"F","address":"593 McKibben Street","employer":"Koogle","email":"blancaellison@koogle.com","city":"Frystown","state":"WY"}
{"index":{"_id":"874"}}
{"account_number":874,"balance":23079,"firstname":"Lynette","lastname":"Higgins","age":22,"gender":"M","address":"377 McKinley Avenue","employer":"Menbrain","email":"lynettehiggins@menbrain.com","city":"Manitou","state":"TX"}
{"index":{"_id":"879"}}
{"account_number":879,"balance":48332,"firstname":"Sabrina","lastname":"Lancaster","age":31,"gender":"F","address":"382 Oak Street","employer":"Webiotic","email":"sabrinalancaster@webiotic.com","city":"Lindisfarne","state":"AZ"}
{"index":{"_id":"881"}}
{"account_number":881,"balance":26684,"firstname":"Barnes","lastname":"Ware","age":38,"gender":"F","address":"666 Hooper Street","employer":"Norali","email":"barnesware@norali.com","city":"Cazadero","state":"GA"}
{"index":{"_id":"886"}}
{"account_number":886,"balance":14867,"firstname":"Willa","lastname":"Leblanc","age":38,"gender":"F","address":"773 Bergen Street","employer":"Nurali","email":"willaleblanc@nurali.com","city":"Hilltop","state":"NC"}
{"index":{"_id":"893"}}
{"account_number":893,"balance":42584,"firstname":"Moses","lastname":"Campos","age":38,"gender":"F","address":"991 Bevy Court","employer":"Trollery","email":"mosescampos@trollery.com","city":"Freetown","state":"AK"}
{"index":{"_id":"898"}}
{"account_number":898,"balance":12019,"firstname":"Lori","lastname":"Stevenson","age":29,"gender":"M","address":"910 Coles Street","employer":"Honotron","email":"loristevenson@honotron.com","city":"Shindler","state":"VT"}
{"index":{"_id":"901"}}
{"account_number":901,"balance":35038,"firstname":"Irma","lastname":"Dotson","age":23,"gender":"F","address":"245 Mayfair Drive","employer":"Bleeko","email":"irmadotson@bleeko.com","city":"Lodoga","state":"UT"}
{"index":{"_id":"906"}}
{"account_number":906,"balance":24073,"firstname":"Vicki","lastname":"Suarez","age":36,"gender":"M","address":"829 Roosevelt Place","employer":"Utara","email":"vickisuarez@utara.com","city":"Albrightsville","state":"AR"}
{"index":{"_id":"913"}}
{"account_number":913,"balance":47657,"firstname":"Margery","lastname":"Monroe","age":25,"gender":"M","address":"941 Fanchon Place","employer":"Exerta","email":"margerymonroe@exerta.com","city":"Bannock","state":"MD"}
{"index":{"_id":"918"}}
{"account_number":918,"balance":36776,"firstname":"Dianna","lastname":"Hernandez","age":25,"gender":"M","address":"499 Moultrie Street","employer":"Isologica","email":"diannahernandez@isologica.com","city":"Falconaire","state":"ID"}
{"index":{"_id":"920"}}
{"account_number":920,"balance":41513,"firstname":"Jerri","lastname":"Mitchell","age":26,"gender":"M","address":"831 Kent Street","employer":"Tasmania","email":"jerrimitchell@tasmania.com","city":"Cotopaxi","state":"IA"}
{"index":{"_id":"925"}}
{"account_number":925,"balance":18295,"firstname":"Rosario","lastname":"Jackson","age":24,"gender":"M","address":"178 Leonora Court","employer":"Progenex","email":"rosariojackson@progenex.com","city":"Rivereno","state":"DE"}
{"index":{"_id":"932"}}
{"account_number":932,"balance":3111,"firstname":"Summer","lastname":"Porter","age":33,"gender":"F","address":"949 Grand Avenue","employer":"Multiflex","email":"summerporter@multiflex.com","city":"Spokane","state":"OK"}
{"index":{"_id":"937"}}
{"account_number":937,"balance":43491,"firstname":"Selma","lastname":"Anderson","age":24,"gender":"M","address":"205 Reed Street","employer":"Dadabase","email":"selmaanderson@dadabase.com","city":"Malo","state":"AL"}
{"index":{"_id":"944"}}
{"account_number":944,"balance":46478,"firstname":"Donaldson","lastname":"Woodard","age":38,"gender":"F","address":"498 Laurel Avenue","employer":"Zogak","email":"donaldsonwoodard@zogak.com","city":"Hasty","state":"ID"}
{"index":{"_id":"949"}}
{"account_number":949,"balance":48703,"firstname":"Latasha","lastname":"Mullins","age":29,"gender":"F","address":"272 Lefferts Place","employer":"Zenolux","email":"latashamullins@zenolux.com","city":"Kieler","state":"MN"}
{"index":{"_id":"951"}}
{"account_number":951,"balance":36337,"firstname":"Tran","lastname":"Burris","age":25,"gender":"F","address":"561 Rutland Road","employer":"Geoform","email":"tranburris@geoform.com","city":"Longbranch","state":"IL"}
{"index":{"_id":"956"}}
{"account_number":956,"balance":19477,"firstname":"Randall","lastname":"Lynch","age":22,"gender":"F","address":"490 Madison Place","employer":"Cosmetex","email":"randalllynch@cosmetex.com","city":"Wells","state":"SD"}
{"index":{"_id":"963"}}
{"account_number":963,"balance":30461,"firstname":"Griffin","lastname":"Sheppard","age":20,"gender":"M","address":"682 Linden Street","employer":"Zanymax","email":"griffinsheppard@zanymax.com","city":"Fannett","state":"NM"}
{"index":{"_id":"968"}}
{"account_number":968,"balance":32371,"firstname":"Luella","lastname":"Burch","age":39,"gender":"M","address":"684 Arkansas Drive","employer":"Krag","email":"luellaburch@krag.com","city":"Brambleton","state":"SD"}
{"index":{"_id":"970"}}
{"account_number":970,"balance":19648,"firstname":"Forbes","lastname":"Wallace","age":28,"gender":"M","address":"990 Mill Road","employer":"Pheast","email":"forbeswallace@pheast.com","city":"Lopezo","state":"AK"}
{"index":{"_id":"975"}}
{"account_number":975,"balance":5239,"firstname":"Delores","lastname":"Booker","age":27,"gender":"F","address":"328 Conselyea Street","employer":"Centice","email":"deloresbooker@centice.com","city":"Williams","state":"HI"}
{"index":{"_id":"982"}}
{"account_number":982,"balance":16511,"firstname":"Buck","lastname":"Robinson","age":24,"gender":"M","address":"301 Melrose Street","employer":"Calcu","email":"buckrobinson@calcu.com","city":"Welch","state":"PA"}
{"index":{"_id":"987"}}
{"account_number":987,"balance":4072,"firstname":"Brock","lastname":"Sandoval","age":20,"gender":"F","address":"977 Gem Street","employer":"Fiberox","email":"brocksandoval@fiberox.com","city":"Celeryville","state":"NY"}
{"index":{"_id":"994"}}
{"account_number":994,"balance":33298,"firstname":"Madge","lastname":"Holcomb","age":31,"gender":"M","address":"612 Hawthorne Street","employer":"Escenta","email":"madgeholcomb@escenta.com","city":"Alafaya","state":"OR"}
{"index":{"_id":"999"}}
{"account_number":999,"balance":6087,"firstname":"Dorothy","lastname":"Barron","age":22,"gender":"F","address":"499 Laurel Avenue","employer":"Xurban","email":"dorothybarron@xurban.com","city":"Belvoir","state":"CA"}
{"index":{"_id":"4"}}
{"account_number":4,"balance":27658,"firstname":"Rodriquez","lastname":"Flores","age":31,"gender":"F","address":"986 Wyckoff Avenue","employer":"Tourmania","email":"rodriquezflores@tourmania.com","city":"Eastvale","state":"HI"}
{"index":{"_id":"9"}}
{"account_number":9,"balance":24776,"firstname":"Opal","lastname":"Meadows","age":39,"gender":"M","address":"963 Neptune Avenue","employer":"Cedward","email":"opalmeadows@cedward.com","city":"Olney","state":"OH"}
{"index":{"_id":"11"}}
{"account_number":11,"balance":20203,"firstname":"Jenkins","lastname":"Haney","age":20,"gender":"M","address":"740 Ferry Place","employer":"Qimonk","email":"jenkinshaney@qimonk.com","city":"Steinhatchee","state":"GA"}
{"index":{"_id":"16"}}
{"account_number":16,"balance":35883,"firstname":"Adrian","lastname":"Pitts","age":34,"gender":"F","address":"963 Fay Court","employer":"Combogene","email":"adrianpitts@combogene.com","city":"Remington","state":"SD"}
{"index":{"_id":"23"}}
{"account_number":23,"balance":42374,"firstname":"Kirsten","lastname":"Fox","age":20,"gender":"M","address":"330 Dumont Avenue","employer":"Codax","email":"kirstenfox@codax.com","city":"Walton","state":"AK"}
{"index":{"_id":"28"}}
{"account_number":28,"balance":42112,"firstname":"Vega","lastname":"Flynn","age":20,"gender":"M","address":"647 Hyman Court","employer":"Accupharm","email":"vegaflynn@accupharm.com","city":"Masthope","state":"OH"}
{"index":{"_id":"30"}}
{"account_number":30,"balance":19087,"firstname":"Lamb","lastname":"Townsend","age":26,"gender":"M","address":"169 Lyme Avenue","employer":"Geeknet","email":"lambtownsend@geeknet.com","city":"Epworth","state":"AL"}
{"index":{"_id":"35"}}
{"account_number":35,"balance":42039,"firstname":"Darla","lastname":"Bridges","age":27,"gender":"F","address":"315 Central Avenue","employer":"Xeronk","email":"darlabridges@xeronk.com","city":"Woodlake","state":"RI"}
{"index":{"_id":"42"}}
{"account_number":42,"balance":21137,"firstname":"Harding","lastname":"Hobbs","age":26,"gender":"F","address":"474 Ridgewood Place","employer":"Xth","email":"hardinghobbs@xth.com","city":"Heil","state":"ND"}
{"index":{"_id":"47"}}
{"account_number":47,"balance":33044,"firstname":"Georgia","lastname":"Wilkerson","age":23,"gender":"M","address":"369 Herbert Street","employer":"Endipin","email":"georgiawilkerson@endipin.com","city":"Dellview","state":"WI"}
{"index":{"_id":"54"}}
{"account_number":54,"balance":23406,"firstname":"Angel","lastname":"Mann","age":22,"gender":"F","address":"229 Ferris Street","employer":"Amtas","email":"angelmann@amtas.com","city":"Calverton","state":"WA"}
{"index":{"_id":"59"}}
{"account_number":59,"balance":37728,"firstname":"Malone","lastname":"Justice","age":37,"gender":"F","address":"721 Russell Street","employer":"Emoltra","email":"malonejustice@emoltra.com","city":"Trucksville","state":"HI"}
{"index":{"_id":"61"}}
{"account_number":61,"balance":6856,"firstname":"Shawn","lastname":"Baird","age":20,"gender":"M","address":"605 Monument Walk","employer":"Moltonic","email":"shawnbaird@moltonic.com","city":"Darlington","state":"MN"}
{"index":{"_id":"66"}}
{"account_number":66,"balance":25939,"firstname":"Franks","lastname":"Salinas","age":28,"gender":"M","address":"437 Hamilton Walk","employer":"Cowtown","email":"frankssalinas@cowtown.com","city":"Chase","state":"VT"}
{"index":{"_id":"73"}}
{"account_number":73,"balance":33457,"firstname":"Irene","lastname":"Stephenson","age":32,"gender":"M","address":"684 Miller Avenue","employer":"Hawkster","email":"irenestephenson@hawkster.com","city":"Levant","state":"AR"}
{"index":{"_id":"78"}}
{"account_number":78,"balance":48656,"firstname":"Elvira","lastname":"Patterson","age":23,"gender":"F","address":"834 Amber Street","employer":"Assistix","email":"elvirapatterson@assistix.com","city":"Dunbar","state":"TN"}
{"index":{"_id":"80"}}
{"account_number":80,"balance":13445,"firstname":"Lacey","lastname":"Blanchard","age":30,"gender":"F","address":"823 Himrod Street","employer":"Comdom","email":"laceyblanchard@comdom.com","city":"Matthews","state":"MO"}
{"index":{"_id":"85"}}
{"account_number":85,"balance":48735,"firstname":"Wilcox","lastname":"Sellers","age":20,"gender":"M","address":"212 Irving Avenue","employer":"Confrenzy","email":"wilcoxsellers@confrenzy.com","city":"Kipp","state":"MT"}
{"index":{"_id":"92"}}
{"account_number":92,"balance":26753,"firstname":"Gay","lastname":"Brewer","age":34,"gender":"M","address":"369 Ditmars Street","employer":"Savvy","email":"gaybrewer@savvy.com","city":"Moquino","state":"HI"}
{"index":{"_id":"97"}}
{"account_number":97,"balance":49671,"firstname":"Karen","lastname":"Trujillo","age":40,"gender":"F","address":"512 Cumberland Walk","employer":"Tsunamia","email":"karentrujillo@tsunamia.com","city":"Fredericktown","state":"MO"}
{"index":{"_id":"100"}}
{"account_number":100,"balance":29869,"firstname":"Madden","lastname":"Woods","age":32,"gender":"F","address":"696 Ryder Avenue","employer":"Slumberia","email":"maddenwoods@slumberia.com","city":"Deercroft","state":"ME"}
{"index":{"_id":"105"}}
{"account_number":105,"balance":29654,"firstname":"Castillo","lastname":"Dickerson","age":33,"gender":"F","address":"673 Oxford Street","employer":"Tellifly","email":"castillodickerson@tellifly.com","city":"Succasunna","state":"NY"}
{"index":{"_id":"112"}}
{"account_number":112,"balance":38395,"firstname":"Frederick","lastname":"Case","age":30,"gender":"F","address":"580 Lexington Avenue","employer":"Talkalot","email":"frederickcase@talkalot.com","city":"Orovada","state":"MA"}
{"index":{"_id":"117"}}
{"account_number":117,"balance":48831,"firstname":"Robin","lastname":"Hays","age":38,"gender":"F","address":"347 Hornell Loop","employer":"Pasturia","email":"robinhays@pasturia.com","city":"Sims","state":"WY"}
{"index":{"_id":"124"}}
{"account_number":124,"balance":16425,"firstname":"Fern","lastname":"Lambert","age":20,"gender":"M","address":"511 Jay Street","employer":"Furnitech","email":"fernlambert@furnitech.com","city":"Cloverdale","state":"FL"}
{"index":{"_id":"129"}}
{"account_number":129,"balance":42409,"firstname":"Alexandria","lastname":"Sanford","age":33,"gender":"F","address":"934 Ridgecrest Terrace","employer":"Kyagoro","email":"alexandriasanford@kyagoro.com","city":"Concho","state":"UT"}
{"index":{"_id":"131"}}
{"account_number":131,"balance":28030,"firstname":"Dollie","lastname":"Koch","age":22,"gender":"F","address":"287 Manhattan Avenue","employer":"Skinserve","email":"dolliekoch@skinserve.com","city":"Shasta","state":"PA"}
{"index":{"_id":"136"}}
{"account_number":136,"balance":45801,"firstname":"Winnie","lastname":"Holland","age":38,"gender":"M","address":"198 Mill Lane","employer":"Neteria","email":"winnieholland@neteria.com","city":"Urie","state":"IL"}
{"index":{"_id":"143"}}
{"account_number":143,"balance":43093,"firstname":"Cohen","lastname":"Noble","age":39,"gender":"M","address":"454 Nelson Street","employer":"Buzzworks","email":"cohennoble@buzzworks.com","city":"Norvelt","state":"CO"}
{"index":{"_id":"148"}}
{"account_number":148,"balance":3662,"firstname":"Annmarie","lastname":"Snider","age":34,"gender":"F","address":"857 Lafayette Walk","employer":"Edecine","email":"annmariesnider@edecine.com","city":"Hollins","state":"OH"}
{"index":{"_id":"150"}}
{"account_number":150,"balance":15306,"firstname":"Ortega","lastname":"Dalton","age":20,"gender":"M","address":"237 Mermaid Avenue","employer":"Rameon","email":"ortegadalton@rameon.com","city":"Maxville","state":"NH"}
{"index":{"_id":"155"}}
{"account_number":155,"balance":27878,"firstname":"Atkinson","lastname":"Hudson","age":39,"gender":"F","address":"434 Colin Place","employer":"Qualitern","email":"atkinsonhudson@qualitern.com","city":"Hoehne","state":"OH"}
{"index":{"_id":"162"}}
{"account_number":162,"balance":6302,"firstname":"Griffith","lastname":"Calderon","age":35,"gender":"M","address":"871 Vandervoort Place","employer":"Quotezart","email":"griffithcalderon@quotezart.com","city":"Barclay","state":"FL"}
{"index":{"_id":"167"}}
{"account_number":167,"balance":42051,"firstname":"Hampton","lastname":"Ryan","age":20,"gender":"M","address":"618 Fleet Place","employer":"Zipak","email":"hamptonryan@zipak.com","city":"Irwin","state":"KS"}
{"index":{"_id":"174"}}
{"account_number":174,"balance":1464,"firstname":"Gamble","lastname":"Pierce","age":23,"gender":"F","address":"650 Eagle Street","employer":"Matrixity","email":"gamblepierce@matrixity.com","city":"Abiquiu","state":"OR"}
{"index":{"_id":"179"}}
{"account_number":179,"balance":13265,"firstname":"Elise","lastname":"Drake","age":25,"gender":"M","address":"305 Christopher Avenue","employer":"Turnling","email":"elisedrake@turnling.com","city":"Loretto","state":"LA"}
{"index":{"_id":"181"}}
{"account_number":181,"balance":27983,"firstname":"Bennett","lastname":"Hampton","age":22,"gender":"F","address":"435 Billings Place","employer":"Voipa","email":"bennetthampton@voipa.com","city":"Rodman","state":"WY"}
{"index":{"_id":"186"}}
{"account_number":186,"balance":18373,"firstname":"Kline","lastname":"Joyce","age":32,"gender":"M","address":"285 Falmouth Street","employer":"Tetratrex","email":"klinejoyce@tetratrex.com","city":"Klondike","state":"SD"}
{"index":{"_id":"193"}}
{"account_number":193,"balance":13412,"firstname":"Patty","lastname":"Petty","age":34,"gender":"F","address":"251 Vermont Street","employer":"Kinetica","email":"pattypetty@kinetica.com","city":"Grantville","state":"MS"}
{"index":{"_id":"198"}}
{"account_number":198,"balance":19686,"firstname":"Rachael","lastname":"Sharp","age":38,"gender":"F","address":"443 Vernon Avenue","employer":"Powernet","email":"rachaelsharp@powernet.com","city":"Canoochee","state":"UT"}
{"index":{"_id":"201"}}
{"account_number":201,"balance":14586,"firstname":"Ronda","lastname":"Perry","age":25,"gender":"F","address":"856 Downing Street","employer":"Artiq","email":"rondaperry@artiq.com","city":"Colton","state":"WV"}
{"index":{"_id":"206"}}
{"account_number":206,"balance":47423,"firstname":"Kelli","lastname":"Francis","age":20,"gender":"M","address":"671 George Street","employer":"Exoswitch","email":"kellifrancis@exoswitch.com","city":"Babb","state":"NJ"}
{"index":{"_id":"213"}}
{"account_number":213,"balance":34172,"firstname":"Bauer","lastname":"Summers","age":27,"gender":"M","address":"257 Boynton Place","employer":"Voratak","email":"bauersummers@voratak.com","city":"Oceola","state":"NC"}
{"index":{"_id":"218"}}
{"account_number":218,"balance":26702,"firstname":"Garrison","lastname":"Bryan","age":24,"gender":"F","address":"478 Greenpoint Avenue","employer":"Uniworld","email":"garrisonbryan@uniworld.com","city":"Comptche","state":"WI"}
{"index":{"_id":"220"}}
{"account_number":220,"balance":3086,"firstname":"Tania","lastname":"Middleton","age":22,"gender":"F","address":"541 Gunther Place","employer":"Zerology","email":"taniamiddleton@zerology.com","city":"Linwood","state":"IN"}
{"index":{"_id":"225"}}
{"account_number":225,"balance":21949,"firstname":"Maryann","lastname":"Murphy","age":24,"gender":"F","address":"894 Bridgewater Street","employer":"Cinesanct","email":"maryannmurphy@cinesanct.com","city":"Cartwright","state":"RI"}
{"index":{"_id":"232"}}
{"account_number":232,"balance":11984,"firstname":"Carr","lastname":"Jensen","age":34,"gender":"F","address":"995 Micieli Place","employer":"Biohab","email":"carrjensen@biohab.com","city":"Waikele","state":"OH"}
{"index":{"_id":"237"}}
{"account_number":237,"balance":5603,"firstname":"Kirby","lastname":"Watkins","age":27,"gender":"F","address":"348 Blake Court","employer":"Sonique","email":"kirbywatkins@sonique.com","city":"Freelandville","state":"PA"}
{"index":{"_id":"244"}}
{"account_number":244,"balance":8048,"firstname":"Judith","lastname":"Riggs","age":27,"gender":"F","address":"590 Kosciusko Street","employer":"Arctiq","email":"judithriggs@arctiq.com","city":"Gorham","state":"DC"}
{"index":{"_id":"249"}}
{"account_number":249,"balance":16822,"firstname":"Mckinney","lastname":"Gallagher","age":38,"gender":"F","address":"939 Seigel Court","employer":"Premiant","email":"mckinneygallagher@premiant.com","city":"Catharine","state":"NH"}
{"index":{"_id":"251"}}
{"account_number":251,"balance":13475,"firstname":"Marks","lastname":"Graves","age":39,"gender":"F","address":"427 Lawn Court","employer":"Dentrex","email":"marksgraves@dentrex.com","city":"Waukeenah","state":"IL"}
{"index":{"_id":"256"}}
{"account_number":256,"balance":48318,"firstname":"Simon","lastname":"Hogan","age":31,"gender":"M","address":"789 Suydam Place","employer":"Dancerity","email":"simonhogan@dancerity.com","city":"Dargan","state":"GA"}
{"index":{"_id":"263"}}
{"account_number":263,"balance":12837,"firstname":"Thornton","lastname":"Meyer","age":29,"gender":"M","address":"575 Elliott Place","employer":"Peticular","email":"thorntonmeyer@peticular.com","city":"Dotsero","state":"NH"}
{"index":{"_id":"268"}}
{"account_number":268,"balance":20925,"firstname":"Avis","lastname":"Blackwell","age":36,"gender":"M","address":"569 Jerome Avenue","employer":"Magnina","email":"avisblackwell@magnina.com","city":"Bethany","state":"MD"}
{"index":{"_id":"270"}}
{"account_number":270,"balance":43951,"firstname":"Moody","lastname":"Harmon","age":39,"gender":"F","address":"233 Vanderbilt Street","employer":"Otherside","email":"moodyharmon@otherside.com","city":"Elwood","state":"MT"}
{"index":{"_id":"275"}}
{"account_number":275,"balance":2384,"firstname":"Reynolds","lastname":"Barnett","age":31,"gender":"M","address":"394 Stockton Street","employer":"Austex","email":"reynoldsbarnett@austex.com","city":"Grandview","state":"MS"}
{"index":{"_id":"282"}}
{"account_number":282,"balance":38540,"firstname":"Gay","lastname":"Schultz","age":25,"gender":"F","address":"805 Claver Place","employer":"Handshake","email":"gayschultz@handshake.com","city":"Tampico","state":"MA"}
{"index":{"_id":"287"}}
{"account_number":287,"balance":10845,"firstname":"Valerie","lastname":"Lang","age":35,"gender":"F","address":"423 Midwood Street","employer":"Quarx","email":"valerielang@quarx.com","city":"Cannondale","state":"VT"}
{"index":{"_id":"294"}}
{"account_number":294,"balance":29582,"firstname":"Pitts","lastname":"Haynes","age":26,"gender":"M","address":"901 Broome Street","employer":"Aquazure","email":"pittshaynes@aquazure.com","city":"Turah","state":"SD"}
{"index":{"_id":"299"}}
{"account_number":299,"balance":40825,"firstname":"Angela","lastname":"Talley","age":36,"gender":"F","address":"822 Bills Place","employer":"Remold","email":"angelatalley@remold.com","city":"Bethpage","state":"DC"}
{"index":{"_id":"302"}}
{"account_number":302,"balance":11298,"firstname":"Isabella","lastname":"Hewitt","age":40,"gender":"M","address":"455 Bedford Avenue","employer":"Cincyr","email":"isabellahewitt@cincyr.com","city":"Blanford","state":"IN"}
{"index":{"_id":"307"}}
{"account_number":307,"balance":43355,"firstname":"Enid","lastname":"Ashley","age":23,"gender":"M","address":"412 Emerson Place","employer":"Avenetro","email":"enidashley@avenetro.com","city":"Catherine","state":"WI"}
{"index":{"_id":"314"}}
{"account_number":314,"balance":5848,"firstname":"Norton","lastname":"Norton","age":35,"gender":"M","address":"252 Ditmas Avenue","employer":"Talkola","email":"nortonnorton@talkola.com","city":"Veyo","state":"SC"}
{"index":{"_id":"319"}}
{"account_number":319,"balance":15430,"firstname":"Ferrell","lastname":"Mckinney","age":36,"gender":"M","address":"874 Cranberry Street","employer":"Portaline","email":"ferrellmckinney@portaline.com","city":"Rose","state":"WV"}
{"index":{"_id":"321"}}
{"account_number":321,"balance":43370,"firstname":"Marta","lastname":"Larsen","age":35,"gender":"M","address":"617 Williams Court","employer":"Manufact","email":"martalarsen@manufact.com","city":"Sisquoc","state":"MA"}
{"index":{"_id":"326"}}
{"account_number":326,"balance":9692,"firstname":"Pearl","lastname":"Reese","age":30,"gender":"F","address":"451 Colonial Court","employer":"Accruex","email":"pearlreese@accruex.com","city":"Westmoreland","state":"MD"}
{"index":{"_id":"333"}}
{"account_number":333,"balance":22778,"firstname":"Trudy","lastname":"Sweet","age":27,"gender":"F","address":"881 Kiely Place","employer":"Acumentor","email":"trudysweet@acumentor.com","city":"Kent","state":"IA"}
{"index":{"_id":"338"}}
{"account_number":338,"balance":6969,"firstname":"Pierce","lastname":"Lawrence","age":35,"gender":"M","address":"318 Gallatin Place","employer":"Lunchpad","email":"piercelawrence@lunchpad.com","city":"Iola","state":"MD"}
{"index":{"_id":"340"}}
{"account_number":340,"balance":42072,"firstname":"Juarez","lastname":"Gutierrez","age":40,"gender":"F","address":"802 Seba Avenue","employer":"Billmed","email":"juarezgutierrez@billmed.com","city":"Malott","state":"OH"}
{"index":{"_id":"345"}}
{"account_number":345,"balance":9812,"firstname":"Parker","lastname":"Hines","age":38,"gender":"M","address":"715 Mill Avenue","employer":"Baluba","email":"parkerhines@baluba.com","city":"Blackgum","state":"KY"}
{"index":{"_id":"352"}}
{"account_number":352,"balance":20290,"firstname":"Kendra","lastname":"Mcintosh","age":31,"gender":"F","address":"963 Wolf Place","employer":"Orboid","email":"kendramcintosh@orboid.com","city":"Bladensburg","state":"AK"}
{"index":{"_id":"357"}}
{"account_number":357,"balance":15102,"firstname":"Adele","lastname":"Carroll","age":39,"gender":"F","address":"381 Arion Place","employer":"Aquafire","email":"adelecarroll@aquafire.com","city":"Springville","state":"RI"}
{"index":{"_id":"364"}}
{"account_number":364,"balance":35247,"firstname":"Felicia","lastname":"Merrill","age":40,"gender":"F","address":"229 Branton Street","employer":"Prosely","email":"feliciamerrill@prosely.com","city":"Dola","state":"MA"}
{"index":{"_id":"369"}}
{"account_number":369,"balance":17047,"firstname":"Mcfadden","lastname":"Guy","age":28,"gender":"F","address":"445 Lott Avenue","employer":"Kangle","email":"mcfaddenguy@kangle.com","city":"Greenbackville","state":"DE"}
{"index":{"_id":"371"}}
{"account_number":371,"balance":19751,"firstname":"Barker","lastname":"Allen","age":32,"gender":"F","address":"295 Wallabout Street","employer":"Nexgene","email":"barkerallen@nexgene.com","city":"Nanafalia","state":"NE"}
{"index":{"_id":"376"}}
{"account_number":376,"balance":44407,"firstname":"Mcmillan","lastname":"Dunn","age":21,"gender":"F","address":"771 Dorchester Road","employer":"Eargo","email":"mcmillandunn@eargo.com","city":"Yogaville","state":"RI"}
{"index":{"_id":"383"}}
{"account_number":383,"balance":48889,"firstname":"Knox","lastname":"Larson","age":28,"gender":"F","address":"962 Bartlett Place","employer":"Bostonic","email":"knoxlarson@bostonic.com","city":"Smeltertown","state":"TX"}
{"index":{"_id":"388"}}
{"account_number":388,"balance":9606,"firstname":"Julianne","lastname":"Nicholson","age":26,"gender":"F","address":"338 Crescent Street","employer":"Viasia","email":"juliannenicholson@viasia.com","city":"Alleghenyville","state":"MO"}
{"index":{"_id":"390"}}
{"account_number":390,"balance":7464,"firstname":"Ramona","lastname":"Roy","age":32,"gender":"M","address":"135 Banner Avenue","employer":"Deminimum","email":"ramonaroy@deminimum.com","city":"Dodge","state":"ID"}
{"index":{"_id":"395"}}
{"account_number":395,"balance":18679,"firstname":"Juliet","lastname":"Whitaker","age":31,"gender":"M","address":"128 Remsen Avenue","employer":"Toyletry","email":"julietwhitaker@toyletry.com","city":"Yonah","state":"LA"}
{"index":{"_id":"403"}}
{"account_number":403,"balance":18833,"firstname":"Williamson","lastname":"Horn","age":32,"gender":"M","address":"223 Strickland Avenue","employer":"Nimon","email":"williamsonhorn@nimon.com","city":"Bawcomville","state":"NJ"}
{"index":{"_id":"408"}}
{"account_number":408,"balance":34666,"firstname":"Lidia","lastname":"Guerrero","age":30,"gender":"M","address":"254 Stratford Road","employer":"Snowpoke","email":"lidiaguerrero@snowpoke.com","city":"Fairlee","state":"LA"}
{"index":{"_id":"410"}}
{"account_number":410,"balance":31200,"firstname":"Fox","lastname":"Cardenas","age":39,"gender":"M","address":"987 Monitor Street","employer":"Corpulse","email":"foxcardenas@corpulse.com","city":"Southview","state":"NE"}
{"index":{"_id":"415"}}
{"account_number":415,"balance":19449,"firstname":"Martinez","lastname":"Benson","age":36,"gender":"M","address":"172 Berkeley Place","employer":"Enersol","email":"martinezbenson@enersol.com","city":"Chumuckla","state":"AL"}
{"index":{"_id":"422"}}
{"account_number":422,"balance":40162,"firstname":"Brigitte","lastname":"Scott","age":26,"gender":"M","address":"662 Vermont Court","employer":"Waretel","email":"brigittescott@waretel.com","city":"Elrama","state":"VA"}
{"index":{"_id":"427"}}
{"account_number":427,"balance":1463,"firstname":"Rebekah","lastname":"Garrison","age":36,"gender":"F","address":"837 Hampton Avenue","employer":"Niquent","email":"rebekahgarrison@niquent.com","city":"Zarephath","state":"NY"}
{"index":{"_id":"434"}}
{"account_number":434,"balance":11329,"firstname":"Christa","lastname":"Huff","age":25,"gender":"M","address":"454 Oriental Boulevard","employer":"Earthpure","email":"christahuff@earthpure.com","city":"Stevens","state":"DC"}
{"index":{"_id":"439"}}
{"account_number":439,"balance":22752,"firstname":"Lula","lastname":"Williams","age":35,"gender":"M","address":"630 Furman Avenue","employer":"Vinch","email":"lulawilliams@vinch.com","city":"Newcastle","state":"ME"}
{"index":{"_id":"441"}}
{"account_number":441,"balance":47947,"firstname":"Dickson","lastname":"Mcgee","age":29,"gender":"M","address":"478 Knight Court","employer":"Gogol","email":"dicksonmcgee@gogol.com","city":"Laurelton","state":"AR"}
{"index":{"_id":"446"}}
{"account_number":446,"balance":23071,"firstname":"Lolita","lastname":"Fleming","age":32,"gender":"F","address":"918 Bridge Street","employer":"Vidto","email":"lolitafleming@vidto.com","city":"Brownlee","state":"HI"}
{"index":{"_id":"453"}}
{"account_number":453,"balance":21520,"firstname":"Hood","lastname":"Powell","age":24,"gender":"F","address":"479 Brevoort Place","employer":"Vortexaco","email":"hoodpowell@vortexaco.com","city":"Alderpoint","state":"CT"}
{"index":{"_id":"458"}}
{"account_number":458,"balance":8865,"firstname":"Aida","lastname":"Wolf","age":21,"gender":"F","address":"403 Thames Street","employer":"Isis","email":"aidawolf@isis.com","city":"Bordelonville","state":"ME"}
{"index":{"_id":"460"}}
{"account_number":460,"balance":37734,"firstname":"Aguirre","lastname":"White","age":21,"gender":"F","address":"190 Crooke Avenue","employer":"Unq","email":"aguirrewhite@unq.com","city":"Albany","state":"NJ"}
{"index":{"_id":"465"}}
{"account_number":465,"balance":10681,"firstname":"Pearlie","lastname":"Holman","age":29,"gender":"M","address":"916 Evergreen Avenue","employer":"Hometown","email":"pearlieholman@hometown.com","city":"Needmore","state":"UT"}
{"index":{"_id":"472"}}
{"account_number":472,"balance":25571,"firstname":"Lee","lastname":"Long","age":32,"gender":"F","address":"288 Mill Street","employer":"Comverges","email":"leelong@comverges.com","city":"Movico","state":"MT"}
{"index":{"_id":"477"}}
{"account_number":477,"balance":25892,"firstname":"Holcomb","lastname":"Cobb","age":40,"gender":"M","address":"369 Marconi Place","employer":"Steeltab","email":"holcombcobb@steeltab.com","city":"Byrnedale","state":"CA"}
{"index":{"_id":"484"}}
{"account_number":484,"balance":3274,"firstname":"Staci","lastname":"Melendez","age":35,"gender":"F","address":"751 Otsego Street","employer":"Namebox","email":"stacimelendez@namebox.com","city":"Harborton","state":"NV"}
{"index":{"_id":"489"}}
{"account_number":489,"balance":7879,"firstname":"Garrett","lastname":"Langley","age":36,"gender":"M","address":"331 Bowne Street","employer":"Zillidium","email":"garrettlangley@zillidium.com","city":"Riviera","state":"LA"}
{"index":{"_id":"491"}}
{"account_number":491,"balance":42942,"firstname":"Teresa","lastname":"Owen","age":24,"gender":"F","address":"713 Canton Court","employer":"Plasmos","email":"teresaowen@plasmos.com","city":"Bartonsville","state":"NH"}
{"index":{"_id":"496"}}
{"account_number":496,"balance":14869,"firstname":"Alison","lastname":"Conrad","age":35,"gender":"F","address":"347 Varet Street","employer":"Perkle","email":"alisonconrad@perkle.com","city":"Cliffside","state":"OH"}
{"index":{"_id":"504"}}
{"account_number":504,"balance":49205,"firstname":"Shanna","lastname":"Chambers","age":23,"gender":"M","address":"220 Beard Street","employer":"Corporana","email":"shannachambers@corporana.com","city":"Cashtown","state":"AZ"}
{"index":{"_id":"509"}}
{"account_number":509,"balance":34754,"firstname":"Durham","lastname":"Pacheco","age":40,"gender":"M","address":"129 Plymouth Street","employer":"Datacator","email":"durhampacheco@datacator.com","city":"Loveland","state":"NC"}
{"index":{"_id":"511"}}
{"account_number":511,"balance":40908,"firstname":"Elba","lastname":"Grant","age":24,"gender":"F","address":"157 Bijou Avenue","employer":"Dognost","email":"elbagrant@dognost.com","city":"Coyote","state":"MT"}
{"index":{"_id":"516"}}
{"account_number":516,"balance":44940,"firstname":"Roy","lastname":"Smith","age":37,"gender":"M","address":"770 Cherry Street","employer":"Parleynet","email":"roysmith@parleynet.com","city":"Carrsville","state":"RI"}
{"index":{"_id":"523"}}
{"account_number":523,"balance":28729,"firstname":"Amalia","lastname":"Benjamin","age":40,"gender":"F","address":"173 Bushwick Place","employer":"Sentia","email":"amaliabenjamin@sentia.com","city":"Jacumba","state":"OK"}
{"index":{"_id":"528"}}
{"account_number":528,"balance":4071,"firstname":"Thompson","lastname":"Hoover","age":27,"gender":"F","address":"580 Garden Street","employer":"Portalis","email":"thompsonhoover@portalis.com","city":"Knowlton","state":"AL"}
{"index":{"_id":"530"}}
{"account_number":530,"balance":8840,"firstname":"Kathrine","lastname":"Evans","age":37,"gender":"M","address":"422 Division Place","employer":"Spherix","email":"kathrineevans@spherix.com","city":"Biddle","state":"CO"}
{"index":{"_id":"535"}}
{"account_number":535,"balance":8715,"firstname":"Fry","lastname":"George","age":34,"gender":"M","address":"722 Green Street","employer":"Ewaves","email":"frygeorge@ewaves.com","city":"Kenmar","state":"DE"}
{"index":{"_id":"542"}}
{"account_number":542,"balance":23285,"firstname":"Michelle","lastname":"Mayo","age":35,"gender":"M","address":"657 Caton Place","employer":"Biflex","email":"michellemayo@biflex.com","city":"Beaverdale","state":"WY"}
{"index":{"_id":"547"}}
{"account_number":547,"balance":12870,"firstname":"Eaton","lastname":"Rios","age":32,"gender":"M","address":"744 Withers Street","employer":"Podunk","email":"eatonrios@podunk.com","city":"Chelsea","state":"IA"}
{"index":{"_id":"554"}}
{"account_number":554,"balance":33163,"firstname":"Townsend","lastname":"Atkins","age":39,"gender":"M","address":"566 Ira Court","employer":"Acruex","email":"townsendatkins@acruex.com","city":"Valle","state":"IA"}
{"index":{"_id":"559"}}
{"account_number":559,"balance":11450,"firstname":"Tonia","lastname":"Schmidt","age":38,"gender":"F","address":"508 Sheffield Avenue","employer":"Extro","email":"toniaschmidt@extro.com","city":"Newry","state":"CT"}
{"index":{"_id":"561"}}
{"account_number":561,"balance":12370,"firstname":"Sellers","lastname":"Davis","age":30,"gender":"M","address":"860 Madoc Avenue","employer":"Isodrive","email":"sellersdavis@isodrive.com","city":"Trail","state":"KS"}
{"index":{"_id":"566"}}
{"account_number":566,"balance":6183,"firstname":"Cox","lastname":"Roman","age":37,"gender":"M","address":"349 Winthrop Street","employer":"Medcom","email":"coxroman@medcom.com","city":"Rosewood","state":"WY"}
{"index":{"_id":"573"}}
{"account_number":573,"balance":32171,"firstname":"Callie","lastname":"Castaneda","age":36,"gender":"M","address":"799 Scott Avenue","employer":"Earthwax","email":"calliecastaneda@earthwax.com","city":"Marshall","state":"NH"}
{"index":{"_id":"578"}}
{"account_number":578,"balance":34259,"firstname":"Holmes","lastname":"Mcknight","age":37,"gender":"M","address":"969 Metropolitan Avenue","employer":"Cubicide","email":"holmesmcknight@cubicide.com","city":"Aguila","state":"PA"}
{"index":{"_id":"580"}}
{"account_number":580,"balance":13716,"firstname":"Mcmahon","lastname":"York","age":34,"gender":"M","address":"475 Beacon Court","employer":"Zillar","email":"mcmahonyork@zillar.com","city":"Farmington","state":"MO"}
{"index":{"_id":"585"}}
{"account_number":585,"balance":26745,"firstname":"Nieves","lastname":"Nolan","age":32,"gender":"M","address":"115 Seagate Terrace","employer":"Jumpstack","email":"nievesnolan@jumpstack.com","city":"Eastmont","state":"UT"}
{"index":{"_id":"592"}}
{"account_number":592,"balance":32968,"firstname":"Head","lastname":"Webster","age":36,"gender":"F","address":"987 Lefferts Avenue","employer":"Empirica","email":"headwebster@empirica.com","city":"Rockingham","state":"TN"}
{"index":{"_id":"597"}}
{"account_number":597,"balance":11246,"firstname":"Penny","lastname":"Knowles","age":33,"gender":"M","address":"139 Forbell Street","employer":"Ersum","email":"pennyknowles@ersum.com","city":"Vallonia","state":"IA"}
{"index":{"_id":"600"}}
{"account_number":600,"balance":10336,"firstname":"Simmons","lastname":"Byers","age":37,"gender":"M","address":"250 Dictum Court","employer":"Qualitex","email":"simmonsbyers@qualitex.com","city":"Wanship","state":"OH"}
{"index":{"_id":"605"}}
{"account_number":605,"balance":38427,"firstname":"Mcclain","lastname":"Manning","age":24,"gender":"M","address":"832 Leonard Street","employer":"Qiao","email":"mcclainmanning@qiao.com","city":"Calvary","state":"TX"}
{"index":{"_id":"612"}}
{"account_number":612,"balance":11868,"firstname":"Dunn","lastname":"Cameron","age":32,"gender":"F","address":"156 Lorimer Street","employer":"Isonus","email":"dunncameron@isonus.com","city":"Virgie","state":"ND"}
{"index":{"_id":"617"}}
{"account_number":617,"balance":35445,"firstname":"Kitty","lastname":"Cooley","age":22,"gender":"M","address":"788 Seagate Avenue","employer":"Ultrimax","email":"kittycooley@ultrimax.com","city":"Clarktown","state":"MD"}
{"index":{"_id":"624"}}
{"account_number":624,"balance":27538,"firstname":"Roxanne","lastname":"Franklin","age":39,"gender":"F","address":"299 Woodrow Court","employer":"Silodyne","email":"roxannefranklin@silodyne.com","city":"Roulette","state":"VA"}
{"index":{"_id":"629"}}
{"account_number":629,"balance":32987,"firstname":"Mcclure","lastname":"Rodgers","age":26,"gender":"M","address":"806 Pierrepont Place","employer":"Elita","email":"mcclurerodgers@elita.com","city":"Brownsville","state":"MI"}
{"index":{"_id":"631"}}
{"account_number":631,"balance":21657,"firstname":"Corrine","lastname":"Barber","age":32,"gender":"F","address":"447 Hunts Lane","employer":"Quarmony","email":"corrinebarber@quarmony.com","city":"Wyano","state":"IL"}
{"index":{"_id":"636"}}
{"account_number":636,"balance":8036,"firstname":"Agnes","lastname":"Hooper","age":25,"gender":"M","address":"865 Hanson Place","employer":"Digial","email":"agneshooper@digial.com","city":"Sperryville","state":"OK"}
{"index":{"_id":"643"}}
{"account_number":643,"balance":8057,"firstname":"Hendricks","lastname":"Stokes","age":23,"gender":"F","address":"142 Barbey Street","employer":"Remotion","email":"hendricksstokes@remotion.com","city":"Lewis","state":"MA"}
{"index":{"_id":"648"}}
{"account_number":648,"balance":11506,"firstname":"Terry","lastname":"Montgomery","age":21,"gender":"F","address":"115 Franklin Avenue","employer":"Enervate","email":"terrymontgomery@enervate.com","city":"Bascom","state":"MA"}
{"index":{"_id":"650"}}
{"account_number":650,"balance":18091,"firstname":"Benton","lastname":"Knight","age":28,"gender":"F","address":"850 Aitken Place","employer":"Pholio","email":"bentonknight@pholio.com","city":"Cobbtown","state":"AL"}
{"index":{"_id":"655"}}
{"account_number":655,"balance":22912,"firstname":"Eula","lastname":"Taylor","age":30,"gender":"M","address":"520 Orient Avenue","employer":"Miracula","email":"eulataylor@miracula.com","city":"Wacissa","state":"IN"}
{"index":{"_id":"662"}}
{"account_number":662,"balance":10138,"firstname":"Daisy","lastname":"Burnett","age":33,"gender":"M","address":"114 Norman Avenue","employer":"Liquicom","email":"daisyburnett@liquicom.com","city":"Grahamtown","state":"MD"}
{"index":{"_id":"667"}}
{"account_number":667,"balance":22559,"firstname":"Juliana","lastname":"Chase","age":32,"gender":"M","address":"496 Coleridge Street","employer":"Comtract","email":"julianachase@comtract.com","city":"Wilsonia","state":"NJ"}
{"index":{"_id":"674"}}
{"account_number":674,"balance":36038,"firstname":"Watts","lastname":"Shannon","age":22,"gender":"F","address":"600 Story Street","employer":"Joviold","email":"wattsshannon@joviold.com","city":"Fairhaven","state":"ID"}
{"index":{"_id":"679"}}
{"account_number":679,"balance":20149,"firstname":"Henrietta","lastname":"Bonner","age":33,"gender":"M","address":"461 Bond Street","employer":"Geekol","email":"henriettabonner@geekol.com","city":"Richville","state":"WA"}
{"index":{"_id":"681"}}
{"account_number":681,"balance":34244,"firstname":"Velazquez","lastname":"Wolfe","age":33,"gender":"M","address":"773 Eckford Street","employer":"Zisis","email":"velazquezwolfe@zisis.com","city":"Smock","state":"ME"}
{"index":{"_id":"686"}}
{"account_number":686,"balance":10116,"firstname":"Decker","lastname":"Mcclure","age":30,"gender":"F","address":"236 Commerce Street","employer":"Everest","email":"deckermcclure@everest.com","city":"Gibbsville","state":"TN"}
{"index":{"_id":"693"}}
{"account_number":693,"balance":31233,"firstname":"Tabatha","lastname":"Zimmerman","age":30,"gender":"F","address":"284 Emmons Avenue","employer":"Pushcart","email":"tabathazimmerman@pushcart.com","city":"Esmont","state":"NC"}
{"index":{"_id":"698"}}
{"account_number":698,"balance":14965,"firstname":"Baker","lastname":"Armstrong","age":36,"gender":"F","address":"796 Tehama Street","employer":"Nurplex","email":"bakerarmstrong@nurplex.com","city":"Starks","state":"UT"}
{"index":{"_id":"701"}}
{"account_number":701,"balance":23772,"firstname":"Gardner","lastname":"Griffith","age":27,"gender":"M","address":"187 Moore Place","employer":"Vertide","email":"gardnergriffith@vertide.com","city":"Coventry","state":"NV"}
{"index":{"_id":"706"}}
{"account_number":706,"balance":5282,"firstname":"Eliza","lastname":"Potter","age":39,"gender":"M","address":"945 Dunham Place","employer":"Playce","email":"elizapotter@playce.com","city":"Woodruff","state":"AK"}
{"index":{"_id":"713"}}
{"account_number":713,"balance":20054,"firstname":"Iris","lastname":"Mcguire","age":21,"gender":"F","address":"508 Benson Avenue","employer":"Duflex","email":"irismcguire@duflex.com","city":"Hillsboro","state":"MO"}
{"index":{"_id":"718"}}
{"account_number":718,"balance":13876,"firstname":"Hickman","lastname":"Dillard","age":22,"gender":"F","address":"132 Etna Street","employer":"Genmy","email":"hickmandillard@genmy.com","city":"Curtice","state":"NV"}
{"index":{"_id":"720"}}
{"account_number":720,"balance":31356,"firstname":"Ruth","lastname":"Vance","age":32,"gender":"F","address":"229 Adams Street","employer":"Zilidium","email":"ruthvance@zilidium.com","city":"Allison","state":"IA"}
{"index":{"_id":"725"}}
{"account_number":725,"balance":14677,"firstname":"Reeves","lastname":"Tillman","age":26,"gender":"M","address":"674 Ivan Court","employer":"Cemention","email":"reevestillman@cemention.com","city":"Navarre","state":"MA"}
{"index":{"_id":"732"}}
{"account_number":732,"balance":38445,"firstname":"Delia","lastname":"Cruz","age":37,"gender":"F","address":"870 Cheever Place","employer":"Multron","email":"deliacruz@multron.com","city":"Cresaptown","state":"NH"}
{"index":{"_id":"737"}}
{"account_number":737,"balance":40431,"firstname":"Sampson","lastname":"Yates","age":23,"gender":"F","address":"214 Cox Place","employer":"Signidyne","email":"sampsonyates@signidyne.com","city":"Brazos","state":"GA"}
{"index":{"_id":"744"}}
{"account_number":744,"balance":8690,"firstname":"Bernard","lastname":"Martinez","age":21,"gender":"M","address":"148 Dunne Place","employer":"Dragbot","email":"bernardmartinez@dragbot.com","city":"Moraida","state":"MN"}
{"index":{"_id":"749"}}
{"account_number":749,"balance":1249,"firstname":"Rush","lastname":"Boyle","age":36,"gender":"M","address":"310 Argyle Road","employer":"Sportan","email":"rushboyle@sportan.com","city":"Brady","state":"WA"}
{"index":{"_id":"751"}}
{"account_number":751,"balance":49252,"firstname":"Patrick","lastname":"Osborne","age":23,"gender":"M","address":"915 Prospect Avenue","employer":"Gynko","email":"patrickosborne@gynko.com","city":"Takilma","state":"MO"}
{"index":{"_id":"756"}}
{"account_number":756,"balance":40006,"firstname":"Jasmine","lastname":"Howell","age":32,"gender":"M","address":"605 Elliott Walk","employer":"Ecratic","email":"jasminehowell@ecratic.com","city":"Harrodsburg","state":"OH"}
{"index":{"_id":"763"}}
{"account_number":763,"balance":12091,"firstname":"Liz","lastname":"Bentley","age":22,"gender":"F","address":"933 Debevoise Avenue","employer":"Nipaz","email":"lizbentley@nipaz.com","city":"Glenville","state":"NJ"}
{"index":{"_id":"768"}}
{"account_number":768,"balance":2213,"firstname":"Sondra","lastname":"Soto","age":21,"gender":"M","address":"625 Colonial Road","employer":"Navir","email":"sondrasoto@navir.com","city":"Benson","state":"VA"}
{"index":{"_id":"770"}}
{"account_number":770,"balance":39505,"firstname":"Joann","lastname":"Crane","age":26,"gender":"M","address":"798 Farragut Place","employer":"Lingoage","email":"joanncrane@lingoage.com","city":"Kirk","state":"MA"}
{"index":{"_id":"775"}}
{"account_number":775,"balance":27943,"firstname":"Wilson","lastname":"Merritt","age":33,"gender":"F","address":"288 Thornton Street","employer":"Geeky","email":"wilsonmerritt@geeky.com","city":"Holtville","state":"HI"}
{"index":{"_id":"782"}}
{"account_number":782,"balance":3960,"firstname":"Maldonado","lastname":"Craig","age":36,"gender":"F","address":"345 Myrtle Avenue","employer":"Zilencio","email":"maldonadocraig@zilencio.com","city":"Yukon","state":"ID"}
{"index":{"_id":"787"}}
{"account_number":787,"balance":11876,"firstname":"Harper","lastname":"Wynn","age":21,"gender":"F","address":"139 Oceanic Avenue","employer":"Interfind","email":"harperwynn@interfind.com","city":"Gerber","state":"ND"}
{"index":{"_id":"794"}}
{"account_number":794,"balance":16491,"firstname":"Walker","lastname":"Charles","age":32,"gender":"M","address":"215 Kenilworth Place","employer":"Orbin","email":"walkercharles@orbin.com","city":"Rivers","state":"WI"}
{"index":{"_id":"799"}}
{"account_number":799,"balance":2889,"firstname":"Myra","lastname":"Guerra","age":28,"gender":"F","address":"625 Dahlgreen Place","employer":"Digigene","email":"myraguerra@digigene.com","city":"Draper","state":"CA"}
{"index":{"_id":"802"}}
{"account_number":802,"balance":19630,"firstname":"Gracie","lastname":"Foreman","age":40,"gender":"F","address":"219 Kent Avenue","employer":"Supportal","email":"gracieforeman@supportal.com","city":"Westboro","state":"NH"}
{"index":{"_id":"807"}}
{"account_number":807,"balance":29206,"firstname":"Hatfield","lastname":"Lowe","age":23,"gender":"M","address":"499 Adler Place","employer":"Lovepad","email":"hatfieldlowe@lovepad.com","city":"Wiscon","state":"DC"}
{"index":{"_id":"814"}}
{"account_number":814,"balance":9838,"firstname":"Morse","lastname":"Mcbride","age":26,"gender":"F","address":"776 Calyer Street","employer":"Inear","email":"morsemcbride@inear.com","city":"Kingstowne","state":"ND"}
{"index":{"_id":"819"}}
{"account_number":819,"balance":3971,"firstname":"Karyn","lastname":"Medina","age":24,"gender":"F","address":"417 Utica Avenue","employer":"Qnekt","email":"karynmedina@qnekt.com","city":"Kerby","state":"WY"}
{"index":{"_id":"821"}}
{"account_number":821,"balance":33271,"firstname":"Trisha","lastname":"Blankenship","age":22,"gender":"M","address":"329 Jamaica Avenue","employer":"Chorizon","email":"trishablankenship@chorizon.com","city":"Sexton","state":"VT"}
{"index":{"_id":"826"}}
{"account_number":826,"balance":11548,"firstname":"Summers","lastname":"Vinson","age":22,"gender":"F","address":"742 Irwin Street","employer":"Globoil","email":"summersvinson@globoil.com","city":"Callaghan","state":"WY"}
{"index":{"_id":"833"}}
{"account_number":833,"balance":46154,"firstname":"Woodward","lastname":"Hood","age":22,"gender":"M","address":"398 Atkins Avenue","employer":"Zedalis","email":"woodwardhood@zedalis.com","city":"Stonybrook","state":"NE"}
{"index":{"_id":"838"}}
{"account_number":838,"balance":24629,"firstname":"Latonya","lastname":"Blake","age":37,"gender":"F","address":"531 Milton Street","employer":"Rugstars","email":"latonyablake@rugstars.com","city":"Tedrow","state":"WA"}
{"index":{"_id":"840"}}
{"account_number":840,"balance":39615,"firstname":"Boone","lastname":"Gomez","age":38,"gender":"M","address":"256 Hampton Place","employer":"Geekular","email":"boonegomez@geekular.com","city":"Westerville","state":"HI"}
{"index":{"_id":"845"}}
{"account_number":845,"balance":35422,"firstname":"Tracy","lastname":"Vaughn","age":39,"gender":"M","address":"645 Rockaway Parkway","employer":"Andryx","email":"tracyvaughn@andryx.com","city":"Wilmington","state":"ME"}
{"index":{"_id":"852"}}
{"account_number":852,"balance":6041,"firstname":"Allen","lastname":"Hammond","age":26,"gender":"M","address":"793 Essex Street","employer":"Tersanki","email":"allenhammond@tersanki.com","city":"Osmond","state":"NC"}
{"index":{"_id":"857"}}
{"account_number":857,"balance":39678,"firstname":"Alyce","lastname":"Douglas","age":23,"gender":"M","address":"326 Robert Street","employer":"Earbang","email":"alycedouglas@earbang.com","city":"Thornport","state":"GA"}
{"index":{"_id":"864"}}
{"account_number":864,"balance":21804,"firstname":"Duffy","lastname":"Anthony","age":23,"gender":"M","address":"582 Cooke Court","employer":"Schoolio","email":"duffyanthony@schoolio.com","city":"Brenton","state":"CO"}
{"index":{"_id":"869"}}
{"account_number":869,"balance":43544,"firstname":"Corinne","lastname":"Robbins","age":25,"gender":"F","address":"732 Quentin Road","employer":"Orbaxter","email":"corinnerobbins@orbaxter.com","city":"Roy","state":"TN"}
{"index":{"_id":"871"}}
{"account_number":871,"balance":35854,"firstname":"Norma","lastname":"Burt","age":32,"gender":"M","address":"934 Cyrus Avenue","employer":"Magnafone","email":"normaburt@magnafone.com","city":"Eden","state":"TN"}
{"index":{"_id":"876"}}
{"account_number":876,"balance":48568,"firstname":"Brady","lastname":"Glover","age":21,"gender":"F","address":"565 Oceanview Avenue","employer":"Comvex","email":"bradyglover@comvex.com","city":"Noblestown","state":"ID"}
{"index":{"_id":"883"}}
{"account_number":883,"balance":33679,"firstname":"Austin","lastname":"Jefferson","age":34,"gender":"M","address":"846 Lincoln Avenue","employer":"Polarax","email":"austinjefferson@polarax.com","city":"Savannah","state":"CT"}
{"index":{"_id":"888"}}
{"account_number":888,"balance":22277,"firstname":"Myrna","lastname":"Herman","age":39,"gender":"F","address":"649 Harwood Place","employer":"Enthaze","email":"myrnaherman@enthaze.com","city":"Idamay","state":"AR"}
{"index":{"_id":"890"}}
{"account_number":890,"balance":31198,"firstname":"Alvarado","lastname":"Pate","age":25,"gender":"M","address":"269 Ashland Place","employer":"Ovolo","email":"alvaradopate@ovolo.com","city":"Volta","state":"MI"}
{"index":{"_id":"895"}}
{"account_number":895,"balance":7327,"firstname":"Lara","lastname":"Mcdaniel","age":36,"gender":"M","address":"854 Willow Place","employer":"Acusage","email":"laramcdaniel@acusage.com","city":"Imperial","state":"NC"}
{"index":{"_id":"903"}}
{"account_number":903,"balance":10238,"firstname":"Wade","lastname":"Page","age":35,"gender":"F","address":"685 Waldorf Court","employer":"Eplosion","email":"wadepage@eplosion.com","city":"Welda","state":"AL"}
{"index":{"_id":"908"}}
{"account_number":908,"balance":45975,"firstname":"Mosley","lastname":"Holloway","age":31,"gender":"M","address":"929 Eldert Lane","employer":"Anivet","email":"mosleyholloway@anivet.com","city":"Biehle","state":"MS"}
{"index":{"_id":"910"}}
{"account_number":910,"balance":36831,"firstname":"Esmeralda","lastname":"James","age":23,"gender":"F","address":"535 High Street","employer":"Terrasys","email":"esmeraldajames@terrasys.com","city":"Dubois","state":"IN"}
{"index":{"_id":"915"}}
{"account_number":915,"balance":19816,"firstname":"Farrell","lastname":"French","age":35,"gender":"F","address":"126 McKibbin Street","employer":"Techmania","email":"farrellfrench@techmania.com","city":"Wescosville","state":"AL"}
{"index":{"_id":"922"}}
{"account_number":922,"balance":39347,"firstname":"Irwin","lastname":"Pugh","age":32,"gender":"M","address":"463 Shale Street","employer":"Idego","email":"irwinpugh@idego.com","city":"Ivanhoe","state":"ID"}
{"index":{"_id":"927"}}
{"account_number":927,"balance":19976,"firstname":"Jeanette","lastname":"Acevedo","age":26,"gender":"M","address":"694 Polhemus Place","employer":"Halap","email":"jeanetteacevedo@halap.com","city":"Harrison","state":"MO"}
{"index":{"_id":"934"}}
{"account_number":934,"balance":43987,"firstname":"Freida","lastname":"Daniels","age":34,"gender":"M","address":"448 Cove Lane","employer":"Vurbo","email":"freidadaniels@vurbo.com","city":"Snelling","state":"NJ"}
{"index":{"_id":"939"}}
{"account_number":939,"balance":31228,"firstname":"Hodges","lastname":"Massey","age":37,"gender":"F","address":"431 Dahl Court","employer":"Kegular","email":"hodgesmassey@kegular.com","city":"Katonah","state":"MD"}
{"index":{"_id":"941"}}
{"account_number":941,"balance":38796,"firstname":"Kim","lastname":"Moss","age":28,"gender":"F","address":"105 Onderdonk Avenue","employer":"Digirang","email":"kimmoss@digirang.com","city":"Centerville","state":"TX"}
{"index":{"_id":"946"}}
{"account_number":946,"balance":42794,"firstname":"Ina","lastname":"Obrien","age":36,"gender":"M","address":"339 Rewe Street","employer":"Eclipsent","email":"inaobrien@eclipsent.com","city":"Soham","state":"RI"}
{"index":{"_id":"953"}}
{"account_number":953,"balance":1110,"firstname":"Baxter","lastname":"Black","age":27,"gender":"M","address":"720 Stillwell Avenue","employer":"Uplinx","email":"baxterblack@uplinx.com","city":"Drummond","state":"MN"}
{"index":{"_id":"958"}}
{"account_number":958,"balance":32849,"firstname":"Brown","lastname":"Wilkins","age":40,"gender":"M","address":"686 Delmonico Place","employer":"Medesign","email":"brownwilkins@medesign.com","city":"Shelby","state":"WY"}
{"index":{"_id":"960"}}
{"account_number":960,"balance":2905,"firstname":"Curry","lastname":"Vargas","age":40,"gender":"M","address":"242 Blake Avenue","employer":"Pearlesex","email":"curryvargas@pearlesex.com","city":"Henrietta","state":"NH"}
{"index":{"_id":"965"}}
{"account_number":965,"balance":21882,"firstname":"Patrica","lastname":"Melton","age":28,"gender":"M","address":"141 Rodney Street","employer":"Flexigen","email":"patricamelton@flexigen.com","city":"Klagetoh","state":"MD"}
{"index":{"_id":"972"}}
{"account_number":972,"balance":24719,"firstname":"Leona","lastname":"Christian","age":26,"gender":"F","address":"900 Woodpoint Road","employer":"Extrawear","email":"leonachristian@extrawear.com","city":"Roderfield","state":"MA"}
{"index":{"_id":"977"}}
{"account_number":977,"balance":6744,"firstname":"Rodgers","lastname":"Mccray","age":21,"gender":"F","address":"612 Duryea Place","employer":"Papricut","email":"rodgersmccray@papricut.com","city":"Marenisco","state":"MD"}
{"index":{"_id":"984"}}
{"account_number":984,"balance":1904,"firstname":"Viola","lastname":"Crawford","age":35,"gender":"F","address":"354 Linwood Street","employer":"Ginkle","email":"violacrawford@ginkle.com","city":"Witmer","state":"AR"}
{"index":{"_id":"989"}}
{"account_number":989,"balance":48622,"firstname":"Franklin","lastname":"Frank","age":38,"gender":"M","address":"270 Carlton Avenue","employer":"Shopabout","email":"franklinfrank@shopabout.com","city":"Guthrie","state":"NC"}
{"index":{"_id":"991"}}
{"account_number":991,"balance":4239,"firstname":"Connie","lastname":"Berry","age":28,"gender":"F","address":"647 Gardner Avenue","employer":"Flumbo","email":"connieberry@flumbo.com","city":"Frierson","state":"MO"}
{"index":{"_id":"996"}}
{"account_number":996,"balance":17541,"firstname":"Andrews","lastname":"Herrera","age":30,"gender":"F","address":"570 Vandam Street","employer":"Klugger","email":"andrewsherrera@klugger.com","city":"Whitehaven","state":"MN"}
{"index":{"_id":"0"}}
{"account_number":0,"balance":16623,"firstname":"Bradshaw","lastname":"Mckenzie","age":29,"gender":"F","address":"244 Columbus Place","employer":"Euron","email":"bradshawmckenzie@euron.com","city":"Hobucken","state":"CO"}
{"index":{"_id":"5"}}
{"account_number":5,"balance":29342,"firstname":"Leola","lastname":"Stewart","age":30,"gender":"F","address":"311 Elm Place","employer":"Diginetic","email":"leolastewart@diginetic.com","city":"Fairview","state":"NJ"}
{"index":{"_id":"12"}}
{"account_number":12,"balance":37055,"firstname":"Stafford","lastname":"Brock","age":20,"gender":"F","address":"296 Wythe Avenue","employer":"Uncorp","email":"staffordbrock@uncorp.com","city":"Bend","state":"AL"}
{"index":{"_id":"17"}}
{"account_number":17,"balance":7831,"firstname":"Bessie","lastname":"Orr","age":31,"gender":"F","address":"239 Hinsdale Street","employer":"Skyplex","email":"bessieorr@skyplex.com","city":"Graball","state":"FL"}
{"index":{"_id":"24"}}
{"account_number":24,"balance":44182,"firstname":"Wood","lastname":"Dale","age":39,"gender":"M","address":"582 Gelston Avenue","employer":"Besto","email":"wooddale@besto.com","city":"Juntura","state":"MI"}
{"index":{"_id":"29"}}
{"account_number":29,"balance":27323,"firstname":"Leah","lastname":"Santiago","age":33,"gender":"M","address":"193 Schenck Avenue","employer":"Isologix","email":"leahsantiago@isologix.com","city":"Gerton","state":"ND"}
{"index":{"_id":"31"}}
{"account_number":31,"balance":30443,"firstname":"Kristen","lastname":"Santana","age":22,"gender":"F","address":"130 Middagh Street","employer":"Dogspa","email":"kristensantana@dogspa.com","city":"Vale","state":"MA"}
{"index":{"_id":"36"}}
{"account_number":36,"balance":15902,"firstname":"Alexandra","lastname":"Nguyen","age":39,"gender":"F","address":"389 Elizabeth Place","employer":"Bittor","email":"alexandranguyen@bittor.com","city":"Hemlock","state":"KY"}
{"index":{"_id":"43"}}
{"account_number":43,"balance":33474,"firstname":"Ryan","lastname":"Howe","age":25,"gender":"M","address":"660 Huntington Street","employer":"Microluxe","email":"ryanhowe@microluxe.com","city":"Clara","state":"CT"}
{"index":{"_id":"48"}}
{"account_number":48,"balance":40608,"firstname":"Peck","lastname":"Downs","age":39,"gender":"F","address":"594 Dwight Street","employer":"Ramjob","email":"peckdowns@ramjob.com","city":"Coloma","state":"WA"}
{"index":{"_id":"50"}}
{"account_number":50,"balance":43695,"firstname":"Sheena","lastname":"Kirkland","age":33,"gender":"M","address":"598 Bank Street","employer":"Zerbina","email":"sheenakirkland@zerbina.com","city":"Walland","state":"IN"}
{"index":{"_id":"55"}}
{"account_number":55,"balance":22020,"firstname":"Shelia","lastname":"Puckett","age":33,"gender":"M","address":"265 Royce Place","employer":"Izzby","email":"sheliapuckett@izzby.com","city":"Slovan","state":"HI"}
{"index":{"_id":"62"}}
{"account_number":62,"balance":43065,"firstname":"Lester","lastname":"Stanton","age":37,"gender":"M","address":"969 Doughty Street","employer":"Geekko","email":"lesterstanton@geekko.com","city":"Itmann","state":"DC"}
{"index":{"_id":"67"}}
{"account_number":67,"balance":39430,"firstname":"Isabelle","lastname":"Spence","age":39,"gender":"M","address":"718 Troy Avenue","employer":"Geeketron","email":"isabellespence@geeketron.com","city":"Camptown","state":"WA"}
{"index":{"_id":"74"}}
{"account_number":74,"balance":47167,"firstname":"Lauri","lastname":"Saunders","age":38,"gender":"F","address":"768 Lynch Street","employer":"Securia","email":"laurisaunders@securia.com","city":"Caroline","state":"TN"}
{"index":{"_id":"79"}}
{"account_number":79,"balance":28185,"firstname":"Booker","lastname":"Lowery","age":29,"gender":"M","address":"817 Campus Road","employer":"Sensate","email":"bookerlowery@sensate.com","city":"Carlos","state":"MT"}
{"index":{"_id":"81"}}
{"account_number":81,"balance":46568,"firstname":"Dennis","lastname":"Gilbert","age":40,"gender":"M","address":"619 Minna Street","employer":"Melbacor","email":"dennisgilbert@melbacor.com","city":"Kersey","state":"ND"}
{"index":{"_id":"86"}}
{"account_number":86,"balance":15428,"firstname":"Walton","lastname":"Butler","age":36,"gender":"M","address":"999 Schenck Street","employer":"Unisure","email":"waltonbutler@unisure.com","city":"Bentonville","state":"IL"}
{"index":{"_id":"93"}}
{"account_number":93,"balance":17728,"firstname":"Jeri","lastname":"Booth","age":31,"gender":"M","address":"322 Roosevelt Court","employer":"Geekology","email":"jeribooth@geekology.com","city":"Leming","state":"ND"}
{"index":{"_id":"98"}}
{"account_number":98,"balance":15085,"firstname":"Cora","lastname":"Barrett","age":24,"gender":"F","address":"555 Neptune Court","employer":"Kiosk","email":"corabarrett@kiosk.com","city":"Independence","state":"MN"}
{"index":{"_id":"101"}}
{"account_number":101,"balance":43400,"firstname":"Cecelia","lastname":"Grimes","age":31,"gender":"M","address":"972 Lincoln Place","employer":"Ecosys","email":"ceceliagrimes@ecosys.com","city":"Manchester","state":"AR"}
{"index":{"_id":"106"}}
{"account_number":106,"balance":8212,"firstname":"Josefina","lastname":"Wagner","age":36,"gender":"M","address":"418 Estate Road","employer":"Kyaguru","email":"josefinawagner@kyaguru.com","city":"Darbydale","state":"FL"}
{"index":{"_id":"113"}}
{"account_number":113,"balance":41652,"firstname":"Burt","lastname":"Moses","age":27,"gender":"M","address":"633 Berry Street","employer":"Uni","email":"burtmoses@uni.com","city":"Russellville","state":"CT"}
{"index":{"_id":"118"}}
{"account_number":118,"balance":2223,"firstname":"Ballard","lastname":"Vasquez","age":33,"gender":"F","address":"101 Bush Street","employer":"Intergeek","email":"ballardvasquez@intergeek.com","city":"Century","state":"MN"}
{"index":{"_id":"120"}}
{"account_number":120,"balance":38565,"firstname":"Browning","lastname":"Rodriquez","age":33,"gender":"M","address":"910 Moore Street","employer":"Opportech","email":"browningrodriquez@opportech.com","city":"Cutter","state":"ND"}
{"index":{"_id":"125"}}
{"account_number":125,"balance":5396,"firstname":"Tanisha","lastname":"Dixon","age":30,"gender":"M","address":"482 Hancock Street","employer":"Junipoor","email":"tanishadixon@junipoor.com","city":"Wauhillau","state":"IA"}
{"index":{"_id":"132"}}
{"account_number":132,"balance":37707,"firstname":"Horton","lastname":"Romero","age":35,"gender":"M","address":"427 Rutherford Place","employer":"Affluex","email":"hortonromero@affluex.com","city":"Hall","state":"AK"}
{"index":{"_id":"137"}}
{"account_number":137,"balance":3596,"firstname":"Frost","lastname":"Freeman","age":29,"gender":"F","address":"191 Dennett Place","employer":"Beadzza","email":"frostfreeman@beadzza.com","city":"Sabillasville","state":"HI"}
{"index":{"_id":"144"}}
{"account_number":144,"balance":43257,"firstname":"Evans","lastname":"Dyer","age":30,"gender":"F","address":"912 Post Court","employer":"Magmina","email":"evansdyer@magmina.com","city":"Gordon","state":"HI"}
{"index":{"_id":"149"}}
{"account_number":149,"balance":22994,"firstname":"Megan","lastname":"Gonzales","age":21,"gender":"M","address":"836 Tampa Court","employer":"Andershun","email":"megangonzales@andershun.com","city":"Rockhill","state":"AL"}
{"index":{"_id":"151"}}
{"account_number":151,"balance":34473,"firstname":"Kent","lastname":"Joyner","age":20,"gender":"F","address":"799 Truxton Street","employer":"Kozgene","email":"kentjoyner@kozgene.com","city":"Allamuchy","state":"DC"}
{"index":{"_id":"156"}}
{"account_number":156,"balance":40185,"firstname":"Sloan","lastname":"Pennington","age":24,"gender":"F","address":"573 Opal Court","employer":"Hopeli","email":"sloanpennington@hopeli.com","city":"Evergreen","state":"CT"}
{"index":{"_id":"163"}}
{"account_number":163,"balance":43075,"firstname":"Wilda","lastname":"Norman","age":33,"gender":"F","address":"173 Beadel Street","employer":"Kog","email":"wildanorman@kog.com","city":"Bodega","state":"ME"}
{"index":{"_id":"168"}}
{"account_number":168,"balance":49568,"firstname":"Carissa","lastname":"Simon","age":20,"gender":"M","address":"975 Flatbush Avenue","employer":"Zillacom","email":"carissasimon@zillacom.com","city":"Neibert","state":"IL"}
{"index":{"_id":"170"}}
{"account_number":170,"balance":6025,"firstname":"Mann","lastname":"Madden","age":36,"gender":"F","address":"161 Radde Place","employer":"Farmex","email":"mannmadden@farmex.com","city":"Thermal","state":"LA"}
{"index":{"_id":"175"}}
{"account_number":175,"balance":16213,"firstname":"Montoya","lastname":"Donaldson","age":28,"gender":"F","address":"481 Morton Street","employer":"Envire","email":"montoyadonaldson@envire.com","city":"Delco","state":"MA"}
{"index":{"_id":"182"}}
{"account_number":182,"balance":7803,"firstname":"Manuela","lastname":"Dillon","age":21,"gender":"M","address":"742 Garnet Street","employer":"Moreganic","email":"manueladillon@moreganic.com","city":"Ilchester","state":"TX"}
{"index":{"_id":"187"}}
{"account_number":187,"balance":26581,"firstname":"Autumn","lastname":"Hodges","age":35,"gender":"M","address":"757 Granite Street","employer":"Ezentia","email":"autumnhodges@ezentia.com","city":"Martinsville","state":"KY"}
{"index":{"_id":"194"}}
{"account_number":194,"balance":16311,"firstname":"Beck","lastname":"Rosario","age":39,"gender":"M","address":"721 Cambridge Place","employer":"Zoid","email":"beckrosario@zoid.com","city":"Efland","state":"ID"}
{"index":{"_id":"199"}}
{"account_number":199,"balance":18086,"firstname":"Branch","lastname":"Love","age":26,"gender":"M","address":"458 Commercial Street","employer":"Frolix","email":"branchlove@frolix.com","city":"Caspar","state":"NC"}
{"index":{"_id":"202"}}
{"account_number":202,"balance":26466,"firstname":"Medina","lastname":"Brown","age":31,"gender":"F","address":"519 Sunnyside Court","employer":"Bleendot","email":"medinabrown@bleendot.com","city":"Winfred","state":"MI"}
{"index":{"_id":"207"}}
{"account_number":207,"balance":45535,"firstname":"Evelyn","lastname":"Lara","age":35,"gender":"F","address":"636 Chestnut Street","employer":"Ultrasure","email":"evelynlara@ultrasure.com","city":"Logan","state":"MI"}
{"index":{"_id":"214"}}
{"account_number":214,"balance":24418,"firstname":"Luann","lastname":"Faulkner","age":37,"gender":"F","address":"697 Hazel Court","employer":"Zolar","email":"luannfaulkner@zolar.com","city":"Ticonderoga","state":"TX"}
{"index":{"_id":"219"}}
{"account_number":219,"balance":17127,"firstname":"Edwards","lastname":"Hurley","age":25,"gender":"M","address":"834 Stockholm Street","employer":"Austech","email":"edwardshurley@austech.com","city":"Bayview","state":"NV"}
{"index":{"_id":"221"}}
{"account_number":221,"balance":15803,"firstname":"Benjamin","lastname":"Barrera","age":34,"gender":"M","address":"568 Main Street","employer":"Zaphire","email":"benjaminbarrera@zaphire.com","city":"Germanton","state":"WY"}
{"index":{"_id":"226"}}
{"account_number":226,"balance":37720,"firstname":"Wilkins","lastname":"Brady","age":40,"gender":"F","address":"486 Baltic Street","employer":"Dogtown","email":"wilkinsbrady@dogtown.com","city":"Condon","state":"MT"}
{"index":{"_id":"233"}}
{"account_number":233,"balance":23020,"firstname":"Washington","lastname":"Walsh","age":27,"gender":"M","address":"366 Church Avenue","employer":"Candecor","email":"washingtonwalsh@candecor.com","city":"Westphalia","state":"MA"}
{"index":{"_id":"238"}}
{"account_number":238,"balance":21287,"firstname":"Constance","lastname":"Wong","age":28,"gender":"M","address":"496 Brown Street","employer":"Grainspot","email":"constancewong@grainspot.com","city":"Cecilia","state":"IN"}
{"index":{"_id":"240"}}
{"account_number":240,"balance":49741,"firstname":"Oconnor","lastname":"Clay","age":35,"gender":"F","address":"659 Highland Boulevard","employer":"Franscene","email":"oconnorclay@franscene.com","city":"Kilbourne","state":"NH"}
{"index":{"_id":"245"}}
{"account_number":245,"balance":22026,"firstname":"Fran","lastname":"Bolton","age":28,"gender":"F","address":"147 Jerome Street","employer":"Solaren","email":"franbolton@solaren.com","city":"Nash","state":"RI"}
{"index":{"_id":"252"}}
{"account_number":252,"balance":18831,"firstname":"Elvia","lastname":"Poole","age":22,"gender":"F","address":"836 Delevan Street","employer":"Velity","email":"elviapoole@velity.com","city":"Groveville","state":"MI"}
{"index":{"_id":"257"}}
{"account_number":257,"balance":5318,"firstname":"Olive","lastname":"Oneil","age":35,"gender":"F","address":"457 Decatur Street","employer":"Helixo","email":"oliveoneil@helixo.com","city":"Chicopee","state":"MI"}
{"index":{"_id":"264"}}
{"account_number":264,"balance":22084,"firstname":"Samantha","lastname":"Ferrell","age":35,"gender":"F","address":"488 Fulton Street","employer":"Flum","email":"samanthaferrell@flum.com","city":"Brandywine","state":"MT"}
{"index":{"_id":"269"}}
{"account_number":269,"balance":43317,"firstname":"Crosby","lastname":"Figueroa","age":34,"gender":"M","address":"910 Aurelia Court","employer":"Pyramia","email":"crosbyfigueroa@pyramia.com","city":"Leyner","state":"OH"}
{"index":{"_id":"271"}}
{"account_number":271,"balance":11864,"firstname":"Holt","lastname":"Walter","age":30,"gender":"F","address":"645 Poplar Avenue","employer":"Grupoli","email":"holtwalter@grupoli.com","city":"Mansfield","state":"OR"}
{"index":{"_id":"276"}}
{"account_number":276,"balance":11606,"firstname":"Pittman","lastname":"Mathis","age":23,"gender":"F","address":"567 Charles Place","employer":"Zuvy","email":"pittmanmathis@zuvy.com","city":"Roeville","state":"KY"}
{"index":{"_id":"283"}}
{"account_number":283,"balance":24070,"firstname":"Fuentes","lastname":"Foley","age":30,"gender":"M","address":"729 Walker Court","employer":"Knowlysis","email":"fuentesfoley@knowlysis.com","city":"Tryon","state":"TN"}
{"index":{"_id":"288"}}
{"account_number":288,"balance":27243,"firstname":"Wong","lastname":"Stone","age":39,"gender":"F","address":"440 Willoughby Street","employer":"Zentix","email":"wongstone@zentix.com","city":"Wheatfields","state":"DC"}
{"index":{"_id":"290"}}
{"account_number":290,"balance":26103,"firstname":"Neva","lastname":"Burgess","age":37,"gender":"F","address":"985 Wyona Street","employer":"Slofast","email":"nevaburgess@slofast.com","city":"Cawood","state":"DC"}
{"index":{"_id":"295"}}
{"account_number":295,"balance":37358,"firstname":"Howe","lastname":"Nash","age":20,"gender":"M","address":"833 Union Avenue","employer":"Aquacine","email":"howenash@aquacine.com","city":"Indio","state":"MN"}
{"index":{"_id":"303"}}
{"account_number":303,"balance":21976,"firstname":"Huffman","lastname":"Green","age":24,"gender":"F","address":"455 Colby Court","employer":"Comtest","email":"huffmangreen@comtest.com","city":"Weeksville","state":"UT"}
{"index":{"_id":"308"}}
{"account_number":308,"balance":33989,"firstname":"Glass","lastname":"Schroeder","age":25,"gender":"F","address":"670 Veterans Avenue","employer":"Realmo","email":"glassschroeder@realmo.com","city":"Gratton","state":"NY"}
{"index":{"_id":"310"}}
{"account_number":310,"balance":23049,"firstname":"Shannon","lastname":"Morton","age":39,"gender":"F","address":"412 Pleasant Place","employer":"Ovation","email":"shannonmorton@ovation.com","city":"Edgar","state":"AZ"}
{"index":{"_id":"315"}}
{"account_number":315,"balance":1314,"firstname":"Clare","lastname":"Morrow","age":33,"gender":"F","address":"728 Madeline Court","employer":"Gaptec","email":"claremorrow@gaptec.com","city":"Mapletown","state":"PA"}
{"index":{"_id":"322"}}
{"account_number":322,"balance":6303,"firstname":"Gilliam","lastname":"Horne","age":27,"gender":"M","address":"414 Florence Avenue","employer":"Shepard","email":"gilliamhorne@shepard.com","city":"Winesburg","state":"WY"}
{"index":{"_id":"327"}}
{"account_number":327,"balance":29294,"firstname":"Nell","lastname":"Contreras","age":27,"gender":"M","address":"694 Gold Street","employer":"Momentia","email":"nellcontreras@momentia.com","city":"Cumminsville","state":"AL"}
{"index":{"_id":"334"}}
{"account_number":334,"balance":9178,"firstname":"Cross","lastname":"Floyd","age":21,"gender":"F","address":"815 Herkimer Court","employer":"Maroptic","email":"crossfloyd@maroptic.com","city":"Kraemer","state":"AK"}
{"index":{"_id":"339"}}
{"account_number":339,"balance":3992,"firstname":"Franco","lastname":"Welch","age":38,"gender":"F","address":"776 Brightwater Court","employer":"Earthplex","email":"francowelch@earthplex.com","city":"Naomi","state":"ME"}
{"index":{"_id":"341"}}
{"account_number":341,"balance":44367,"firstname":"Alberta","lastname":"Bradford","age":30,"gender":"F","address":"670 Grant Avenue","employer":"Bugsall","email":"albertabradford@bugsall.com","city":"Romeville","state":"MT"}
{"index":{"_id":"346"}}
{"account_number":346,"balance":26594,"firstname":"Shelby","lastname":"Sanchez","age":36,"gender":"F","address":"257 Fillmore Avenue","employer":"Geekus","email":"shelbysanchez@geekus.com","city":"Seymour","state":"CO"}
{"index":{"_id":"353"}}
{"account_number":353,"balance":45182,"firstname":"Rivera","lastname":"Sherman","age":37,"gender":"M","address":"603 Garden Place","employer":"Bovis","email":"riverasherman@bovis.com","city":"Otranto","state":"CA"}
{"index":{"_id":"358"}}
{"account_number":358,"balance":44043,"firstname":"Hale","lastname":"Baldwin","age":40,"gender":"F","address":"845 Menahan Street","employer":"Kidgrease","email":"halebaldwin@kidgrease.com","city":"Day","state":"AK"}
{"index":{"_id":"360"}}
{"account_number":360,"balance":26651,"firstname":"Ward","lastname":"Hicks","age":34,"gender":"F","address":"592 Brighton Court","employer":"Biotica","email":"wardhicks@biotica.com","city":"Kanauga","state":"VT"}
{"index":{"_id":"365"}}
{"account_number":365,"balance":3176,"firstname":"Sanders","lastname":"Holder","age":31,"gender":"F","address":"453 Cypress Court","employer":"Geekola","email":"sandersholder@geekola.com","city":"Staples","state":"TN"}
{"index":{"_id":"372"}}
{"account_number":372,"balance":28566,"firstname":"Alba","lastname":"Forbes","age":24,"gender":"M","address":"814 Meserole Avenue","employer":"Isostream","email":"albaforbes@isostream.com","city":"Clarence","state":"OR"}
{"index":{"_id":"377"}}
{"account_number":377,"balance":5374,"firstname":"Margo","lastname":"Gay","age":34,"gender":"F","address":"613 Chase Court","employer":"Rotodyne","email":"margogay@rotodyne.com","city":"Waumandee","state":"KS"}
{"index":{"_id":"384"}}
{"account_number":384,"balance":48758,"firstname":"Sallie","lastname":"Houston","age":31,"gender":"F","address":"836 Polar Street","employer":"Squish","email":"salliehouston@squish.com","city":"Morningside","state":"NC"}
{"index":{"_id":"389"}}
{"account_number":389,"balance":8839,"firstname":"York","lastname":"Cummings","age":27,"gender":"M","address":"778 Centre Street","employer":"Insurity","email":"yorkcummings@insurity.com","city":"Freeburn","state":"RI"}
{"index":{"_id":"391"}}
{"account_number":391,"balance":14733,"firstname":"Holman","lastname":"Jordan","age":30,"gender":"M","address":"391 Forrest Street","employer":"Maineland","email":"holmanjordan@maineland.com","city":"Cade","state":"CT"}
{"index":{"_id":"396"}}
{"account_number":396,"balance":14613,"firstname":"Marsha","lastname":"Elliott","age":38,"gender":"F","address":"297 Liberty Avenue","employer":"Orbiflex","email":"marshaelliott@orbiflex.com","city":"Windsor","state":"TX"}
{"index":{"_id":"404"}}
{"account_number":404,"balance":34978,"firstname":"Massey","lastname":"Becker","age":26,"gender":"F","address":"930 Pitkin Avenue","employer":"Genekom","email":"masseybecker@genekom.com","city":"Blairstown","state":"OR"}
{"index":{"_id":"409"}}
{"account_number":409,"balance":36960,"firstname":"Maura","lastname":"Glenn","age":31,"gender":"M","address":"183 Poly Place","employer":"Viagreat","email":"mauraglenn@viagreat.com","city":"Foscoe","state":"DE"}
{"index":{"_id":"411"}}
{"account_number":411,"balance":1172,"firstname":"Guzman","lastname":"Whitfield","age":22,"gender":"M","address":"181 Perry Terrace","employer":"Springbee","email":"guzmanwhitfield@springbee.com","city":"Balm","state":"IN"}
{"index":{"_id":"416"}}
{"account_number":416,"balance":27169,"firstname":"Hunt","lastname":"Schwartz","age":28,"gender":"F","address":"461 Havens Place","employer":"Danja","email":"huntschwartz@danja.com","city":"Grenelefe","state":"NV"}
{"index":{"_id":"423"}}
{"account_number":423,"balance":38852,"firstname":"Hines","lastname":"Underwood","age":21,"gender":"F","address":"284 Louise Terrace","employer":"Namegen","email":"hinesunderwood@namegen.com","city":"Downsville","state":"CO"}
{"index":{"_id":"428"}}
{"account_number":428,"balance":13925,"firstname":"Stephens","lastname":"Cain","age":20,"gender":"F","address":"189 Summit Street","employer":"Rocklogic","email":"stephenscain@rocklogic.com","city":"Bourg","state":"HI"}
{"index":{"_id":"430"}}
{"account_number":430,"balance":15251,"firstname":"Alejandra","lastname":"Chavez","age":34,"gender":"M","address":"651 Butler Place","employer":"Gology","email":"alejandrachavez@gology.com","city":"Allensworth","state":"VT"}
{"index":{"_id":"435"}}
{"account_number":435,"balance":14654,"firstname":"Sue","lastname":"Lopez","age":22,"gender":"F","address":"632 Stone Avenue","employer":"Emergent","email":"suelopez@emergent.com","city":"Waterford","state":"TN"}
{"index":{"_id":"442"}}
{"account_number":442,"balance":36211,"firstname":"Lawanda","lastname":"Leon","age":27,"gender":"F","address":"126 Canal Avenue","employer":"Xixan","email":"lawandaleon@xixan.com","city":"Berwind","state":"TN"}
{"index":{"_id":"447"}}
{"account_number":447,"balance":11402,"firstname":"Lucia","lastname":"Livingston","age":35,"gender":"M","address":"773 Lake Avenue","employer":"Soprano","email":"lucialivingston@soprano.com","city":"Edgewater","state":"TN"}
{"index":{"_id":"454"}}
{"account_number":454,"balance":31687,"firstname":"Alicia","lastname":"Rollins","age":22,"gender":"F","address":"483 Verona Place","employer":"Boilcat","email":"aliciarollins@boilcat.com","city":"Lutsen","state":"MD"}
{"index":{"_id":"459"}}
{"account_number":459,"balance":18869,"firstname":"Pamela","lastname":"Henry","age":20,"gender":"F","address":"361 Locust Avenue","employer":"Imageflow","email":"pamelahenry@imageflow.com","city":"Greenfields","state":"OH"}
{"index":{"_id":"461"}}
{"account_number":461,"balance":38807,"firstname":"Mcbride","lastname":"Padilla","age":34,"gender":"F","address":"550 Borinquen Pl","employer":"Zepitope","email":"mcbridepadilla@zepitope.com","city":"Emory","state":"AZ"}
{"index":{"_id":"466"}}
{"account_number":466,"balance":25109,"firstname":"Marcie","lastname":"Mcmillan","age":30,"gender":"F","address":"947 Gain Court","employer":"Entroflex","email":"marciemcmillan@entroflex.com","city":"Ronco","state":"ND"}
{"index":{"_id":"473"}}
{"account_number":473,"balance":5391,"firstname":"Susan","lastname":"Luna","age":25,"gender":"F","address":"521 Bogart Street","employer":"Zaya","email":"susanluna@zaya.com","city":"Grazierville","state":"MI"}
{"index":{"_id":"478"}}
{"account_number":478,"balance":28044,"firstname":"Dana","lastname":"Decker","age":35,"gender":"M","address":"627 Dobbin Street","employer":"Acrodance","email":"danadecker@acrodance.com","city":"Sharon","state":"MN"}
{"index":{"_id":"480"}}
{"account_number":480,"balance":40807,"firstname":"Anastasia","lastname":"Parker","age":24,"gender":"M","address":"650 Folsom Place","employer":"Zilladyne","email":"anastasiaparker@zilladyne.com","city":"Oberlin","state":"WY"}
{"index":{"_id":"485"}}
{"account_number":485,"balance":44235,"firstname":"Albert","lastname":"Roberts","age":40,"gender":"M","address":"385 Harman Street","employer":"Stralum","email":"albertroberts@stralum.com","city":"Watrous","state":"NM"}
{"index":{"_id":"492"}}
{"account_number":492,"balance":31055,"firstname":"Burnett","lastname":"Briggs","age":35,"gender":"M","address":"987 Cass Place","employer":"Pharmex","email":"burnettbriggs@pharmex.com","city":"Cornfields","state":"TX"}
{"index":{"_id":"497"}}
{"account_number":497,"balance":13493,"firstname":"Doyle","lastname":"Jenkins","age":30,"gender":"M","address":"205 Nevins Street","employer":"Unia","email":"doylejenkins@unia.com","city":"Nicut","state":"DC"}
{"index":{"_id":"500"}}
{"account_number":500,"balance":39143,"firstname":"Pope","lastname":"Keith","age":28,"gender":"F","address":"537 Fane Court","employer":"Zboo","email":"popekeith@zboo.com","city":"Courtland","state":"AL"}
{"index":{"_id":"505"}}
{"account_number":505,"balance":45493,"firstname":"Shelley","lastname":"Webb","age":29,"gender":"M","address":"873 Crawford Avenue","employer":"Quadeebo","email":"shelleywebb@quadeebo.com","city":"Topanga","state":"IL"}
{"index":{"_id":"512"}}
{"account_number":512,"balance":47432,"firstname":"Alisha","lastname":"Morales","age":29,"gender":"M","address":"623 Batchelder Street","employer":"Terragen","email":"alishamorales@terragen.com","city":"Gilmore","state":"VA"}
{"index":{"_id":"517"}}
{"account_number":517,"balance":3022,"firstname":"Allyson","lastname":"Walls","age":38,"gender":"F","address":"334 Coffey Street","employer":"Gorganic","email":"allysonwalls@gorganic.com","city":"Dahlen","state":"GA"}
{"index":{"_id":"524"}}
{"account_number":524,"balance":49334,"firstname":"Salas","lastname":"Farley","age":30,"gender":"F","address":"499 Trucklemans Lane","employer":"Xumonk","email":"salasfarley@xumonk.com","city":"Noxen","state":"AL"}
{"index":{"_id":"529"}}
{"account_number":529,"balance":21788,"firstname":"Deann","lastname":"Fisher","age":23,"gender":"F","address":"511 Buffalo Avenue","employer":"Twiist","email":"deannfisher@twiist.com","city":"Templeton","state":"WA"}
{"index":{"_id":"531"}}
{"account_number":531,"balance":39770,"firstname":"Janet","lastname":"Pena","age":38,"gender":"M","address":"645 Livonia Avenue","employer":"Corecom","email":"janetpena@corecom.com","city":"Garberville","state":"OK"}
{"index":{"_id":"536"}}
{"account_number":536,"balance":6255,"firstname":"Emma","lastname":"Adkins","age":33,"gender":"F","address":"971 Calder Place","employer":"Ontagene","email":"emmaadkins@ontagene.com","city":"Ruckersville","state":"GA"}
{"index":{"_id":"543"}}
{"account_number":543,"balance":48022,"firstname":"Marina","lastname":"Rasmussen","age":31,"gender":"M","address":"446 Love Lane","employer":"Crustatia","email":"marinarasmussen@crustatia.com","city":"Statenville","state":"MD"}
{"index":{"_id":"548"}}
{"account_number":548,"balance":36930,"firstname":"Sandra","lastname":"Andrews","age":37,"gender":"M","address":"973 Prospect Street","employer":"Datagene","email":"sandraandrews@datagene.com","city":"Inkerman","state":"MO"}
{"index":{"_id":"550"}}
{"account_number":550,"balance":32238,"firstname":"Walsh","lastname":"Goodwin","age":22,"gender":"M","address":"953 Canda Avenue","employer":"Proflex","email":"walshgoodwin@proflex.com","city":"Ypsilanti","state":"MT"}
{"index":{"_id":"555"}}
{"account_number":555,"balance":10750,"firstname":"Fannie","lastname":"Slater","age":31,"gender":"M","address":"457 Tech Place","employer":"Kineticut","email":"fannieslater@kineticut.com","city":"Basye","state":"MO"}
{"index":{"_id":"562"}}
{"account_number":562,"balance":10737,"firstname":"Sarah","lastname":"Strong","age":39,"gender":"F","address":"177 Pioneer Street","employer":"Megall","email":"sarahstrong@megall.com","city":"Ladera","state":"WY"}
{"index":{"_id":"567"}}
{"account_number":567,"balance":6507,"firstname":"Diana","lastname":"Dominguez","age":40,"gender":"M","address":"419 Albany Avenue","employer":"Ohmnet","email":"dianadominguez@ohmnet.com","city":"Wildwood","state":"TX"}
{"index":{"_id":"574"}}
{"account_number":574,"balance":32954,"firstname":"Andrea","lastname":"Mosley","age":24,"gender":"M","address":"368 Throop Avenue","employer":"Musix","email":"andreamosley@musix.com","city":"Blende","state":"DC"}
{"index":{"_id":"579"}}
{"account_number":579,"balance":12044,"firstname":"Banks","lastname":"Sawyer","age":36,"gender":"M","address":"652 Doone Court","employer":"Rooforia","email":"bankssawyer@rooforia.com","city":"Foxworth","state":"ND"}
{"index":{"_id":"581"}}
{"account_number":581,"balance":16525,"firstname":"Fuller","lastname":"Mcintyre","age":32,"gender":"M","address":"169 Bergen Place","employer":"Applideck","email":"fullermcintyre@applideck.com","city":"Kenvil","state":"NY"}
{"index":{"_id":"586"}}
{"account_number":586,"balance":13644,"firstname":"Love","lastname":"Velasquez","age":26,"gender":"F","address":"290 Girard Street","employer":"Zomboid","email":"lovevelasquez@zomboid.com","city":"Villarreal","state":"SD"}
{"index":{"_id":"593"}}
{"account_number":593,"balance":41230,"firstname":"Muriel","lastname":"Vazquez","age":37,"gender":"M","address":"395 Montgomery Street","employer":"Sustenza","email":"murielvazquez@sustenza.com","city":"Strykersville","state":"OK"}
{"index":{"_id":"598"}}
{"account_number":598,"balance":33251,"firstname":"Morgan","lastname":"Coleman","age":33,"gender":"M","address":"324 McClancy Place","employer":"Aclima","email":"morgancoleman@aclima.com","city":"Bowden","state":"WA"}
{"index":{"_id":"601"}}
{"account_number":601,"balance":20796,"firstname":"Vickie","lastname":"Valentine","age":34,"gender":"F","address":"432 Bassett Avenue","employer":"Comvene","email":"vickievalentine@comvene.com","city":"Teasdale","state":"UT"}
{"index":{"_id":"606"}}
{"account_number":606,"balance":28770,"firstname":"Michael","lastname":"Bray","age":31,"gender":"M","address":"935 Lake Place","employer":"Telepark","email":"michaelbray@telepark.com","city":"Lemoyne","state":"CT"}
{"index":{"_id":"613"}}
{"account_number":613,"balance":39340,"firstname":"Eddie","lastname":"Mccarty","age":34,"gender":"F","address":"971 Richards Street","employer":"Bisba","email":"eddiemccarty@bisba.com","city":"Fruitdale","state":"NY"}
{"index":{"_id":"618"}}
{"account_number":618,"balance":8976,"firstname":"Cheri","lastname":"Ford","age":30,"gender":"F","address":"803 Ridgewood Avenue","employer":"Zorromop","email":"cheriford@zorromop.com","city":"Gambrills","state":"VT"}
{"index":{"_id":"620"}}
{"account_number":620,"balance":7224,"firstname":"Coleen","lastname":"Bartlett","age":38,"gender":"M","address":"761 Carroll Street","employer":"Idealis","email":"coleenbartlett@idealis.com","city":"Mathews","state":"DE"}
{"index":{"_id":"625"}}
{"account_number":625,"balance":46010,"firstname":"Cynthia","lastname":"Johnston","age":23,"gender":"M","address":"142 Box Street","employer":"Zentry","email":"cynthiajohnston@zentry.com","city":"Makena","state":"MA"}
{"index":{"_id":"632"}}
{"account_number":632,"balance":40470,"firstname":"Kay","lastname":"Warren","age":20,"gender":"F","address":"422 Alabama Avenue","employer":"Realysis","email":"kaywarren@realysis.com","city":"Homestead","state":"HI"}
{"index":{"_id":"637"}}
{"account_number":637,"balance":3169,"firstname":"Kathy","lastname":"Carter","age":27,"gender":"F","address":"410 Jamison Lane","employer":"Limage","email":"kathycarter@limage.com","city":"Ernstville","state":"WA"}
{"index":{"_id":"644"}}
{"account_number":644,"balance":44021,"firstname":"Etta","lastname":"Miller","age":21,"gender":"F","address":"376 Lawton Street","employer":"Bluegrain","email":"ettamiller@bluegrain.com","city":"Baker","state":"MD"}
{"index":{"_id":"649"}}
{"account_number":649,"balance":20275,"firstname":"Jeanine","lastname":"Malone","age":26,"gender":"F","address":"114 Dodworth Street","employer":"Nixelt","email":"jeaninemalone@nixelt.com","city":"Keyport","state":"AK"}
{"index":{"_id":"651"}}
{"account_number":651,"balance":18360,"firstname":"Young","lastname":"Reeves","age":34,"gender":"M","address":"581 Plaza Street","employer":"Krog","email":"youngreeves@krog.com","city":"Sussex","state":"WY"}
{"index":{"_id":"656"}}
{"account_number":656,"balance":21632,"firstname":"Olson","lastname":"Hunt","age":36,"gender":"M","address":"342 Jaffray Street","employer":"Volax","email":"olsonhunt@volax.com","city":"Bangor","state":"WA"}
{"index":{"_id":"663"}}
{"account_number":663,"balance":2456,"firstname":"Rollins","lastname":"Richards","age":37,"gender":"M","address":"129 Sullivan Place","employer":"Geostele","email":"rollinsrichards@geostele.com","city":"Morgandale","state":"FL"}
{"index":{"_id":"668"}}
{"account_number":668,"balance":45069,"firstname":"Potter","lastname":"Michael","age":27,"gender":"M","address":"803 Glenmore Avenue","employer":"Ontality","email":"pottermichael@ontality.com","city":"Newkirk","state":"KS"}
{"index":{"_id":"670"}}
{"account_number":670,"balance":10178,"firstname":"Ollie","lastname":"Riley","age":22,"gender":"M","address":"252 Jackson Place","employer":"Adornica","email":"ollieriley@adornica.com","city":"Brethren","state":"WI"}
{"index":{"_id":"675"}}
{"account_number":675,"balance":36102,"firstname":"Fisher","lastname":"Shepard","age":27,"gender":"F","address":"859 Varick Street","employer":"Qot","email":"fishershepard@qot.com","city":"Diaperville","state":"MD"}
{"index":{"_id":"682"}}
{"account_number":682,"balance":14168,"firstname":"Anne","lastname":"Hale","age":22,"gender":"F","address":"708 Anthony Street","employer":"Cytrek","email":"annehale@cytrek.com","city":"Beechmont","state":"WV"}
{"index":{"_id":"687"}}
{"account_number":687,"balance":48630,"firstname":"Caroline","lastname":"Cox","age":31,"gender":"M","address":"626 Hillel Place","employer":"Opticon","email":"carolinecox@opticon.com","city":"Loma","state":"ND"}
{"index":{"_id":"694"}}
{"account_number":694,"balance":33125,"firstname":"Craig","lastname":"Palmer","age":31,"gender":"F","address":"273 Montrose Avenue","employer":"Comvey","email":"craigpalmer@comvey.com","city":"Cleary","state":"OK"}
{"index":{"_id":"699"}}
{"account_number":699,"balance":4156,"firstname":"Gallagher","lastname":"Marshall","age":37,"gender":"F","address":"648 Clifford Place","employer":"Exiand","email":"gallaghermarshall@exiand.com","city":"Belfair","state":"KY"}
{"index":{"_id":"702"}}
{"account_number":702,"balance":46490,"firstname":"Meadows","lastname":"Delgado","age":26,"gender":"M","address":"612 Jardine Place","employer":"Daisu","email":"meadowsdelgado@daisu.com","city":"Venice","state":"AR"}
{"index":{"_id":"707"}}
{"account_number":707,"balance":30325,"firstname":"Sonya","lastname":"Trevino","age":30,"gender":"F","address":"181 Irving Place","employer":"Atgen","email":"sonyatrevino@atgen.com","city":"Enetai","state":"TN"}
{"index":{"_id":"714"}}
{"account_number":714,"balance":16602,"firstname":"Socorro","lastname":"Murray","age":34,"gender":"F","address":"810 Manhattan Court","employer":"Isoswitch","email":"socorromurray@isoswitch.com","city":"Jugtown","state":"AZ"}
{"index":{"_id":"719"}}
{"account_number":719,"balance":33107,"firstname":"Leanna","lastname":"Reed","age":25,"gender":"F","address":"528 Krier Place","employer":"Rodeology","email":"leannareed@rodeology.com","city":"Carrizo","state":"WI"}
{"index":{"_id":"721"}}
{"account_number":721,"balance":32958,"firstname":"Mara","lastname":"Dickson","age":26,"gender":"M","address":"810 Harrison Avenue","employer":"Comtours","email":"maradickson@comtours.com","city":"Thynedale","state":"DE"}
{"index":{"_id":"726"}}
{"account_number":726,"balance":44737,"firstname":"Rosemary","lastname":"Salazar","age":21,"gender":"M","address":"290 Croton Loop","employer":"Rockabye","email":"rosemarysalazar@rockabye.com","city":"Helen","state":"IA"}
{"index":{"_id":"733"}}
{"account_number":733,"balance":15722,"firstname":"Lakeisha","lastname":"Mccarthy","age":37,"gender":"M","address":"782 Turnbull Avenue","employer":"Exosis","email":"lakeishamccarthy@exosis.com","city":"Caberfae","state":"NM"}
{"index":{"_id":"738"}}
{"account_number":738,"balance":44936,"firstname":"Rosalind","lastname":"Hunter","age":32,"gender":"M","address":"644 Eaton Court","employer":"Zolarity","email":"rosalindhunter@zolarity.com","city":"Cataract","state":"SD"}
{"index":{"_id":"740"}}
{"account_number":740,"balance":6143,"firstname":"Chambers","lastname":"Hahn","age":22,"gender":"M","address":"937 Windsor Place","employer":"Medalert","email":"chambershahn@medalert.com","city":"Dorneyville","state":"DC"}
{"index":{"_id":"745"}}
{"account_number":745,"balance":4572,"firstname":"Jacobs","lastname":"Sweeney","age":32,"gender":"M","address":"189 Lott Place","employer":"Comtent","email":"jacobssweeney@comtent.com","city":"Advance","state":"NJ"}
{"index":{"_id":"752"}}
{"account_number":752,"balance":14039,"firstname":"Jerry","lastname":"Rush","age":31,"gender":"M","address":"632 Dank Court","employer":"Ebidco","email":"jerryrush@ebidco.com","city":"Geyserville","state":"AR"}
{"index":{"_id":"757"}}
{"account_number":757,"balance":34628,"firstname":"Mccullough","lastname":"Moore","age":30,"gender":"F","address":"304 Hastings Street","employer":"Nikuda","email":"mcculloughmoore@nikuda.com","city":"Charco","state":"DC"}
{"index":{"_id":"764"}}
{"account_number":764,"balance":3728,"firstname":"Noemi","lastname":"Gill","age":30,"gender":"M","address":"427 Chester Street","employer":"Avit","email":"noemigill@avit.com","city":"Chesterfield","state":"AL"}
{"index":{"_id":"769"}}
{"account_number":769,"balance":15362,"firstname":"Francis","lastname":"Beck","age":28,"gender":"M","address":"454 Livingston Street","employer":"Furnafix","email":"francisbeck@furnafix.com","city":"Dunnavant","state":"HI"}
{"index":{"_id":"771"}}
{"account_number":771,"balance":32784,"firstname":"Jocelyn","lastname":"Boone","age":23,"gender":"M","address":"513 Division Avenue","employer":"Collaire","email":"jocelynboone@collaire.com","city":"Lisco","state":"VT"}
{"index":{"_id":"776"}}
{"account_number":776,"balance":29177,"firstname":"Duke","lastname":"Atkinson","age":24,"gender":"M","address":"520 Doscher Street","employer":"Tripsch","email":"dukeatkinson@tripsch.com","city":"Lafferty","state":"NC"}
{"index":{"_id":"783"}}
{"account_number":783,"balance":11911,"firstname":"Faith","lastname":"Cooper","age":25,"gender":"F","address":"539 Rapelye Street","employer":"Insuron","email":"faithcooper@insuron.com","city":"Jennings","state":"MN"}
{"index":{"_id":"788"}}
{"account_number":788,"balance":12473,"firstname":"Marianne","lastname":"Aguilar","age":39,"gender":"F","address":"213 Holly Street","employer":"Marqet","email":"marianneaguilar@marqet.com","city":"Alfarata","state":"HI"}
{"index":{"_id":"790"}}
{"account_number":790,"balance":29912,"firstname":"Ellis","lastname":"Sullivan","age":39,"gender":"F","address":"877 Coyle Street","employer":"Enersave","email":"ellissullivan@enersave.com","city":"Canby","state":"MS"}
{"index":{"_id":"795"}}
{"account_number":795,"balance":31450,"firstname":"Bruce","lastname":"Avila","age":34,"gender":"M","address":"865 Newkirk Placez","employer":"Plasmosis","email":"bruceavila@plasmosis.com","city":"Ada","state":"ID"}
{"index":{"_id":"803"}}
{"account_number":803,"balance":49567,"firstname":"Marissa","lastname":"Spears","age":25,"gender":"M","address":"963 Highland Avenue","employer":"Centregy","email":"marissaspears@centregy.com","city":"Bloomington","state":"MS"}
{"index":{"_id":"808"}}
{"account_number":808,"balance":11251,"firstname":"Nola","lastname":"Quinn","age":20,"gender":"M","address":"863 Wythe Place","employer":"Iplax","email":"nolaquinn@iplax.com","city":"Cuylerville","state":"NH"}
{"index":{"_id":"810"}}
{"account_number":810,"balance":10563,"firstname":"Alyssa","lastname":"Ortega","age":40,"gender":"M","address":"977 Clymer Street","employer":"Eventage","email":"alyssaortega@eventage.com","city":"Convent","state":"SC"}
{"index":{"_id":"815"}}
{"account_number":815,"balance":19336,"firstname":"Guthrie","lastname":"Morse","age":30,"gender":"M","address":"685 Vandalia Avenue","employer":"Gronk","email":"guthriemorse@gronk.com","city":"Fowlerville","state":"OR"}
{"index":{"_id":"822"}}
{"account_number":822,"balance":13024,"firstname":"Hicks","lastname":"Farrell","age":25,"gender":"M","address":"468 Middleton Street","employer":"Zolarex","email":"hicksfarrell@zolarex.com","city":"Columbus","state":"OR"}
{"index":{"_id":"827"}}
{"account_number":827,"balance":37536,"firstname":"Naomi","lastname":"Ball","age":29,"gender":"F","address":"319 Stewart Street","employer":"Isotronic","email":"naomiball@isotronic.com","city":"Trona","state":"NM"}
{"index":{"_id":"834"}}
{"account_number":834,"balance":38049,"firstname":"Sybil","lastname":"Carrillo","age":25,"gender":"M","address":"359 Baughman Place","employer":"Phuel","email":"sybilcarrillo@phuel.com","city":"Kohatk","state":"CT"}
{"index":{"_id":"839"}}
{"account_number":839,"balance":38292,"firstname":"Langley","lastname":"Neal","age":39,"gender":"F","address":"565 Newton Street","employer":"Liquidoc","email":"langleyneal@liquidoc.com","city":"Osage","state":"AL"}
{"index":{"_id":"841"}}
{"account_number":841,"balance":28291,"firstname":"Dalton","lastname":"Waters","age":21,"gender":"M","address":"859 Grand Street","employer":"Malathion","email":"daltonwaters@malathion.com","city":"Tonopah","state":"AZ"}
{"index":{"_id":"846"}}
{"account_number":846,"balance":35099,"firstname":"Maureen","lastname":"Glass","age":22,"gender":"M","address":"140 Amherst Street","employer":"Stelaecor","email":"maureenglass@stelaecor.com","city":"Cucumber","state":"IL"}
{"index":{"_id":"853"}}
{"account_number":853,"balance":38353,"firstname":"Travis","lastname":"Parks","age":40,"gender":"M","address":"930 Bay Avenue","employer":"Pyramax","email":"travisparks@pyramax.com","city":"Gadsden","state":"ND"}
{"index":{"_id":"858"}}
{"account_number":858,"balance":23194,"firstname":"Small","lastname":"Hatfield","age":36,"gender":"M","address":"593 Tennis Court","employer":"Letpro","email":"smallhatfield@letpro.com","city":"Haena","state":"KS"}
{"index":{"_id":"860"}}
{"account_number":860,"balance":23613,"firstname":"Clark","lastname":"Boyd","age":37,"gender":"M","address":"501 Rock Street","employer":"Deepends","email":"clarkboyd@deepends.com","city":"Whitewater","state":"MA"}
{"index":{"_id":"865"}}
{"account_number":865,"balance":10574,"firstname":"Cook","lastname":"Kelley","age":28,"gender":"F","address":"865 Lincoln Terrace","employer":"Quizmo","email":"cookkelley@quizmo.com","city":"Kansas","state":"KY"}
{"index":{"_id":"872"}}
{"account_number":872,"balance":26314,"firstname":"Jane","lastname":"Greer","age":36,"gender":"F","address":"717 Hewes Street","employer":"Newcube","email":"janegreer@newcube.com","city":"Delshire","state":"DE"}
{"index":{"_id":"877"}}
{"account_number":877,"balance":42879,"firstname":"Tracey","lastname":"Ruiz","age":34,"gender":"F","address":"141 Tompkins Avenue","employer":"Waab","email":"traceyruiz@waab.com","city":"Zeba","state":"NM"}
{"index":{"_id":"884"}}
{"account_number":884,"balance":29316,"firstname":"Reva","lastname":"Rosa","age":40,"gender":"M","address":"784 Greene Avenue","employer":"Urbanshee","email":"revarosa@urbanshee.com","city":"Bakersville","state":"MS"}
{"index":{"_id":"889"}}
{"account_number":889,"balance":26464,"firstname":"Fischer","lastname":"Klein","age":38,"gender":"F","address":"948 Juliana Place","employer":"Comtext","email":"fischerklein@comtext.com","city":"Jackpot","state":"PA"}
{"index":{"_id":"891"}}
{"account_number":891,"balance":34829,"firstname":"Jacobson","lastname":"Clemons","age":24,"gender":"F","address":"507 Wilson Street","employer":"Quilm","email":"jacobsonclemons@quilm.com","city":"Muir","state":"TX"}
{"index":{"_id":"896"}}
{"account_number":896,"balance":31947,"firstname":"Buckley","lastname":"Peterson","age":26,"gender":"M","address":"217 Beayer Place","employer":"Earwax","email":"buckleypeterson@earwax.com","city":"Franklin","state":"DE"}
{"index":{"_id":"904"}}
{"account_number":904,"balance":27707,"firstname":"Mendez","lastname":"Mcneil","age":26,"gender":"M","address":"431 Halsey Street","employer":"Macronaut","email":"mendezmcneil@macronaut.com","city":"Troy","state":"OK"}
{"index":{"_id":"909"}}
{"account_number":909,"balance":18421,"firstname":"Stark","lastname":"Lewis","age":36,"gender":"M","address":"409 Tilden Avenue","employer":"Frosnex","email":"starklewis@frosnex.com","city":"Axis","state":"CA"}
{"index":{"_id":"911"}}
{"account_number":911,"balance":42655,"firstname":"Annie","lastname":"Lyons","age":21,"gender":"M","address":"518 Woods Place","employer":"Enerforce","email":"annielyons@enerforce.com","city":"Stagecoach","state":"MA"}
{"index":{"_id":"916"}}
{"account_number":916,"balance":47887,"firstname":"Jarvis","lastname":"Alexander","age":40,"gender":"M","address":"406 Bergen Avenue","employer":"Equitax","email":"jarvisalexander@equitax.com","city":"Haring","state":"KY"}
{"index":{"_id":"923"}}
{"account_number":923,"balance":48466,"firstname":"Mueller","lastname":"Mckee","age":26,"gender":"M","address":"298 Ruby Street","employer":"Luxuria","email":"muellermckee@luxuria.com","city":"Coleville","state":"TN"}
{"index":{"_id":"928"}}
{"account_number":928,"balance":19611,"firstname":"Hester","lastname":"Copeland","age":22,"gender":"F","address":"425 Cropsey Avenue","employer":"Dymi","email":"hestercopeland@dymi.com","city":"Wolcott","state":"NE"}
{"index":{"_id":"930"}}
{"account_number":930,"balance":47257,"firstname":"Kinney","lastname":"Lawson","age":39,"gender":"M","address":"501 Raleigh Place","employer":"Neptide","email":"kinneylawson@neptide.com","city":"Deltaville","state":"MD"}
{"index":{"_id":"935"}}
{"account_number":935,"balance":4959,"firstname":"Flowers","lastname":"Robles","age":30,"gender":"M","address":"201 Hull Street","employer":"Xelegyl","email":"flowersrobles@xelegyl.com","city":"Rehrersburg","state":"AL"}
{"index":{"_id":"942"}}
{"account_number":942,"balance":21299,"firstname":"Hamilton","lastname":"Clayton","age":26,"gender":"M","address":"413 Debevoise Street","employer":"Architax","email":"hamiltonclayton@architax.com","city":"Terlingua","state":"NM"}
{"index":{"_id":"947"}}
{"account_number":947,"balance":22039,"firstname":"Virgie","lastname":"Garza","age":30,"gender":"M","address":"903 Matthews Court","employer":"Plasmox","email":"virgiegarza@plasmox.com","city":"Somerset","state":"WY"}
{"index":{"_id":"954"}}
{"account_number":954,"balance":49404,"firstname":"Jenna","lastname":"Martin","age":22,"gender":"M","address":"688 Hart Street","employer":"Zinca","email":"jennamartin@zinca.com","city":"Oasis","state":"MD"}
{"index":{"_id":"959"}}
{"account_number":959,"balance":34743,"firstname":"Shaffer","lastname":"Cervantes","age":40,"gender":"M","address":"931 Varick Avenue","employer":"Oceanica","email":"shaffercervantes@oceanica.com","city":"Bowie","state":"AL"}
{"index":{"_id":"961"}}
{"account_number":961,"balance":43219,"firstname":"Betsy","lastname":"Hyde","age":27,"gender":"F","address":"183 Junius Street","employer":"Tubalum","email":"betsyhyde@tubalum.com","city":"Driftwood","state":"TX"}
{"index":{"_id":"966"}}
{"account_number":966,"balance":20619,"firstname":"Susanne","lastname":"Rodriguez","age":35,"gender":"F","address":"255 Knickerbocker Avenue","employer":"Comtrek","email":"susannerodriguez@comtrek.com","city":"Trinway","state":"TX"}
{"index":{"_id":"973"}}
{"account_number":973,"balance":45756,"firstname":"Rice","lastname":"Farmer","age":31,"gender":"M","address":"476 Nassau Avenue","employer":"Photobin","email":"ricefarmer@photobin.com","city":"Suitland","state":"ME"}
{"index":{"_id":"978"}}
{"account_number":978,"balance":21459,"firstname":"Melanie","lastname":"Rojas","age":33,"gender":"M","address":"991 Java Street","employer":"Kage","email":"melanierojas@kage.com","city":"Greenock","state":"VT"}
{"index":{"_id":"980"}}
{"account_number":980,"balance":42436,"firstname":"Cash","lastname":"Collier","age":33,"gender":"F","address":"999 Sapphire Street","employer":"Ceprene","email":"cashcollier@ceprene.com","city":"Glidden","state":"AK"}
{"index":{"_id":"985"}}
{"account_number":985,"balance":20083,"firstname":"Martin","lastname":"Gardner","age":28,"gender":"F","address":"644 Fairview Place","employer":"Golistic","email":"martingardner@golistic.com","city":"Connerton","state":"NJ"}
{"index":{"_id":"992"}}
{"account_number":992,"balance":11413,"firstname":"Kristie","lastname":"Kennedy","age":33,"gender":"F","address":"750 Hudson Avenue","employer":"Ludak","email":"kristiekennedy@ludak.com","city":"Warsaw","state":"WY"}
{"index":{"_id":"997"}}
{"account_number":997,"balance":25311,"firstname":"Combs","lastname":"Frederick","age":20,"gender":"M","address":"586 Lloyd Court","employer":"Pathways","email":"combsfrederick@pathways.com","city":"Williamson","state":"CA"}
{"index":{"_id":"3"}}
{"account_number":3,"balance":44947,"firstname":"Levine","lastname":"Burks","age":26,"gender":"F","address":"328 Wilson Avenue","employer":"Amtap","email":"levineburks@amtap.com","city":"Cochranville","state":"HI"}
{"index":{"_id":"8"}}
{"account_number":8,"balance":48868,"firstname":"Jan","lastname":"Burns","age":35,"gender":"M","address":"699 Visitation Place","employer":"Glasstep","email":"janburns@glasstep.com","city":"Wakulla","state":"AZ"}
{"index":{"_id":"10"}}
{"account_number":10,"balance":46170,"firstname":"Dominique","lastname":"Park","age":37,"gender":"F","address":"100 Gatling Place","employer":"Conjurica","email":"dominiquepark@conjurica.com","city":"Omar","state":"NJ"}
{"index":{"_id":"15"}}
{"account_number":15,"balance":43456,"firstname":"Bobbie","lastname":"Sexton","age":21,"gender":"M","address":"232 Sedgwick Place","employer":"Zytrex","email":"bobbiesexton@zytrex.com","city":"Hendersonville","state":"CA"}
{"index":{"_id":"22"}}
{"account_number":22,"balance":40283,"firstname":"Barrera","lastname":"Terrell","age":23,"gender":"F","address":"292 Orange Street","employer":"Steelfab","email":"barreraterrell@steelfab.com","city":"Bynum","state":"ME"}
{"index":{"_id":"27"}}
{"account_number":27,"balance":6176,"firstname":"Meyers","lastname":"Williamson","age":26,"gender":"F","address":"675 Henderson Walk","employer":"Plexia","email":"meyerswilliamson@plexia.com","city":"Richmond","state":"AZ"}
{"index":{"_id":"34"}}
{"account_number":34,"balance":35379,"firstname":"Ellison","lastname":"Kim","age":30,"gender":"F","address":"986 Revere Place","employer":"Signity","email":"ellisonkim@signity.com","city":"Sehili","state":"IL"}
{"index":{"_id":"39"}}
{"account_number":39,"balance":38688,"firstname":"Bowers","lastname":"Mendez","age":22,"gender":"F","address":"665 Bennet Court","employer":"Farmage","email":"bowersmendez@farmage.com","city":"Duryea","state":"PA"}
{"index":{"_id":"41"}}
{"account_number":41,"balance":36060,"firstname":"Hancock","lastname":"Holden","age":20,"gender":"M","address":"625 Gaylord Drive","employer":"Poochies","email":"hancockholden@poochies.com","city":"Alamo","state":"KS"}
{"index":{"_id":"46"}}
{"account_number":46,"balance":12351,"firstname":"Karla","lastname":"Bowman","age":23,"gender":"M","address":"554 Chapel Street","employer":"Undertap","email":"karlabowman@undertap.com","city":"Sylvanite","state":"DC"}
{"index":{"_id":"53"}}
{"account_number":53,"balance":28101,"firstname":"Kathryn","lastname":"Payne","age":29,"gender":"F","address":"467 Louis Place","employer":"Katakana","email":"kathrynpayne@katakana.com","city":"Harviell","state":"SD"}
{"index":{"_id":"58"}}
{"account_number":58,"balance":31697,"firstname":"Marva","lastname":"Cannon","age":40,"gender":"M","address":"993 Highland Place","employer":"Comcubine","email":"marvacannon@comcubine.com","city":"Orviston","state":"MO"}
{"index":{"_id":"60"}}
{"account_number":60,"balance":45955,"firstname":"Maude","lastname":"Casey","age":31,"gender":"F","address":"566 Strauss Street","employer":"Quilch","email":"maudecasey@quilch.com","city":"Enlow","state":"GA"}
{"index":{"_id":"65"}}
{"account_number":65,"balance":23282,"firstname":"Leonor","lastname":"Pruitt","age":24,"gender":"M","address":"974 Terrace Place","employer":"Velos","email":"leonorpruitt@velos.com","city":"Devon","state":"WI"}
{"index":{"_id":"72"}}
{"account_number":72,"balance":9732,"firstname":"Barlow","lastname":"Rhodes","age":25,"gender":"F","address":"891 Clinton Avenue","employer":"Zialactic","email":"barlowrhodes@zialactic.com","city":"Echo","state":"TN"}
{"index":{"_id":"77"}}
{"account_number":77,"balance":5724,"firstname":"Byrd","lastname":"Conley","age":24,"gender":"F","address":"698 Belmont Avenue","employer":"Zidox","email":"byrdconley@zidox.com","city":"Rockbridge","state":"SC"}
{"index":{"_id":"84"}}
{"account_number":84,"balance":3001,"firstname":"Hutchinson","lastname":"Newton","age":34,"gender":"F","address":"553 Locust Street","employer":"Zaggles","email":"hutchinsonnewton@zaggles.com","city":"Snyderville","state":"DC"}
{"index":{"_id":"89"}}
{"account_number":89,"balance":13263,"firstname":"Mcdowell","lastname":"Bradley","age":28,"gender":"M","address":"960 Howard Alley","employer":"Grok","email":"mcdowellbradley@grok.com","city":"Toftrees","state":"TX"}
{"index":{"_id":"91"}}
{"account_number":91,"balance":29799,"firstname":"Vonda","lastname":"Galloway","age":20,"gender":"M","address":"988 Voorhies Avenue","employer":"Illumity","email":"vondagalloway@illumity.com","city":"Holcombe","state":"HI"}
{"index":{"_id":"96"}}
{"account_number":96,"balance":15933,"firstname":"Shirley","lastname":"Edwards","age":38,"gender":"M","address":"817 Caton Avenue","employer":"Equitox","email":"shirleyedwards@equitox.com","city":"Nelson","state":"MA"}
{"index":{"_id":"104"}}
{"account_number":104,"balance":32619,"firstname":"Casey","lastname":"Roth","age":29,"gender":"M","address":"963 Railroad Avenue","employer":"Hotcakes","email":"caseyroth@hotcakes.com","city":"Davenport","state":"OH"}
{"index":{"_id":"109"}}
{"account_number":109,"balance":25812,"firstname":"Gretchen","lastname":"Dawson","age":31,"gender":"M","address":"610 Bethel Loop","employer":"Tetak","email":"gretchendawson@tetak.com","city":"Hailesboro","state":"CO"}
{"index":{"_id":"111"}}
{"account_number":111,"balance":1481,"firstname":"Traci","lastname":"Allison","age":35,"gender":"M","address":"922 Bryant Street","employer":"Enjola","email":"traciallison@enjola.com","city":"Robinette","state":"OR"}
{"index":{"_id":"116"}}
{"account_number":116,"balance":21335,"firstname":"Hobbs","lastname":"Wright","age":24,"gender":"M","address":"965 Temple Court","employer":"Netbook","email":"hobbswright@netbook.com","city":"Strong","state":"CA"}
{"index":{"_id":"123"}}
{"account_number":123,"balance":3079,"firstname":"Cleo","lastname":"Beach","age":27,"gender":"F","address":"653 Haring Street","employer":"Proxsoft","email":"cleobeach@proxsoft.com","city":"Greensburg","state":"ME"}
{"index":{"_id":"128"}}
{"account_number":128,"balance":3556,"firstname":"Mack","lastname":"Bullock","age":34,"gender":"F","address":"462 Ingraham Street","employer":"Terascape","email":"mackbullock@terascape.com","city":"Eureka","state":"PA"}
{"index":{"_id":"130"}}
{"account_number":130,"balance":24171,"firstname":"Roxie","lastname":"Cantu","age":33,"gender":"M","address":"841 Catherine Street","employer":"Skybold","email":"roxiecantu@skybold.com","city":"Deputy","state":"NE"}
{"index":{"_id":"135"}}
{"account_number":135,"balance":24885,"firstname":"Stevenson","lastname":"Crosby","age":40,"gender":"F","address":"473 Boardwalk ","employer":"Accel","email":"stevensoncrosby@accel.com","city":"Norris","state":"OK"}
{"index":{"_id":"142"}}
{"account_number":142,"balance":4544,"firstname":"Vang","lastname":"Hughes","age":27,"gender":"M","address":"357 Landis Court","employer":"Bolax","email":"vanghughes@bolax.com","city":"Emerald","state":"WY"}
{"index":{"_id":"147"}}
{"account_number":147,"balance":35921,"firstname":"Charmaine","lastname":"Whitney","age":28,"gender":"F","address":"484 Seton Place","employer":"Comveyer","email":"charmainewhitney@comveyer.com","city":"Dexter","state":"DC"}
{"index":{"_id":"154"}}
{"account_number":154,"balance":40945,"firstname":"Burns","lastname":"Solis","age":31,"gender":"M","address":"274 Lorraine Street","employer":"Rodemco","email":"burnssolis@rodemco.com","city":"Ballico","state":"WI"}
{"index":{"_id":"159"}}
{"account_number":159,"balance":1696,"firstname":"Alvarez","lastname":"Mack","age":22,"gender":"F","address":"897 Manor Court","employer":"Snorus","email":"alvarezmack@snorus.com","city":"Rosedale","state":"CA"}
{"index":{"_id":"161"}}
{"account_number":161,"balance":4659,"firstname":"Doreen","lastname":"Randall","age":37,"gender":"F","address":"178 Court Street","employer":"Calcula","email":"doreenrandall@calcula.com","city":"Belmont","state":"TX"}
{"index":{"_id":"166"}}
{"account_number":166,"balance":33847,"firstname":"Rutledge","lastname":"Rivas","age":23,"gender":"M","address":"352 Verona Street","employer":"Virxo","email":"rutledgerivas@virxo.com","city":"Brandermill","state":"NE"}
{"index":{"_id":"173"}}
{"account_number":173,"balance":5989,"firstname":"Whitley","lastname":"Blevins","age":32,"gender":"M","address":"127 Brooklyn Avenue","employer":"Pawnagra","email":"whitleyblevins@pawnagra.com","city":"Rodanthe","state":"ND"}
{"index":{"_id":"178"}}
{"account_number":178,"balance":36735,"firstname":"Clements","lastname":"Finley","age":39,"gender":"F","address":"270 Story Court","employer":"Imaginart","email":"clementsfinley@imaginart.com","city":"Lookingglass","state":"MN"}
{"index":{"_id":"180"}}
{"account_number":180,"balance":34236,"firstname":"Ursula","lastname":"Goodman","age":32,"gender":"F","address":"414 Clinton Street","employer":"Earthmark","email":"ursulagoodman@earthmark.com","city":"Rote","state":"AR"}
{"index":{"_id":"185"}}
{"account_number":185,"balance":43532,"firstname":"Laurel","lastname":"Cline","age":40,"gender":"M","address":"788 Fenimore Street","employer":"Prismatic","email":"laurelcline@prismatic.com","city":"Frank","state":"UT"}
{"index":{"_id":"192"}}
{"account_number":192,"balance":23508,"firstname":"Ramsey","lastname":"Carr","age":31,"gender":"F","address":"209 Williamsburg Street","employer":"Strezzo","email":"ramseycarr@strezzo.com","city":"Grapeview","state":"NM"}
{"index":{"_id":"197"}}
{"account_number":197,"balance":17246,"firstname":"Sweet","lastname":"Sanders","age":33,"gender":"F","address":"712 Homecrest Court","employer":"Isosure","email":"sweetsanders@isosure.com","city":"Sheatown","state":"VT"}
{"index":{"_id":"200"}}
{"account_number":200,"balance":26210,"firstname":"Teri","lastname":"Hester","age":39,"gender":"M","address":"653 Abbey Court","employer":"Electonic","email":"terihester@electonic.com","city":"Martell","state":"MD"}
{"index":{"_id":"205"}}
{"account_number":205,"balance":45493,"firstname":"Johnson","lastname":"Chang","age":28,"gender":"F","address":"331 John Street","employer":"Gleamink","email":"johnsonchang@gleamink.com","city":"Sultana","state":"KS"}
{"index":{"_id":"212"}}
{"account_number":212,"balance":10299,"firstname":"Marisol","lastname":"Fischer","age":39,"gender":"M","address":"362 Prince Street","employer":"Autograte","email":"marisolfischer@autograte.com","city":"Oley","state":"SC"}
{"index":{"_id":"217"}}
{"account_number":217,"balance":33730,"firstname":"Sally","lastname":"Mccoy","age":38,"gender":"F","address":"854 Corbin Place","employer":"Omnigog","email":"sallymccoy@omnigog.com","city":"Escondida","state":"FL"}
{"index":{"_id":"224"}}
{"account_number":224,"balance":42708,"firstname":"Billie","lastname":"Nixon","age":28,"gender":"F","address":"241 Kaufman Place","employer":"Xanide","email":"billienixon@xanide.com","city":"Chapin","state":"NY"}
{"index":{"_id":"229"}}
{"account_number":229,"balance":2740,"firstname":"Jana","lastname":"Hensley","age":30,"gender":"M","address":"176 Erasmus Street","employer":"Isotrack","email":"janahensley@isotrack.com","city":"Caledonia","state":"ME"}
{"index":{"_id":"231"}}
{"account_number":231,"balance":46180,"firstname":"Essie","lastname":"Clarke","age":34,"gender":"F","address":"308 Harbor Lane","employer":"Pharmacon","email":"essieclarke@pharmacon.com","city":"Fillmore","state":"MS"}
{"index":{"_id":"236"}}
{"account_number":236,"balance":41200,"firstname":"Suzanne","lastname":"Bird","age":39,"gender":"F","address":"219 Luquer Street","employer":"Imant","email":"suzannebird@imant.com","city":"Bainbridge","state":"NY"}
{"index":{"_id":"243"}}
{"account_number":243,"balance":29902,"firstname":"Evangelina","lastname":"Perez","age":20,"gender":"M","address":"787 Joval Court","employer":"Keengen","email":"evangelinaperez@keengen.com","city":"Mulberry","state":"SD"}
{"index":{"_id":"248"}}
{"account_number":248,"balance":49989,"firstname":"West","lastname":"England","age":36,"gender":"M","address":"717 Hendrickson Place","employer":"Obliq","email":"westengland@obliq.com","city":"Maury","state":"WA"}
{"index":{"_id":"250"}}
{"account_number":250,"balance":27893,"firstname":"Earlene","lastname":"Ellis","age":39,"gender":"F","address":"512 Bay Street","employer":"Codact","email":"earleneellis@codact.com","city":"Sunwest","state":"GA"}
{"index":{"_id":"255"}}
{"account_number":255,"balance":49339,"firstname":"Iva","lastname":"Rivers","age":38,"gender":"M","address":"470 Rost Place","employer":"Mantrix","email":"ivarivers@mantrix.com","city":"Disautel","state":"MD"}
{"index":{"_id":"262"}}
{"account_number":262,"balance":30289,"firstname":"Tameka","lastname":"Levine","age":36,"gender":"F","address":"815 Atlantic Avenue","employer":"Acium","email":"tamekalevine@acium.com","city":"Winchester","state":"SD"}
{"index":{"_id":"267"}}
{"account_number":267,"balance":42753,"firstname":"Weeks","lastname":"Castillo","age":21,"gender":"F","address":"526 Holt Court","employer":"Talendula","email":"weekscastillo@talendula.com","city":"Washington","state":"NV"}
{"index":{"_id":"274"}}
{"account_number":274,"balance":12104,"firstname":"Frieda","lastname":"House","age":33,"gender":"F","address":"171 Banker Street","employer":"Quonk","email":"friedahouse@quonk.com","city":"Aberdeen","state":"NJ"}
{"index":{"_id":"279"}}
{"account_number":279,"balance":15904,"firstname":"Chapman","lastname":"Hart","age":32,"gender":"F","address":"902 Bliss Terrace","employer":"Kongene","email":"chapmanhart@kongene.com","city":"Bradenville","state":"NJ"}
{"index":{"_id":"281"}}
{"account_number":281,"balance":39830,"firstname":"Bean","lastname":"Aguirre","age":20,"gender":"F","address":"133 Pilling Street","employer":"Amril","email":"beanaguirre@amril.com","city":"Waterview","state":"TX"}
{"index":{"_id":"286"}}
{"account_number":286,"balance":39063,"firstname":"Rosetta","lastname":"Turner","age":35,"gender":"M","address":"169 Jefferson Avenue","employer":"Spacewax","email":"rosettaturner@spacewax.com","city":"Stewart","state":"MO"}
{"index":{"_id":"293"}}
{"account_number":293,"balance":29867,"firstname":"Cruz","lastname":"Carver","age":28,"gender":"F","address":"465 Boerum Place","employer":"Vitricomp","email":"cruzcarver@vitricomp.com","city":"Crayne","state":"CO"}
{"index":{"_id":"298"}}
{"account_number":298,"balance":34334,"firstname":"Bullock","lastname":"Marsh","age":20,"gender":"M","address":"589 Virginia Place","employer":"Renovize","email":"bullockmarsh@renovize.com","city":"Coinjock","state":"UT"}
{"index":{"_id":"301"}}
{"account_number":301,"balance":16782,"firstname":"Minerva","lastname":"Graham","age":35,"gender":"M","address":"532 Harrison Place","employer":"Sureplex","email":"minervagraham@sureplex.com","city":"Belleview","state":"GA"}
{"index":{"_id":"306"}}
{"account_number":306,"balance":2171,"firstname":"Hensley","lastname":"Hardin","age":40,"gender":"M","address":"196 Maujer Street","employer":"Neocent","email":"hensleyhardin@neocent.com","city":"Reinerton","state":"HI"}
{"index":{"_id":"313"}}
{"account_number":313,"balance":34108,"firstname":"Alston","lastname":"Henderson","age":36,"gender":"F","address":"132 Prescott Place","employer":"Prosure","email":"alstonhenderson@prosure.com","city":"Worton","state":"IA"}
{"index":{"_id":"318"}}
{"account_number":318,"balance":8512,"firstname":"Nichole","lastname":"Pearson","age":34,"gender":"F","address":"656 Lacon Court","employer":"Yurture","email":"nicholepearson@yurture.com","city":"Juarez","state":"MO"}
{"index":{"_id":"320"}}
{"account_number":320,"balance":34521,"firstname":"Patti","lastname":"Brennan","age":37,"gender":"F","address":"870 Degraw Street","employer":"Cognicode","email":"pattibrennan@cognicode.com","city":"Torboy","state":"FL"}
{"index":{"_id":"325"}}
{"account_number":325,"balance":1956,"firstname":"Magdalena","lastname":"Simmons","age":25,"gender":"F","address":"681 Townsend Street","employer":"Geekosis","email":"magdalenasimmons@geekosis.com","city":"Sterling","state":"CA"}
{"index":{"_id":"332"}}
{"account_number":332,"balance":37770,"firstname":"Shepherd","lastname":"Davenport","age":28,"gender":"F","address":"586 Montague Terrace","employer":"Ecraze","email":"shepherddavenport@ecraze.com","city":"Accoville","state":"NM"}
{"index":{"_id":"337"}}
{"account_number":337,"balance":43432,"firstname":"Monroe","lastname":"Stafford","age":37,"gender":"F","address":"183 Seigel Street","employer":"Centuria","email":"monroestafford@centuria.com","city":"Camino","state":"DE"}
{"index":{"_id":"344"}}
{"account_number":344,"balance":42654,"firstname":"Sasha","lastname":"Baxter","age":35,"gender":"F","address":"700 Bedford Place","employer":"Callflex","email":"sashabaxter@callflex.com","city":"Campo","state":"MI"}
{"index":{"_id":"349"}}
{"account_number":349,"balance":24180,"firstname":"Allison","lastname":"Fitzpatrick","age":22,"gender":"F","address":"913 Arlington Avenue","employer":"Veraq","email":"allisonfitzpatrick@veraq.com","city":"Marbury","state":"TX"}
{"index":{"_id":"351"}}
{"account_number":351,"balance":47089,"firstname":"Hendrix","lastname":"Stephens","age":29,"gender":"M","address":"181 Beaver Street","employer":"Recrisys","email":"hendrixstephens@recrisys.com","city":"Denio","state":"OR"}
{"index":{"_id":"356"}}
{"account_number":356,"balance":34540,"firstname":"Lourdes","lastname":"Valdez","age":20,"gender":"F","address":"700 Anchorage Place","employer":"Interloo","email":"lourdesvaldez@interloo.com","city":"Goldfield","state":"OK"}
{"index":{"_id":"363"}}
{"account_number":363,"balance":34007,"firstname":"Peggy","lastname":"Bright","age":21,"gender":"M","address":"613 Engert Avenue","employer":"Inventure","email":"peggybright@inventure.com","city":"Chautauqua","state":"ME"}
{"index":{"_id":"368"}}
{"account_number":368,"balance":23535,"firstname":"Hooper","lastname":"Tyson","age":39,"gender":"M","address":"892 Taaffe Place","employer":"Zaggle","email":"hoopertyson@zaggle.com","city":"Nutrioso","state":"ME"}
{"index":{"_id":"370"}}
{"account_number":370,"balance":28499,"firstname":"Oneill","lastname":"Carney","age":25,"gender":"F","address":"773 Adelphi Street","employer":"Bedder","email":"oneillcarney@bedder.com","city":"Yorklyn","state":"FL"}
{"index":{"_id":"375"}}
{"account_number":375,"balance":23860,"firstname":"Phoebe","lastname":"Patton","age":25,"gender":"M","address":"564 Hale Avenue","employer":"Xoggle","email":"phoebepatton@xoggle.com","city":"Brule","state":"NM"}
{"index":{"_id":"382"}}
{"account_number":382,"balance":42061,"firstname":"Finley","lastname":"Singleton","age":37,"gender":"F","address":"407 Clay Street","employer":"Quarex","email":"finleysingleton@quarex.com","city":"Bedias","state":"LA"}
{"index":{"_id":"387"}}
{"account_number":387,"balance":35916,"firstname":"April","lastname":"Hill","age":29,"gender":"M","address":"818 Bayard Street","employer":"Kengen","email":"aprilhill@kengen.com","city":"Chloride","state":"NC"}
{"index":{"_id":"394"}}
{"account_number":394,"balance":6121,"firstname":"Lorrie","lastname":"Nunez","age":38,"gender":"M","address":"221 Ralph Avenue","employer":"Bullzone","email":"lorrienunez@bullzone.com","city":"Longoria","state":"ID"}
{"index":{"_id":"399"}}
{"account_number":399,"balance":32587,"firstname":"Carmela","lastname":"Franks","age":23,"gender":"M","address":"617 Dewey Place","employer":"Zensure","email":"carmelafranks@zensure.com","city":"Sanders","state":"DC"}
{"index":{"_id":"402"}}
{"account_number":402,"balance":1282,"firstname":"Pacheco","lastname":"Rosales","age":32,"gender":"M","address":"538 Pershing Loop","employer":"Circum","email":"pachecorosales@circum.com","city":"Elbert","state":"ID"}
{"index":{"_id":"407"}}
{"account_number":407,"balance":36417,"firstname":"Gilda","lastname":"Jacobson","age":29,"gender":"F","address":"883 Loring Avenue","employer":"Comveyor","email":"gildajacobson@comveyor.com","city":"Topaz","state":"NH"}
{"index":{"_id":"414"}}
{"account_number":414,"balance":17506,"firstname":"Conway","lastname":"Daugherty","age":37,"gender":"F","address":"643 Kermit Place","employer":"Lyria","email":"conwaydaugherty@lyria.com","city":"Vaughn","state":"NV"}
{"index":{"_id":"419"}}
{"account_number":419,"balance":34847,"firstname":"Helen","lastname":"Montoya","age":29,"gender":"F","address":"736 Kingsland Avenue","employer":"Hairport","email":"helenmontoya@hairport.com","city":"Edinburg","state":"NE"}
{"index":{"_id":"421"}}
{"account_number":421,"balance":46868,"firstname":"Tamika","lastname":"Mccall","age":27,"gender":"F","address":"764 Bragg Court","employer":"Eventix","email":"tamikamccall@eventix.com","city":"Tivoli","state":"RI"}
{"index":{"_id":"426"}}
{"account_number":426,"balance":4499,"firstname":"Julie","lastname":"Parsons","age":31,"gender":"M","address":"768 Keap Street","employer":"Goko","email":"julieparsons@goko.com","city":"Coldiron","state":"VA"}
{"index":{"_id":"433"}}
{"account_number":433,"balance":19266,"firstname":"Wilkinson","lastname":"Flowers","age":39,"gender":"M","address":"154 Douglass Street","employer":"Xsports","email":"wilkinsonflowers@xsports.com","city":"Coultervillle","state":"MN"}
{"index":{"_id":"438"}}
{"account_number":438,"balance":16367,"firstname":"Walter","lastname":"Velez","age":27,"gender":"F","address":"931 Farragut Road","employer":"Virva","email":"waltervelez@virva.com","city":"Tyro","state":"WV"}
{"index":{"_id":"440"}}
{"account_number":440,"balance":41590,"firstname":"Ray","lastname":"Wiley","age":31,"gender":"F","address":"102 Barwell Terrace","employer":"Polaria","email":"raywiley@polaria.com","city":"Hardyville","state":"IA"}
{"index":{"_id":"445"}}
{"account_number":445,"balance":41178,"firstname":"Rodriguez","lastname":"Macias","age":34,"gender":"M","address":"164 Boerum Street","employer":"Xylar","email":"rodriguezmacias@xylar.com","city":"Riner","state":"AL"}
{"index":{"_id":"452"}}
{"account_number":452,"balance":3589,"firstname":"Blackwell","lastname":"Delaney","age":39,"gender":"F","address":"443 Sackett Street","employer":"Imkan","email":"blackwelldelaney@imkan.com","city":"Gasquet","state":"DC"}
{"index":{"_id":"457"}}
{"account_number":457,"balance":14057,"firstname":"Bush","lastname":"Gordon","age":34,"gender":"M","address":"975 Dakota Place","employer":"Softmicro","email":"bushgordon@softmicro.com","city":"Chemung","state":"PA"}
{"index":{"_id":"464"}}
{"account_number":464,"balance":20504,"firstname":"Cobb","lastname":"Humphrey","age":21,"gender":"M","address":"823 Sunnyside Avenue","employer":"Apexia","email":"cobbhumphrey@apexia.com","city":"Wintersburg","state":"NY"}
{"index":{"_id":"469"}}
{"account_number":469,"balance":26509,"firstname":"Marci","lastname":"Shepherd","age":26,"gender":"M","address":"565 Hall Street","employer":"Shadease","email":"marcishepherd@shadease.com","city":"Springhill","state":"IL"}
{"index":{"_id":"471"}}
{"account_number":471,"balance":7629,"firstname":"Juana","lastname":"Silva","age":36,"gender":"M","address":"249 Amity Street","employer":"Artworlds","email":"juanasilva@artworlds.com","city":"Norfolk","state":"TX"}
{"index":{"_id":"476"}}
{"account_number":476,"balance":33386,"firstname":"Silva","lastname":"Marks","age":31,"gender":"F","address":"183 Eldert Street","employer":"Medifax","email":"silvamarks@medifax.com","city":"Hachita","state":"RI"}
{"index":{"_id":"483"}}
{"account_number":483,"balance":6344,"firstname":"Kelley","lastname":"Harper","age":29,"gender":"M","address":"758 Preston Court","employer":"Xyqag","email":"kelleyharper@xyqag.com","city":"Healy","state":"IA"}
{"index":{"_id":"488"}}
{"account_number":488,"balance":6289,"firstname":"Wilma","lastname":"Hopkins","age":38,"gender":"M","address":"428 Lee Avenue","employer":"Entality","email":"wilmahopkins@entality.com","city":"Englevale","state":"WI"}
{"index":{"_id":"490"}}
{"account_number":490,"balance":1447,"firstname":"Strong","lastname":"Hendrix","age":26,"gender":"F","address":"134 Beach Place","employer":"Duoflex","email":"stronghendrix@duoflex.com","city":"Allentown","state":"ND"}
{"index":{"_id":"495"}}
{"account_number":495,"balance":13478,"firstname":"Abigail","lastname":"Nichols","age":40,"gender":"F","address":"887 President Street","employer":"Enquility","email":"abigailnichols@enquility.com","city":"Bagtown","state":"NM"}
{"index":{"_id":"503"}}
{"account_number":503,"balance":42649,"firstname":"Leta","lastname":"Stout","age":39,"gender":"F","address":"518 Bowery Street","employer":"Pivitol","email":"letastout@pivitol.com","city":"Boonville","state":"ND"}
{"index":{"_id":"508"}}
{"account_number":508,"balance":41300,"firstname":"Lawrence","lastname":"Mathews","age":27,"gender":"F","address":"987 Rose Street","employer":"Deviltoe","email":"lawrencemathews@deviltoe.com","city":"Woodburn","state":"FL"}
{"index":{"_id":"510"}}
{"account_number":510,"balance":48504,"firstname":"Petty","lastname":"Sykes","age":28,"gender":"M","address":"566 Village Road","employer":"Nebulean","email":"pettysykes@nebulean.com","city":"Wedgewood","state":"MO"}
{"index":{"_id":"515"}}
{"account_number":515,"balance":18531,"firstname":"Lott","lastname":"Keller","age":27,"gender":"M","address":"827 Miami Court","employer":"Translink","email":"lottkeller@translink.com","city":"Gila","state":"TX"}
{"index":{"_id":"522"}}
{"account_number":522,"balance":19879,"firstname":"Faulkner","lastname":"Garrett","age":29,"gender":"F","address":"396 Grove Place","employer":"Pigzart","email":"faulknergarrett@pigzart.com","city":"Felt","state":"AR"}
{"index":{"_id":"527"}}
{"account_number":527,"balance":2028,"firstname":"Carver","lastname":"Peters","age":35,"gender":"M","address":"816 Victor Road","employer":"Housedown","email":"carverpeters@housedown.com","city":"Nadine","state":"MD"}
{"index":{"_id":"534"}}
{"account_number":534,"balance":20470,"firstname":"Cristina","lastname":"Russo","age":25,"gender":"F","address":"500 Highlawn Avenue","employer":"Cyclonica","email":"cristinarusso@cyclonica.com","city":"Gorst","state":"KS"}
{"index":{"_id":"539"}}
{"account_number":539,"balance":24560,"firstname":"Tami","lastname":"Maddox","age":23,"gender":"F","address":"741 Pineapple Street","employer":"Accidency","email":"tamimaddox@accidency.com","city":"Kennedyville","state":"OH"}
{"index":{"_id":"541"}}
{"account_number":541,"balance":42915,"firstname":"Logan","lastname":"Burke","age":32,"gender":"M","address":"904 Clarendon Road","employer":"Overplex","email":"loganburke@overplex.com","city":"Johnsonburg","state":"OH"}
{"index":{"_id":"546"}}
{"account_number":546,"balance":43242,"firstname":"Bernice","lastname":"Sims","age":33,"gender":"M","address":"382 Columbia Street","employer":"Verbus","email":"bernicesims@verbus.com","city":"Sena","state":"KY"}
{"index":{"_id":"553"}}
{"account_number":553,"balance":28390,"firstname":"Aimee","lastname":"Cohen","age":28,"gender":"M","address":"396 Lafayette Avenue","employer":"Eplode","email":"aimeecohen@eplode.com","city":"Thatcher","state":"NJ"}
{"index":{"_id":"558"}}
{"account_number":558,"balance":8922,"firstname":"Horne","lastname":"Valenzuela","age":20,"gender":"F","address":"979 Kensington Street","employer":"Isoternia","email":"hornevalenzuela@isoternia.com","city":"Greenbush","state":"NC"}
{"index":{"_id":"560"}}
{"account_number":560,"balance":24514,"firstname":"Felecia","lastname":"Oneill","age":26,"gender":"M","address":"995 Autumn Avenue","employer":"Mediot","email":"feleciaoneill@mediot.com","city":"Joppa","state":"IN"}
{"index":{"_id":"565"}}
{"account_number":565,"balance":15197,"firstname":"Taylor","lastname":"Ingram","age":37,"gender":"F","address":"113 Will Place","employer":"Lyrichord","email":"tayloringram@lyrichord.com","city":"Collins","state":"ME"}
{"index":{"_id":"572"}}
{"account_number":572,"balance":49355,"firstname":"Therese","lastname":"Espinoza","age":20,"gender":"M","address":"994 Chester Court","employer":"Gonkle","email":"thereseespinoza@gonkle.com","city":"Hayes","state":"UT"}
{"index":{"_id":"577"}}
{"account_number":577,"balance":21398,"firstname":"Gilbert","lastname":"Serrano","age":38,"gender":"F","address":"294 Troutman Street","employer":"Senmao","email":"gilbertserrano@senmao.com","city":"Greer","state":"MT"}
{"index":{"_id":"584"}}
{"account_number":584,"balance":5346,"firstname":"Pearson","lastname":"Bryant","age":40,"gender":"F","address":"971 Heyward Street","employer":"Anacho","email":"pearsonbryant@anacho.com","city":"Bluffview","state":"MN"}
{"index":{"_id":"589"}}
{"account_number":589,"balance":33260,"firstname":"Ericka","lastname":"Cote","age":39,"gender":"F","address":"425 Bath Avenue","employer":"Venoflex","email":"erickacote@venoflex.com","city":"Blue","state":"CT"}
{"index":{"_id":"591"}}
{"account_number":591,"balance":48997,"firstname":"Rivers","lastname":"Macdonald","age":34,"gender":"F","address":"919 Johnson Street","employer":"Ziore","email":"riversmacdonald@ziore.com","city":"Townsend","state":"IL"}
{"index":{"_id":"596"}}
{"account_number":596,"balance":4063,"firstname":"Letitia","lastname":"Walker","age":26,"gender":"F","address":"963 Vanderveer Place","employer":"Zizzle","email":"letitiawalker@zizzle.com","city":"Rossmore","state":"ID"}
{"index":{"_id":"604"}}
{"account_number":604,"balance":10675,"firstname":"Isabel","lastname":"Gilliam","age":23,"gender":"M","address":"854 Broadway ","employer":"Zenthall","email":"isabelgilliam@zenthall.com","city":"Ventress","state":"WI"}
{"index":{"_id":"609"}}
{"account_number":609,"balance":28586,"firstname":"Montgomery","lastname":"Washington","age":30,"gender":"M","address":"169 Schroeders Avenue","employer":"Kongle","email":"montgomerywashington@kongle.com","city":"Croom","state":"AZ"}
{"index":{"_id":"611"}}
{"account_number":611,"balance":17528,"firstname":"Katherine","lastname":"Prince","age":33,"gender":"F","address":"705 Elm Avenue","employer":"Zillacon","email":"katherineprince@zillacon.com","city":"Rew","state":"MI"}
{"index":{"_id":"616"}}
{"account_number":616,"balance":25276,"firstname":"Jessie","lastname":"Mayer","age":35,"gender":"F","address":"683 Chester Avenue","employer":"Emtrak","email":"jessiemayer@emtrak.com","city":"Marysville","state":"HI"}
{"index":{"_id":"623"}}
{"account_number":623,"balance":20514,"firstname":"Rose","lastname":"Combs","age":32,"gender":"F","address":"312 Grimes Road","employer":"Aquamate","email":"rosecombs@aquamate.com","city":"Fostoria","state":"OH"}
{"index":{"_id":"628"}}
{"account_number":628,"balance":42736,"firstname":"Buckner","lastname":"Chen","age":37,"gender":"M","address":"863 Rugby Road","employer":"Jamnation","email":"bucknerchen@jamnation.com","city":"Camas","state":"TX"}
{"index":{"_id":"630"}}
{"account_number":630,"balance":46060,"firstname":"Leanne","lastname":"Jones","age":31,"gender":"M","address":"451 Bayview Avenue","employer":"Wazzu","email":"leannejones@wazzu.com","city":"Kylertown","state":"OK"}
{"index":{"_id":"635"}}
{"account_number":635,"balance":44705,"firstname":"Norman","lastname":"Gilmore","age":33,"gender":"M","address":"330 Gates Avenue","employer":"Comfirm","email":"normangilmore@comfirm.com","city":"Riceville","state":"TN"}
{"index":{"_id":"642"}}
{"account_number":642,"balance":32852,"firstname":"Reyna","lastname":"Harris","age":35,"gender":"M","address":"305 Powell Street","employer":"Bedlam","email":"reynaharris@bedlam.com","city":"Florence","state":"KS"}
{"index":{"_id":"647"}}
{"account_number":647,"balance":10147,"firstname":"Annabelle","lastname":"Velazquez","age":30,"gender":"M","address":"299 Kensington Walk","employer":"Sealoud","email":"annabellevelazquez@sealoud.com","city":"Soudan","state":"ME"}
{"index":{"_id":"654"}}
{"account_number":654,"balance":38695,"firstname":"Armstrong","lastname":"Frazier","age":25,"gender":"M","address":"899 Seeley Street","employer":"Zensor","email":"armstrongfrazier@zensor.com","city":"Cherokee","state":"UT"}
{"index":{"_id":"659"}}
{"account_number":659,"balance":29648,"firstname":"Dorsey","lastname":"Sosa","age":40,"gender":"M","address":"270 Aberdeen Street","employer":"Daycore","email":"dorseysosa@daycore.com","city":"Chamberino","state":"SC"}
{"index":{"_id":"661"}}
{"account_number":661,"balance":3679,"firstname":"Joanne","lastname":"Spencer","age":39,"gender":"F","address":"910 Montauk Avenue","employer":"Visalia","email":"joannespencer@visalia.com","city":"Valmy","state":"NH"}
{"index":{"_id":"666"}}
{"account_number":666,"balance":13880,"firstname":"Mcguire","lastname":"Lloyd","age":40,"gender":"F","address":"658 Just Court","employer":"Centrexin","email":"mcguirelloyd@centrexin.com","city":"Warren","state":"MT"}
{"index":{"_id":"673"}}
{"account_number":673,"balance":11303,"firstname":"Mcdaniel","lastname":"Harrell","age":33,"gender":"M","address":"565 Montgomery Place","employer":"Eyeris","email":"mcdanielharrell@eyeris.com","city":"Garnet","state":"NV"}
{"index":{"_id":"678"}}
{"account_number":678,"balance":43663,"firstname":"Ruby","lastname":"Shaffer","age":28,"gender":"M","address":"350 Clark Street","employer":"Comtrail","email":"rubyshaffer@comtrail.com","city":"Aurora","state":"MA"}
{"index":{"_id":"680"}}
{"account_number":680,"balance":31561,"firstname":"Melton","lastname":"Camacho","age":32,"gender":"F","address":"771 Montana Place","employer":"Insuresys","email":"meltoncamacho@insuresys.com","city":"Sparkill","state":"IN"}
{"index":{"_id":"685"}}
{"account_number":685,"balance":22249,"firstname":"Yesenia","lastname":"Rowland","age":24,"gender":"F","address":"193 Dekalb Avenue","employer":"Coriander","email":"yeseniarowland@coriander.com","city":"Lupton","state":"NC"}
{"index":{"_id":"692"}}
{"account_number":692,"balance":10435,"firstname":"Haney","lastname":"Barlow","age":21,"gender":"F","address":"267 Lenox Road","employer":"Egypto","email":"haneybarlow@egypto.com","city":"Detroit","state":"IN"}
{"index":{"_id":"697"}}
{"account_number":697,"balance":48745,"firstname":"Mallory","lastname":"Emerson","age":24,"gender":"F","address":"318 Dunne Court","employer":"Exoplode","email":"malloryemerson@exoplode.com","city":"Montura","state":"LA"}
{"index":{"_id":"700"}}
{"account_number":700,"balance":19164,"firstname":"Patel","lastname":"Durham","age":21,"gender":"F","address":"440 King Street","employer":"Icology","email":"pateldurham@icology.com","city":"Mammoth","state":"IL"}
{"index":{"_id":"705"}}
{"account_number":705,"balance":28415,"firstname":"Krystal","lastname":"Cross","age":22,"gender":"M","address":"604 Drew Street","employer":"Tubesys","email":"krystalcross@tubesys.com","city":"Dalton","state":"MO"}
{"index":{"_id":"712"}}
{"account_number":712,"balance":12459,"firstname":"Butler","lastname":"Alston","age":37,"gender":"M","address":"486 Hemlock Street","employer":"Quordate","email":"butleralston@quordate.com","city":"Verdi","state":"MS"}
{"index":{"_id":"717"}}
{"account_number":717,"balance":29270,"firstname":"Erickson","lastname":"Mcdonald","age":31,"gender":"M","address":"873 Franklin Street","employer":"Exotechno","email":"ericksonmcdonald@exotechno.com","city":"Jessie","state":"MS"}
{"index":{"_id":"724"}}
{"account_number":724,"balance":12548,"firstname":"Hopper","lastname":"Peck","age":31,"gender":"M","address":"849 Hendrickson Street","employer":"Uxmox","email":"hopperpeck@uxmox.com","city":"Faxon","state":"UT"}
{"index":{"_id":"729"}}
{"account_number":729,"balance":41812,"firstname":"Katy","lastname":"Rivera","age":36,"gender":"F","address":"791 Olive Street","employer":"Blurrybus","email":"katyrivera@blurrybus.com","city":"Innsbrook","state":"MI"}
{"index":{"_id":"731"}}
{"account_number":731,"balance":4994,"firstname":"Lorene","lastname":"Weiss","age":35,"gender":"M","address":"990 Ocean Court","employer":"Comvoy","email":"loreneweiss@comvoy.com","city":"Lavalette","state":"WI"}
{"index":{"_id":"736"}}
{"account_number":736,"balance":28677,"firstname":"Rogers","lastname":"Mcmahon","age":21,"gender":"F","address":"423 Cameron Court","employer":"Brainclip","email":"rogersmcmahon@brainclip.com","city":"Saddlebrooke","state":"FL"}
{"index":{"_id":"743"}}
{"account_number":743,"balance":14077,"firstname":"Susana","lastname":"Moody","age":23,"gender":"M","address":"842 Fountain Avenue","employer":"Bitrex","email":"susanamoody@bitrex.com","city":"Temperanceville","state":"TN"}
{"index":{"_id":"748"}}
{"account_number":748,"balance":38060,"firstname":"Ford","lastname":"Branch","age":25,"gender":"M","address":"926 Cypress Avenue","employer":"Buzzness","email":"fordbranch@buzzness.com","city":"Beason","state":"DC"}
{"index":{"_id":"750"}}
{"account_number":750,"balance":40481,"firstname":"Cherie","lastname":"Brooks","age":20,"gender":"F","address":"601 Woodhull Street","employer":"Kaggle","email":"cheriebrooks@kaggle.com","city":"Groton","state":"MA"}
{"index":{"_id":"755"}}
{"account_number":755,"balance":43878,"firstname":"Bartlett","lastname":"Conway","age":22,"gender":"M","address":"453 Times Placez","employer":"Konnect","email":"bartlettconway@konnect.com","city":"Belva","state":"VT"}
{"index":{"_id":"762"}}
{"account_number":762,"balance":10291,"firstname":"Amanda","lastname":"Head","age":20,"gender":"F","address":"990 Ocean Parkway","employer":"Zentury","email":"amandahead@zentury.com","city":"Hegins","state":"AR"}
{"index":{"_id":"767"}}
{"account_number":767,"balance":26220,"firstname":"Anthony","lastname":"Sutton","age":27,"gender":"F","address":"179 Fayette Street","employer":"Xiix","email":"anthonysutton@xiix.com","city":"Iberia","state":"TN"}
{"index":{"_id":"774"}}
{"account_number":774,"balance":35287,"firstname":"Lynnette","lastname":"Alvarez","age":38,"gender":"F","address":"991 Brightwater Avenue","employer":"Gink","email":"lynnettealvarez@gink.com","city":"Leola","state":"NC"}
{"index":{"_id":"779"}}
{"account_number":779,"balance":40983,"firstname":"Maggie","lastname":"Pace","age":32,"gender":"F","address":"104 Harbor Court","employer":"Bulljuice","email":"maggiepace@bulljuice.com","city":"Floris","state":"MA"}
{"index":{"_id":"781"}}
{"account_number":781,"balance":29961,"firstname":"Sanford","lastname":"Mullen","age":26,"gender":"F","address":"879 Dover Street","employer":"Zanity","email":"sanfordmullen@zanity.com","city":"Martinez","state":"TX"}
{"index":{"_id":"786"}}
{"account_number":786,"balance":3024,"firstname":"Rene","lastname":"Vang","age":33,"gender":"M","address":"506 Randolph Street","employer":"Isopop","email":"renevang@isopop.com","city":"Vienna","state":"NJ"}
{"index":{"_id":"793"}}
{"account_number":793,"balance":16911,"firstname":"Alford","lastname":"Compton","age":36,"gender":"M","address":"186 Veronica Place","employer":"Zyple","email":"alfordcompton@zyple.com","city":"Sugartown","state":"AK"}
{"index":{"_id":"798"}}
{"account_number":798,"balance":3165,"firstname":"Catherine","lastname":"Ward","age":30,"gender":"F","address":"325 Burnett Street","employer":"Dreamia","email":"catherineward@dreamia.com","city":"Glenbrook","state":"SD"}
{"index":{"_id":"801"}}
{"account_number":801,"balance":14954,"firstname":"Molly","lastname":"Maldonado","age":37,"gender":"M","address":"518 Maple Avenue","employer":"Straloy","email":"mollymaldonado@straloy.com","city":"Hebron","state":"WI"}
{"index":{"_id":"806"}}
{"account_number":806,"balance":36492,"firstname":"Carson","lastname":"Riddle","age":31,"gender":"M","address":"984 Lois Avenue","employer":"Terrago","email":"carsonriddle@terrago.com","city":"Leland","state":"MN"}
{"index":{"_id":"813"}}
{"account_number":813,"balance":30833,"firstname":"Ebony","lastname":"Bishop","age":20,"gender":"M","address":"487 Ridge Court","employer":"Optique","email":"ebonybishop@optique.com","city":"Fairmount","state":"WA"}
{"index":{"_id":"818"}}
{"account_number":818,"balance":24433,"firstname":"Espinoza","lastname":"Petersen","age":26,"gender":"M","address":"641 Glenwood Road","employer":"Futurity","email":"espinozapetersen@futurity.com","city":"Floriston","state":"MD"}
{"index":{"_id":"820"}}
{"account_number":820,"balance":1011,"firstname":"Shepard","lastname":"Ramsey","age":24,"gender":"F","address":"806 Village Court","employer":"Mantro","email":"shepardramsey@mantro.com","city":"Tibbie","state":"NV"}
{"index":{"_id":"825"}}
{"account_number":825,"balance":49000,"firstname":"Terra","lastname":"Witt","age":21,"gender":"F","address":"590 Conway Street","employer":"Insectus","email":"terrawitt@insectus.com","city":"Forbestown","state":"AR"}
{"index":{"_id":"832"}}
{"account_number":832,"balance":8582,"firstname":"Laura","lastname":"Gibbs","age":39,"gender":"F","address":"511 Osborn Street","employer":"Corepan","email":"lauragibbs@corepan.com","city":"Worcester","state":"KS"}
{"index":{"_id":"837"}}
{"account_number":837,"balance":14485,"firstname":"Amy","lastname":"Villarreal","age":35,"gender":"M","address":"381 Stillwell Place","employer":"Fleetmix","email":"amyvillarreal@fleetmix.com","city":"Sanford","state":"IA"}
{"index":{"_id":"844"}}
{"account_number":844,"balance":26840,"firstname":"Jill","lastname":"David","age":31,"gender":"M","address":"346 Legion Street","employer":"Zytrax","email":"jilldavid@zytrax.com","city":"Saticoy","state":"SC"}
{"index":{"_id":"849"}}
{"account_number":849,"balance":16200,"firstname":"Barry","lastname":"Chapman","age":26,"gender":"M","address":"931 Dekoven Court","employer":"Darwinium","email":"barrychapman@darwinium.com","city":"Whitestone","state":"WY"}
{"index":{"_id":"851"}}
{"account_number":851,"balance":22026,"firstname":"Henderson","lastname":"Price","age":33,"gender":"F","address":"530 Hausman Street","employer":"Plutorque","email":"hendersonprice@plutorque.com","city":"Brutus","state":"RI"}
{"index":{"_id":"856"}}
{"account_number":856,"balance":27583,"firstname":"Alissa","lastname":"Knox","age":25,"gender":"M","address":"258 Empire Boulevard","employer":"Geologix","email":"alissaknox@geologix.com","city":"Hartsville/Hartley","state":"MN"}
{"index":{"_id":"863"}}
{"account_number":863,"balance":23165,"firstname":"Melendez","lastname":"Fernandez","age":40,"gender":"M","address":"661 Johnson Avenue","employer":"Vixo","email":"melendezfernandez@vixo.com","city":"Farmers","state":"IL"}
{"index":{"_id":"868"}}
{"account_number":868,"balance":27624,"firstname":"Polly","lastname":"Barron","age":22,"gender":"M","address":"129 Frank Court","employer":"Geofarm","email":"pollybarron@geofarm.com","city":"Loyalhanna","state":"ND"}
{"index":{"_id":"870"}}
{"account_number":870,"balance":43882,"firstname":"Goff","lastname":"Phelps","age":21,"gender":"M","address":"164 Montague Street","employer":"Digigen","email":"goffphelps@digigen.com","city":"Weedville","state":"IL"}
{"index":{"_id":"875"}}
{"account_number":875,"balance":19655,"firstname":"Mercer","lastname":"Pratt","age":24,"gender":"M","address":"608 Perry Place","employer":"Twiggery","email":"mercerpratt@twiggery.com","city":"Eggertsville","state":"MO"}
{"index":{"_id":"882"}}
{"account_number":882,"balance":10895,"firstname":"Mari","lastname":"Landry","age":39,"gender":"M","address":"963 Gerald Court","employer":"Kenegy","email":"marilandry@kenegy.com","city":"Lithium","state":"NC"}
{"index":{"_id":"887"}}
{"account_number":887,"balance":31772,"firstname":"Eunice","lastname":"Watts","age":36,"gender":"F","address":"707 Stuyvesant Avenue","employer":"Memora","email":"eunicewatts@memora.com","city":"Westwood","state":"TN"}
{"index":{"_id":"894"}}
{"account_number":894,"balance":1031,"firstname":"Tyler","lastname":"Fitzgerald","age":32,"gender":"M","address":"787 Meserole Street","employer":"Jetsilk","email":"tylerfitzgerald@jetsilk.com","city":"Woodlands","state":"WV"}
{"index":{"_id":"899"}}
{"account_number":899,"balance":32953,"firstname":"Carney","lastname":"Callahan","age":23,"gender":"M","address":"724 Kimball Street","employer":"Mangelica","email":"carneycallahan@mangelica.com","city":"Tecolotito","state":"MT"}
{"index":{"_id":"902"}}
{"account_number":902,"balance":13345,"firstname":"Hallie","lastname":"Jarvis","age":23,"gender":"F","address":"237 Duryea Court","employer":"Anixang","email":"halliejarvis@anixang.com","city":"Boykin","state":"IN"}
{"index":{"_id":"907"}}
{"account_number":907,"balance":12961,"firstname":"Ingram","lastname":"William","age":36,"gender":"M","address":"826 Overbaugh Place","employer":"Genmex","email":"ingramwilliam@genmex.com","city":"Kimmell","state":"AK"}
{"index":{"_id":"914"}}
{"account_number":914,"balance":7120,"firstname":"Esther","lastname":"Bean","age":32,"gender":"F","address":"583 Macon Street","employer":"Applica","email":"estherbean@applica.com","city":"Homeworth","state":"MN"}
{"index":{"_id":"919"}}
{"account_number":919,"balance":39655,"firstname":"Shauna","lastname":"Hanson","age":27,"gender":"M","address":"557 Hart Place","employer":"Exospace","email":"shaunahanson@exospace.com","city":"Outlook","state":"LA"}
{"index":{"_id":"921"}}
{"account_number":921,"balance":49119,"firstname":"Barbara","lastname":"Wade","age":29,"gender":"M","address":"687 Hoyts Lane","employer":"Roughies","email":"barbarawade@roughies.com","city":"Sattley","state":"CO"}
{"index":{"_id":"926"}}
{"account_number":926,"balance":49433,"firstname":"Welch","lastname":"Mcgowan","age":21,"gender":"M","address":"833 Quincy Street","employer":"Atomica","email":"welchmcgowan@atomica.com","city":"Hampstead","state":"VT"}
{"index":{"_id":"933"}}
{"account_number":933,"balance":18071,"firstname":"Tabitha","lastname":"Cole","age":21,"gender":"F","address":"916 Rogers Avenue","employer":"Eclipto","email":"tabithacole@eclipto.com","city":"Lawrence","state":"TX"}
{"index":{"_id":"938"}}
{"account_number":938,"balance":9597,"firstname":"Sharron","lastname":"Santos","age":40,"gender":"F","address":"215 Matthews Place","employer":"Zenco","email":"sharronsantos@zenco.com","city":"Wattsville","state":"VT"}
{"index":{"_id":"940"}}
{"account_number":940,"balance":23285,"firstname":"Melinda","lastname":"Mendoza","age":38,"gender":"M","address":"806 Kossuth Place","employer":"Kneedles","email":"melindamendoza@kneedles.com","city":"Coaldale","state":"OK"}
{"index":{"_id":"945"}}
{"account_number":945,"balance":23085,"firstname":"Hansen","lastname":"Hebert","age":33,"gender":"F","address":"287 Conduit Boulevard","employer":"Capscreen","email":"hansenhebert@capscreen.com","city":"Taycheedah","state":"AK"}
{"index":{"_id":"952"}}
{"account_number":952,"balance":21430,"firstname":"Angelique","lastname":"Weeks","age":33,"gender":"M","address":"659 Reeve Place","employer":"Exodoc","email":"angeliqueweeks@exodoc.com","city":"Turpin","state":"MD"}
{"index":{"_id":"957"}}
{"account_number":957,"balance":11373,"firstname":"Michael","lastname":"Giles","age":31,"gender":"M","address":"668 Court Square","employer":"Yogasm","email":"michaelgiles@yogasm.com","city":"Rosburg","state":"WV"}
{"index":{"_id":"964"}}
{"account_number":964,"balance":26154,"firstname":"Elena","lastname":"Waller","age":34,"gender":"F","address":"618 Crystal Street","employer":"Insurety","email":"elenawaller@insurety.com","city":"Gallina","state":"NY"}
{"index":{"_id":"969"}}
{"account_number":969,"balance":22214,"firstname":"Briggs","lastname":"Lynn","age":30,"gender":"M","address":"952 Lester Court","employer":"Quinex","email":"briggslynn@quinex.com","city":"Roland","state":"ID"}
{"index":{"_id":"971"}}
{"account_number":971,"balance":22772,"firstname":"Gabrielle","lastname":"Reilly","age":32,"gender":"F","address":"964 Tudor Terrace","employer":"Blanet","email":"gabriellereilly@blanet.com","city":"Falmouth","state":"AL"}
{"index":{"_id":"976"}}
{"account_number":976,"balance":31707,"firstname":"Mullen","lastname":"Tanner","age":26,"gender":"M","address":"711 Whitney Avenue","employer":"Pulze","email":"mullentanner@pulze.com","city":"Mooresburg","state":"MA"}
{"index":{"_id":"983"}}
{"account_number":983,"balance":47205,"firstname":"Mattie","lastname":"Eaton","age":24,"gender":"F","address":"418 Allen Avenue","employer":"Trasola","email":"mattieeaton@trasola.com","city":"Dupuyer","state":"NJ"}
{"index":{"_id":"988"}}
{"account_number":988,"balance":17803,"firstname":"Lucy","lastname":"Castro","age":34,"gender":"F","address":"425 Fleet Walk","employer":"Geekfarm","email":"lucycastro@geekfarm.com","city":"Mulino","state":"VA"}
{"index":{"_id":"990"}}
{"account_number":990,"balance":44456,"firstname":"Kelly","lastname":"Steele","age":35,"gender":"M","address":"809 Hoyt Street","employer":"Eschoir","email":"kellysteele@eschoir.com","city":"Stewartville","state":"ID"}
{"index":{"_id":"995"}}
{"account_number":995,"balance":21153,"firstname":"Phelps","lastname":"Parrish","age":25,"gender":"M","address":"666 Miller Place","employer":"Pearlessa","email":"phelpsparrish@pearlessa.com","city":"Brecon","state":"ME"}
5、进阶检索
1、SearchAPI ES支持两种基本方式检索; (a)通过REST request uri 发送搜索参数 (uri +检索参数); (b)通过REST request body 来发送它们(uri+请求体);
(1)检索信息
(a)一切检索从_search开始

(b)uri+请求体进行检索

2、Query DSL
(1)基本语法格式
Elasticsearch 提供了一个可以执行查询的 Json 风格的 DSL(domain-specific language 领域特定语言)。这个被称为 Query DSL。该查询语言非常全面,
并且刚开始的时候感觉有点复杂,真正学好它的方法是从一些基础的示例开始的
(a)一个查询语句 的典型结构

(b)如果是针对某个字段,那么它的结构如下:


(2)返回部分字段


(3)match【匹配查询】
(a)基本类型(非字符串),精确匹配

(b)字符串,全文检索

(c)字符换,多个单词(分词+全文检索)

(4)match_phrase【短语匹配】

文本字段的匹配,使用keyword,匹配的条件就是要显示字段的全部值,要进行精确匹配的。
match_phrase是做短语匹配,只要文本中包含匹配条件,就能匹配到。
(5)multi_match【多字段匹配】

(6)bool【复合查询】


(b)should:应该达到 should 列举的条件,如果达到会增加相关文档的评分,并不会改变查询的结果。如果 query 中只有 should 且只有一种匹配规则,那么 should 的条件就会被作为默认匹配条件而去改变查询结果

(c)must_not 必须不是指定的情况

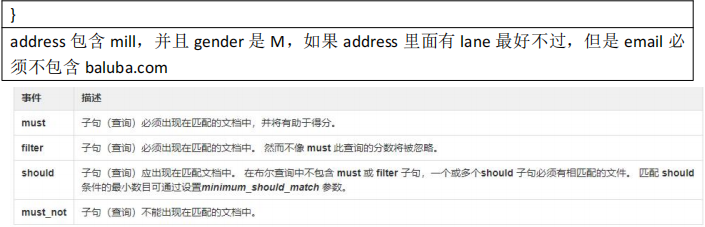
(7)filter【结果过滤】

(8)term
和 match 一样。匹配某个属性的值。全文检索字段用 match,其他非 text 字段匹配用 term。
不要使用term来进行文本字段查询
es默认存储text值时用分词分析,所以要搜索text值,使用match
字段.keyword:要一一匹配到
match_phrase:子串包含即可

(9)aggregations(执行聚合)


运行结果:
{
"took" : 274,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAvg" : {
"value" : 34.0
},
"group_by_state" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 38,
"doc_count" : 2
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 32,
"doc_count" : 1
}
]
}
}
}
(b)复杂:按照年龄聚合,并且请求这些年龄段的这些人的平均薪资

(c)复杂:查出所有年龄分布,并且这些年龄段中 M 的平均薪资和 F 的平均薪资以及这个年龄段的总体平均薪资



3、Mappig
映射定义文档如何被存储检索的
(1)字段类型

(2) 映射

(a)查看 mapping 信息
GET bank/_mapping
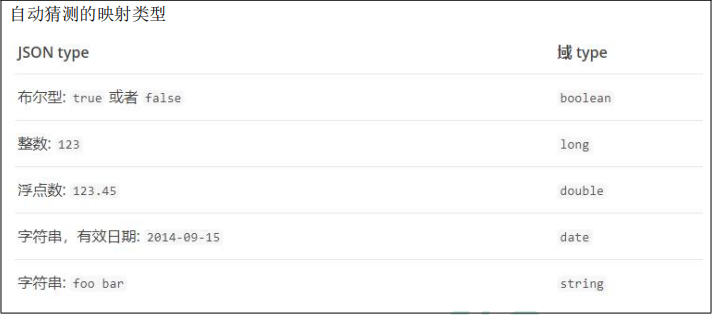
(3)新版本改变

1、创建映射


输出:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my_index"
}
查看映射 GET /my_index
{
"my_index" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"email" : {
"type" : "keyword"
},
"name" : {
"type" : "text"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1639723434557",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "O71P-B5WRa6z9YkMLt3vMg",
"version" : {
"created" : "7040299"
},
"provided_name" : "my_index"
}
}
}
}
2、添加新的字段映射

输出:
{
"acknowledged" : true
}
注意:这里的 “index”: false,表明新增的字段不能被检索,只是一个冗余字段。
3、更新映射
对于已经存在的映射字段,我们不能更新。更新必须创建新的索引进行数据迁移
4、数据迁移
先创建出 new_twitter 的正确映射。然后使用如下方式进行数据迁移



4、分词
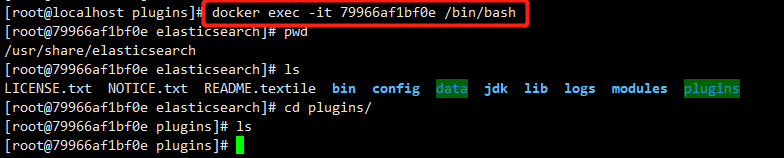

(b)下载 ik 分词器
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip

注意:
(1)这一步可以使用wget命令下载,也可以直接下载下来使用xshell命令上传
(2)关于wget和unzip命令找不到的问题,查看 谷粒商城分布式基础(二)—— 环境搭建(虚拟机 & JDK & Maven & docker & mysql & redis & vue) 中 “1、安装 Linux 虚拟机” 的 第13点
我们还可以进入es的容器中,可以看到映射对应的文件目录里面也可以看到

(c)解压下载文件

最后,记得删除掉原下载的压缩包

(d)设置权限
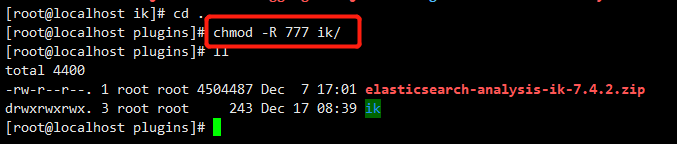
(e)确认是否安装好了分词器

(f)重启 es

(2)测试分词器

{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "中",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "国",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "人",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}

{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}

{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
}
]
}
(3)自定义词库
注意:请先按照 谷粒商城分布式高级(一)—— 环境搭建(高级篇补充)(ElasticSearch) 中的 “2、Nginx” 安装好nginx
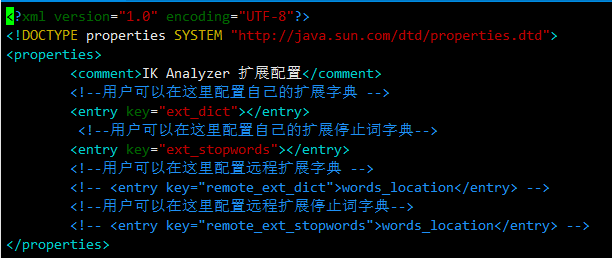
修改后的xml
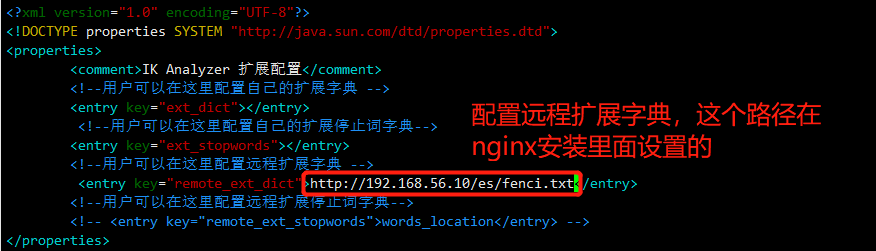
(b)然后重启 es 服务,重启 nginx

查看是否启动成功:
http://192.168.56.10:9200/
http://192.168.56.10:5601/app/kibana
(c)在 kibana 中测试分词效果
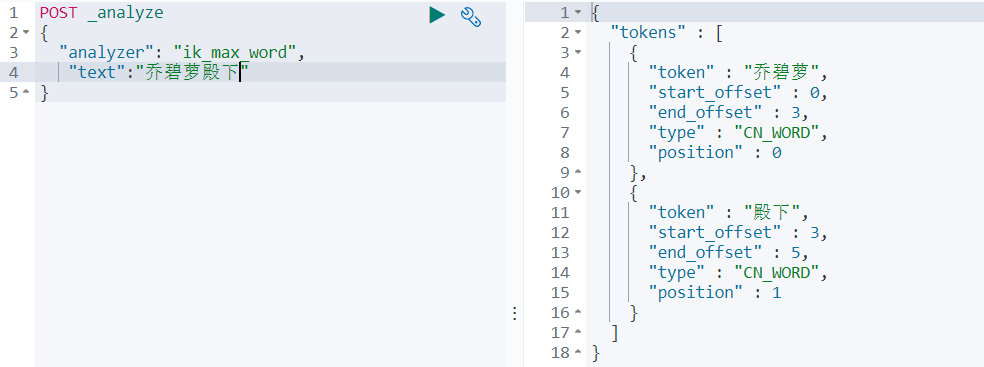
6、Elasticsearch-Rest-Client


最终选择 Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client)
1、SpringBoot 整合 ElasticSearch
创建检索服务 gulimall-search
(1)New Module,选择Spring Initiializr

选择 Web——Spring Web
(2)我们修改一下pom.xml,版本环境保持一致
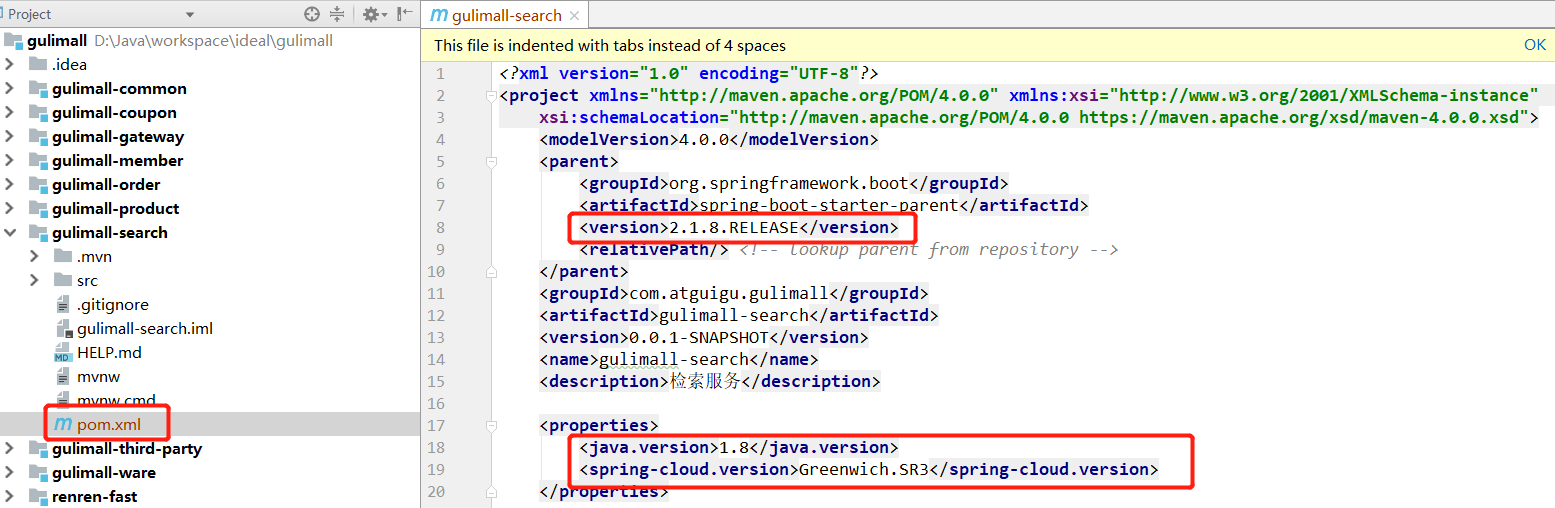
(3)引入公共依赖 gulimall-common
gulimll-common中已经引入了服务的注册发现和配置中心的依赖包
<dependency>
<groupId>com.atguigu.gulimall</groupId>
<artifactId>gulimall-common</artifactId>
<version>0.0.1-SNAPSHOT</version>
<exclusions>
<exclusion>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
</exclusion>
</exclusions>
</dependency>
(4)导入 es 的依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
在spring-boot-dependencies中所依赖的ES版本位6.8.5,要改掉
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Greenwich.SR3</spring-cloud.version>
<elasticsearch.version>7.4.2</elasticsearch.version>
</properties>

(5)配置注册中心
(a)修改application.yml

(b)启用服务的注册/发现
(6)添加 es 配置类
package com.atguigu.gulimall.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.SpringBootConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 1、导入依赖
* 2、编写配置,给容器中注入一个RestHighLevelClient
* 3、参考API
*/
@Configuration
public class GulimallElasticSearchConfig {
@Bean
public RestHighLevelClient esRestClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.56.10", 9200, "http")));
return client;
}
}
(7)单元测试获取 client对象
package com.atguigu.gulimall.search;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
@RunWith(SpringRunner.class)
@SpringBootTest
public class GulimallSearchApplicationTests {
@Resource
private RestHighLevelClient client;
@Test
public void contextLoads() {
System.out.println("客户端"+client);
}
}
运行结果:

2、测试
请求测试项,比如es添加了安全访问规则,访问es需要添加一个安全头,就可以通过requestOptions设置
官方建议把requestOptions创建成单实例
package com.atguigu.gulimall.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.SpringBootConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 1、导入依赖
* 2、编写配置,给容器中注入一个RestHighLevelClient
* 3、参考API
*/
@Configuration
public class GulimallElasticSearchConfig {
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient esRestClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.56.10", 9200, "http")));
return client;
}
}
(1)测试保存数据
保存方式分为同步和异步,异步方式多了个listener回调
/**
* 测试存储数据到es
*/
@Test
public void indexData() throws IOException {
//设置索引
IndexRequest indexRequest = new IndexRequest("users");
indexRequest.id("1");//数据的id
User user = new User();
user.setUserName("张三");
user.setAge(20);
user.setGender("男");
String jsonString = JSON.toJSONString(user);
//设置要保存的内容,指定数据和类型
indexRequest.source(jsonString, XContentType.JSON);
//执行创建索引和保存数据
IndexResponse index = client.index(indexRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
System.out.println(index);
}
@Data
class User{
private String userName;
private String gender;
private Integer age;
}
运行结果:

查看kibana
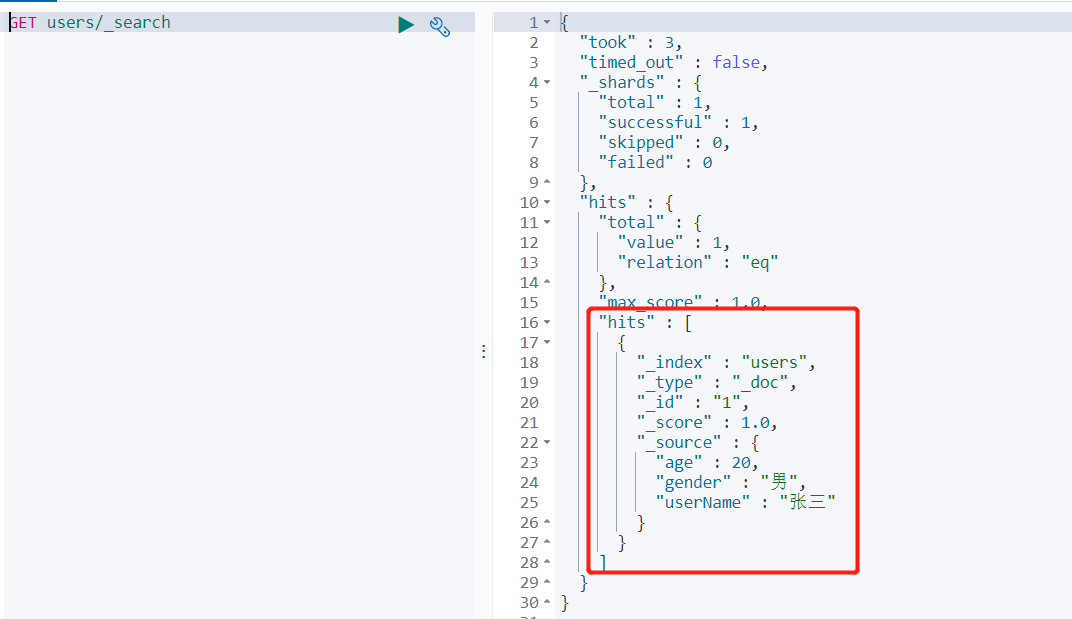
(2) 测试获取数据
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-search.html
@Test
public void find() throws IOException{
//1 创建检索请求
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("bank");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 构造检索条件
//sourceBuilder.query();
//sourceBuilder.from();
//sourceBuilder.size();
//sourceBuilder.aggregation();
sourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
System.out.println(sourceBuilder.toString());
searchRequest.source(sourceBuilder);
// 2 执行检索
SearchResponse response = client.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
// 3 分析响应结果
System.out.println(response.toString());
}
查询结果:
{"query":{"match":{"address":{"query":"mill","operator":"OR","prefix_length":0,"max_expansions":50,"fuzzy_transpositions":true,"lenient":false,"zero_terms_query":"NONE","auto_generate_synonyms_phrase_query":true,"boost":1.0}}}}
{"took":11,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":4,"relation":"eq"},"max_score":5.4032025,"hits":[{"_index":"bank","_type":"account","_id":"970","_score":5.4032025,"_source":{"account_number":970,"balance":19648,"firstname":"Forbes","lastname":"Wallace","age":28,"gender":"M","address":"990 Mill Road","employer":"Pheast","email":"forbeswallace@pheast.com","city":"Lopezo","state":"AK"}},{"_index":"bank","_type":"account","_id":"136","_score":5.4032025,"_source":{"account_number":136,"balance":45801,"firstname":"Winnie","lastname":"Holland","age":38,"gender":"M","address":"198 Mill Lane","employer":"Neteria","email":"winnieholland@neteria.com","city":"Urie","state":"IL"}},{"_index":"bank","_type":"account","_id":"345","_score":5.4032025,"_source":{"account_number":345,"balance":9812,"firstname":"Parker","lastname":"Hines","age":38,"gender":"M","address":"715 Mill Avenue","employer":"Baluba","email":"parkerhines@baluba.com","city":"Blackgum","state":"KY"}},{"_index":"bank","_type":"account","_id":"472","_score":5.4032025,"_source":{"account_number":472,"balance":25571,"firstname":"Lee","lastname":"Long","age":32,"gender":"F","address":"288 Mill Street","employer":"Comverges","email":"leelong@comverges.com","city":"Movico","state":"MT"}}]}}
@Test
public void find() throws IOException{
//1 创建检索请求
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("bank");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 构造检索条件
//sourceBuilder.query();
//sourceBuilder.from();
//sourceBuilder.size();
//sourceBuilder.aggregation();
sourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
//AggregationBuilders工具类构建AggregationBuilder
// 构建第一个聚合条件:按照年龄的值分布
TermsAggregationBuilder agg1 = AggregationBuilders.terms("agg1").field("age").size(10);// 聚合名称
// 参数为AggregationBuilder
sourceBuilder.aggregation(agg1);
// 构建第二个聚合条件:平均薪资
AvgAggregationBuilder agg2 = AggregationBuilders.avg("agg2").field("balance");
sourceBuilder.aggregation(agg2);
System.out.println("检索条件"+sourceBuilder.toString());
searchRequest.source(sourceBuilder);
// 2 执行检索
SearchResponse response = client.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
// 3 分析响应结果
System.out.println(response.toString());
}
运行结果:
检索条件{"query":{"match":{"address":{"query":"mill","operator":"OR","prefix_length":0,"max_expansions":50,"fuzzy_transpositions":true,"lenient":false,"zero_terms_query":"NONE","auto_generate_synonyms_phrase_query":true,"boost":1.0}}},"aggregations":{"agg1":{"terms":{"field":"age","size":10,"min_doc_count":1,"shard_min_doc_count":0,"show_term_doc_count_error":false,"order":[{"_count":"desc"},{"_key":"asc"}]}},"agg2":{"avg":{"field":"balance"}}}}
{"took":5,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":4,"relation":"eq"},"max_score":5.4032025,"hits":[{"_index":"bank","_type":"account","_id":"970","_score":5.4032025,"_source":{"account_number":970,"balance":19648,"firstname":"Forbes","lastname":"Wallace","age":28,"gender":"M","address":"990 Mill Road","employer":"Pheast","email":"forbeswallace@pheast.com","city":"Lopezo","state":"AK"}},{"_index":"bank","_type":"account","_id":"136","_score":5.4032025,"_source":{"account_number":136,"balance":45801,"firstname":"Winnie","lastname":"Holland","age":38,"gender":"M","address":"198 Mill Lane","employer":"Neteria","email":"winnieholland@neteria.com","city":"Urie","state":"IL"}},{"_index":"bank","_type":"account","_id":"345","_score":5.4032025,"_source":{"account_number":345,"balance":9812,"firstname":"Parker","lastname":"Hines","age":38,"gender":"M","address":"715 Mill Avenue","employer":"Baluba","email":"parkerhines@baluba.com","city":"Blackgum","state":"KY"}},{"_index":"bank","_type":"account","_id":"472","_score":5.4032025,"_source":{"account_number":472,"balance":25571,"firstname":"Lee","lastname":"Long","age":32,"gender":"F","address":"288 Mill Street","employer":"Comverges","email":"leelong@comverges.com","city":"Movico","state":"MT"}}]},"aggregations":{"avg#agg2":{"value":25208.0},"lterms#agg1":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":38,"doc_count":2},{"key":28,"doc_count":1},{"key":32,"doc_count":1}]}}}
(3)把检索结果封装为java bean
@Test
public void find() throws IOException{
//1 创建检索请求
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("bank");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 构造检索条件
//sourceBuilder.query();
//sourceBuilder.from();
//sourceBuilder.size();
//sourceBuilder.aggregation();
sourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
//AggregationBuilders工具类构建AggregationBuilder
// 构建第一个聚合条件:按照年龄的值分布
TermsAggregationBuilder agg1 = AggregationBuilders.terms("agg1").field("age").size(10);// 聚合名称
// 参数为AggregationBuilder
sourceBuilder.aggregation(agg1);
// 构建第二个聚合条件:平均薪资
AvgAggregationBuilder agg2 = AggregationBuilders.avg("agg2").field("balance");
sourceBuilder.aggregation(agg2);
//System.out.println("检索条件"+sourceBuilder.toString());
searchRequest.source(sourceBuilder);
// 2 执行检索
SearchResponse response = client.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
// 3 分析响应结果
//System.out.println(response.toString());
//Map map = JSON.parseObject(response.toString(), Map.class);
//3.1 获取所有查到的数据
SearchHits hits = response.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits){
hit.getId();hit.getType();hit.getIndex();
String sourceAsString = hit.getSourceAsString();
Account account = JSON.parseObject(sourceAsString, Account.class);
System.out.println("account:"+account);
}
}
@Data
static class Account{
private int account_number;
private int balance;
private String firstname;
private String lastname;
private int age;
private String gender;
private String address;
private String employer;
private String email;
private String city;
private String state;
}
运行结果:
account:GulimallSearchApplicationTests.Account(account_number=970, balance=19648, firstname=Forbes, lastname=Wallace, age=28, gender=M, address=990 Mill Road, employer=Pheast, email=forbeswallace@pheast.com, city=Lopezo, state=AK)
account:GulimallSearchApplicationTests.Account(account_number=136, balance=45801, firstname=Winnie, lastname=Holland, age=38, gender=M, address=198 Mill Lane, employer=Neteria, email=winnieholland@neteria.com, city=Urie, state=IL)
account:GulimallSearchApplicationTests.Account(account_number=345, balance=9812, firstname=Parker, lastname=Hines, age=38, gender=M, address=715 Mill Avenue, employer=Baluba, email=parkerhines@baluba.com, city=Blackgum, state=KY)
account:GulimallSearchApplicationTests.Account(account_number=472, balance=25571, firstname=Lee, lastname=Long, age=32, gender=F, address=288 Mill Street, employer=Comverges, email=leelong@comverges.com, city=Movico, state=MT)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号