Hadoop+微服务 环境搭建笔记
准备工作
相关软件和资料
链接:https://pan.baidu.com/s/1CPGqJSH2e6rnPvfXGYo8ow
提取码:pe9c
目标:VMware(虚拟机)安装
双击开始安装

下一步
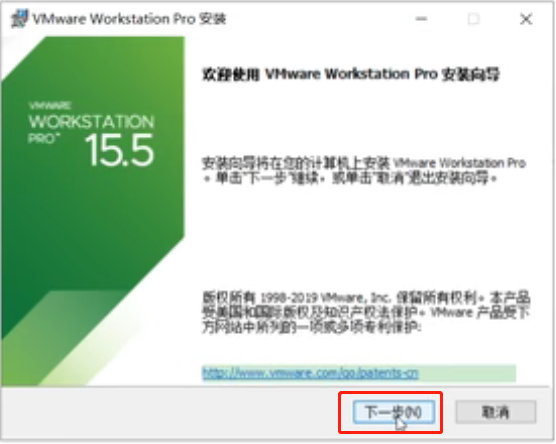
接受许可,下一步
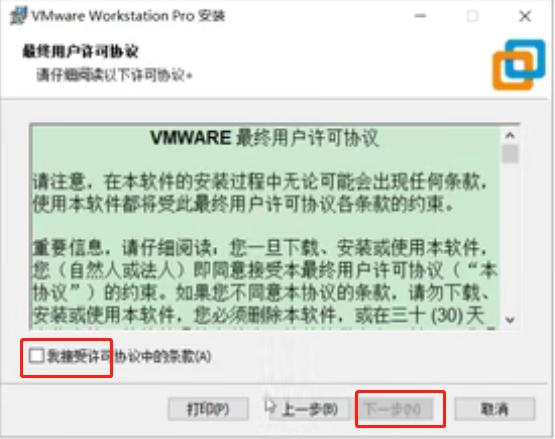
修改路径,下一步
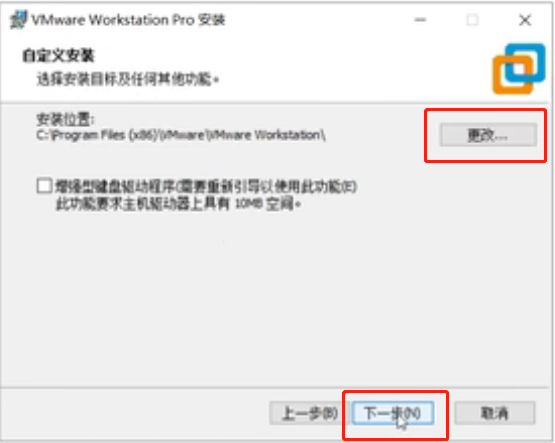
取消勾选,下一步

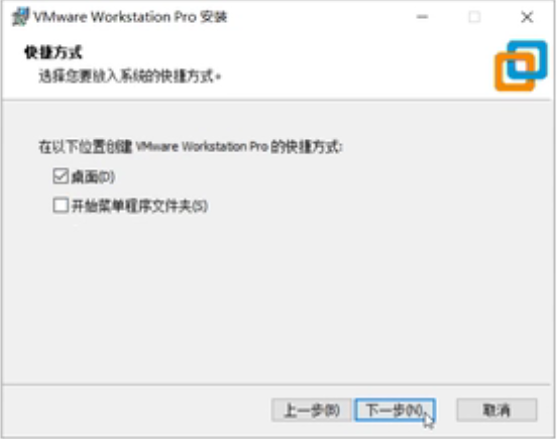
下一步
安装
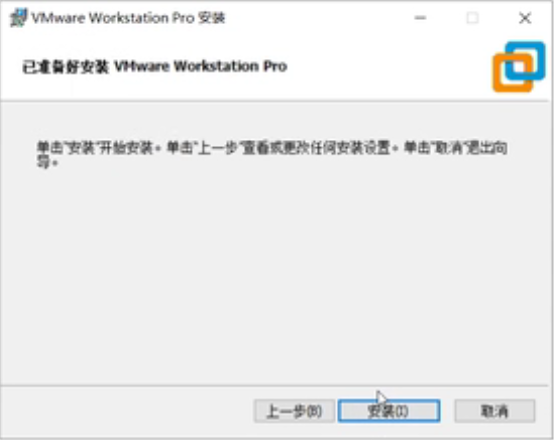
安装中....
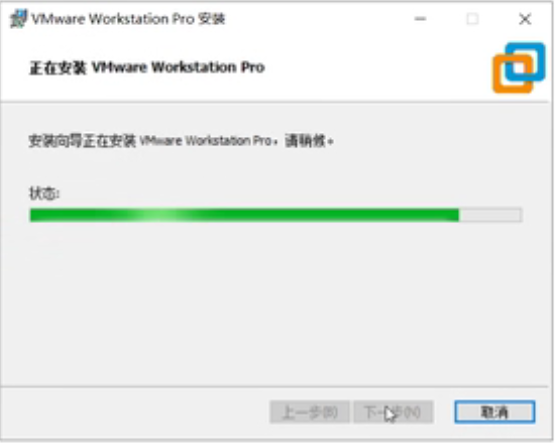
安装完成
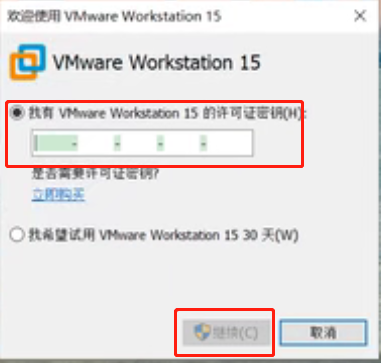
双击打开

输入秘钥,点击“继续”,密钥找度娘一大把
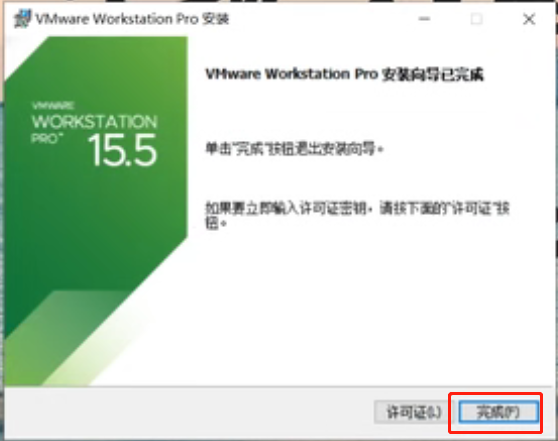
完成
安装完毕
目标:Centos7.5软硬件安装
注意内容:
1、在安装系统之前需要检查自己虚拟机的bios的虚拟化是否打开(大部分的电脑都是打开的,大家可以先尝试直接安装,如果出现错误再去调试,没有出错就不用管了)
以下是查看虚拟机bios是否开启的方式
(1)Windows10
CPU,性能查看
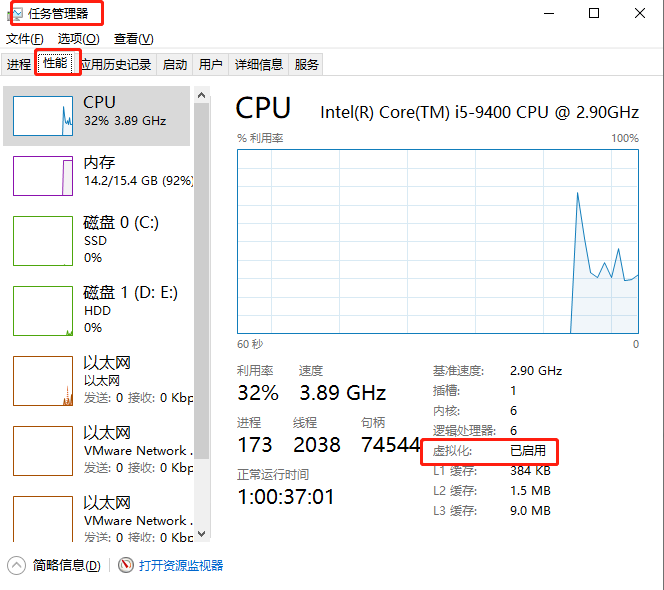
(2)Windows7里面看不到(得到bios里面看)
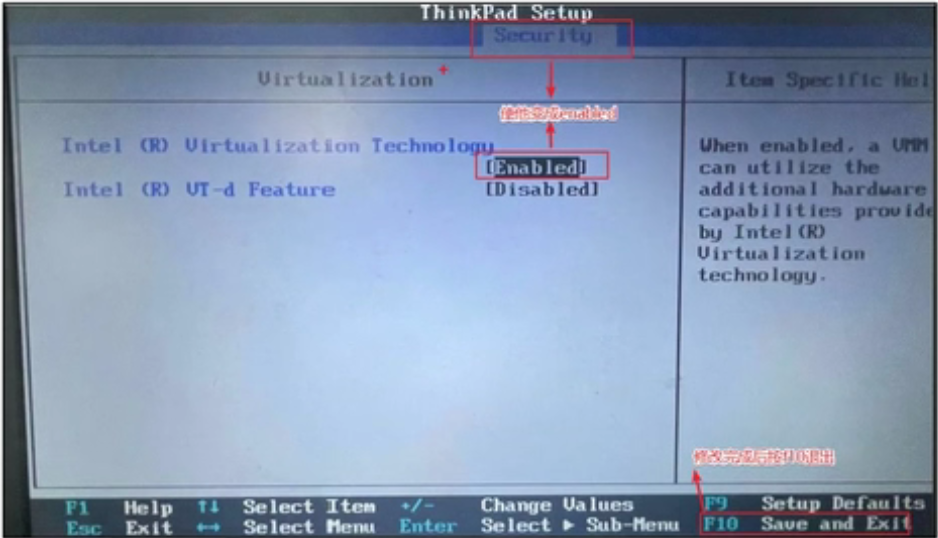
(3)如果发现bios虚拟化没有开启怎么办,重启电脑,在加载界面时按f1-f10,或者电脑旁边一个小洞,具体怎么进入得去查一下(按照自己电脑的型号去查)
(4)修改虚拟化为开启(thinkpad为例)找到security里面的VT并改成enabled
创建新的虚拟机
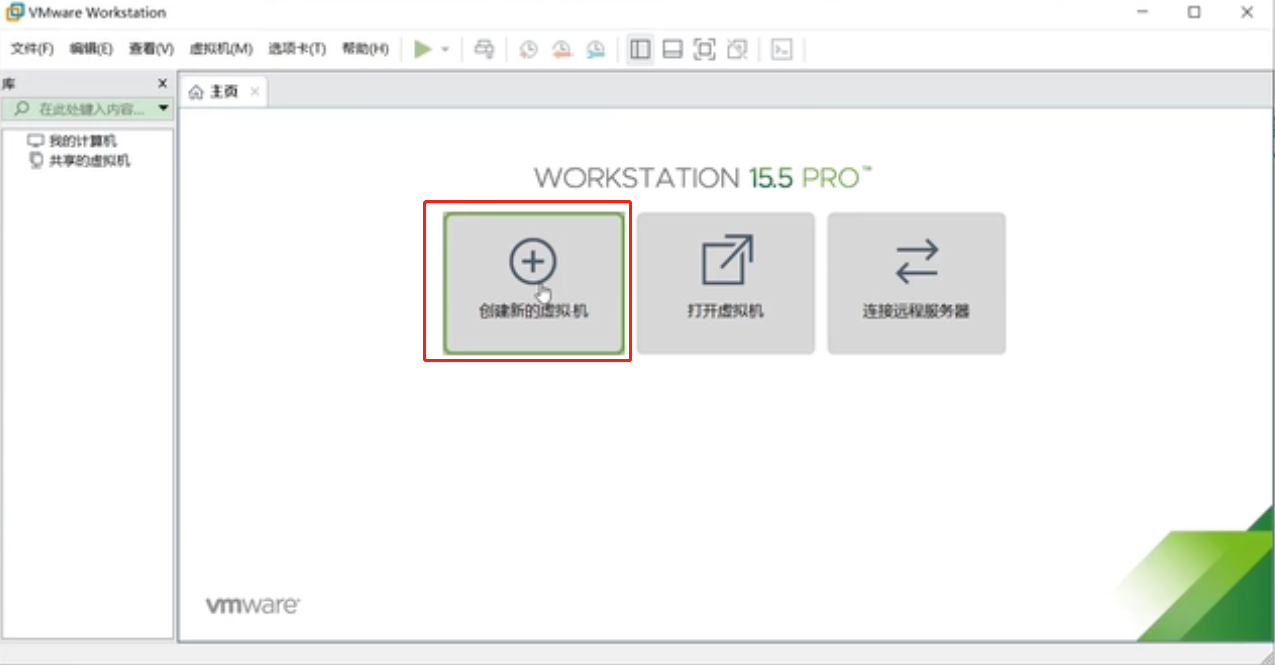
选择“自定义”,下一步
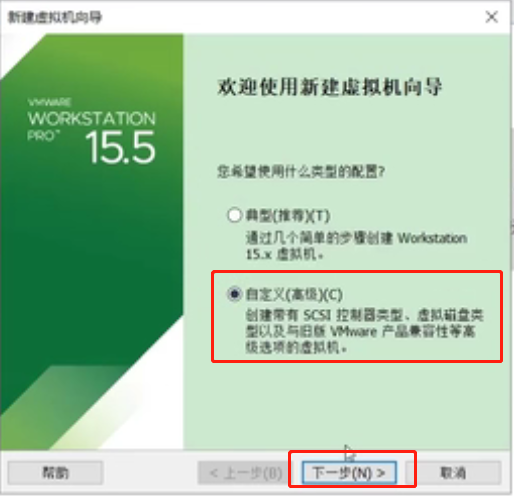
下一步
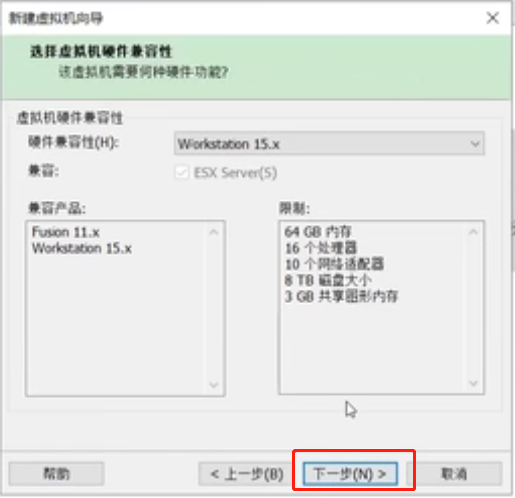
选择“稍后安装操作系统”,下一步
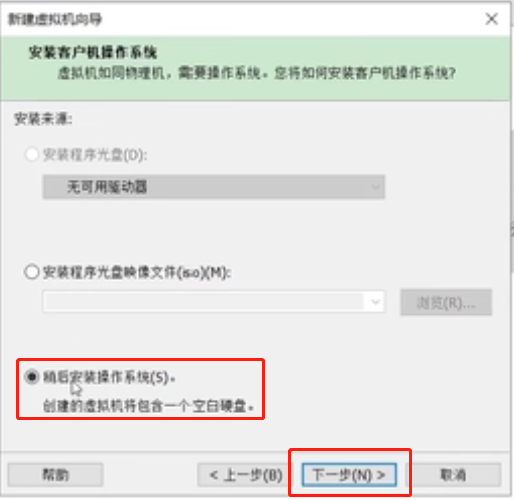
选择客户机操作系统为“Linux”,版本为“CentOS 7 64位”,下一步
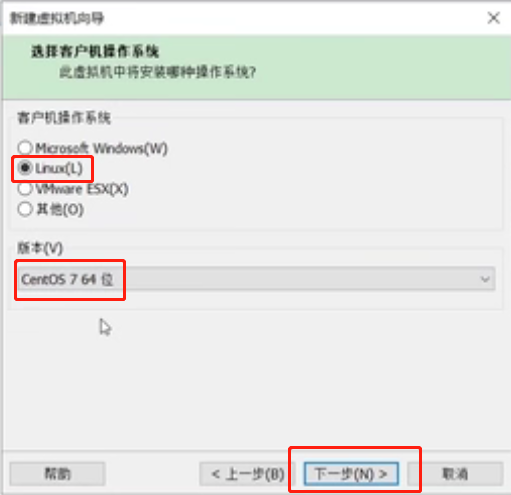
修改虚拟机名称为“hadoop100”,修改安装位置,下一步
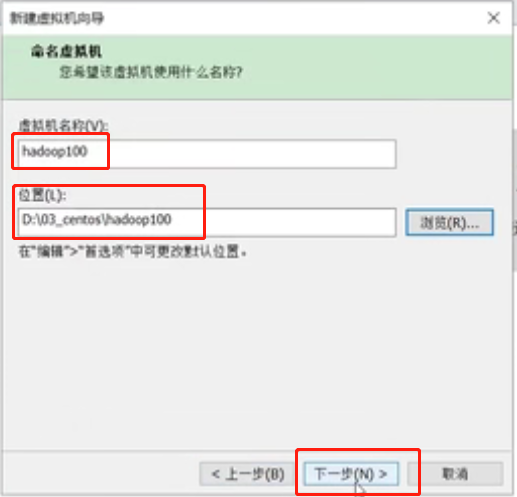
修改处理器数量和每个处理器的内核数量,下一步
注意:处理器数量和每个处理器的内核数量的总和不能超过自己系统的CPU总数
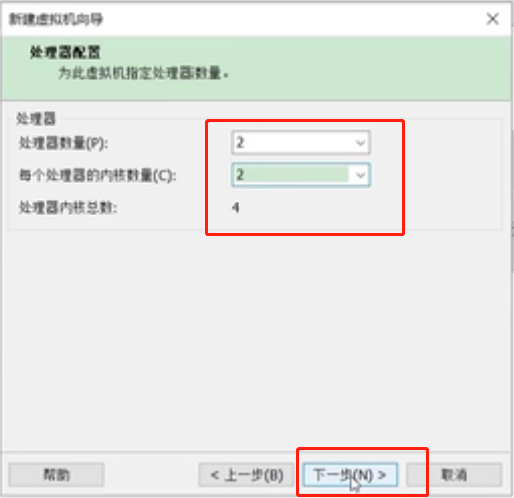
修改虚拟机内存,向下兼容一般设置为4G,下一步

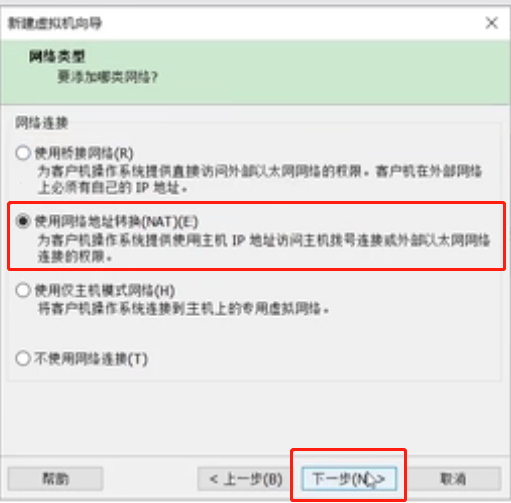
网络类型选择“使用网络地址转换(NAT)”,下一步
I/0选择器类型选择推荐的即可,下一步
磁盘类型选择默认推荐的
选择“创建新虚拟磁盘”,下一步
修改最大磁盘大小为“50G”,下一步
修改磁盘文件路径到当前虚拟机目录下,方便统一管理。下一步
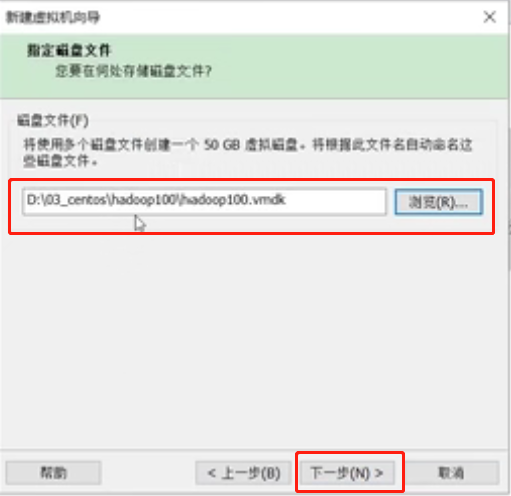
点击“完成”
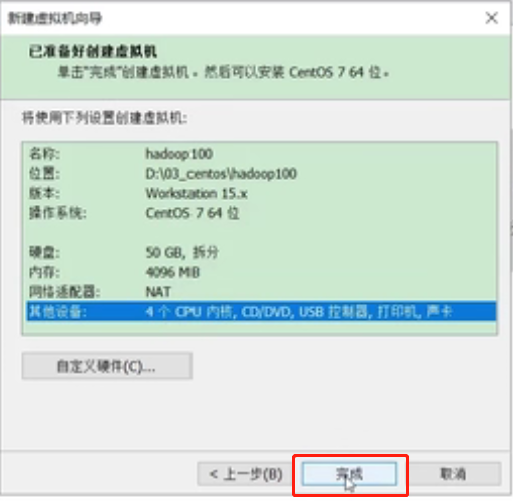
这就是刚刚安装的虚拟机,名字是刚刚自己取的
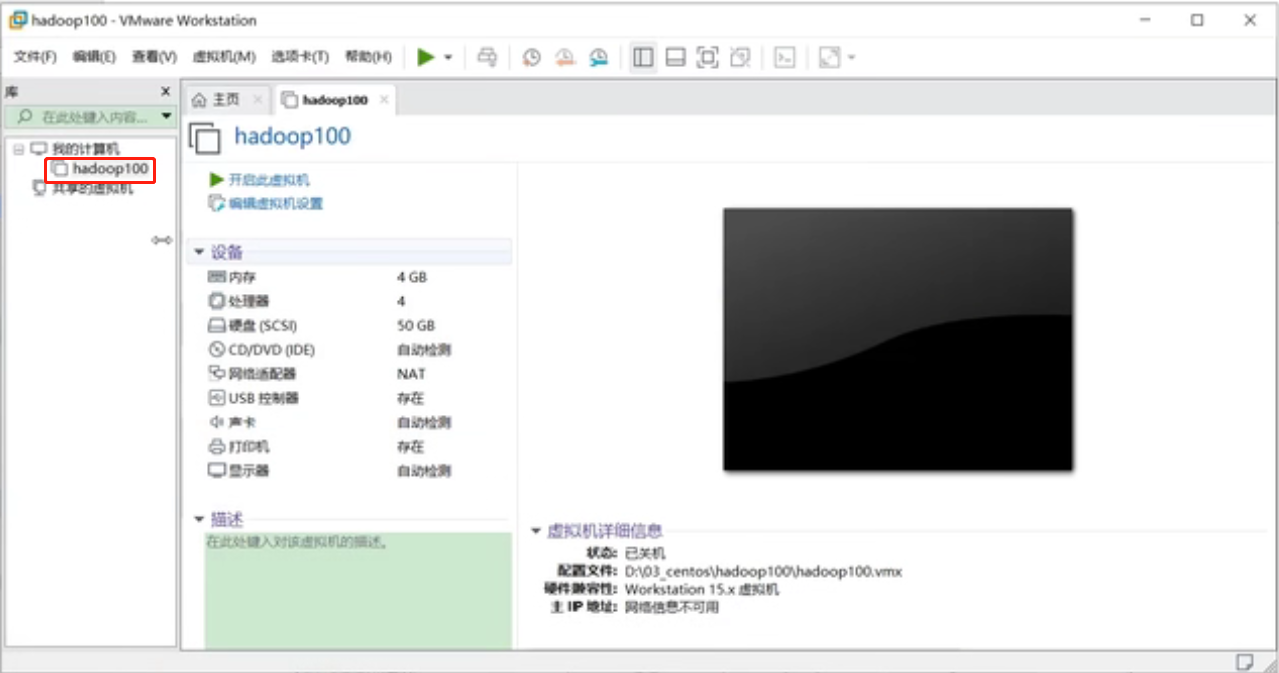
继续安装操作系统,步骤如下:
点击“CD/DVD”选择插入一块硬盘
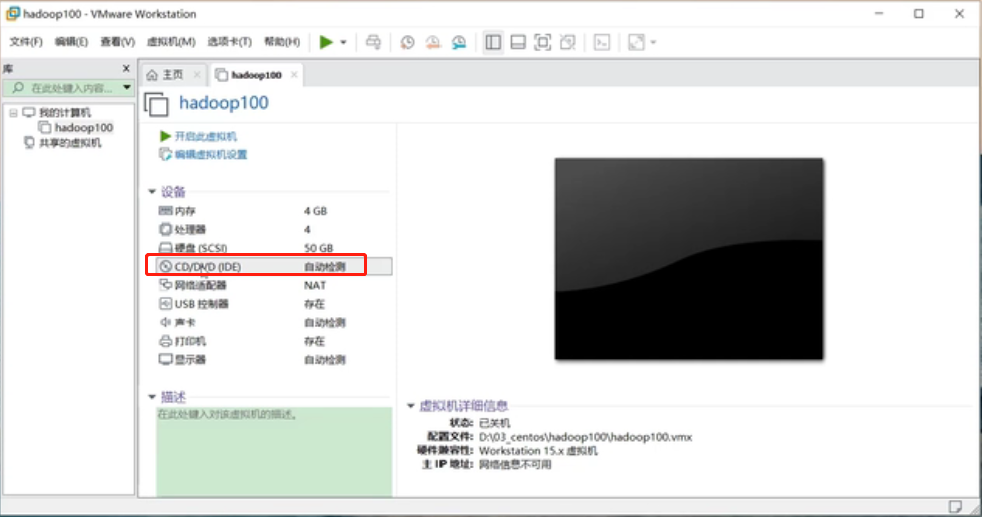
选择“使用ISO映像文件”插入镜像文件,确定
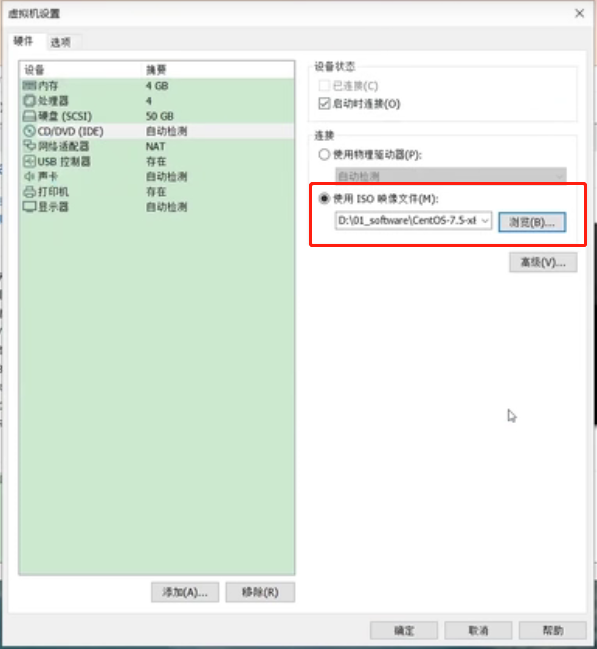
插入镜像文件之后,“开启此虚拟机”
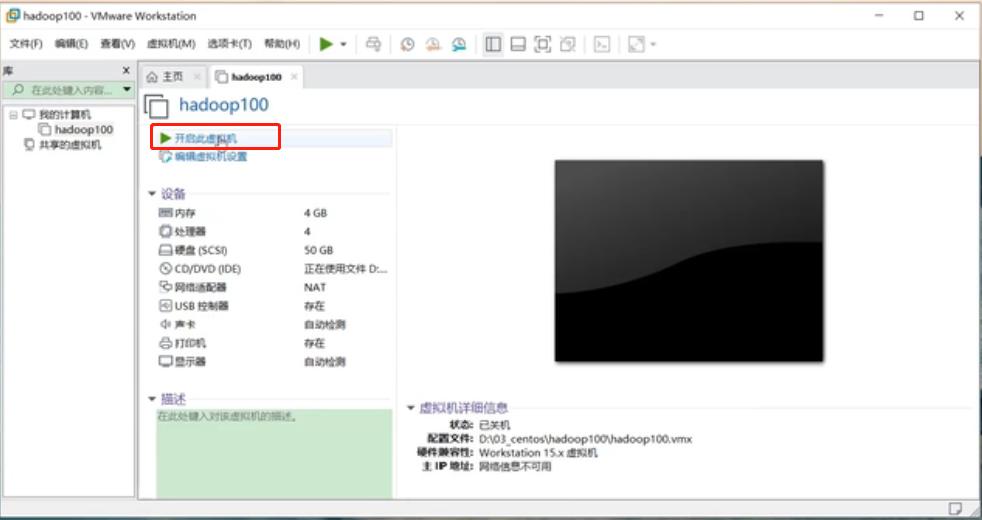
开启之后,进入页面直接Enter回车,正常安装
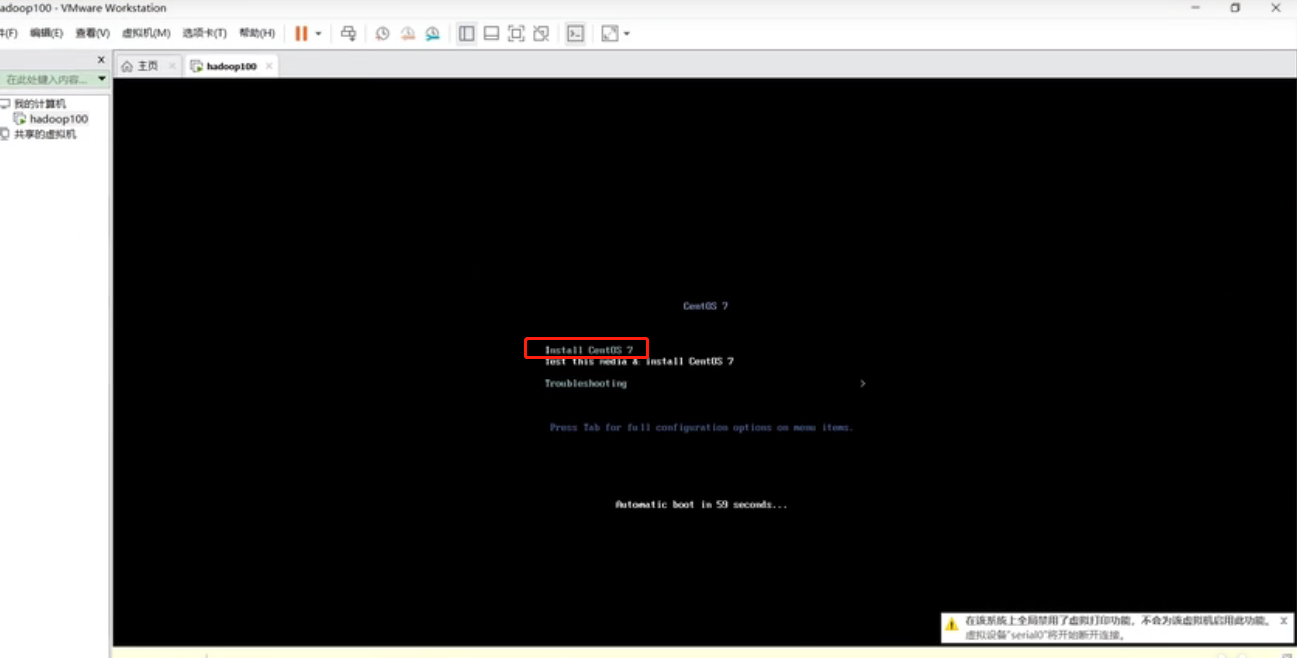
等待安装中.....
.
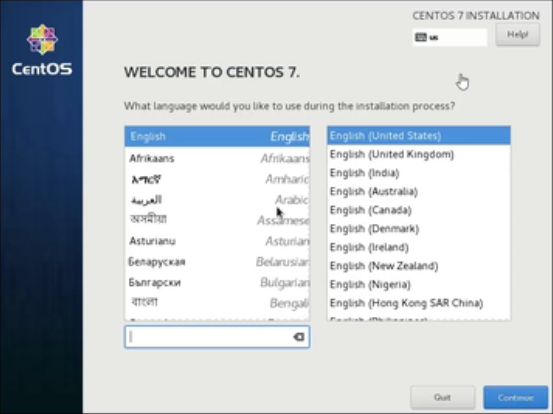
来到了欢迎页面
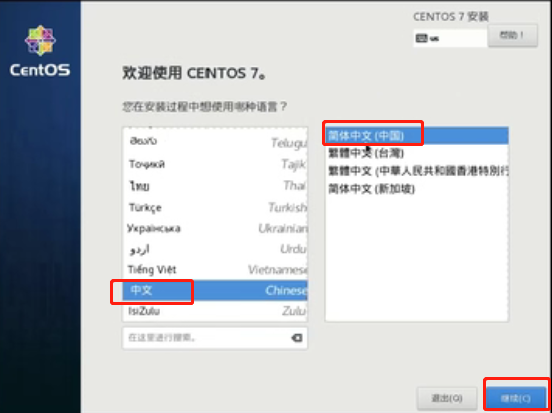
选择“中文”,继续
点击“日期和时间”设置时间
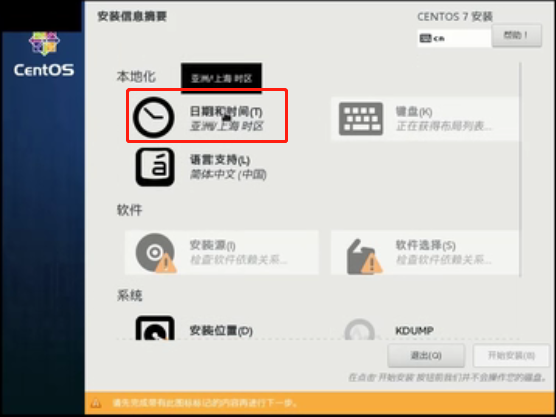
选择“亚洲”,“上海”之后,设置好时间,点击“完成”
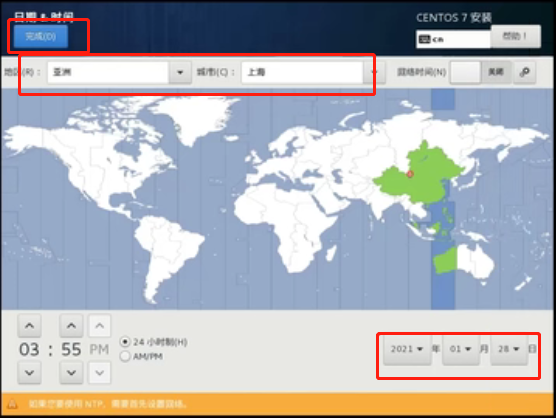
完整日期时间设置后,点击“软件选择”
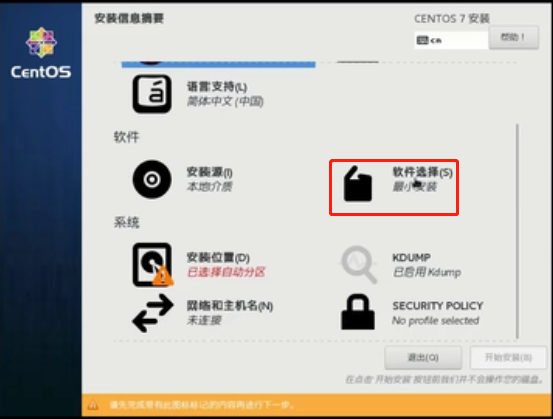
选择“桌面”版安装,点击完成
注意:也可以选择“最小安装”,区别:最小系统没有图形化页面,全部命令行操作,本人学习阶段选择的是桌面版本
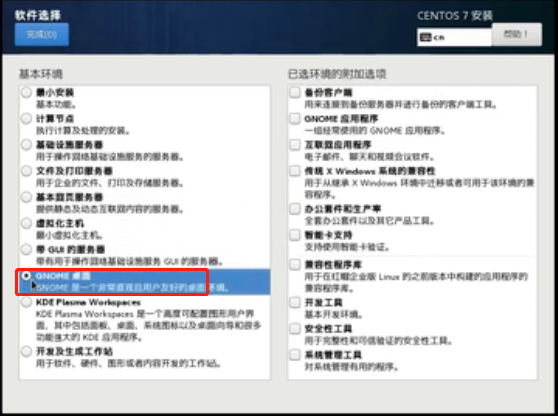
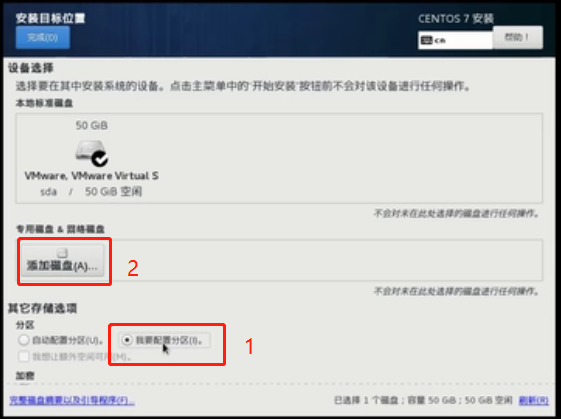
接下来点击“安装位置”
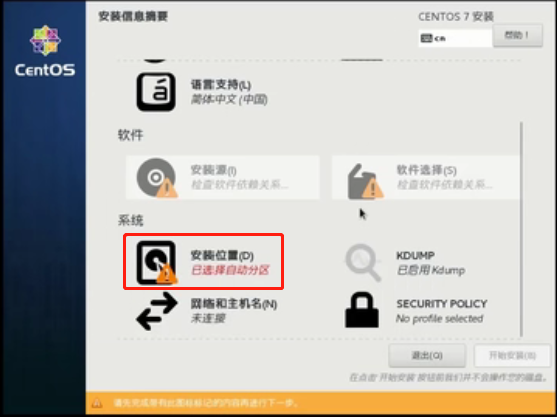
选择“我要配置分区”,然后“添加磁盘”,点击完成
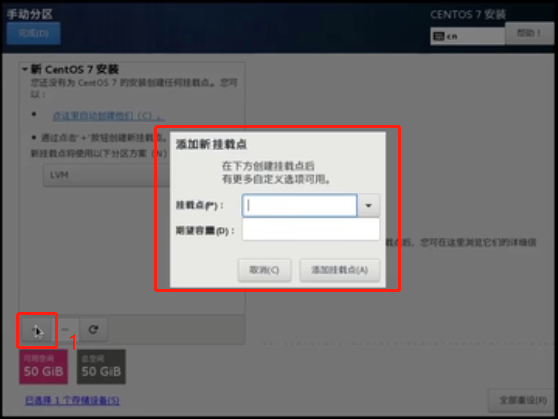
弹出以下页面,点击“+”,弹出页面选择挂载点和容量,并将文件系统设置为“ext4”
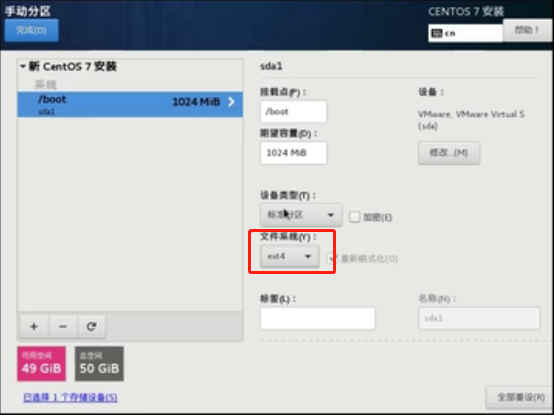
这个过程中,我配置了三个挂载点,分别为
/boot 1g 、 swap 4g 、 / 45g
添加完毕,点击完成
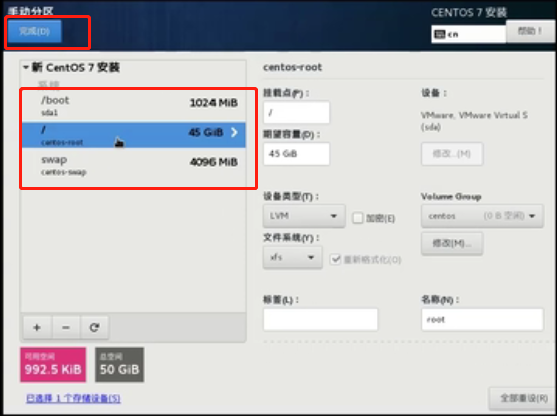
接受并更改
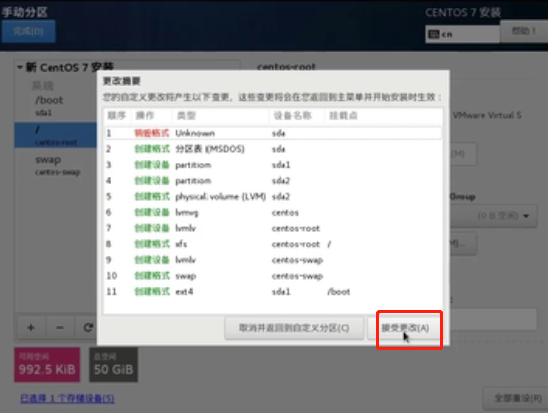
点击“KDUMP”
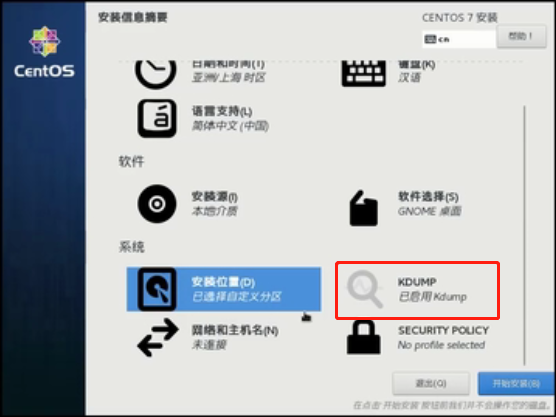
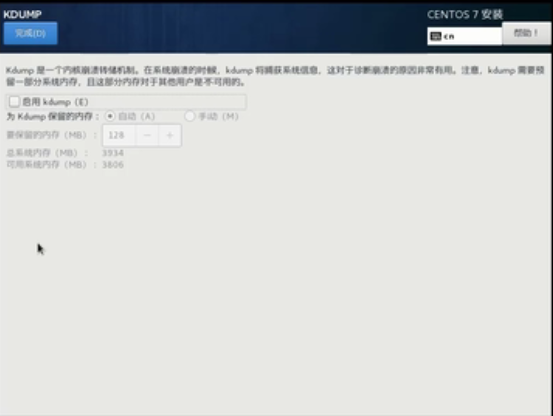
去掉勾选“kdump”,学习阶段崩溃不备份,并点击“完成”
点击“网络和主机名”
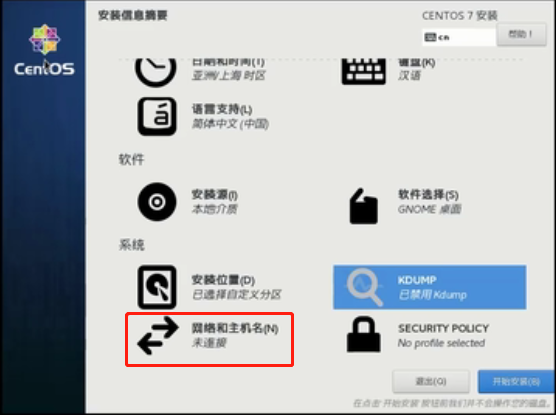
修改主机名为“hadoop100”,打开网络,点击完成
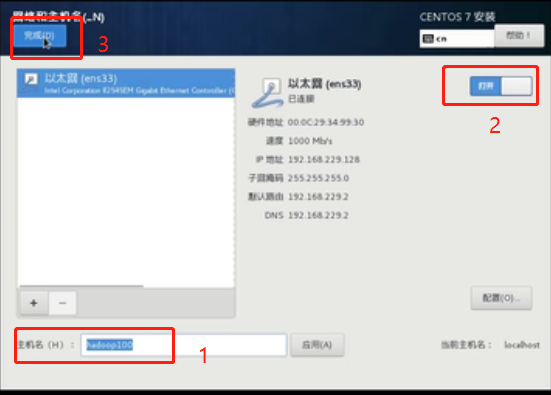
点击“SECURITY POUCY”
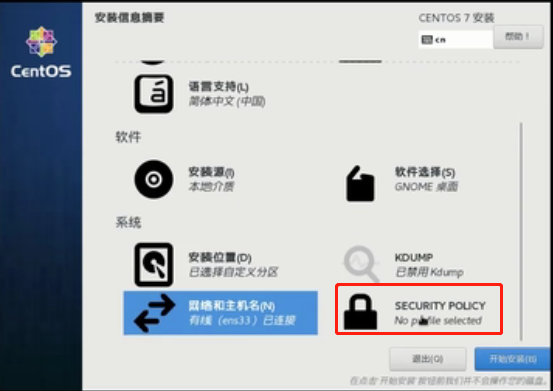
保持默认打开即可,点击完成
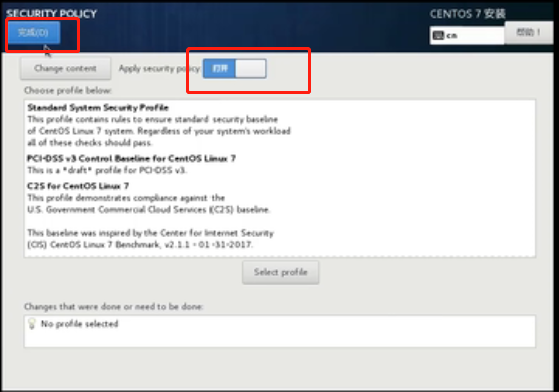
所有准备完毕,开始安装
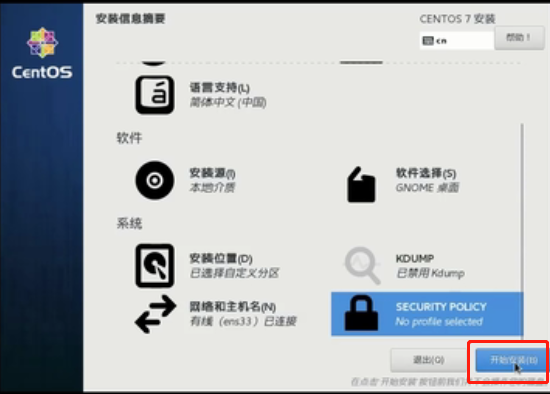
等待安装中........

安装过程中顺便配置一下ROOT密码
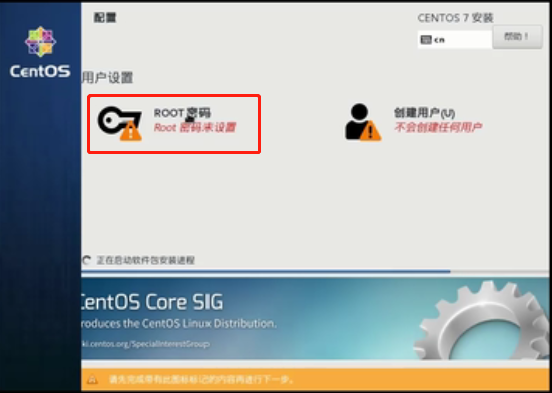
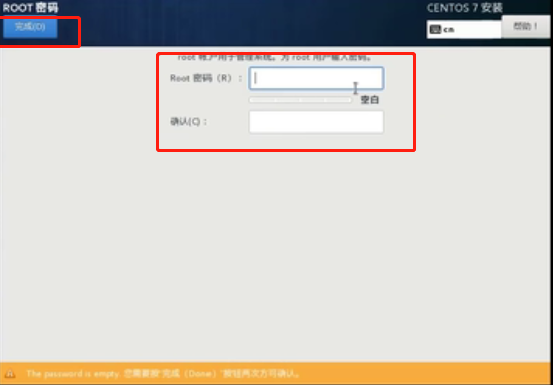
设置密码为123456,点击完成
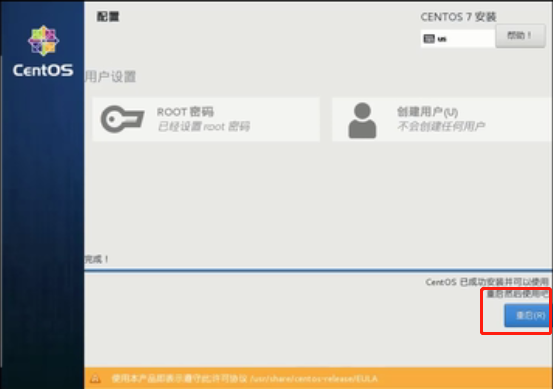
经过十几分钟的等待,安装完毕,点击“重启”
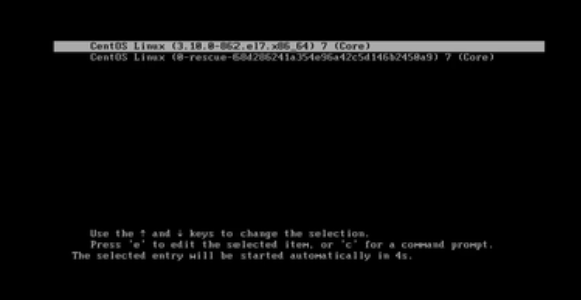
回车
进入主页面,点击“LICENSIGN”
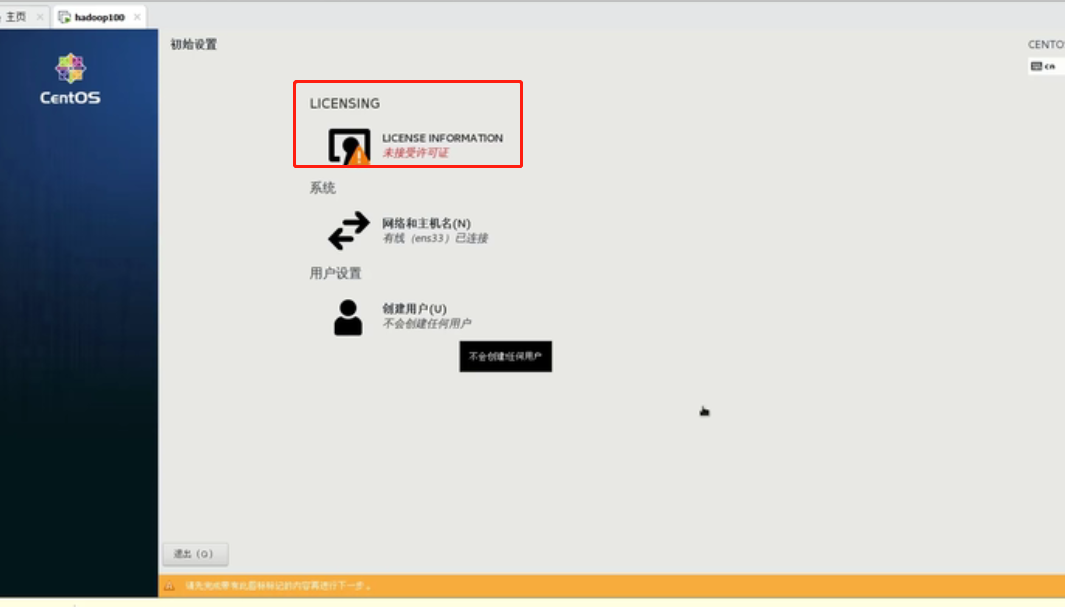
勾选同意,点击完成
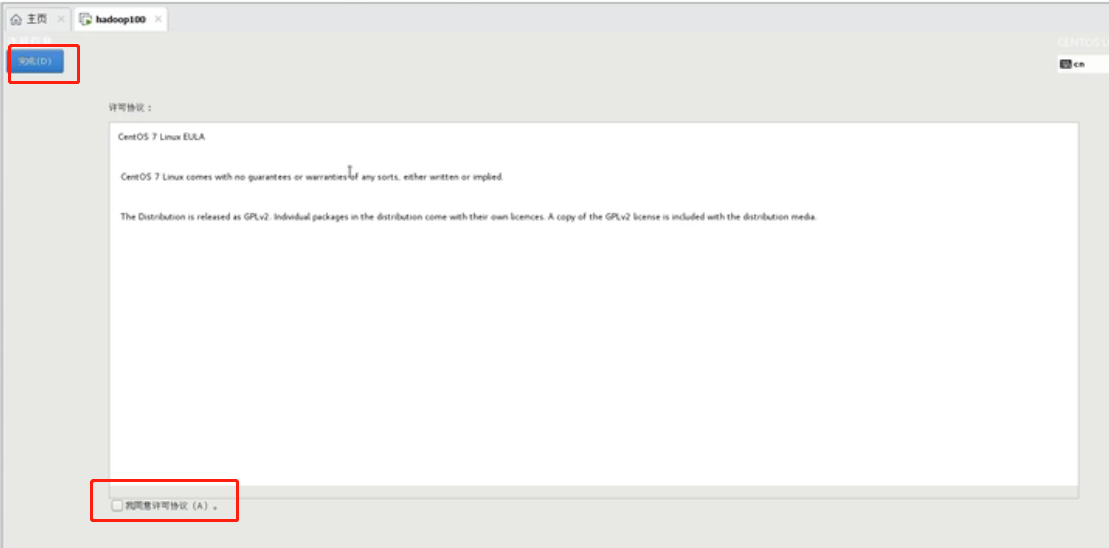
点击“完成配置”
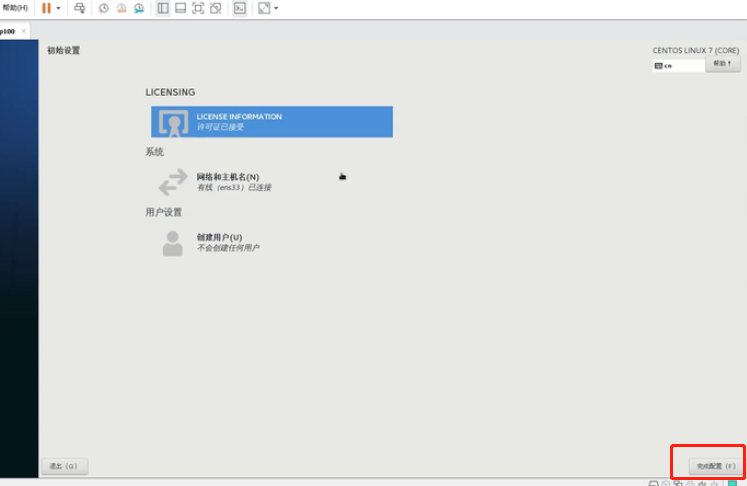
直接“前进”
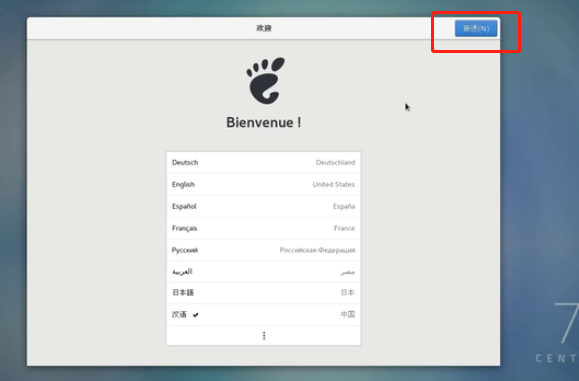
前进
前进
允许访问
输入“上海”,前进
跳过
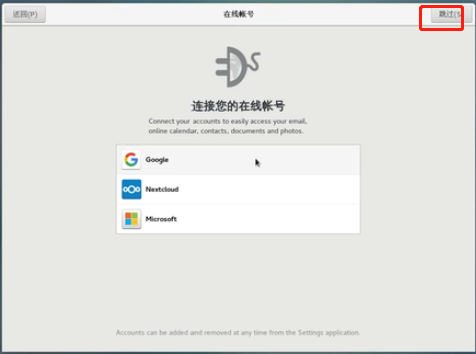
设置账号,atguigu
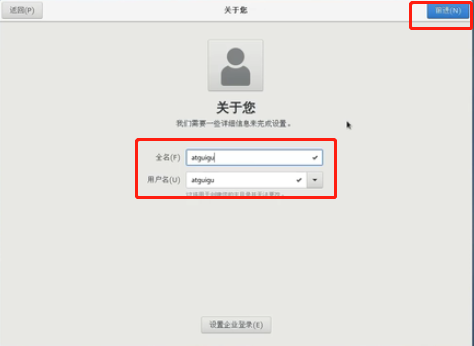
设置密码123456,前进
至此,该虚拟机设置完毕
目标: ip和主机名称配置
1、配置VM的ip地址
VMware点击“编辑”,选择“虚拟网络编辑器”
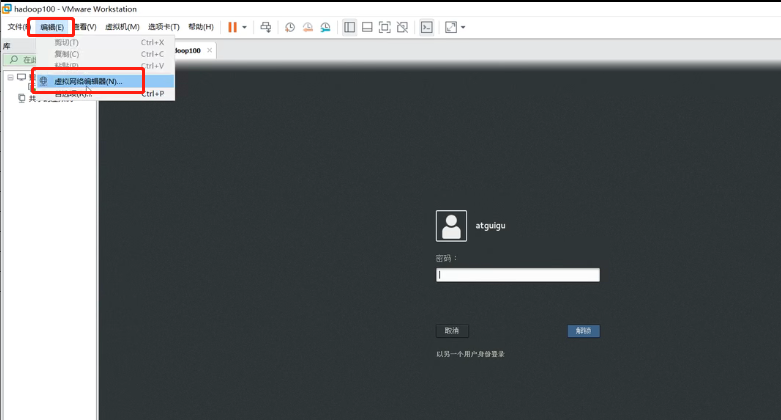
点击“VMnet8”,“更改设置”
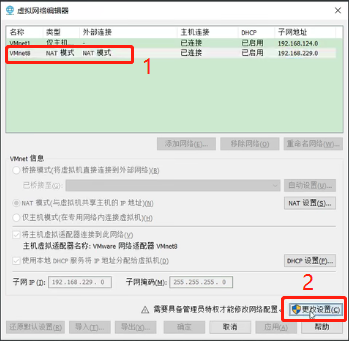
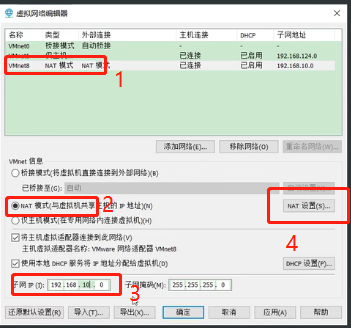
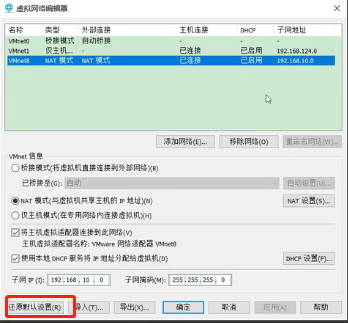
再次打开“虚拟网络编辑器”,点击“VMnet8”,选择NAT模式,修改子网掩码为:192.168.10.0,点击“NAT设置”
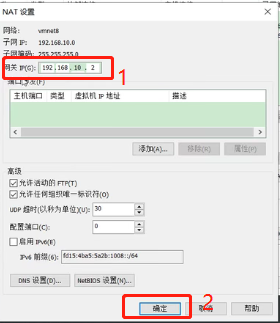
修改NAT设置网关IP为:192.168.10.2,点击确定
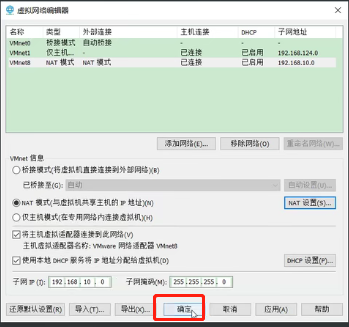
点击确定
2、修改win10的的ip地址
“控制面板”找到“网络和Internet”,找到“网络连接”,右键VMnet8,选择属性
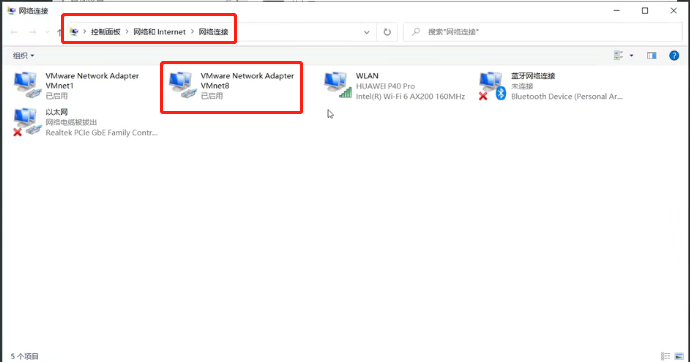
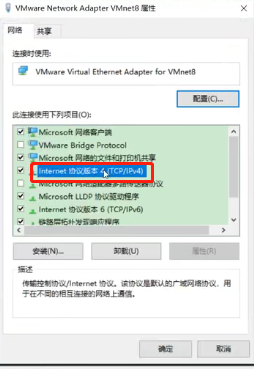
双击“Internet协议版本4”
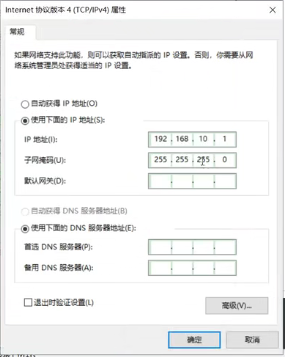
修改ip地址和网关如下,点击确定保存
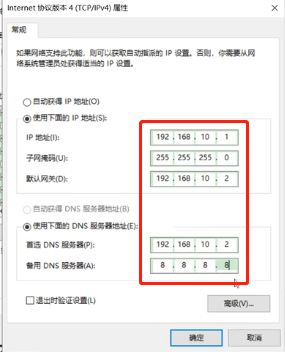
注意:如果你的网络连接页面没有出现VMnet8,则打开VMware的“虚拟网络编辑”页面,点击“还原默认设置”按钮,操作完毕之后就会出现VMnet8
3、修改主机ip
回到VMware页面,输入密码登录
右键“打开终端”,打开如下页面。显示当前用户是atguigu
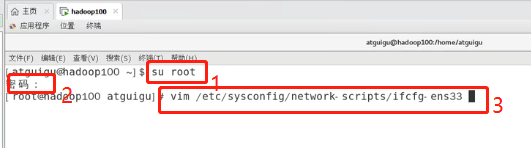
输入以下命令
#切换到root用户 su root #输入密码 123456 #vim打开ifcfg-ens33文件 vim /etc/sysconfig/network-scripts/ifcfg-ens33
得到以下页面,按照截图所示操作
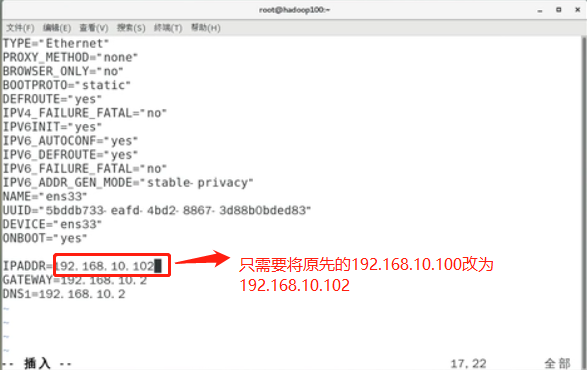
IPADDR=192.168.10.100 GATEWAY=192.168.10.2 DNS1=192.168.10.2
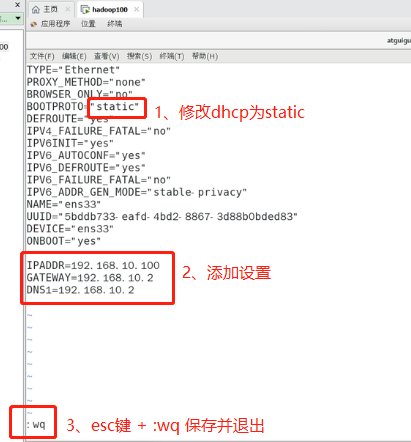
修改主机名称
#vim打开修改主机名称
vim /etc/hostname

进入后发现主机名称默认为hadoop100(创建虚拟机的时候设置的),不用修改,直接退出
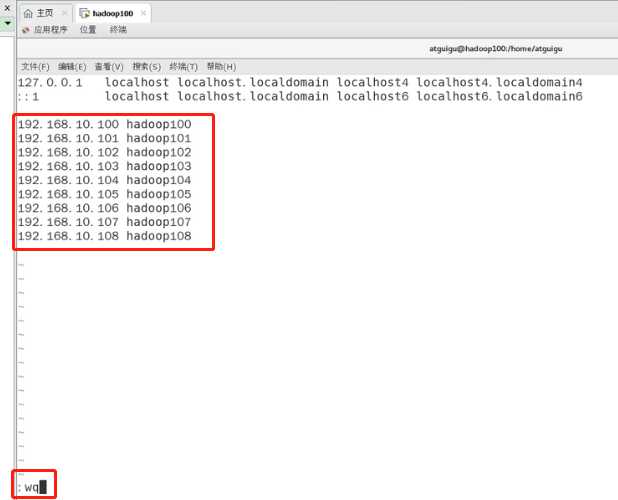
修改hosts主机文件,输入以下命令
vim /etc/hosts

打开hosts文件之后,添加以下配置,并保存退出
192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 192.168.10.105 hadoop105 192.168.10.106 hadoop106 192.168.10.107 hadoop107 192.168.10.108 hadoop108
重启主机
#reboot命令:重启主机
reboot
重启之后以root账号重新登录虚拟机,并打开终端
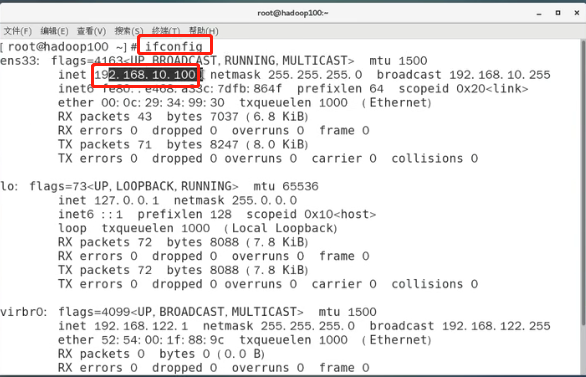
输入以下命令,验证ip地址,发现ip地址已更新
#输入命令验证ip地址
ifconfig
ping一下百度,看是否能ping通
ping www.baidu.com

查看主机名称
hostname

目标:Xshell远程访问工具
傻瓜式下一步安装xshell工具,这里不做介绍了
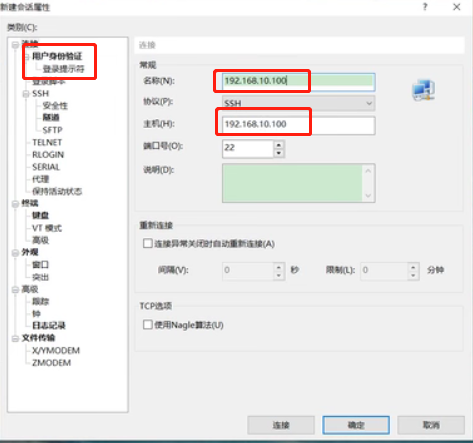
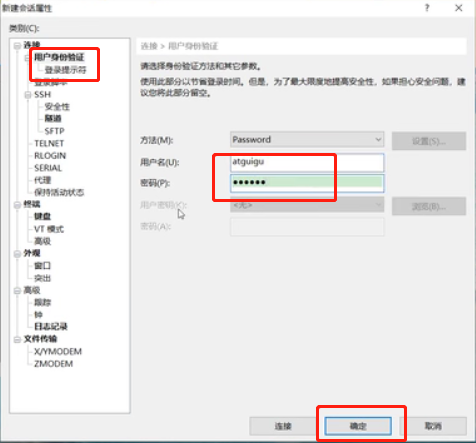
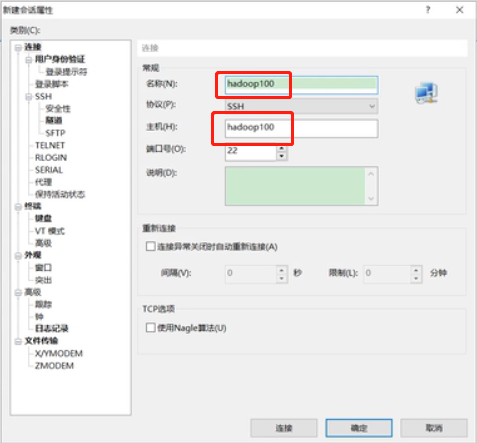
输入ip地址192.168.10.100连接,以atguigu账号连接入
下面我们的目的是将ip地址和主机名称关联起来:修改Windows的主机映射文件(host文件)
(1)如果操作系统是window7,可以直接修改
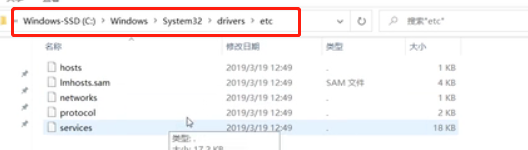
(a)进入C:\Windows\System32\drivers\etc路径找到hosts文件
打开hosts文件并添加如下内容,然后保存
192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 192.168.10.105 hadoop105 192.168.10.106 hadoop106 192.168.10.107 hadoop107 192.168.10.108 hadoop108
(2)如果操作系统是window10,先拷贝出来,修改保存以后,再覆盖即可
(a)进入C:\Windows\System32\drivers\etc路径
(b)拷贝hosts文件到桌面
(c)打开桌面hosts文件并添加如下内容
192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 192.168.10.105 hadoop105 192.168.10.106 hadoop106 192.168.10.107 hadoop107 192.168.10.108 hadoop108
(d)将桌面hosts文件覆盖C:\Windows\System32\drivers\etc路径hosts文件
修改完毕之后,重新连接xshell,这次输入名称和主机为hadoop100,仍然以atguigu账号登录
接着傻瓜式安装xftp工具
目标:模板虚拟机准备完成
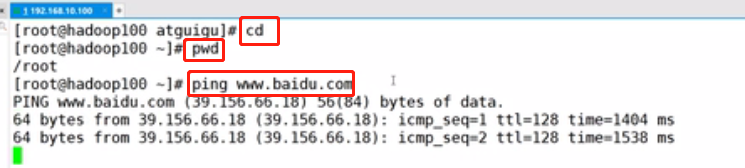
输入以下命令,切换到root账号

切换目录,并且查看网络状态
输入以下命令,安装epel-release:是一个软件仓库
yum install -y epel-release
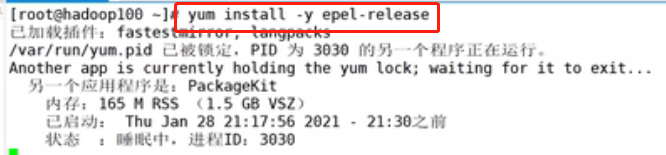
发现有一个pid被占用,用kill命令杀掉进程
kill -9 3030

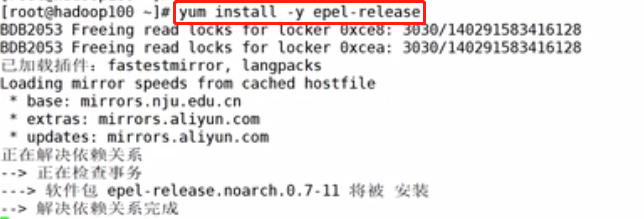
再次执行命令:yum install -y epel-release
注意:如果Linux安装的是最小系统版,还需要安装如下工具;如果安装的是Linux桌面标准版,不需要执行如下操作
- net-tool:工具包集合,包含ifconfig等命令
yum install -y net-tools
- vim:编辑器
yum install -y vim
关闭防火墙,关闭防火墙开机自启
#关闭防火墙
systemctl stop firewalld
#关闭防火墙开机自启
systemctl disable firewalld.service

注意:在企业开发时,通常单个服务器的防火墙时关闭的。公司整体对外会设置非常安全的防火墙
配置atguigu用户具有root权限,方便后期加sudo执行root权限的命令
vim /etc/sudoers

修改/etc/sudoers文件,在%wheel这行下面添加一行,保存并退出,如下所示:
## Allow root to run any commands anywhere root ALL=(ALL) ALL ## Allows people in group wheel to run all commands %wheel ALL=(ALL) ALL atguigu ALL=(ALL) NOPASSWD:ALL
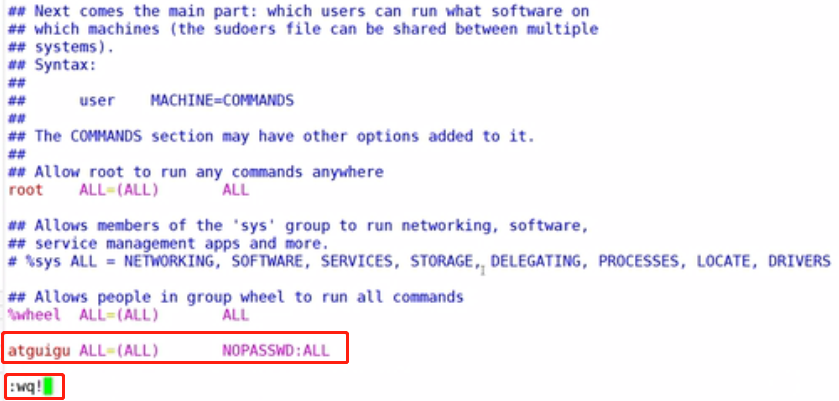
测试一下是否好用
#切换到/opt目录 cd /opt/ #查看目录内容 ll #退出到aiguigu用户,因为我们是从atguigu用户切换进来的 exit #再次切换到/opt目录 cd /opt/ #查看目录内容 ll #删除掉rh文件(root权限),发现权限不足 rm -rf rh/ #sudo执行删除 sudo rm -rf rh/ #查看是否删除,发现已经删除了rh文件 ll
做准备工作
#在当前路径/opt创建module文件夹(软件安装目录),当前操作账号是atguigu sudo mkdir module #查看目录文件 ll #创建software文件夹 sudo mkdir software #查看目录文件,发现module、software文件夹的所有者和所属组均为root用户 ll #修改module、software文件夹的所有者和所属组均为atguigu用户
#注意:需要切换到root账号操作 chown atguigu:atguigu /opt/module chown atguigu:atguigu /opt/software #查看module、software文件夹的所有者和所属组 ll
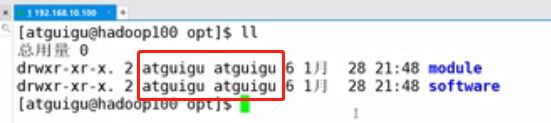
发现module、software文件夹的所有者和所属组都已经变为atguigu了
卸载虚拟机自带的JDK
注意:如果你的虚拟机是最小化安装不需要执行这一步
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps rpm -qa:查询所安装的所有rpm软件包 grep -i:忽略大小写 xargs -n1:表示每次只传递一个参数 rpm -e –nodeps:强制卸载软件
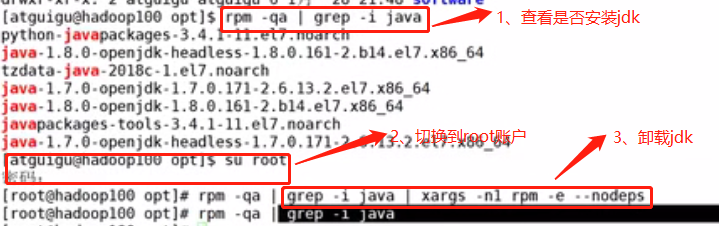
最后重启虚拟机
reboot
目标:克隆三台虚拟机
此次的目标是利用模板机hadoop100,克隆三台虚拟机:hadoop102 hadoop103 hadoop104
注意:克隆的时候,要先关闭hadoop100
右键hadoop100--->管理--->克隆
下一步
下一步
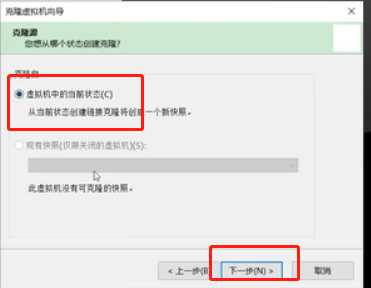
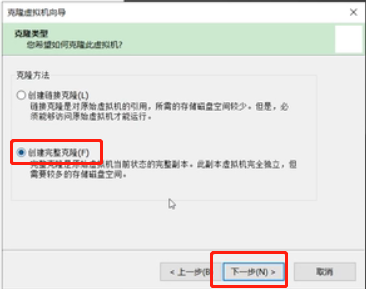
选择“创建完整克隆”,点击下一步
修改虚拟机名称,选择安装位置,点击完成
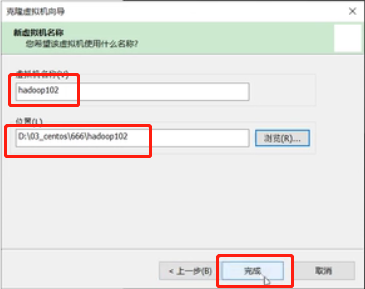
克隆等待中
一模一样的操作过程,克隆出103和104,并将虚拟机新建目录进行管理
启动虚拟机hadoop102,root用户登录,并打开终端
修改克隆虚拟机hadoop102的静态IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改虚拟机hadoop102名称
vim /etc/hostname
查看hosts文件是否都已经修改了
vim /etc/hosts
发现之前都已经修改过了,不用修改

重启机器
reboot
一模一样的流程修改hadoop103和hadoop104
(1)启动虚拟机hadoop103(4),root用户登录,并打开终端
(2)命令vim /etc/sysconfig/network-scripts/ifcfg-ens33打开,修改IPADDR=192.168.10.100为IPADDR=192.168.10.103(4)
(3)命令vim /etc/hostname虚拟机hadoop103(4)名称
(4)重启虚拟机
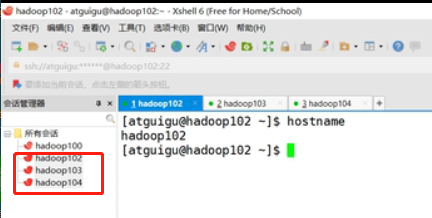
xshell工具链接hadoop102、hadoop103、hadoop104
目标:JDK安装
注意:安装JDK之前,一定要确保提前删除了虚拟机自带的JDK
用XShell传输工具将JDK导入到opt目录下面的software文件夹下面
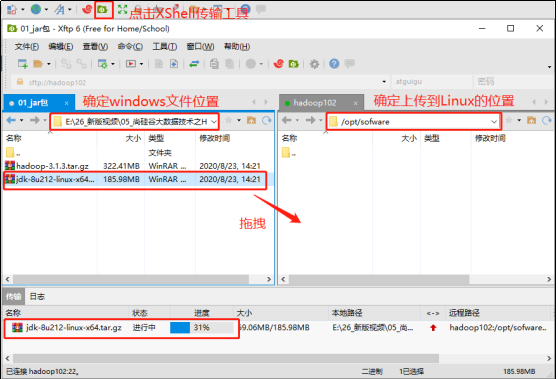
切换到/opt/software目录,查看是否上传成功

解压JDK到/opt/module目录下
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
解压完毕后切换目录到/opt/module/jdk1.8.0_212下
配置JDK环境变量
(1)新建/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh

注意截图里面是已经切换到/etc/profile.d目录了
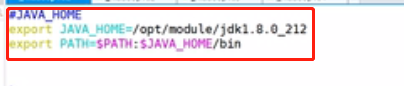
添加如下内容
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin
(2)保存后退出
:wq
(3)source一下/etc/profile文件,让新的环境变量PATH生效
source /etc/profile
测试JDK是否安装成功
java -version
如果能看到以下结果,则代表Java安装成功。
java version "1.8.0_212"
注意:重启(如果java -version可以用就不用重启
目标:hadoop安装
用XShell文件传输工具将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面
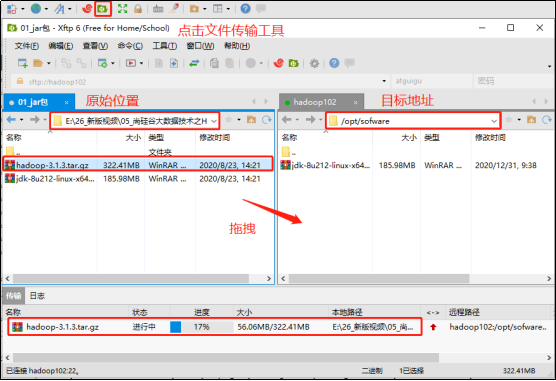
进入到hadoop安装包路径下
cd /opt/software/
解压安装文件到/opt/module下面
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
查看是否解压成功
ls /opt/module/
将hadoop添加到环境变量
(1)打开/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh
在my_env.sh文件末尾添加如下内容:(shift+g)
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
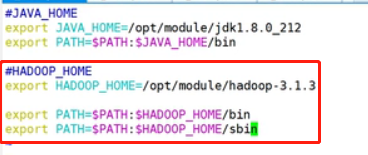
保存并退出
(2)让修改后的文件生效
source /etc/profile
测试是否安装成功
hadoop version
重启(如果hadoop命令不能用再重启虚拟机)
目标:本地运行模式
主机hadoop102切换目录到/opt/module/hadoop-3.1.3,在此下面新建一个wcinput文件夹
mkdir wcinput
在wcinput文件夹下创建一个word.txt文件
#进入创建的wcinput文件夹 cd wcinput/ #创建word.txt文件 vim word.text
编辑word.txt文件,在文件中输入如下内容,保存并退出
hadoop yarn
hadoop mapreduce
atguigu
atguigu
回到hadoop目录 /opt/module/hadoop-3.1.3
执行以下命令
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
查看结果
cat wcoutput/part-r-0000
看到如下结果: atguigu 2 hadoop 2 mapreduce 1 yarn 1
目标:完全分布式运行模式
1、scp(secure copy)安全拷贝
(1)scp定义
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
(3)案例实操
前提:在hadoop102、hadoop103、hadoop104都已经创建好的/opt/module、/opt/software两个目录,并且已经把这两个目录修改为atguigu:atguigu
sudo chown atguigu:atguigu -R /opt/module
备注:由于我们在克隆主机之前就已经设置好了,所以这里不需要设置
(a)在hadoop102上,将hadoop102中/opt/module/jdk1.8.0_212目录拷贝到hadoop103上。
scp -r /opt/module/jdk1.8.0_212 atguigu@hadoop103:/opt/module
首次连接需要密码,拷贝时间比较长
(b)在hadoop103上,将hadoop102中/opt/module/hadoop-3.1.3目录拷贝到hadoop103上。
scp -r atguigu@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/
(c)在hadoop103上操作,将hadoop102中/opt/module目录下所有目录拷贝到hadoop104上。
scp -r atguigu@hadoop102:/opt/module/* atguigu@hadoop104:/opt/module
2、rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
选项参数说明
|
选项 |
功能 |
|
-a |
归档拷贝 |
|
-v |
显示复制过程 |
(2)案例实操
(a)删除hadoop103中/opt/module/hadoop-3.1.3/wcinput
cd /opt/module/hadoop-3.1.3
rm -rf wcinput/

发现主机hadoop103上的wcinput文件已经被删除了
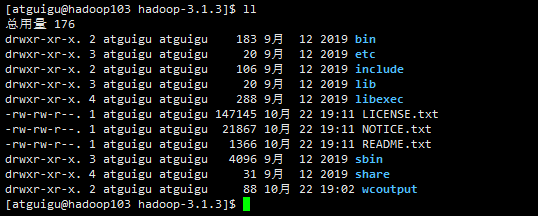
(b)同步hadoop102中的/opt/module/hadoop-3.1.3到hadoop103
cd /opt/module
rsync -av hadoop-3.1.3/ atguigu@hadoop103:/opt/module/hadoop-3.1.3/

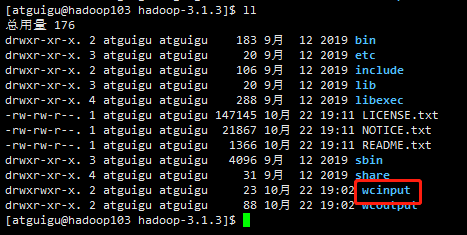
并且hadoop102上的wcinput文件已经被同步到hadoop103
发现这次同步时间比上次快
3、xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /opt/module atguigu@hadoop103:/opt/
(b)期望脚本:
xsync要同步的文件名称
举例子:
创建a.txt文件
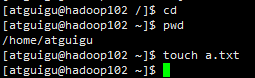
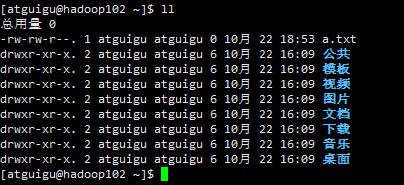
期望执行 xsync 同步文件名称 命令将a.tx同步到hadoop102和hadoop103上
(c)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
echo $PATH

(3)脚本实现
(a)在/home/atguigu/bin目录下创建xsync文件
cd mkdir bin ll cd bin/ pwd
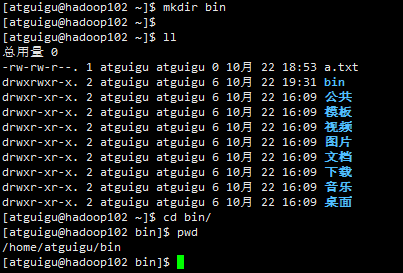
vim xsync
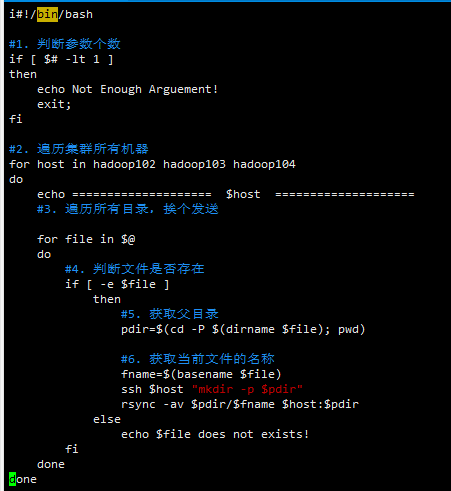
在该文件中编写如下代码
#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done
保存并退出
ll

发现这个脚本没有可执行的权限
(b)修改脚本xsync具有执行权限
chmod +x xsync

修改完毕,该脚本具有可执行权限了
(c)测试脚本
测试之前hadoop1003上没有bin目录
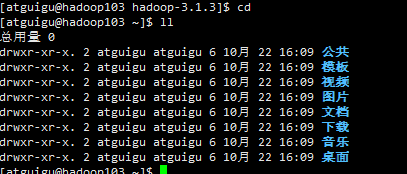
在主机hadoop102上执行脚本
cd
ll
xsync /home/atguigu/bin
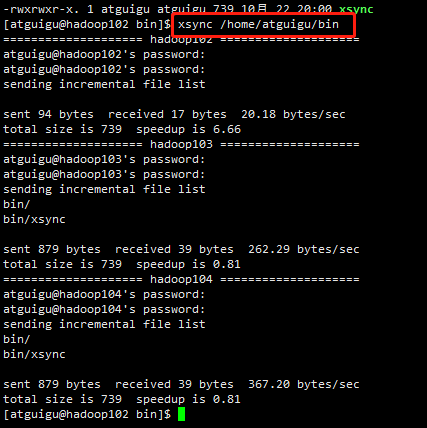
查看hadoop103和hadoop104上是否已经同步
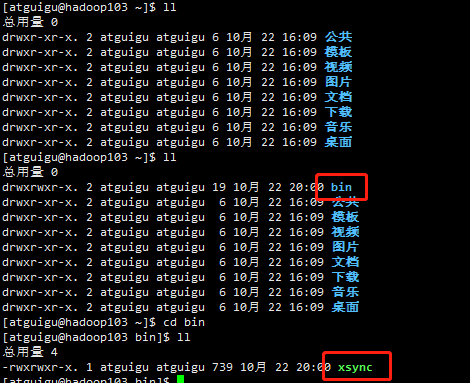
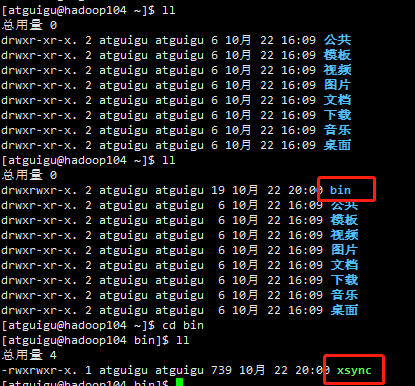
发现已经同步过去
(d)分发同步虚拟机hadoop102上的环境变量到hadoop103和hadoop104
xsync /etc/profile.d/my_env.sh
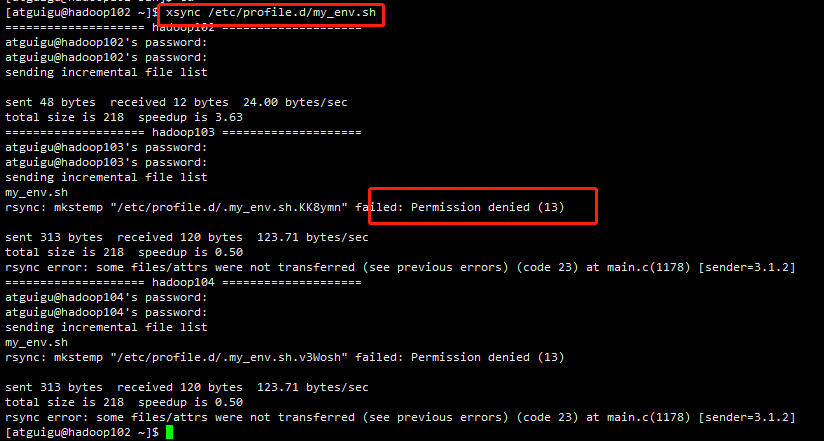
发现分发的时候权限被拒绝了,排查发现是找不到路径为绝对路径
修改命令如下:
cd
sudo ./bin/xsync /etc/profile.d/my_env.sh
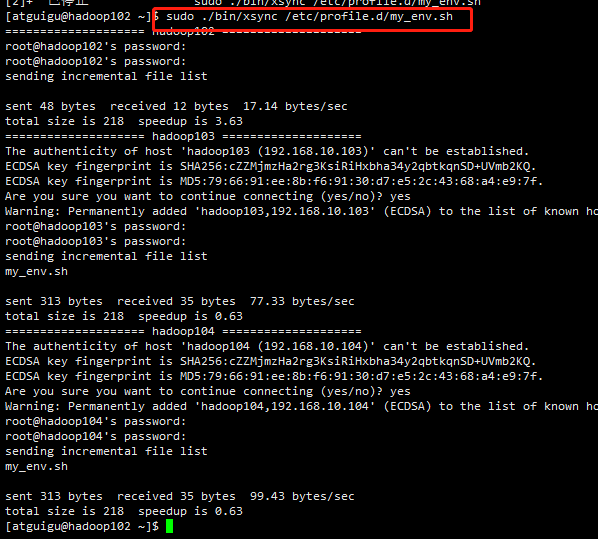
分别在hadoop103和hadoop104上查看环境变量是否同步
cd
vim /etc/profile.d/my_env.sh
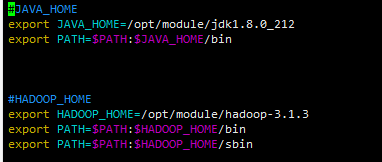
发现同步完毕,最后记得分别重新加载一下环境变量
source /etc/profile
目标:ssh免密登录
1、配置ssh
(1)基本语法
ssh另一台电脑的IP地址
(2)ssh连接时出现Host key verification failed的解决方法
ssh hadoop103
Ø 如果出现如下内容
Are you sure you want to continue connecting (yes/no)?
Ø 输入yes,并回车
(3)退回到hadoop102
exit
2、无密钥配置
(1)免密登录原理

(2)生成公钥和私钥
虚拟机hadoop102执行
cd pwd ls -al cd .ssh/ ll cd
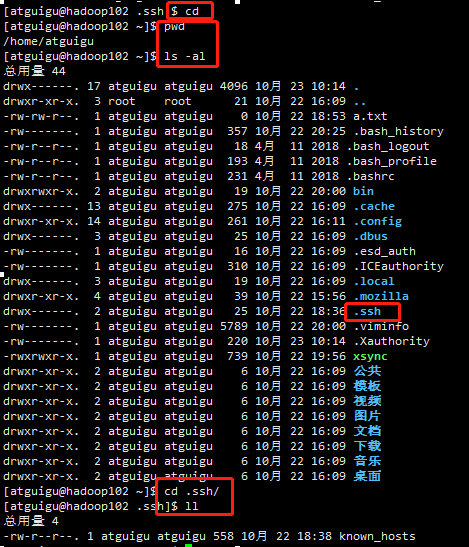
期望目标:hadoop102可以无密登录hadoop103和hadoop104,语法如下
#生成公私钥 ssh-keygen -t rsa #查看私钥 cat id_rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
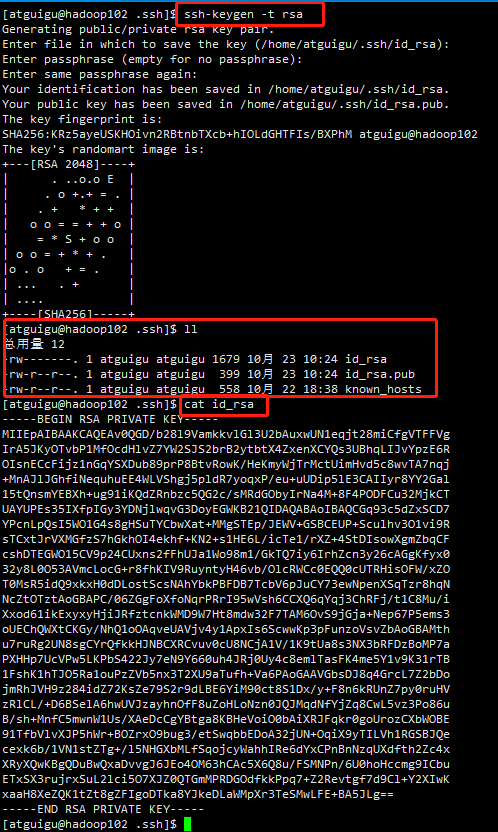
(3)将公钥拷贝到要免密登录的目标机器上
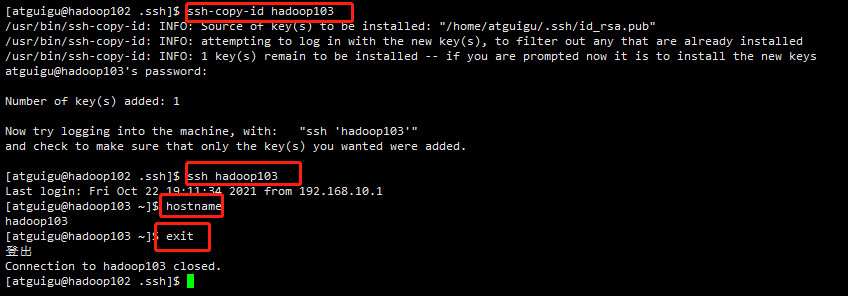
#将hadoop102的公钥拷贝到hadoop103 ssh-copy-id hadoop103 #测试是否可以ssh免密登录hadoop103 ssh hadoop103 #测试当前是否已登录到hadoop103 hostname #退出 exit #将hadoop102的公钥拷贝到hadoop104 ssh-copy-id hadoop104 #测试是否可以ssh免密登录hadoop104 ssh hadoop104 #测试当前是否已登录到hadoop104 hostname #退出 exit
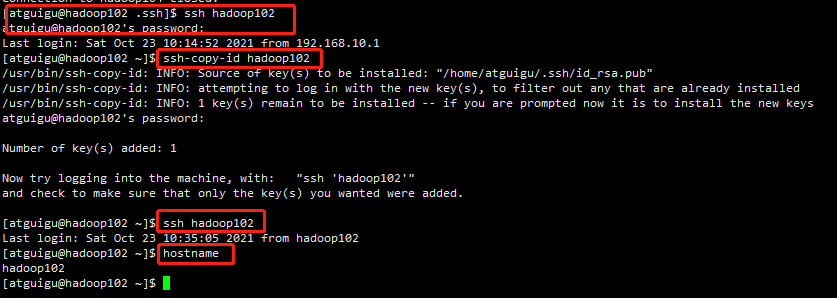
测试hadoop102是否可以ssh免密登录自己,发现不能之后,说明自己也要配置ssh免密登录才行
#测试hadoop102是否可以ssh免密登录自己 ssh hadoop102 #将hadoop102的公钥拷贝到hadoop102 ssh-copy-id hadoop103 #测试是否可以ssh免密登录hadoop102 ssh hadoop102 #测试当前是否已登录到hadoop102 hostname
注意:
还需要在hadoop103上采用atguigu账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop104上采用atguigu账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;
此处相关操作与hadoop102一模一样,不再记录
3、.ssh文件夹下(~/.ssh)的文件功能解释
|
known_hosts |
记录ssh访问过计算机的公钥(public key) |
|
id_rsa |
生成的私钥 |
|
id_rsa.pub |
生成的公钥 |
|
authorized_keys |
存放授权过的无密登录服务器公钥 |
目标:集群配置
1、集群部署规划
注意:
Ø NameNode和SecondaryNameNode不要安装在同一台服务器
Ø ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
|
hadoop102 |
hadoop103 |
hadoop104 |
|
|
HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
2、配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
|
要获取的默认文件 |
文件存放在Hadoop的jar包中的位置 |
|
[core-default.xml] |
hadoop-common-3.1.3.jar/core-default.xml |
|
[hdfs-default.xml] |
hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
|
[yarn-default.xml] |
hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
|
[mapred-default.xml] |
hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
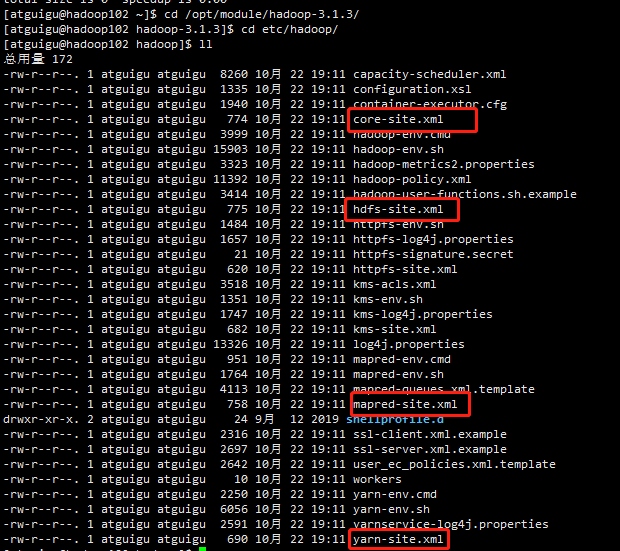
3、配置集群
(1)核心配置文件
配置core-site.xml
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml
文件内容如下:
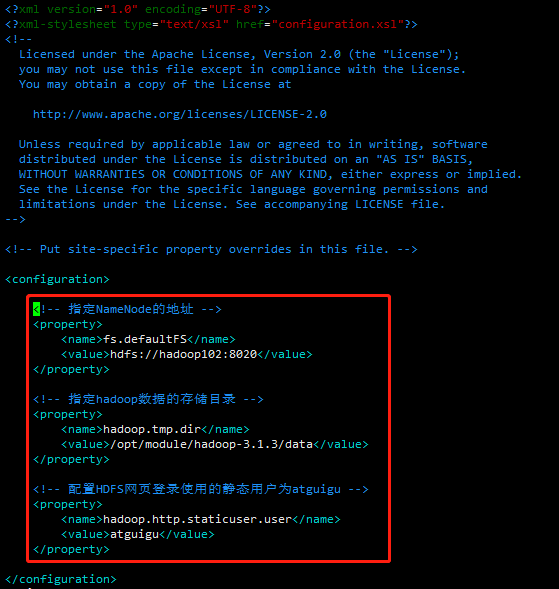
保存退出
(2)HDFS配置文件
配置hdfs-site.xml
vim hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> </configuration>
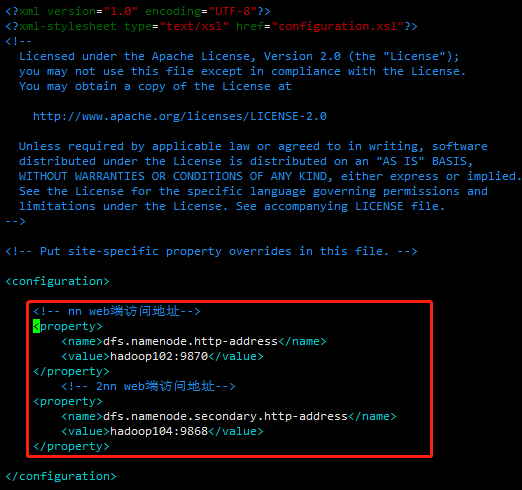
(3)YARN配置文件
配置yarn-site.xml
vim yarn-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
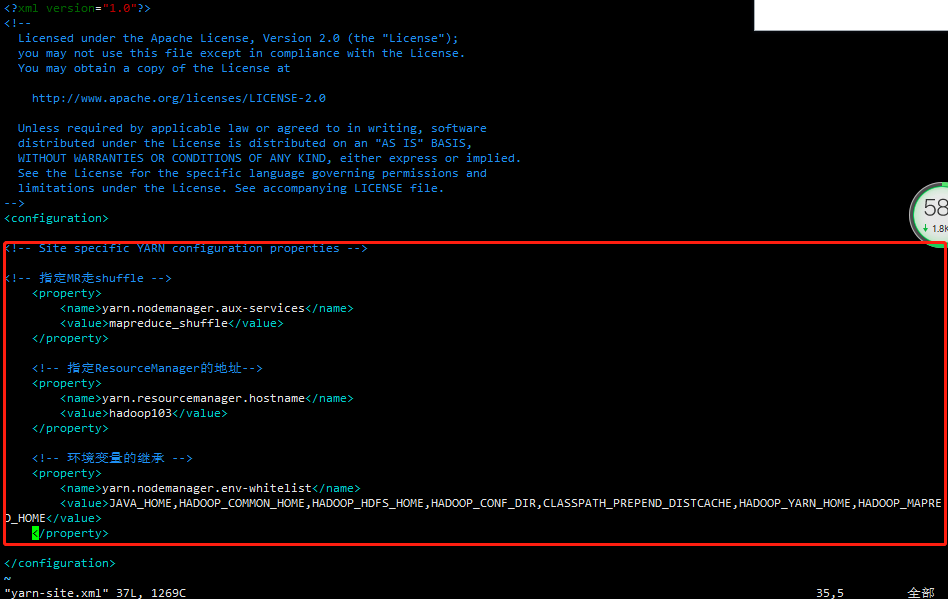
(4)MapReduce配置文件
配置mapred-site.xml
vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
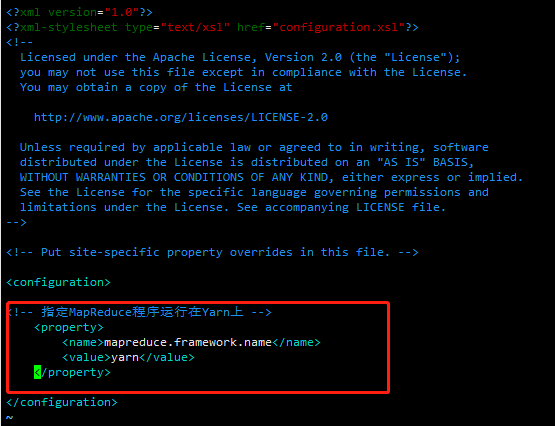
4、在集群上分发配置好的Hadoop配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
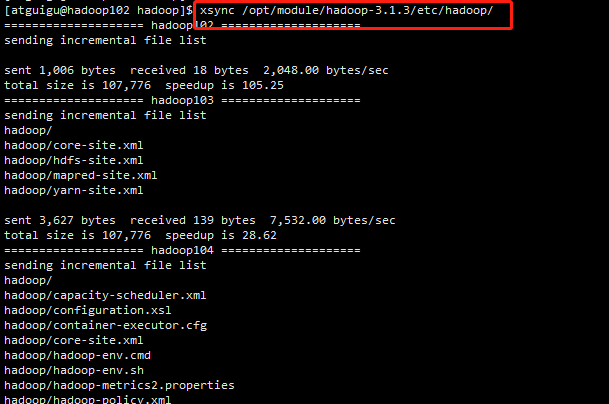
5、去103和104上查看文件分发情况
cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
目标:集起集群并测试
1、配置workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers

在该文件中增加如下内容(默认localhost删除掉):
hadoop102
hadoop103
hadoop104

注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
xsync /opt/module/hadoop-3.1.3/etc
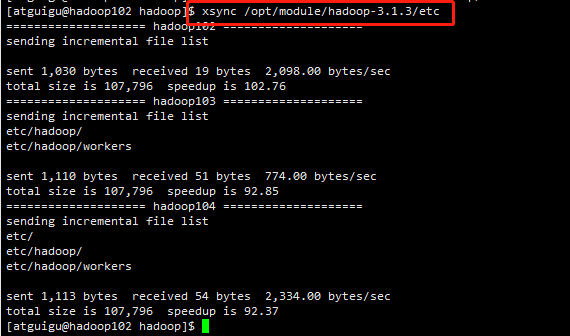
2、启动集群
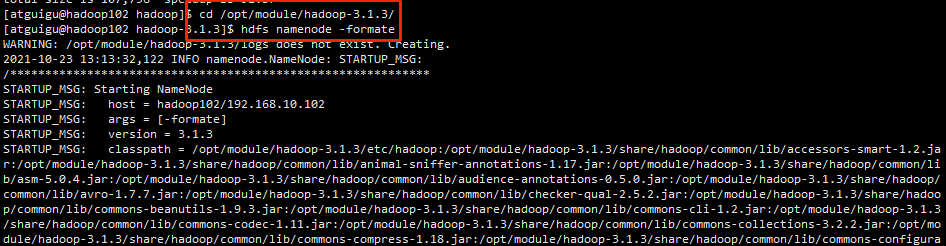
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
hdfs namenode -format
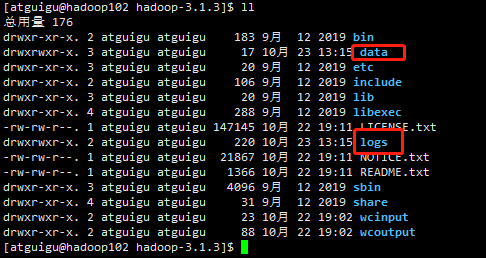
初始化完毕之后,发现多了data和log目录
(2)启动HDFS
sbin/start-dfs.sh

启动之后,hadoop102、hadoop103、hadoop104
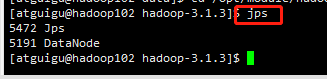
(3)在配置了ResourceManager的节点(hadoop103)启动YARN
sbin/start-yarn.sh
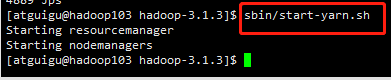
注意:一定要在hadoop103上启动
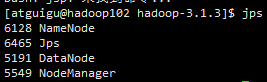
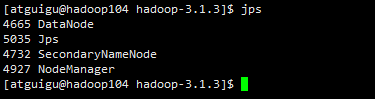
启动之后,
hadoop102
hadoop103
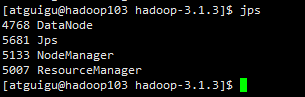
hadoop104
(4)Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息
(5)Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息
3、集群基本测试
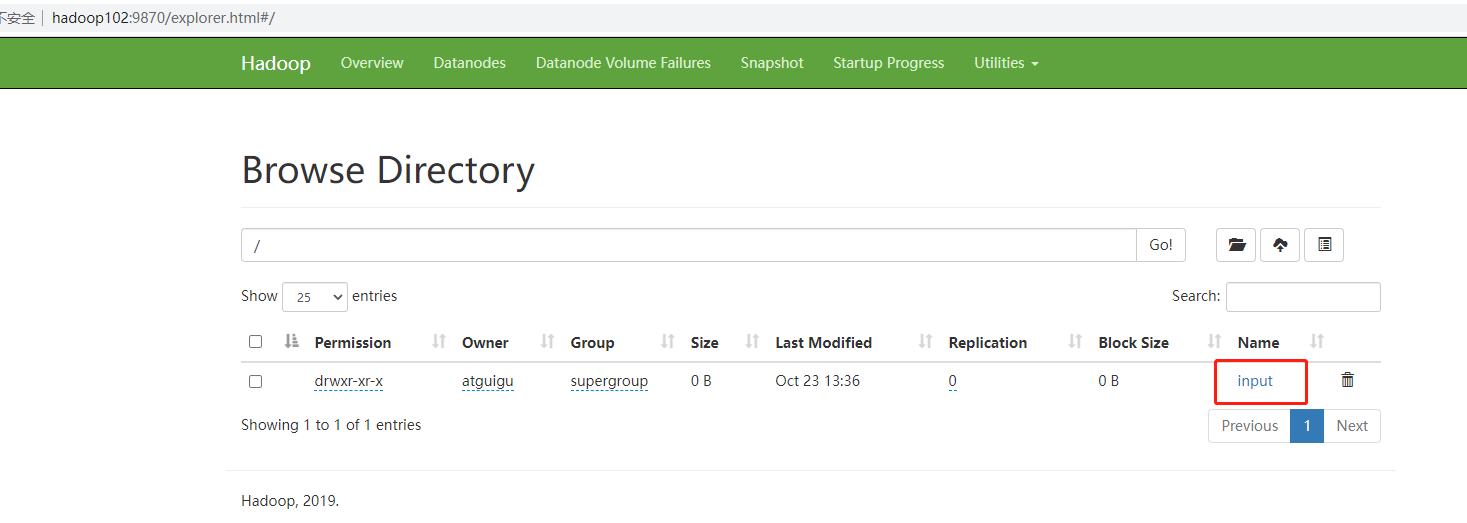
(1)上传文件到集群
- 上传小文件
cd
hadoop fs -mkdir /input
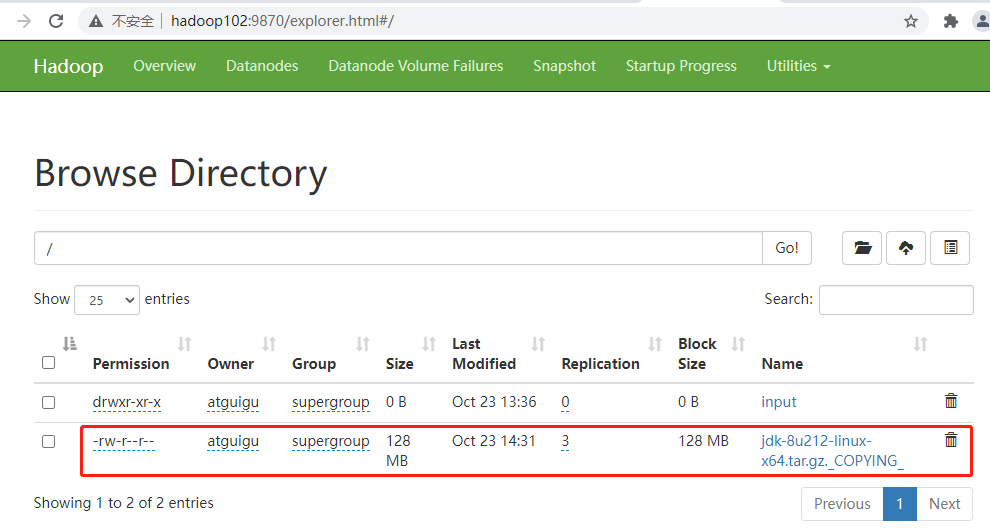
- 上传大文件
hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /

(2)上传文件后查看文件存放在什么位置
- 查看HDFS文件存储路径
cd /opt/module/hadoop-3.1.3/ ll cd data/ ll cd dfs/ ll cd data/ ll cd current/ ll cd BP-1475925467-192.168.10.102-1634967224222/ ll cd finalized/ ll cd subdir0/ ll
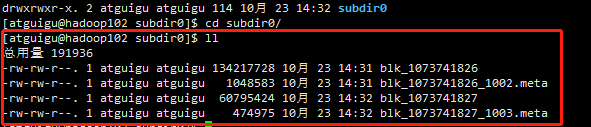

发现存储目录是
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1475925467-192.168.10.102-1634967224222/current/finalized/subdir0/subdir0
(3)拼接
cat blk_1073741826>>tmp.tar.gz cat blk_1073741827>>tmp.tar.gz ll

解压完毕
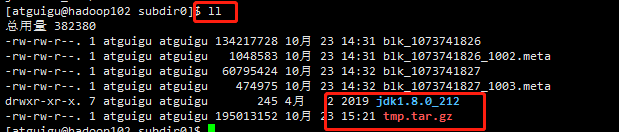
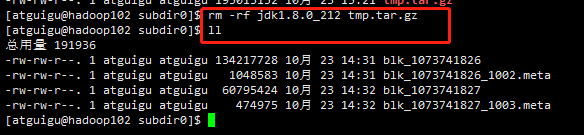
删除压缩文件和解压文件
目标:ZooKeeper 本地安装
本地模式安装
1、安装前准备
(1)安装JDK
(2) 拷贝apache-zookeeper-3.5.7-bin.tar.gz 安装包到 Linux 系统下
(3)解压到指定目录
cd /opt/software/ ll tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/


(4)修改名称
#切换目录 cd /opt/module #修改文件名称 mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7
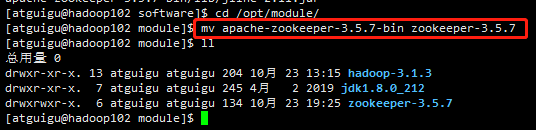
2、配置修改
(1)将/opt/module/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg;
cd /opt/module/zookeeper-3.5.7/conf/ mv zoo_sample.cfg zoo.cfg ll
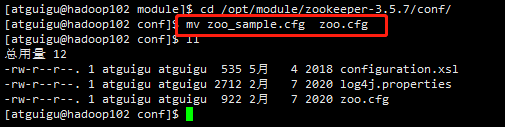
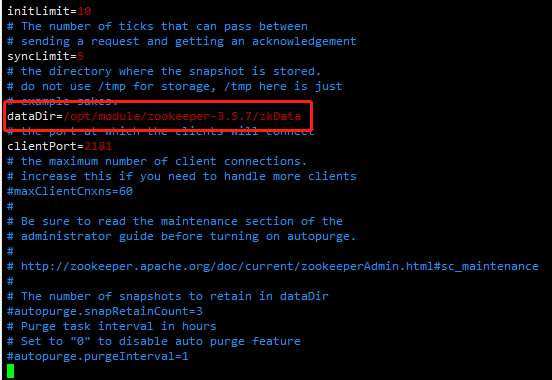
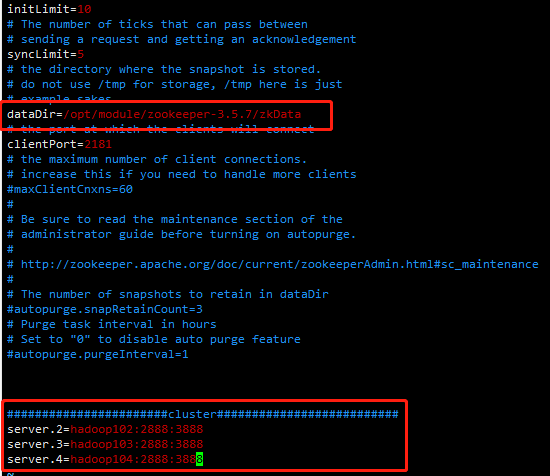
(2)打开 zoo.cfg 文件,修改 dataDir 路径:
vim zoo.cfg
dataDir=/opt/module/zookeeper-3.5.7/zkData
保存退出
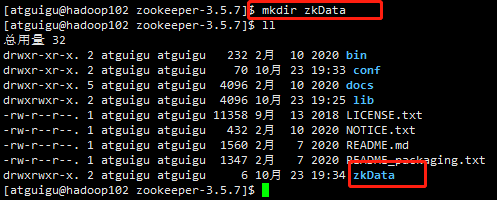
(3)在cd /opt/module/zookeeper-3.5.7/这个目录上创建zkData文件夹
mkdir zkData
ll
3、操作Zookeeper
(1)启动Zookeeper
bin/zkServer.sh start

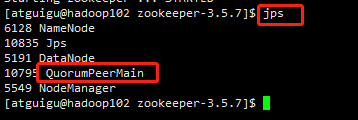
(2)查看进程是否启动
jps
(3)查看状态
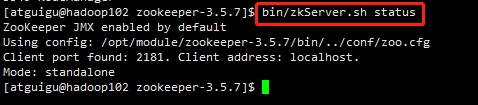
bin/zkServer.sh status
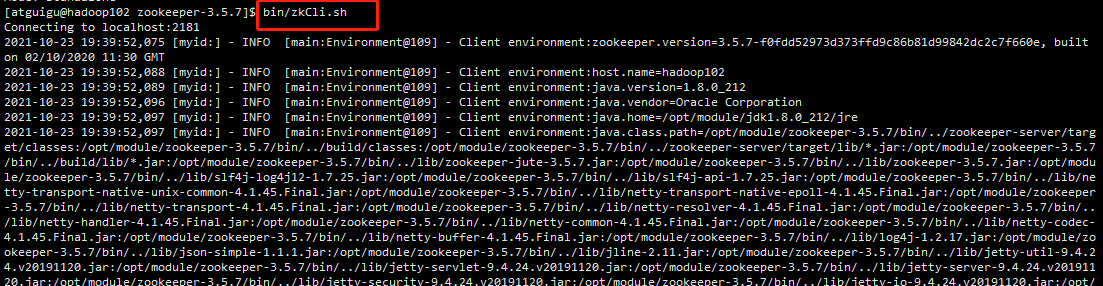
(4)启动客户端
bin/zkCli.sh

(5)退出客户端
quit

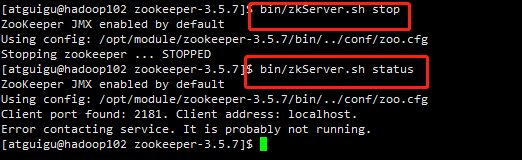
(6)停止Zookeeper
#停止ZooKeeper bin/zkServer.sh stop #查看状态 bin/zkServer.sh status
目标:ZooKeeper 集群安装
分布式安装部署
1、集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper
2、解压安装
(1)解压Zookeeper安装包到/opt/module/目录下
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
具体解压安装修改名称操作见本地安装模式,不再详细描述
(2)同步/opt/module/zookeeper-3.5.7目录内容到hadoop103、hadoop104
xsync zookeeper-3.5.7/
3、配置服务器编号
(1)在/opt/module/zookeeper-3.5.7/ 这个目录下创建zkData
mkdir -p zkData
由于我在单机本地安装模式已经操作过,这里就不演示了
(2)在/opt/module/zookeeper-3.5.7/zkData 目录下创建一个myid的文件,并编辑myid文件
注意:添加myid文件,注意一定要在Linux里面创建,在notepad++里面很可能乱码
cd /opt/module/zookeeper-3.5.7/ ll cd zkData/ vim myid
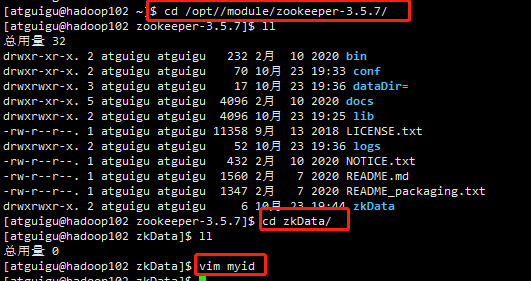
在文件中添加与server对应的编号:
2
(3)拷贝配置好的zookeeper到其他机器上
xsync myid
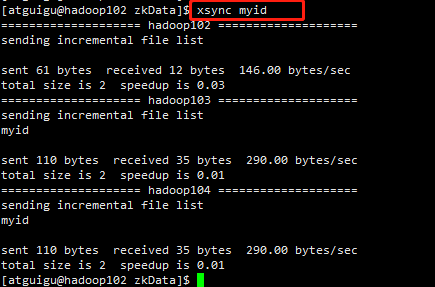
并分别在hadoop103、hadoop104上修改myid文件中内容为3、4


4、配置zoo.cfg文件
(1)将/opt/module/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg;
cd /opt/module/zookeeper-3.5.7/conf/
mv zoo_sample.cfg zoo.cfg
ll
注意,hadoop102的文件名称在单机本地安装模式的时候已经修改了
(2)打开 zoo.cfg 文件,修改 dataDir 路径:
vim zoo.cfg
dataDir=/opt/module/zookeeper-3.5.7/zkData
增加如下配置
#######################cluster########################## server.2=hadoop102:2888:3888 server.3=hadoop103:2888:3888 server.4=hadoop104:2888:3888
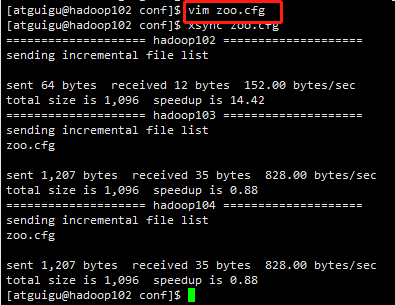
(3)同步zoo.cfg配置文件
xsync zoo.cfg
(4)配置参数解读
server.A=B:C:D
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server
B是这个服务器的地址;
C是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
5、集群操作
(1)分别启动ZooKeeper
bin/zkServer.sh start
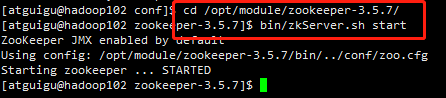
同样的方式,启动hadoop003、hadoop004
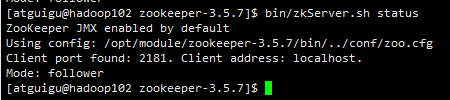
(2)查看状态
bin/zkServer.sh status

注意:如果hadoop003和hadoop004上的ZooKeeper 没启动就会显示上面的状态,当我们把hadoop003和hadoop004分别启动之后,结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号