京东后端实习一面(附详解),秒挂!
今天分享的是一位华中科技大学同学分享的京东一面面经,主要是一些非常基础的问题,也就是比较简单且容易准备的常规八股。

这也是这位同学人生的第一次面试,直接秒挂了。其实也挺正常,毕竟缺乏经验。对于 Java 后端实习面试来说,这位同学面试遇到的问题已经非常简单了。
很多同学觉得这种基础问题的考查意义不大,实际上还是很有意义的,这种基础性的知识在日常开发中也会需要经常用到。例如,线程池这块的拒绝策略、核心参数配置什么的,如果你不了解,实际项目中使用线程池可能就用的不是很明白,容易出现问题。而且,其实这种基础性的问题是最容易准备的,像各种底层原理、系统设计、场景题以及深挖你的项目这类才是最难的!
1、Redis 了解吗,作用?
Redis (REmote DIctionary Server)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 KV 键值对数据。
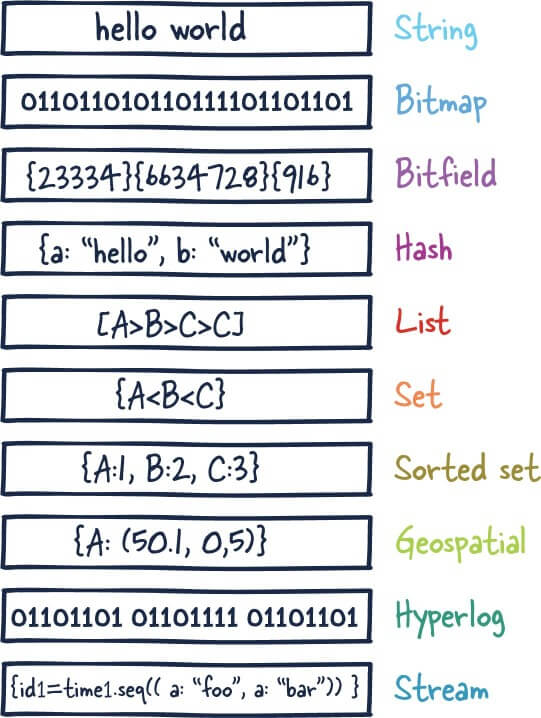
为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
- Redis 基于内存,内存的访问速度是磁盘的上千倍;
- Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
- Redis 内置了多种优化过后的数据类型/结构实现,性能非常高。
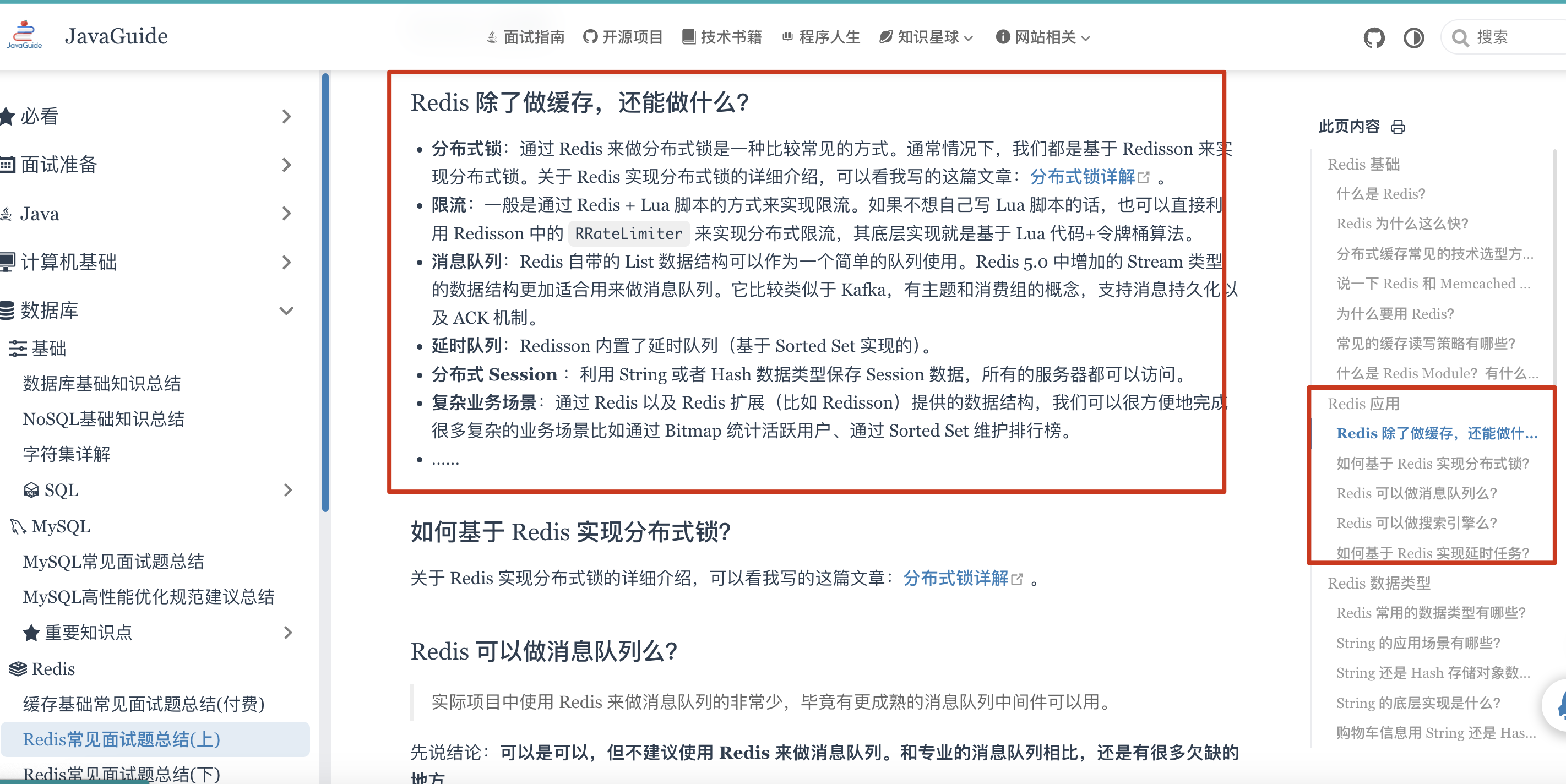
Redis 除了做缓存,还能做什么?
- 分布式锁:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:如何基于 Redis 实现分布式锁?。
- 限流:一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》。
- 消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- 延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
- 分布式 Session :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
- 复杂业务场景:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
- ……
详细介绍可以看这篇文章:Redis 除了缓存还能做什么?可以做消息队列吗? 。
2、Redis 数据结构有哪些?
Redis 中比较常见的数据类型有下面这些:
- 5 种基础数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
- 3 种特殊数据类型:HyperLogLog(基数统计)、Bitmap (位图)、Geospatial (地理位置)。
除了上面提到的之外,还有一些其他的比如 Bloom filter(布隆过滤器)、Bitfield(位域)。
关于 Redis 5 种基础数据类型和 3 种特殊数据类型的详细介绍请看 Redis 官方文档对 Redis 数据类型的介绍 和我写的这两篇文章:
3、同步和异步的区别
- 同步:发出一个调用之后,在没有得到结果之前, 该调用就不可以返回,一直等待。
- 异步:调用在发出之后,不用等待返回结果,该调用直接返回。
4、创建线程的方法哪些?
一般来说,创建线程有很多种方式,例如继承Thread类、实现Runnable接口、实现Callable接口、使用线程池、使用CompletableFuture类等等。
不过,这些方式其实并没有真正创建出线程。准确点来说,这些都属于是在 Java 代码中使用多线程的方法。
严格来说,Java 就只有一种方式可以创建线程,那就是通过new Thread().start()创建。不管是哪种方式,最终还是依赖于new Thread().start()。
关于这个问题的详细分析可以查看这篇文章:大家都说 Java 有三种创建线程的方式!并发编程中的惊天骗局!。
5、线程池作用是什么?
线程池提供了一种限制和管理资源(包括执行一个任务)的方式。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
这里借用《Java 并发编程的艺术》提到的来说一下使用线程池的好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 构造函数的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
Executors 返回线程池对象的弊端如下(后文会详细介绍到):
FixedThreadPool和SingleThreadExecutor:使用的是无界的LinkedBlockingQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。CachedThreadPool:使用的是同步队列SynchronousQueue, 允许创建的线程数量为Integer.MAX_VALUE,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM。ScheduledThreadPool和SingleThreadScheduledExecutor: 使用的无界的延迟阻塞队列DelayedWorkQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。
相关阅读:
6、Spring,Spring MVC,Spring Boot 之间什么关系?
很多人对 Spring,Spring MVC,Spring Boot 这三者傻傻分不清楚!这里简单介绍一下这三者,其实很简单,没有什么高深的东西。
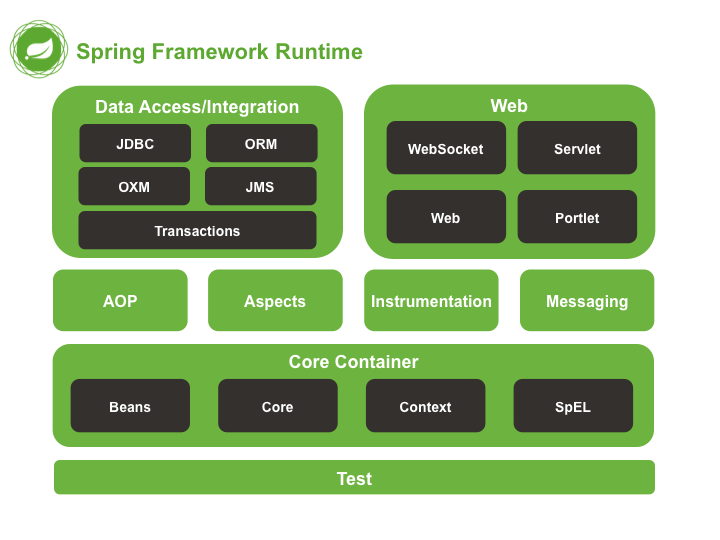
Spring 包含了多个功能模块(上面刚刚提到过),其中最重要的是 Spring-Core(主要提供 IoC 依赖注入功能的支持) 模块, Spring 中的其他模块(比如 Spring MVC)的功能实现基本都需要依赖于该模块。
下图对应的是 Spring4.x 版本。目前最新的 5.x 版本中 Web 模块的 Portlet 组件已经被废弃掉,同时增加了用于异步响应式处理的 WebFlux 组件。
Spring MVC 是 Spring 中的一个很重要的模块,主要赋予 Spring 快速构建 MVC 架构的 Web 程序的能力。MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。
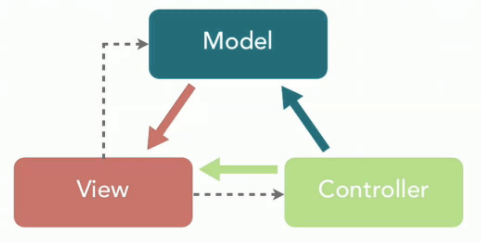
使用 Spring 进行开发各种配置过于麻烦比如开启某些 Spring 特性时,需要用 XML 或 Java 进行显式配置。于是,Spring Boot 诞生了!
Spring 旨在简化 J2EE 企业应用程序开发。Spring Boot 旨在简化 Spring 开发(减少配置文件,开箱即用!)。
Spring Boot 只是简化了配置,如果你需要构建 MVC 架构的 Web 程序,你还是需要使用 Spring MVC 作为 MVC 框架,只是说 Spring Boot 帮你简化了 Spring MVC 的很多配置,真正做到开箱即用!
7、IoC 和 AOP
IoC
IoC(Inversion of Control:控制反转) 是一种设计思想,而不是一个具体的技术实现。IoC 的思想就是将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理。不过, IoC 并非 Spring 特有,在其他语言中也有应用。
为什么叫控制反转?
- 控制:指的是对象创建(实例化、管理)的权力
- 反转:控制权交给外部环境(Spring 框架、IoC 容器)
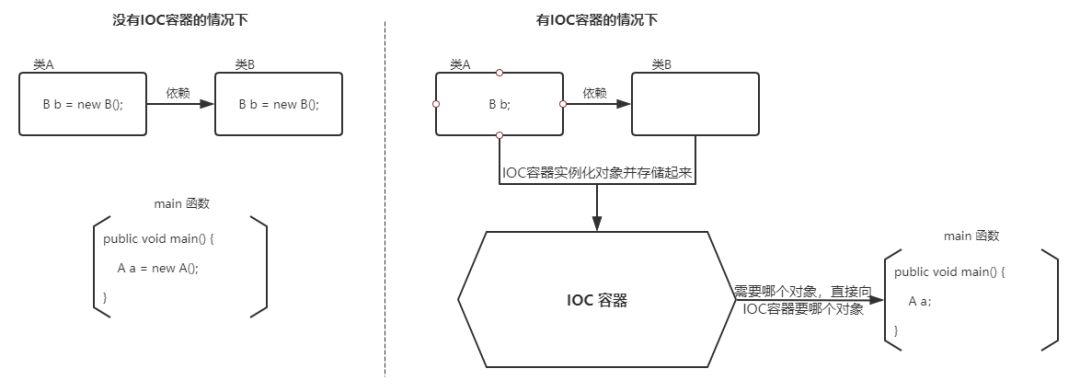
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。
在实际项目中一个 Service 类可能依赖了很多其他的类,假如我们需要实例化这个 Service,你可能要每次都要搞清这个 Service 所有底层类的构造函数,这可能会把人逼疯。如果利用 IoC 的话,你只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。
在 Spring 中, IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个 Map(key,value),Map 中存放的是各种对象。
Spring 时代我们一般通过 XML 文件来配置 Bean,后来开发人员觉得 XML 文件来配置不太好,于是 SpringBoot 注解配置就慢慢开始流行起来。
AOP
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:
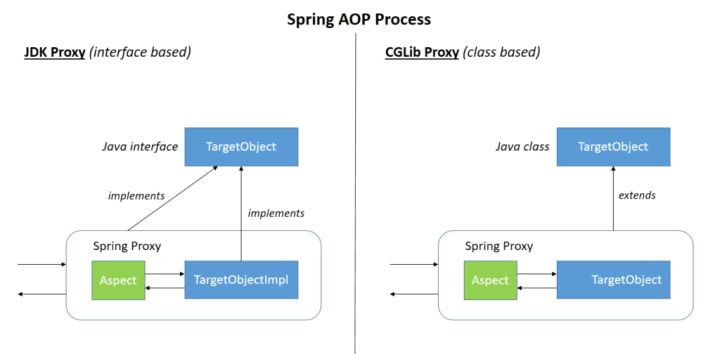
当然你也可以使用 AspectJ !Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
AOP 切面编程涉及到的一些专业术语:
| 术语 | 含义 |
|---|---|
| 目标(Target) | 被通知的对象 |
| 代理(Proxy) | 向目标对象应用通知之后创建的代理对象 |
| 连接点(JoinPoint) | 目标对象的所属类中,定义的所有方法均为连接点 |
| 切入点(Pointcut) | 被切面拦截 / 增强的连接点(切入点一定是连接点,连接点不一定是切入点) |
| 通知(Advice) | 增强的逻辑 / 代码,也即拦截到目标对象的连接点之后要做的事情 |
| 切面(Aspect) | 切入点(Pointcut)+通知(Advice) |
| Weaving(织入) | 将通知应用到目标对象,进而生成代理对象的过程动作 |
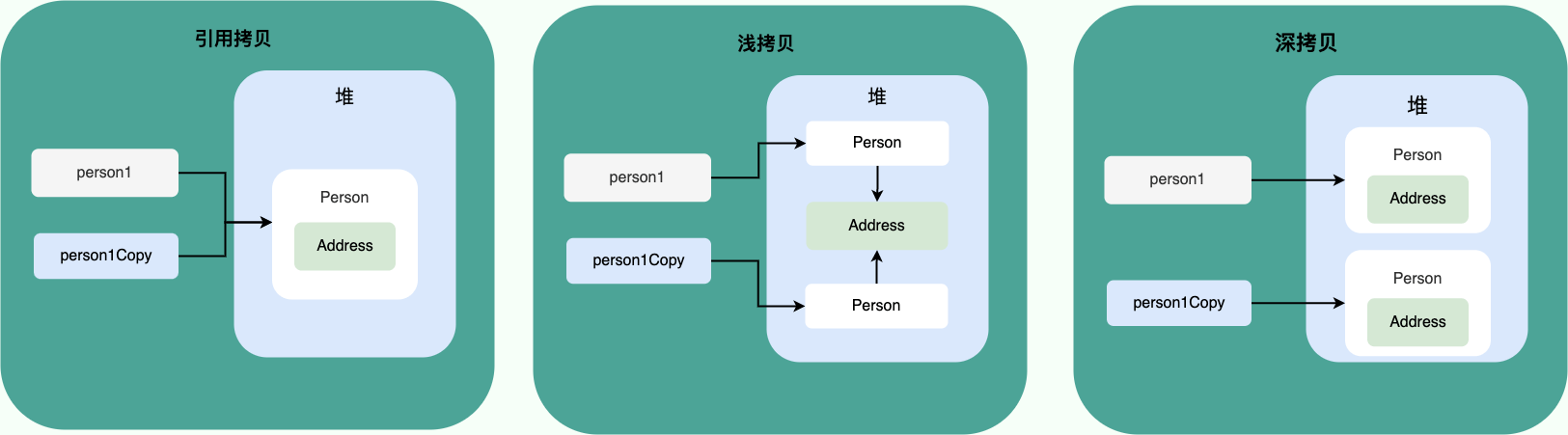
8、浅拷贝和深拷贝
关于深拷贝和浅拷贝区别,我这里先给结论:
- 浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
- 深拷贝:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
上面的结论没有完全理解的话也没关系,我们来看一个具体的案例!
浅拷贝
浅拷贝的示例代码如下,我们这里实现了 Cloneable 接口,并重写了 clone() 方法。
clone() 方法的实现很简单,直接调用的是父类 Object 的 clone() 方法。
public class Address implements Cloneable{
private String name;
// 省略构造函数、Getter&Setter方法
@Override
public Address clone() {
try {
return (Address) super.clone();
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
}
public class Person implements Cloneable {
private Address address;
// 省略构造函数、Getter&Setter方法
@Override
public Person clone() {
try {
Person person = (Person) super.clone();
return person;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
}
测试:
Person person1 = new Person(new Address("武汉"));
Person person1Copy = person1.clone();
// true
System.out.println(person1.getAddress() == person1Copy.getAddress());
从输出结构就可以看出, person1 的克隆对象和 person1 使用的仍然是同一个 Address 对象。
深拷贝
这里我们简单对 Person 类的 clone() 方法进行修改,连带着要把 Person 对象内部的 Address 对象一起复制。
@Override
public Person clone() {
try {
Person person = (Person) super.clone();
person.setAddress(person.getAddress().clone());
return person;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
测试:
Person person1 = new Person(new Address("武汉"));
Person person1Copy = person1.clone();
// false
System.out.println(person1.getAddress() == person1Copy.getAddress());
从输出结构就可以看出,显然 person1 的克隆对象和 person1 包含的 Address 对象已经是不同的了。
那什么是引用拷贝呢? 简单来说,引用拷贝就是两个不同的引用指向同一个对象。
我专门画了一张图来描述浅拷贝、深拷贝、引用拷贝:
9、List a, list b; a=b 是浅拷贝还是深拷贝,怎么才能深拷贝?
List a, list b; a=b 本质上来说应该属于是引用拷贝,也就是两个不同的引用指向同一个对象,即 a 和 b 都会指向同一个 List 对象。当你更改 b 时,a 也会相应地更改,反之亦然。
示例代码:
List<String> a = new ArrayList<>();
a.add("Element1");
a.add("Element2");
List<String> b = new ArrayList<>();
b.add("Element3");
a=b;
System.out.println(a.hashCode() == b.hashCode());
b.add("Element4");
System.out.println(a);
输出:
true
[Element3, Element4]
如果想要深拷贝的话,需要创建一个新的 List 对象,并将原始列表中的元素复制到新列表中。如果列表中的元素本身对象的话,还需要确保这些对象也被复制。
10、接口和抽象类的区别,抽象类的作用
接口和抽象类的共同点:
- 都不能被实例化。
- 都可以包含抽象方法。
- 都可以有默认实现的方法(Java 8 可以用
default关键字在接口中定义默认方法)。
接口和抽象类的区别:
- 接口主要用于对类的行为进行约束,你实现了某个接口就具有了对应的行为。抽象类主要用于代码复用,强调的是所属关系。
- 一个类只能继承一个类,但是可以实现多个接口。
- 接口中的成员变量只能是
public static final类型的,不能被修改且必须有初始值,而抽象类的成员变量默认 default,可在子类中被重新定义,也可被重新赋值。
抽象类的作用:
抽象类的作用主要是为子类提供一个共同的模板,定义了一些通用的方法和属性。子类可以继承抽象类拥有这些通用属性并按需实现或覆盖其中的方法。抽象类是面向对象编程中重要的概念,能够提高代码的复用性和可读性,同时也能够对类的继承进行限制。
11、String、StringBuffer、StringBuilder 的区别?
可变性
String 是不可变的。
StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串,不过没有使用 final 和 private 关键字修饰,最关键的是这个 AbstractStringBuilder 类还提供了很多修改字符串的方法比如 append 方法。
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
//...
}
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据: 适用
String - 单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder - 多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer
12、你项目中怎么向前端传数据的
后端向前端传数据的几种常用途径:
- RESTful API:使用 HTTP 请求进行数据交换,前端可以通过 GET、POST、PUT 等方法请求服务端数据或者发送数据到服务端。
- Websocket:提供全双工通信渠道,允许服务端和客户端之间进行实时数据传输。
- Server-Sent Events (SSE):允许服务端向客户端推送实时数据更新,通常用于单向通信,如推送通知。
这些方法各有优劣,选择哪种方式取决于应用的需求和特定场景。例如,需要实时双向通信可以选择 Websocket,只需要服务端向客户端推送数据可以选择 SSE,标准的客户端和服务端数据交换可以选择 RESTful API(这也是平时用的最频繁的)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号