

进程的描述和进程的创建
于佳心 原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
实验 分析一个Linux内核创建新进程的过程
首先,按照之前学过的方法,删除menu,并克隆一个新menu
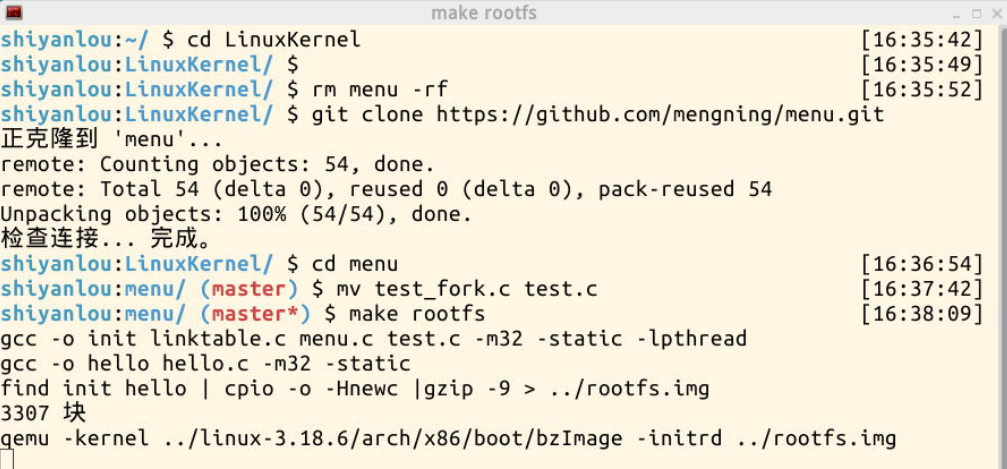
输入make rootfs之后

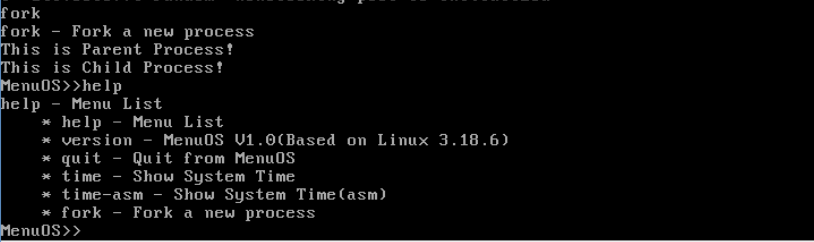
在qemu界面输入fork
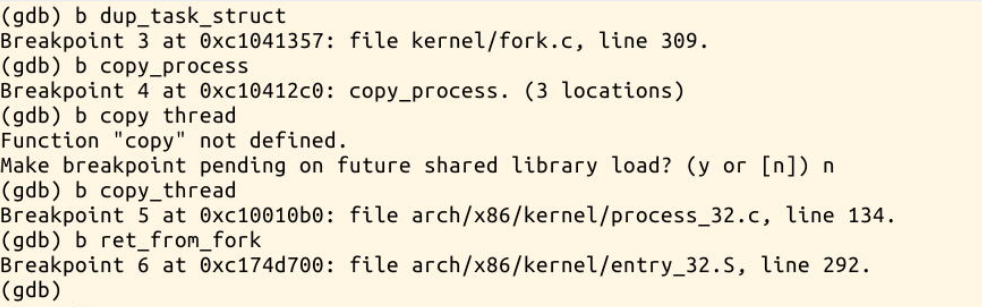
设置很多很多断点

在设置了一系列断点之后,开始一步一步的运行。
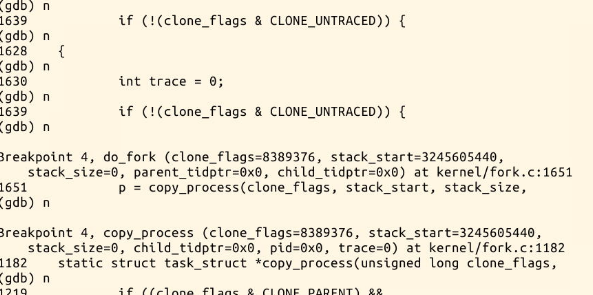
通过实验我们发现:
新进程开始的地方是ret_from_fork
在ret_from_fork之前,copy_thread()函数中
*childregs = *current_pt_regs();
父进程的regs参数赋值到子进程的内核堆栈中。
总结
一、进程的描述
操作系统有三大功能:进程管理、内存管理、文件系统,其中以进程管理为核心
操作系统有三个状态:操作态、运行态、阻塞态
但是在进程管理中不太一样,比如就绪状态和运行状态都是TASK_RUNNING
进程的状态变化如图:
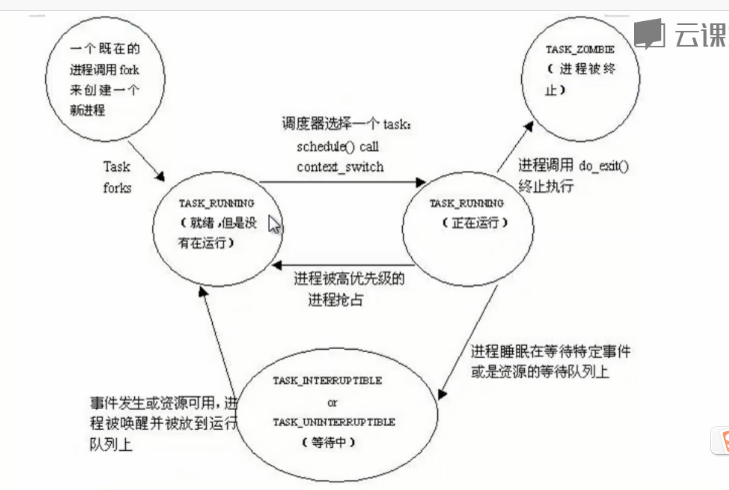
为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息。
-
struct task_struct数据结构很庞大
1235 struct task_struct {
1236 volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
1237 void *stack;
1238 atomic_t usage;
1239 unsigned int flags; /* per process flags, defined below */
1240 unsigned int ptrace;
state表示运行状态
stack 进程的内核堆栈
usage、flags 进程的标识符
1242 #ifdef CONFIG_SMP
1243 struct llist_node wake_entry;
1244 int on_cpu;
1245 struct task_struct *last_wakee;
1246 unsigned long wakee_flips;
1247 unsigned long wakee_flip_decay_ts;
1248
1249 int wake_cpu;
1250#endif
1251 int on_rq;
SMP是条件编译,多处理器会用到
rq 运行队列
后面又有一堆和优先级、调度相关的代码,我们先不管它们。
1301struct mm_struct *mm, *active_mm;
1302#ifdef CONFIG_COMPAT_BRK
1303 unsigned brk_randomized:1;
1304#endif
内存管理,进程的地址空间相关,代码段、数据段都要和它打交道
每个进程都有自己的进程地址空间
1356 struct list_head ptraced;
调试
struct pid_link pids[PIDTYPE_MAX];
哈希表,用于查找
1368 cputime_t utime, stime, utimescaled, stimescaled;
1369 cputime_t gtime;
1370#ifndef CONFIG_VIRT_CPU_ACCOUNTING_NATIVE
1371 struct cputime prev_cputime;
1372#endif
1373#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
1374 seqlock_t vtime_seqlock;
1375 unsigned long long vtime_snap;
1376 enum {
1377 VTIME_SLEEPING = 0,
1378 VTIME_USER,
1379 VTIME_SYS,
1380 } vtime_snap_whence;
1381#endif
时间相关
1420 struct signal_struct *signal;
1421 struct sighand_struct *sighand;
信号处理相关
1598 struct pipe_inode_info *splice_pipe;
管道相关
-
进程的标识符pid
1330 pid_t pid;
1331 pid_t tgid;
-
所有进程链表struct list_head tasks;
1361 struct list_head thread_group;
1362 struct list_head thread_node;
进程链表相关,把相关的进程链起来
-
内核的双向循环链表的实现方法 - 一个更简略的双向循环链表
1295struct list_head tasks;
1296#ifdef CONFIG_SMP
1297 struct plist_node pushable_tasks;
1298 struct rb_node pushable_dl_tasks;
1299#endif
这个结构就是双向循环的进程链表
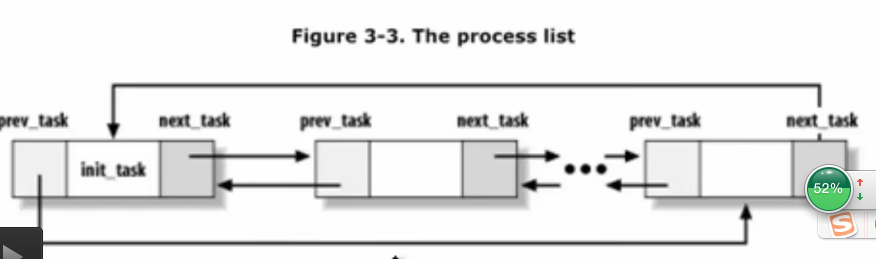
-
程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系
1342 struct task_struct __rcu *real_parent; /* real parent process */
1343 struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
1344 /*
1345 * children/sibling forms the list of my natural children
1346 */
1347 struct list_head children; /* list of my children */
1348 struct list_head sibling; /* linkage in my parent's children list */
1349 struct task_struct *group_leader; /* threadgroup leader */
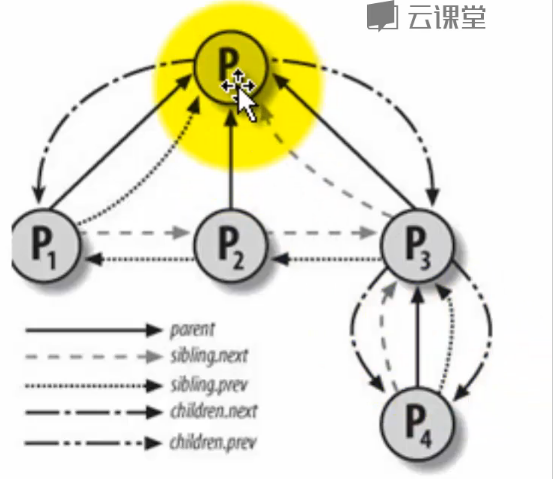
-
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
-
进程处于内核态时使用, 不同于用户态堆栈,即PCB中指定了内核栈
-
内核控制路径所用的堆栈 很少,因此对栈和Thread_info 来说,8KB足够了
-
struct thread_struct thread; //CPU-specific state of this task cpu相关,进行上下文切换
打开thread具体代码,其中有一个thread_struct,esp和eip就存在这里
-
文件系统和文件描述符
1414 struct fs_struct *fs;
文件相关,进程地址空间,内存管理空间
1416 struct files_struct *files;
打开的文件描述符列表
进程的创建
复习:
0号进程是我们自己写入的
1号进程复制0号进程的PCB,再加入可执行文件
1号进程是所有用户态进程的祖先
2号进程是所有内核线程的祖先
于是我们明白,进程的创建即是从父进程复制一份子进程,并做合理的修改
那么用shell命令行怎么创建一个子进程呢?
fork() 是在用户态用于创建一个子进程的系统调用
#include <stdio.h> #include <stdlib.h> #include <unistd.h>
int main(int argc, char * argv[]) { int pid; /* fork another process */ pid = fork(); if (pid < 0) { /* error occurred */ fprintf(stderr,"Fork Failed!"); exit(-1); } else if (pid == 0) { /* child process */ printf("This is Child Process!\n"); } else { /* parent process*/ printf("This is Parent Process!\n"); /* parent will wait for the child to complete*/ wait(NULL); printf("Child Complete!\n"); } }
如代码中的英文注释所说,当返回值<0时,出错处理,返回值==0时,子程序执行,这里需要注意的是,else后面的内容也一起执行
这是因为fork系统调用是在父进程和子进程各返回一次的
子程序的返回值是0,父进程的返回值是子进程的ID
系统调用的过程回顾:
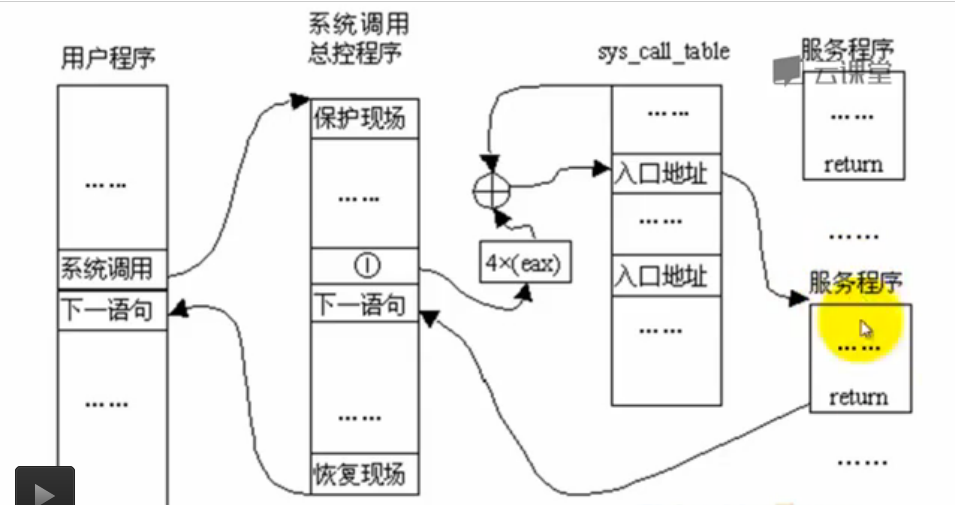
子进程是从哪里开始执行的?
在内核里开始执行,fork返回。新进程执行的起点是我们设立的。
理解复杂的事物要预设一个大致的框架。
创建进程框架:
创建新进程是通过复制当前进程来实现的,大多数地方都一样,但是父子进程的pid不一样,内核堆栈也不一样,thread也不一样
虚拟设想:
复制进程PCB,修改复制完的PCB,分配新的内核堆栈,内核堆栈的一部分也需要拷贝,根据状况设定eip、esp的位置
创建一个新进程在内核中的执行过程
-
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;
-
Linux通过复制父进程来创建一个新进程,那么这就给我们理解这一个过程提供一个想象的框架:
-
复制一个PCB——task_struct
err = arch_dup_task_struct(tsk, orig);
-
要给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node); tsk->stack = ti; setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈要修改复制过来的进程数据,比如pid、进程链表等等都要改改吧,见copy_process内部。
-
从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回,那它在系统调用处理过程中的哪里开始执行的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process
*childregs = *current_pt_regs(); //复制内核堆栈 childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因! p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶 p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址这一次的新内容好多,越来越难了,对代码的理解越来越吃力,不是老师讲的不好,但是我一听到代码的部分就快睡着了,宝宝心好累。
求高分!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号