
线程基础
线程基础
前言
最近由于在产品中出现了一些并发问题,因为业务需要,我负责的业务模块有不少是应对大数据量的操作,其中很多都是对java并发知识的应用,干IT这行的,困难重重,既然不能逃避,就只能去拿下它了
1、实现线程的方法
实现现场是并发编程中基础,因为必须要先实现多现场,才可以继续后续的一系列操作
实现线程方式:
-
实现Runnable接口
以下这种通过Runnable实现线程创建,如下代码所示,首先通过RunnableClass类实现Runnable接口,然后重写run()方法,之后需要吧这个实现了run()方法的实例传到Thread类中实现多线程。
public class RunnableClass implements Runnable{ @Override public void run() { System.out.println("使用Runnable接口实现线程创建"); } } -
继承Thread类
以下这种实现与第一种差不多,也是我们经常使用的俩种创建方式
public class ExtendsClass extends Thread{ @Override public void run() { System.out.println("用Thred类实现线程创建"); } } -
线程池创建
通过线程池创建现场。线程池确实实现了多线程。接下来我们看一下线程池的源码:
对于线程池而言,本质是通过线程工厂创建线程的,它会给线程设置一些默认值,比如:名字,线程优先级等,最终还是通过new Thread()创建线程的
-
有返回值的Callable创建线程
-
其他创建线程的方式
- 定时器
-
实现线程只有一种方式
实现原理:首先,启动线程需要调用start()方法,而最终还会调用run()
- Runnable
- Thread
-
实现Runnable接口比继承Thread类实现线程要好
- 首先,从代码的架构层面上考虑,实际上,Runnable里只有一个run()方法,它定义了需要执行的内容,在这种情况下,实现了Runnable与Thread类的解耦,Thread类负责线程启动和属性设置等内容,权责分明
- 在某些情况下可以提高性能,使用继承Thread类方式,每次执行一次任务,都需要新建一个独立的线程,执行完任务后线程走到生命周期的尽头被销毁,如果还想执行这个任务,就必须在新建一个继承了Thread类的类,如果此时执行的内容较少,那么此时真正执行任务的开销要比线程的创建到销毁流程的开销小的多,得不偿失。而Runnable接口方式,可以吧任务直接传入到线程池,使用线程池来完成
- 从java语言的特性上来说,它不支持双继承,不利于线程业务类实现其他的扩展需求
2、线程停止与线程标记
通常情况下,我们不会手动停止线程,而是运行到自然结束,但有时候需要提前停止线程:比如用户关闭线程,或运算出错等
这种情况下,即将停止的线程在很多业务场景下仍然有价值,尤其在一个健壮性很好,能够安全应对各种场景的程序时,正确停止线程显得格外重要。但java并没有提供简单易用,能直接安全停止线程的努力
为什么线程不强制停止
对于java而言,最正确的停止线程的方式是使用interrupt。但interrupt仅仅起到通知被停止线程的作用,而对呗停止的线程而言,它拥有完全的自主权,它既可以选择立即停止,也可以选择一段时间后停止,也可以选择压根不停止。
事实上,java希望程序间能够相互通知、相互协作地管理线程,因为如果不了解对方正在做的工作,贸然强制停止线程,就可能造成一些安全的问题,为了避免造成问题,就需要给对方一定时间来整理收尾工作
如何用interrupt停止线程
while(!Thread.currentThread().isInterrupted() && more work to do){
do more work
}
明白java停止线程的设计原理之后,我们看看如何用代码实现停止线程的逻辑。我们一旦调用某个线程的interrupt()之后,这个线程的中断标记位就会被设置成true,每个线程都有这样的标记位,当线程执行时,应该定期检查这个标记位,如果标记位被设置成true,就说明有程序向终止该线程。回到源码,可以看到while循环体判断语句中,首先通过Thread.currentThread().isInterrupt()判断宣传是否被中断,随后检查师傅还有工作要做。&& 逻辑表示只有当俩个条件同时满足才会执行下面的工作
public class StopThread implements Runnable{
@Override
public void run() {
int count = 0;
while (!Thread.currentThread().isInterrupted() && count < 1000){
System.out.println("count = " + count++);
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new StopThread());
thread.start();
Thread.sleep(500);
thread.interrupt();
}
}
sleep期间是否感受到中断
Runnable runnable=()->{
int num = 0;
try{
while (!Thread.currentThread().isInterrupted() && num <= 1000){
System.out.println(num);
num++;
Thread.sleep(1000000);
}
}catch (Exception e){
e.printStackTrace();
}
};
我们考虑一个特殊情况,改下上面的代码,如果线程执行任务期间有休眠需求,也就是每打印一个数字,就进入一次sleep,而此时Thread.sleep()的休眠时间设置为1000秒
Runnable runnable=()->{
int num = 0;
try{
while (!Thread.currentThread().isInterrupted() && num <= 1000){
System.out.println(num);
num++;
Thread.sleep(1000000);
}
}catch (Exception e){
e.printStackTrace();
}
};
Thread thread = new Thread(runnable);
thread.start();
Thread.sleep(5);
thread.interrupt();
运行后
0
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at com.wan.thread.StopThread.lambda$main$0(StopThread.java:24)
at java.lang.Thread.run(Thread.java:748)
若sleep,wait等可以让线程进入阻塞的方法使线程休眠了,而处于休眠中的线程被中断,那么线程可以感受到中断信号,并且抛出一个InterruptedException异常,同时清除中断信号,将中断标记位设置成false
如何争取处理线程中断
-
run()中强制try/catch
方法签名异常,run()中强制try/catch,要求每一个方法的调用方有义务去处理异常,调用方不使用try/catch并在catch中正确处理异常,要不将异常声明到方法签名中,如果每层逻辑都准守规范,便可以将中断信号层层传递到顶层,最终让run()方法捕获异常,而对run()方法来说,他本身没有抛出checkedException的能力,只能通过try/catch来处理异常,层层传递异常的逻辑保障了异常不会被遗漏,而对run()而言,就可以根据不同的业务逻辑来进行相应的异常处理
-
再次中断
private void reInterrupt(){ try { Thread.sleep(10000); }catch (InterruptedException e){ Thread.currentThread().interrupt(); e.printStackTrace(); } } -
线程停止
-
错误的停止线程方法:stop(),suspend(),resume()
-
volatile修饰标记位适用的场景
public class VolatileCanStop implements Runnable{ private volatile boolean canceled = false; @Override public void run() { int num = 0; try { while (!canceled && num <= 1000000){ if (num % 10 == 0){ System.out.println(num + " 是10的倍数"); } num++; Thread.sleep(1); } } catch (InterruptedException e) { e.printStackTrace(); } } } -
volatile修饰标记位不适用的场景
生产者:
public class Producer implements Runnable{ public volatile boolean canceled = false; ArrayBlockingQueue storage; public Producer(ArrayBlockingQueue storage){ this.storage = storage; } @Override public void run() { int num = 0; try { while (num <= 100000 && !canceled){ if(num % 50 == 0){ storage.put(num); System.out.println(num + "是50的倍数,被放到仓库中了。"); } num++; } }catch (InterruptedException e){ e.printStackTrace(); }finally { System.out.println("生产者结束运行"); } } }消费者:
public class Consumer { ArrayBlockingQueue storage; public Consumer(ArrayBlockingQueue storage) { this.storage = storage; } public boolean needMoreNums(){ if(Math.random() > 0.97){ return false; } return true; } }调用方:
public static void main(String[] args) throws InterruptedException { ArrayBlockingQueue storage = new ArrayBlockingQueue(8); Producer producer = new Producer(storage); Thread producerThread = new Thread(producer); producerThread.start(); Thread.sleep(500); Consumer consumer = new Consumer(storage); while (consumer.needMoreNums()){ System.out.println(consumer.storage.take() + "被消费了"); Thread.sleep(100); } System.out.println("消费者完成消费后,不需要消费数据"); //不需要消费后,需停止生产者生产数据 producer.canceled = true; System.out.println(producer.canceled); }输出结果截取:
2000是50的倍数,被放到仓库中了。
1650被消费了
2050是50的倍数,被放到仓库中了。
1700被消费了
2100是50的倍数,被放到仓库中了。
1750被消费了
2150是50的倍数,被放到仓库中了。
消费者完成消费后,不需要消费数据
true以经常使用的生产者/消费者模式为例,可以看到上面的运行过程,消费则完成消费后,通过valatile关键字去停止生产者生产数据,但没停止掉,原因是由于公用仓库:ArrayBlockingQueue是阻塞队列,所以生产者实际上是阻塞在storage.put(num);这步,它被叫醒之前是无法进行判断标记位的,所以需要使用interrupt语句来中断线程
-
3、线程状态
-
线程的6种状态
- new(新创建)
- Runnable(可运行)
- Blocked(被阻塞)
- waiting(等待)
- Timed Waiting(计时等待)
- Terminated(被终止)
可通过getState()方法查询线程状态
4、wait/notify/nottifyall
-
为什么wait必须在synchronized保护的同步代码中使用
若wait方法没有在synchronized保护中,那他的条件与等待就无法构成原子操作,后续的唤醒可能会被错过,程序就很容易出错,若有了synchronized保护,则程序是原子性的,提高了程序的安全性,并避免了虚假唤醒问题
-
为什么 wait/notify/notifyAll 被定义在 Object 类中,而 sleep 定义在 Thread 类中?
- 因为 Java 中每个对象都有一把称之为 monitor 监视器的锁,由于每个对象都可以上锁,这就要求在对象头中有一个用来保存锁信息的位置。这个锁是对象级别的,而非线程级别的,wait/notify/notifyAll 也都是锁级别的操作,它们的锁属于对象,所以把它们定义在 Object 类中是最合适,因为 Object 类是所有对象的父类。
- 因为如果把 wait/notify/notifyAll 方法定义在 Thread 类中,会带来很大的局限性,比如一个线程可能持有多把锁,以便实现相互配合的复杂逻辑,假设此时 wait 方法定义在 Thread 类中,如何实现让一个线程持有多把锁呢?又如何明确线程等待的是哪把锁呢?既然我们是让当前线程去等待某个对象的锁,自然应该通过操作对象来实现,而不是操作线程
-
wait/notify 和 sleep 方法的异同?
相同点:
- 它们都可以让线程阻塞。
- 它们都可以响应 interrupt 中断:在等待的过程中如果收到中断信号,都可以进行响应,并抛出 InterruptedException 异常。
不同点:
- wait 方法必须在 synchronized 保护的代码中使用,而 sleep 方法并没有这个要求
- 在同步代码中执行 sleep 方法时,并不会释放 monitor 锁,但执行 wait 方法时会主动释放 monitor 锁
- sleep 方法中会要求必须定义一个时间,时间到期后会主动恢复,而对于没有参数的 wait 方法而言,意味着永久等待,直到被中断或被唤醒才能恢复,它并不会主动恢复
- wait/notify 是 Object 类的方法,而 sleep 是 Thread 类的方法
5、生产者/消费者模式
生产者消费者模式是程序设计中很常见的一种设计模式,现实世界中,我们吧生产商一方称为生产者,消费商品称为消费者。
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力
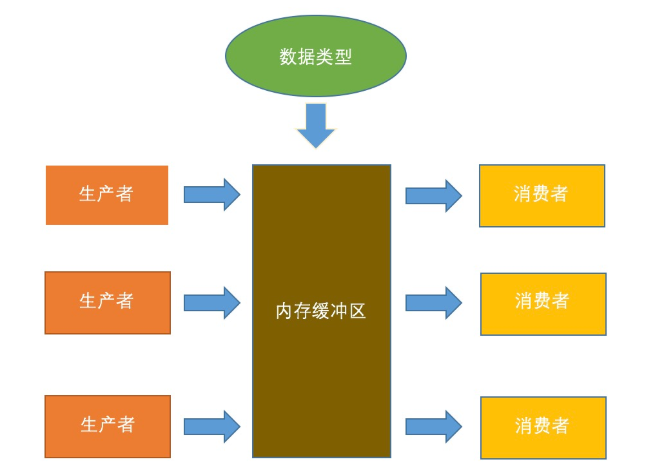
-
使用BlockingQueue实现生产者消费者模式
public static void main(String[] args) { BlockingDeque<Object> queue = new ArrayBlockingQueue<>(10); Runnable producer = () ->{ while (true){ try { queue.put(new Object()); } catch (InterruptedException e) { e.printStackTrace(); } } }; new Thread(producer).start(); new Thread(producer).start(); Runnable consumer = () ->{ while (true){ try { queue.take(); } catch (InterruptedException e) { e.printStackTrace(); } } }; new Thread(consumer).start(); new Thread(consumer).start(); }- 创建一个ArrayBlockingQueue类型的阻塞队列,容量设置为10
- 创建一个简单的生产者,循环往队列添加数据
- 启动生产者线程
- 消费者也是如此
- 阻塞队列功能:队列满了就去阻塞生产者线程,队列有空就唤醒生产者线程
-
Condition实现生产者消费者模式
public class MyBlockingQueueForCondition { private Queue queue; private int max = 16; private ReentrantLock lock = new ReentrantLock(); private Condition notEmpty = lock.newCondition(); private Condition notFull = lock.newCondition(); public MyBlockingQueueForCondition(int size) { this.max = size; queue = new LinkedList(); } public void put(Object o) throws InterruptedException { lock.lock(); try { while (queue.size() == max){ notFull.await(); } queue.add(o); notEmpty.signalAll(); }finally { lock.unlock(); } } public Object take() throws InterruptedException { lock.lock(); try { while (queue.size() == 0){ notEmpty.await(); } Object remove = queue.remove(); notFull.signalAll(); return remove; }finally { lock.unlock(); } } }- 定义一个queue最大容量为16的队列
- 定义一个ReentrantLock类型的lock锁,并在锁的基础上创建俩个Condition,一个是notEmpty代表列队没有空条件,一个是notFull没有满条件
- 由于是多线程场景,所以需要同步措施来保障线程安全,所以put和get方法都用lock锁上,然后while条件里检查queue是不是已经满了,如果已经满了,则调用notFull的await方法来阻塞生产者线程并释放锁,如果没满,则往队列里放,并利用notEmpty.singnalAll通知等待的所有消费则并且唤醒他们,最后在finally中解锁
- 注意,while和条件最好不要分开用,防止俩个队列同时进来时产生异常
-
使用wait/notify实现生产者消费者模型
public class MyBlockingQueue { private int max; private LinkedList<Object> storage; public MyBlockingQueue(int max) { this.max = max; storage = new LinkedList<>(); } public synchronized void put() throws InterruptedException { while (storage.size() == max){ wait(); } storage.add(new Object()); notifyAll(); } public synchronized void get() throws InterruptedException { while (storage.size() == 0){ wait(); } System.out.println(storage.remove()); notifyAll(); } }实现与Condition类似

 浙公网安备 33010602011771号
浙公网安备 33010602011771号