spark 集群搭建
其实都是相似的!网上的我不知道,我只保证我写的都是我自己亲自运行过的,可以正常使用的!
1.http://spark.apache.org/downloads.html 下载地址
2.环境 jdk 免密登录这些就不说了,这些还不会,下面也不要看了!浪费你个人时间~
我下载的:spark-1.6.1-bin-hadoop2.6.tgz
1.解压
2.到conf下面
mv spark-env.sh.template spark-env.sh
vi spark-env.sh
添加:
export JAVA_HOME=/usr/local/jvm/jdk1.8.0_11
export SPARK_MASTER_IP=v1
export SPARK_MASTER_PORT=7077
然后在编辑下
mv slaves.template slaves
vi slaves
在该文件中添加子节点所在的位置(Worker节点)
v2
v3
保存退出
把修改好的分发到其他机器上去
scp -r ......
主 上面启动:
start-all.sh
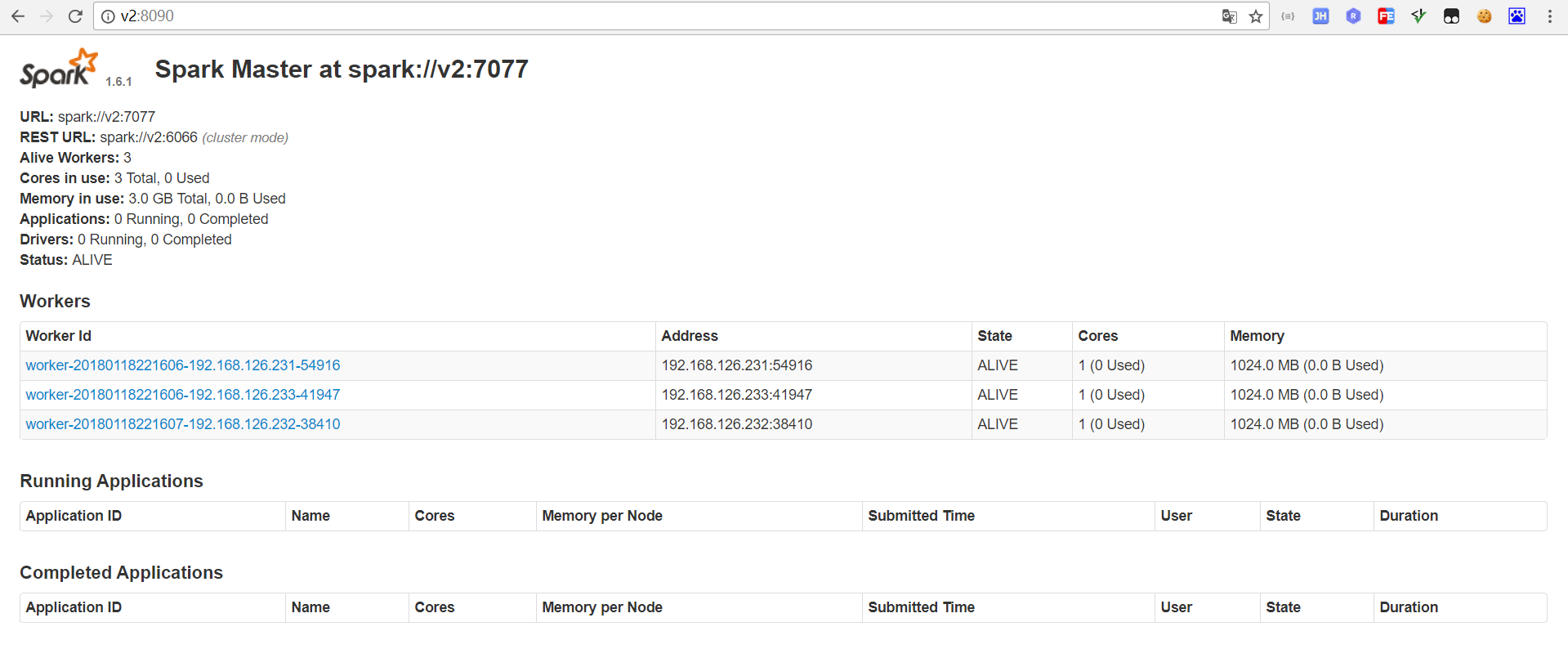
页面管理界面 v1:8080
其实有个问题就是,很多ui的管理界面端口都是8080。例如storm 也是8080 ,修改下
我是直接修改了默认值。2种修改方法,一个是在spark-env.sh 中配置,
还有一个是
vi start-master.sh
定位到下面部分内容:
if [ "$SPARK_MASTER_WEBUI_PORT" = "" ]; then
SPARK_MASTER_WEBUI_PORT=8080
fi
然后修改下,随便你自己改 不冲突就好了
starting org.apache.spark.deploy.master.Master, logging to /usr/local/app/spark-1.6.1/logs/spark-root-org.apache.spark.deploy.master.Master-1-v1.out
v3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/app/spark-1.6.1/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-v3.out
v2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/app/spark-1.6.1/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-v2.out
上面是日志, 然后Jps 看下 ,master worker 至此,最简单的spark 集群就完事了,
不是这样就完事了,至少你能觉得 单主要是挂了,那这集群怎么办?? 是不是全部就完蛋了,
结合zk 多主,备用 ,上面集群 做如下修改 ,保证高可用!
停止spark所有服务,修改配置文件spark-env.sh,在该配置文件中删掉SPARK_MASTER_IP并添加如下配置
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk1,zk2,zk3 -Dspark.deploy.zookeeper.dir=/spark"
1.在node1节点上修改slaves配置文件内容指定worker节点
2.在node1上执行sbin/start-all.sh脚本,然后在node2上执行sbin/start-master.sh启动第二个Master
我测试了。,kill 掉node1 时候 。大约几秒后会切换到node2 中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号