
一致性Hash算法原理(手写Hash算法,通俗易懂)
一致性Hash算法应用场景
请求的负载均衡:比如Nginx的ip_hash策略,通过对IP的Hash值来额定将请求转发到哪台Tomcat
分布式存储:比如分布式集群架构Redis、Hadoop、ElasticSearch、Mysql分库分表,数据存入哪台服务器,就可以通过Hash算法来确定
普通Hash算法存在的问题
如果服务器减少或者增多,所有客户端都需要进行重新Hash,然后进行分配。
一致性Hash算法

一条直线上有0到2^32-1,这些正整数。然后我们将其头尾相接,变成一个圆环形成闭环(Hash环)
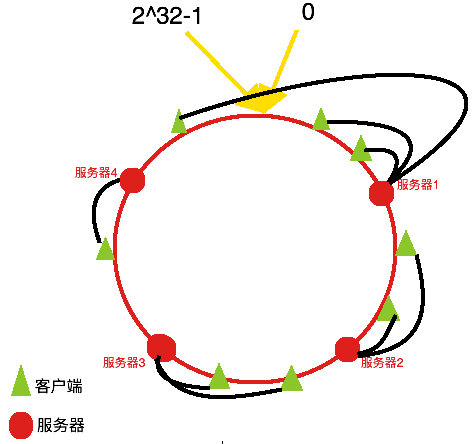
我们以Nginx的ip_hash分发请求为例说明一致性Hash算法:
对服务器的IP进行hash算法,获取Hash值,然后放到Hash闭环对应位置上;
通过对客户端的IP进行Hash算法获取Hash值,然后顺时针查找距离该Hash最近的服务器,并将请求转发到该服务器。
这样的话服务器进行扩展或者缩减后,比如缩减了一台服务器3,那么服务器3和服务器2之间的请求会被转发到服务器4上,而其他的请求不会受到影响,这就是一致性Hash的好处,将影响程度减小。
PS:这种方式有一个问题
假如就两台服务器,通过Hash算法后位置如下:
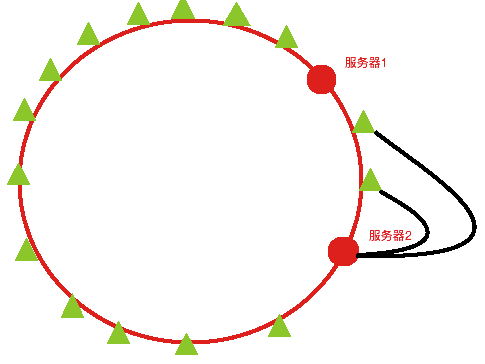
服务器1-服务器2之间的客户端请求都转发到了服务器2上,然而其他大量请求都转发到了服务器1上,这就导致服务器1压力过大,这种问题叫做数据倾斜问题。
数据倾斜问题解决
一致性Hash算法引入了虚拟节点机制
具体做法是在服务器IP或者主机名后面增加编号来实现。比如可以为每台服务器计算是哪个虚拟节点,于是可以分别计算“服务器1IP#1,服务器2IP#2,服务器1IP#3,服务器2IP#1,服务器2IP#2,服务器2IP#3”的哈希值,于是形成了6个虚拟节点,如下图
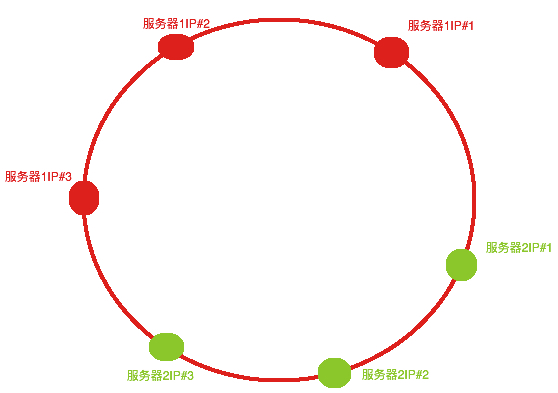
这样的话客户端经过Hash算法后就会被更加均匀的分布在Hash闭环上,请求也会被更加均匀的分发在各个服务器上,从而解决了数据倾斜问题
普通Hash算法代码实现
package com.lagou; /** * @ClassName: GeneralHash * @Description: 普通Hash算法 * @Author: qjc * @Date: 2021/9/7 6:25 下午 */ public class GeneralHash { public static void main(String[] args) { // 客户端IP集合 String[] clientList = new String[]{"127.1.1.1", "127.1.1.2", "127.1.1.3"}; // 服务器数量 int serverCount = 5; // 通过Hash算法,获取hash值,路由到服务器。hash(ip)%serverCount for (String clientIP : clientList) { int index = Math.abs(clientIP.hashCode()) % serverCount; System.err.println("客户端:" + clientIP + ",对应服务器:" + index); } } }
结果如下

这样有个问题,如果服务器减少或者增加,对请求的转发影响都会特别大
一致性Hash算法代码实现
package com.lagou; import java.util.HashMap; import java.util.Map; import java.util.SortedMap; import java.util.TreeMap; /** * @ClassName: ConsistentHash * @Description: 一致性Hash算法 * @Author: qjc * @Date: 2021/9/7 6:32 下午 */ public class ConsistentHash { public static void main(String[] args) { // 服务端IP集合 String[] serverList = new String[]{"127.0.0.1", "127.0.0.4", "127.0.0.7"}; // 然后将服务端IP进行Hash然后存储到map中,想象成一个闭环 SortedMap<Integer, String> serverHashMap = new TreeMap<>(); for (int i = 0; i < serverList.length; i++) { String serverIP = serverList[i]; // Hash值我们用IP的最后一位代替,这是为了测试 int serverHash = Integer.valueOf(serverIP.split("\\.")[3]); serverHashMap.put(serverHash, serverIP); } // 客户端IP集合 String[] clientList = new String[]{"127.1.1.1", "127.1.1.2", "127.1.1.3", "127.1.1.4", "127.1.1.5", "127.1.1.6", "127.1.1.7", "127.1.1.8", "127.1.2.9"}; for (int i = 0; i < clientList.length; i++) { String clientIP = clientList[i]; int clientHash = Integer.valueOf(clientIP.split("\\.")[3]); // tailMap方法获取的是参数key(包含key)后面的map,比如 // serverIPMap = {1="127.0.0.1",2="127.0.0.2",3="127.0.0.3",4="127.0.0.4"} // serverIPMap.tailMap(2) = {2="127.0.0.2",3="127.0.0.3",4="127.0.0.4"} SortedMap<Integer, String> integerStringSortedMap = serverHashMap.tailMap(clientHash); if (integerStringSortedMap.isEmpty()) { // 如果为空,则只能转发到第一个服务器上 Integer firstServerIP = serverHashMap.firstKey(); System.err.println("客户端:" + clientIP + ",服务器:" + serverHashMap.get(firstServerIP)); } else { // 如果不为空,则转发到最近的服务器IP Integer nearestServerIP = integerStringSortedMap.firstKey(); System.err.println("客户端:" + clientIP + ",服务器:" + serverHashMap.get(nearestServerIP)); } } } }
结果如下

这种情况下如果服务器减少或者增加,对请求的分发影响不大,但是有个问题,服务器如果不是均匀分布在Hash闭环上,就会导致数据倾斜
一致性Hash算法(含虚拟节点)
package com.lagou; import java.util.SortedMap; import java.util.TreeMap; /** * @ClassName: ConsistenHashWithVirtual * @Description: 使用虚拟节点的一致性Hash算法 * @Author: Administrator * @Date: 2021/9/7 21:41 */ public class ConsistenHashWithVirtual { public static void main(String[] args) { // 服务端IP集合 String[] serverList = new String[]{"127.0.0.1", "127.0.0.4", "127.0.0.7"}; // 然后将服务端IP进行Hash然后存储到map中,想象成一个闭环 SortedMap<Integer, String> serverHashMap = new TreeMap<>(); int virtualCount = 2; for (int i = 0; i < serverList.length; i++) { String serverIP = serverList[i]; // Hash值我们用IP的最后一位代替,这是为了测试 int serverHash = Integer.valueOf(serverIP.split("\\.")[3]); serverHashMap.put(serverHash, serverIP); for (int j = 0; j < virtualCount; j++) { // 虚拟节点Hash值 int virtualServerHash = Integer.valueOf(serverIP.split("\\.")[3]) + (j + 1); serverHashMap.put(virtualServerHash, "请求转发到虚拟节点:" + serverIP + "(虚拟后缀:" + (j + 1) + ")"); } } // 客户端IP集合 String[] clientList = new String[]{"127.1.1.1", "127.1.1.2", "127.1.1.3", "127.1.1.4", "127.1.1.5", "127.1.1.6", "127.1.1.7", "127.1.1.8", "127.1.2.9"}; for (int i = 0; i < clientList.length; i++) { String clientIP = clientList[i]; int clientHash = Integer.valueOf(clientIP.split("\\.")[3]); // tailMap方法获取的是参数key(包含key)后面的map,比如 // serverIPMap = {1="127.0.0.1",2="127.0.0.2",3="127.0.0.3",4="127.0.0.4"} // serverIPMap.tailMap(2) = {2="127.0.0.2",3="127.0.0.3",4="127.0.0.4"} SortedMap<Integer, String> integerStringSortedMap = serverHashMap.tailMap(clientHash); if (integerStringSortedMap.isEmpty()) { // 如果为空,则只能转发到第一个服务器上 Integer firstServerIP = serverHashMap.firstKey(); System.err.println("客户端:" + clientIP + ",服务器:" + serverHashMap.get(firstServerIP)); } else { // 如果不为空,则转发到最近的服务器IP Integer nearestServerIP = integerStringSortedMap.firstKey(); System.err.println("客户端:" + clientIP + ",服务器:" + serverHashMap.get(nearestServerIP)); } } } }
运行结果如下

这样就大大减少了服务器压力
劈天造陆,开辟属于自己的天地!!!与君共勉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号