
MySQL分组查询每组最新的一条数据(通俗易懂)
开发中经常会遇到,分组查询最新数据的问题,比如下面这张表(查询每个地址最新的一条记录):

sql如下:
-- ---------------------------- -- Table structure for test -- ---------------------------- DROP TABLE IF EXISTS `test`; CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `address` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `create_time` timestamp(0) NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 13 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of test -- ---------------------------- INSERT INTO `test` VALUES (1, '张三1', '北京', '2019-09-10 11:22:23'); INSERT INTO `test` VALUES (2, '张三2', '北京', '2019-09-10 12:22:23'); INSERT INTO `test` VALUES (3, '张三3', '北京', '2019-09-05 12:22:23'); INSERT INTO `test` VALUES (4, '张三4', '北京', '2019-09-06 12:22:23'); INSERT INTO `test` VALUES (5, '李四1', '上海', '2019-09-06 12:22:23'); INSERT INTO `test` VALUES (6, '李四2', '上海', '2019-09-07 12:22:23'); INSERT INTO `test` VALUES (7, '李四3', '上海', '2019-09-11 12:22:23'); INSERT INTO `test` VALUES (8, '李四4', '上海', '2019-09-12 12:22:23'); INSERT INTO `test` VALUES (9, '王二1', '广州', '2019-09-03 12:22:23'); INSERT INTO `test` VALUES (10, '王二2', '广州', '2019-09-04 12:22:23'); INSERT INTO `test` VALUES (11, '王二3', '广州', '2019-09-05 12:22:23');
平常我们会进行按照时间倒叙排列然后进行分组,获取每个地址的最新记录,sql如下:
SELECT * FROM(SELECT * FROM test ORDER BY create_time DESC) a GROUP BY address
但是查询结果却不是我们想要的:

执行时间按倒叙排列结果为:
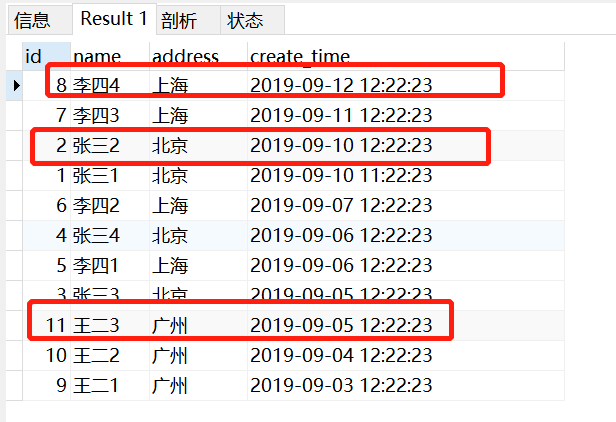
所以真正想要得到的结果是id为2/8/11的记录,上面的查询得到的却是1/5/9,这是为什么呢?
因为在mysql5.7的时候,子查询的排序已经变为无效了,可能是因为子查询大多数是作为一个结果给主查询使用,所以子查询不需要排序的原因。
那么我们应该怎么查呢,有两种方式:
第一种:
SELECT * FROM(SELECT * FROM test ORDER BY create_time DESC LIMIT 10000) a GROUP BY address
结果为:
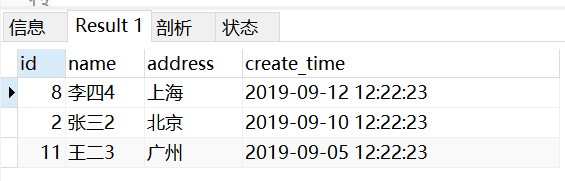
对子查询的排序进行limit限制,此时子查询就不光是排序,所以此时排序会生效,但是限制条数却只能尽可能的设置大些
第二种:
SELECT t.* FROM (SELECT address,max(create_time) as create_time FROM test GROUP BY address) a LEFT JOIN test t ON t.address=a.address and t.create_time=a.create_time
通过MAX函数获取最新的时间和地址(因为需要按照地址分组),然后作为一张表和原来的数据进行联查,
条件就是地址和时间要和获取的最大时间和地址相等,此时结果为:

这两种方式的查询效率差不太多,第二种比第一种查询稍微快一点,可能是由于第二种方式的子查询只有两个字段(时间,被分组字段)的缘故吧!
感兴趣的可以照一张字段多的数据量大的表查询一下比较比较。
PS:第二种方式中最新的记录,不能同时地点和时间都相同,如果出现这种情况,第二种方式会查出把这两条记录都查出来,而第一条不会。
所以根据业务和数据情况来选择其中一种方式,毕竟效率差不太多。
劈天造陆,开辟属于自己的天地!!!与君共勉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号