
python爬虫scrapy框架的使用
总结
scrapy startproject name
scrapy genspider baidu http://www.baidu.com
scrapy crawl baidu
# 常用函数
response.text
.body
.xpath
.extract 提取selector对象的data属性值
.extract_first 提取的selector列表的第一个数据
scrapy项目创建
scrapy startproject scrapy_baidu_091

创建爬虫文件
在spider中创建爬虫文件
# scrapy genspider 名称 域名(不写http)
scrapy genspider baidu http://www.baidu.com

运行爬虫
# scrapy crawl 爬虫名称
scrapy crawl baidu

不遵守robots协议

项目介绍
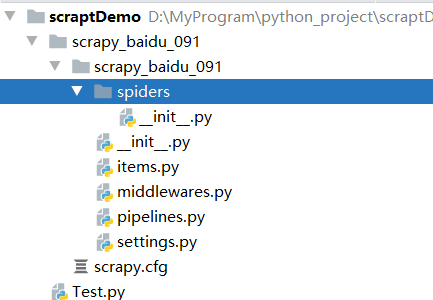
项目结构
项目名字
项目名字
spiders文件夹(存储的是爬虫文件)
init
自定义的爬虫文件 核心功能文件******
init
items 定义数据结构的地方 爬取的数据都包含哪些
middleware 中间件 代理
pipelines 管道 用来处理数据下载的数据
settings 配置文件 robots协议 ua定义等
scrapy_crawlspider的使用
创建流程
scrapy startproject name
scrapy genspider -t crawl read https://www.dushu.com/book/1188.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号