爬取spa网站与ssr网站的区别
前言
在练习爬虫的时候不清楚spa与ssr网站的区别,都使用bs4直接解析网页的html,结果ssr网站输出结果,spa网站却没有输出结果,特此记录
ssr网站:https://ssr1.scrape.center/page/1
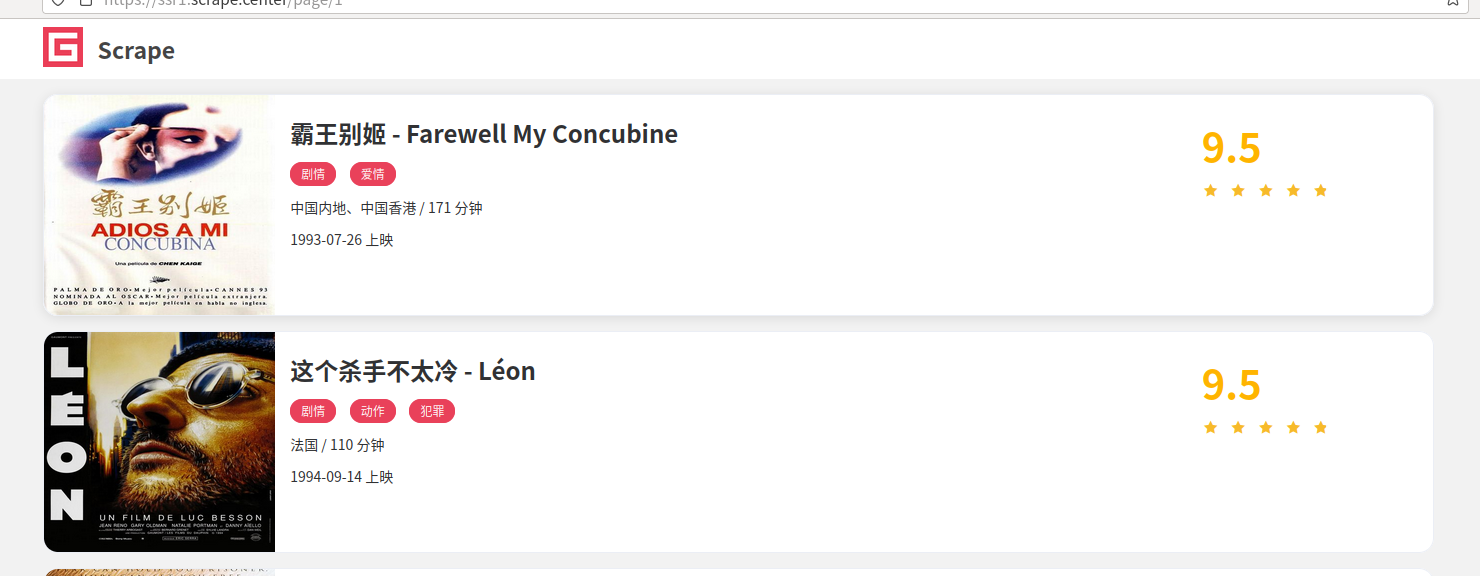
spa网站:https://spa1.scrape.center/page/1
页面解析的代码
from email import header
import requests
from bs4 import BeautifulSoup
# url = "https://spa1.scrape.center/page/" #can't get
url = "https://ssr1.scrape.center/page/" #get success
pageIndex = 0
header = {
"User-Agent":"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:105.0) Gecko/20100101 Firefox/105.0"
}
for i in range(10):
pageIndex = pageIndex+1
response = requests.get(url=url+str(pageIndex),headers=header)
soup = BeautifulSoup(response.text,'html.parser')
lists = soup.find_all('h2',class_='m-b-sm')
for list in lists:
print(list.string)
spa网站与ssr网站的区别
参考大佬的文章:
https://www.jianshu.com/p/fcb98533bc18
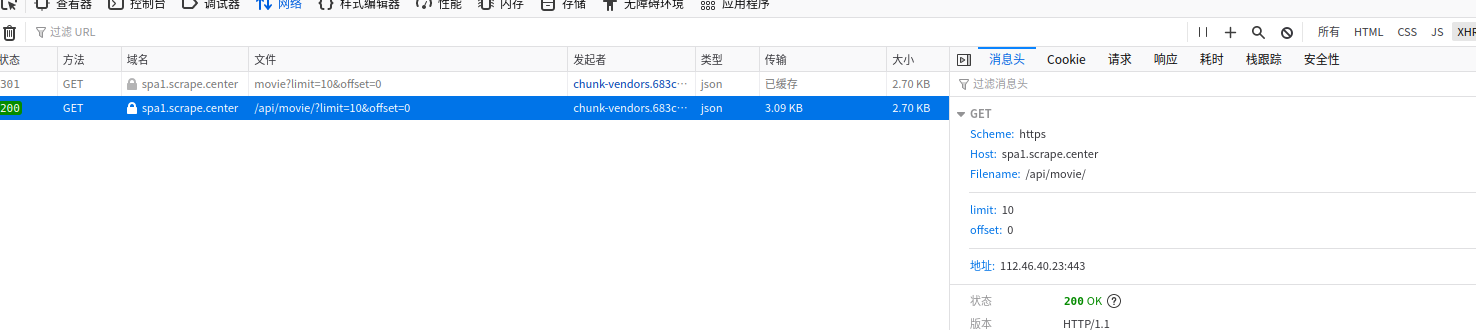
尝试获取xhr链接中的数据
F12打开控制台,发现刷新页面时spa网站会有xhr数据
import requests
from bs4 import BeautifulSoup
url = "https://spa1.scrape.center/api/movie/?limit=10&offset="
# url = "https://spa1.scrape.center/page/" #can't get
# url = "https://ssr1.scrape.center/page/" #get success
pageIndex = 0
header = {
"User-Agent":"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:105.0) Gecko/20100101 Firefox/105.0"
}
response = requests.get(url=url+str(pageIndex),headers=header)
print(respons)
发现可以获得响应中的数据
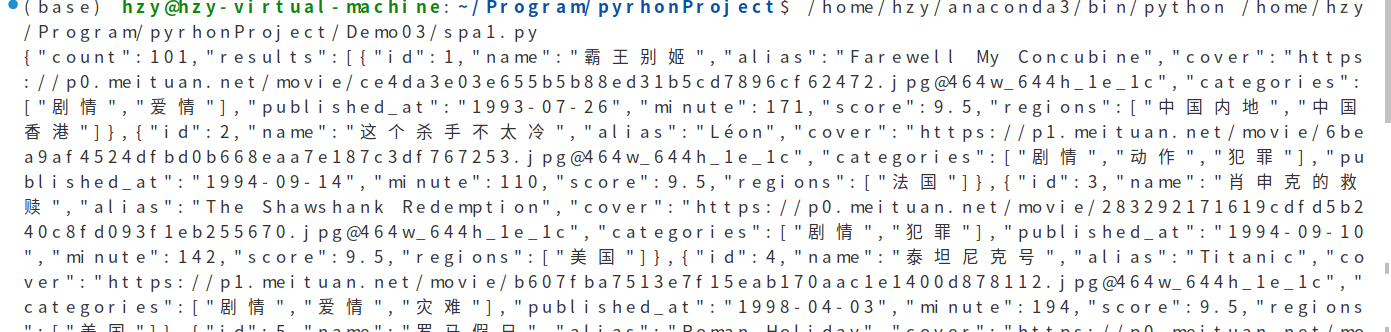
使用json将字符串转化为字典格式
import requests
from bs4 import BeautifulSoup
import json
url = "https://spa1.scrape.center/api/movie/?limit=10&offset="
# url = "https://spa1.scrape.center/page/" #can't get
# url = "https://ssr1.scrape.center/page/" #get success
pageIndex = 0
header = {
"User-Agent":"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:105.0) Gecko/20100101 Firefox/105.0"
}
response = requests.get(url=url+str(pageIndex),headers=header)
# print(response.text)
# 转化为字典格式
data = json.loads(response.text)
print(type(data))

over:可以成功像访问字典一样访问数据了!
import requests
from bs4 import BeautifulSoup
import json
url = "https://spa1.scrape.center/api/movie/?limit=10&offset="
# url = "https://spa1.scrape.center/page/" #can't get
# url = "https://ssr1.scrape.center/page/" #get success
pageIndex = 0
header = {
"User-Agent":"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:105.0) Gecko/20100101 Firefox/105.0"
}
response = requests.get(url=url+str(pageIndex),headers=header)
# print(response.text)
data = json.loads(response.text)
print(data['results'][1]['name'])


 浙公网安备 33010602011771号
浙公网安备 33010602011771号