
数据提取之xpath
lxml是一款高性能的 Python HTML/XML 解析器,我们可以利用它带的XPath语法来快速的定位特定元素以及获取节点信息,而XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML 文档中对元素和属性进行遍历。
xpath中节点的关系

谷歌浏览器安装xpath helper 插件
xpath helper 插件是用来学习xpath语法的便利工具,具体安装使用可以参考
chrome爬虫网页解析工具 Chrome插件图文教程
xpath语法
比较实用的表达式
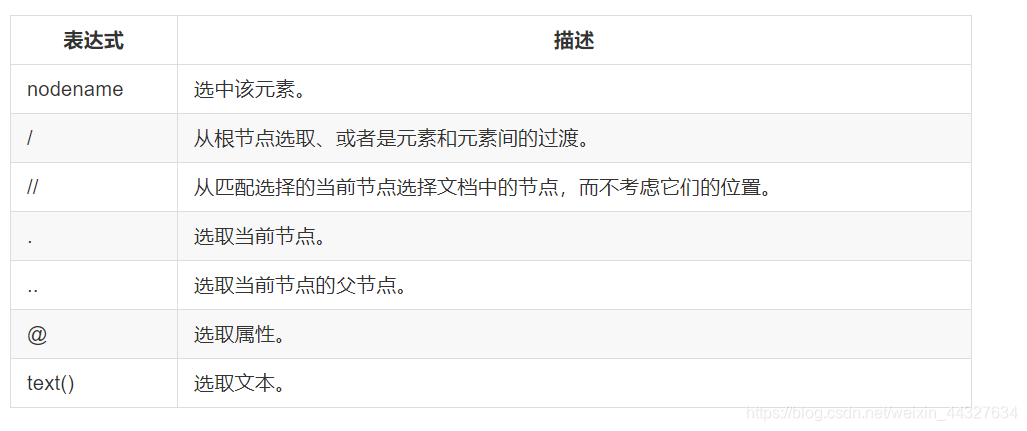
示例:
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>

选取未知节点,XPath 通配符可用来选取未知的 XML 元素:
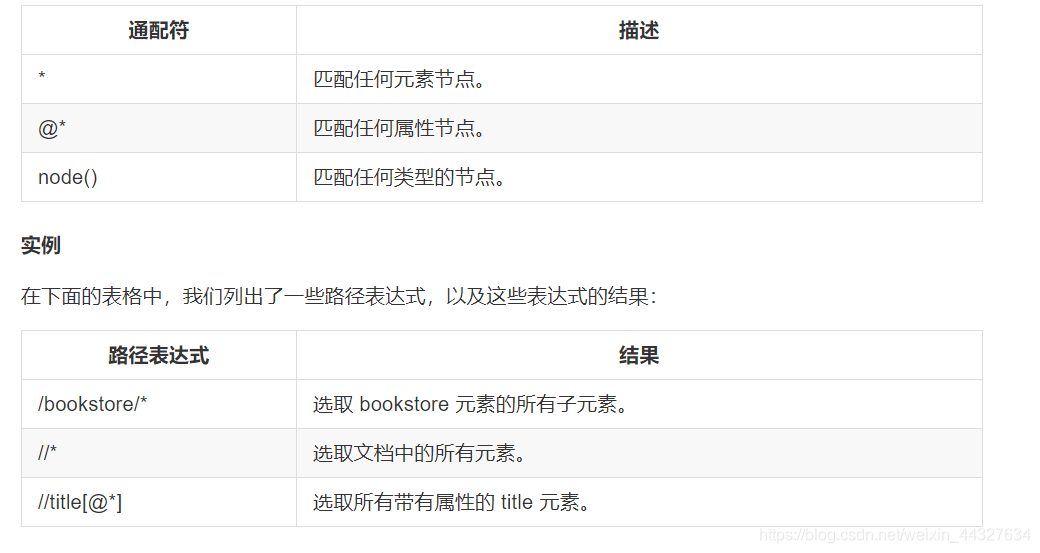
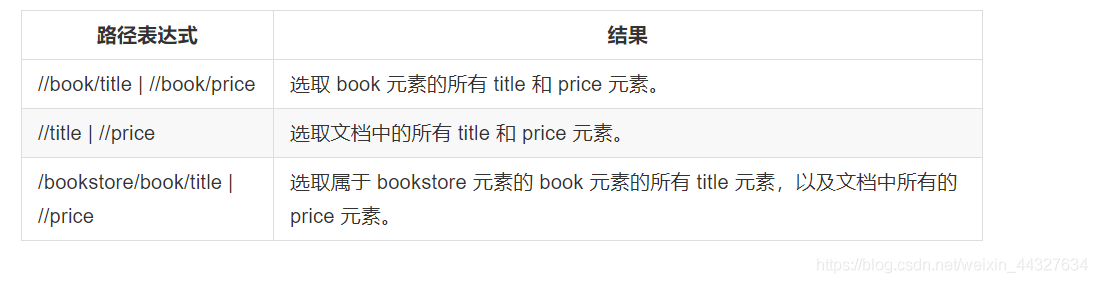
通过在路径表达式中使用“|”运算符可以选取若干个路径:
小案例–抓取豆瓣电影top250电影名和对应的url
准备工作,基础知识储备及注意点:
1.lxml库的安装: pip install lxml
2.lxml的导包:from lxml import etree;
3.lxml转换解析类型的方法:etree.HTML(text)
4.lxml解析数据的方法:data.xpath("//div/text()")
5.需要注意lxml提取完毕数据的数据类型都是列表类型
6.如果数据比较复杂:先提取大节点, 在遍历小节点操作
import requests
from lxml import etree
titles_list = [] # 电影名称列表
urls_list = [] # 详情页url列表
if __name__ == '__main__':
# 1.确认目标的url
for i in range(10):
page = i*25
# 确认目标url,并且格式化输出,,进行翻页
url_ = f'https://movie.douban.com/top250?start={page}&filter='
# 用户代理
headers_ = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
# requests发送get请求,,得到响应
response_ = requests.get(url_,headers=headers_)
# 先取出字符串类型的文本内容
str_html = response_.text
# print(type(str_html))
# 完成解析 提取特定的数据 xpath解析不了str
# 1.转换类型 str >>> xpath可解析的类型
html_data = etree.HTML(str_html) # <class 'str'> >>> <class 'lxml.etree._Element'>
# print(type(html_data))
# 2.xpath语法进行 xpath的语法当作参数 电影名称 不管数量如何 都是列表
title_list = html_data.xpath('//div[@class="hd"]/a/span[1]/text()')
# 最终的列表 = 老列表 + 新列表
titles_list = titles_list + title_list
# 电影详情页的url
url_list = html_data.xpath('//div[@class="hd"]/a/@href')
urls_list = urls_list + url_list
time.sleep(1)
# 将电影名和其对应的url组成键值对放入字典
title_url = {}
for i in range(len(urls_list)):
title_url[titles_list[i]] = urls_list[i]
print(title_url)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号