

动态规划(DP)

1. 动态规划概念
动态规划(英语:Dynamic programming,简称DP)
简单来说,动态规划其实就是,给定一个问题,我们把它拆成一个个子问题,直到子问题可以直接解决。然后呢,把子问题答案保存起来,以减少重复计算。再根据子问题答案反推,得出原问题解的一种方法。
拆分子问题,记住过往,减少重复计算
动态规划问题的一般形式就是求最值。
动态规划其实是运筹学的一种最优化方法。只不过计算机问题上应用比较多,比如说求最长递增子序列、最小编辑距离等等。
- 求解动态规划的核心问题是穷举。因为要求最值,肯定要把所有可⾏的答案穷举出来,然后在其中找最值呗。
2. 动态规划三要素
- 「重叠⼦问题」:如果暴力穷举的话效率会及其低下,所以需要
备忘录或者DP table来优化穷举过程,避免不必要的计算。如图中要计算斐波那契数列f(20)=f(19)+f(18)、f(19)=f(18)+f(17)…时f(18会被计算两次) 所以这就是重叠子问题。

-
「最优⼦结构」: ⽽且,动态规划问题⼀定会具备
「最优⼦结构」,才能通过⼦问题的最值得到原问题的最值。 -
「状态转移⽅程」:描述问题结构的数学形式,列出正确的状态转移方程是困难的。
![在这里插入图片描述]()
- 列出状态转移方程的步骤:明确状态 -> 定义dp数组/函数的含义 -> 明确选择 -> 明确 base case

3. 案例
3.1 斐波那契数列
3.1.1 暴力递归
斐波那契数列的数学形式就是递归的,写成代码就是这样:
int fib(int N) {
if (N == 1 || N == 2) return 1;
return fib(N - 1) + fib(N - 2);
}
假设n = 20 ,那么它的递归树如下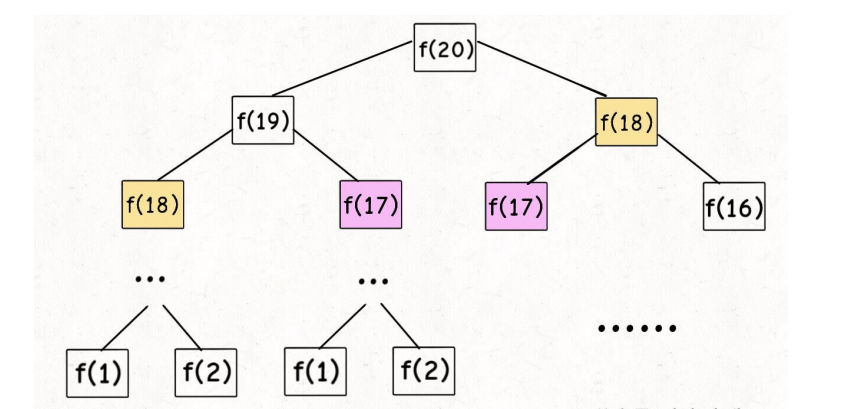
这个递归树怎么理解?就是说想要计算原问题 f(20) ,我就得先计算出⼦问题 f(19) 和 f(18) ,然后要计算 f(19) ,我就要先算出⼦问题 f(18)和 f(17) ,以此类推。最后遇到 f(1) 或者 f(2) 的时候,结果已知,就能直接返回结果,递归树不再向下⽣⻓了。
注意:但凡遇到需要递归的问题,最好都画出递归树,这对分析算法的复杂度,寻找算法低效的原因有很大帮助。
递归算法的时间复杂度怎么计算?子问题个数乘以解决一个子问题所需要的时间
解决⼀个⼦问题的时间,在本算法中,没有循环,只有 f(n - 1) + f(n - 2) ⼀个加法操作,时间为 O(1)。
所以,这个算法的时间复杂度为 O(2^n),指数级别,爆炸。
观察递归树,很明显发现了算法低效的原因:存在⼤量重复计算,⽐如f(18) 被计算了两次,⽽且你可以看到,以 f(18) 为根的这个递归树体量巨⼤,多算⼀遍,会耗费巨⼤的时间。更何况,还不⽌ f(18) 这⼀个节点被重复计算,所以这个算法及其低效。
这就是动态规划问题的第⼀个性质:重叠⼦问题。下⾯,我们想办法解决这个问题。
3.1.2 带备忘录的递归解法
即然耗时的原因是重复计算,那么我们可以造⼀个「备忘录」,每次算出某个⼦问题的答案后别急着返回,先记到「备忘录」⾥再返回;每次遇到⼀个⼦问题先去「备忘录」⾥查⼀查,如果发现之前已经解决过这个问题了,直接把答案拿出来⽤,不要再
耗时去计算了。⼀般使⽤⼀个数组充当这个「备忘录」,当然你也可以使⽤哈希表(字典),思想都是⼀样的。
C语言版本:
int fib(int N) {
if (N < 1) return 0;
// 备忘录全初始化为 0
vector<int> memo(N + 1, 0);
// 初始化最简情况
return helper(memo, N);
}
int helper(vector<int>& memo, int n) {
// base case
if (n == 1 || n == 2) return 1;
// 已经计算过
if (memo[n] != 0) return memo[n];
memo[n] = helper(memo, n - 1) +
helper(memo, n - 2);
return memo[n];
}
java版本:
class Solution {
static final int VAR = (int) (1e9+7); // 1000000007
public int fib(int n) {
if(n<1) return 0;
int memo[] = new int[n+1];
return helper(memo,n);
}
// 备忘录helper 每次计算前先去helper中查找,如果有就返回,没有就添加
public int helper(int[] memo,int n){
if(n==1||n==2){
return 1;
}
if(memo[n] != 0) return memo[n];
memo[n] = helper(memo,n-1) % VAR + helper(memo,n-2) % VAR;
return memo[n] % VAR;
}
}
画出递归树
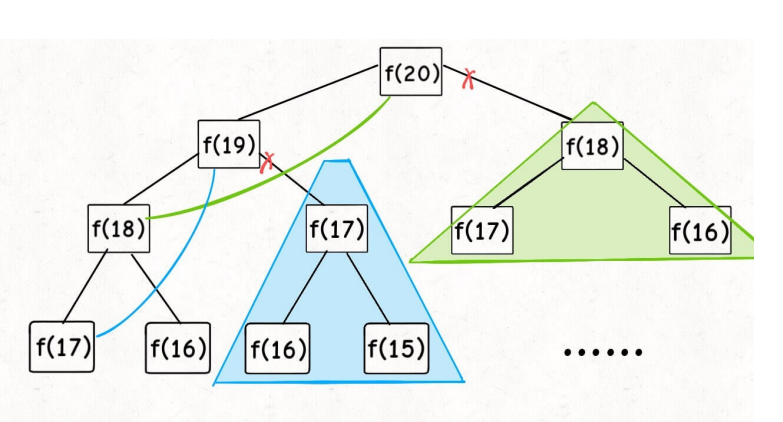
实际上,带「备忘录」的递归算法,把⼀棵存在巨量冗余的递归树通过「剪枝」,改造成了⼀幅不存在冗余的递归图,极⼤减少了⼦问题(即递归图中节点)的个数。
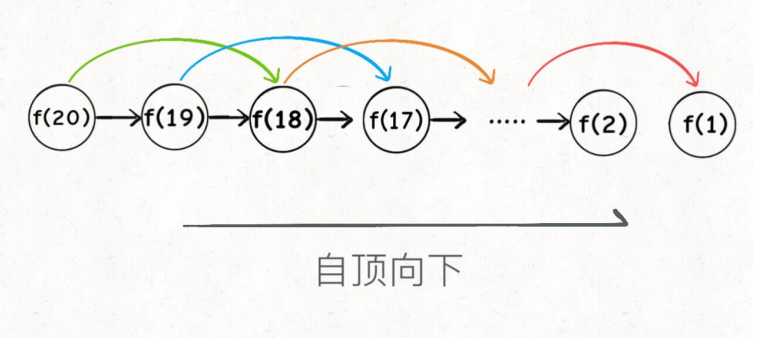
本算法的时间复杂度是 O(n)
-
带备忘录的递归:自顶向下,注意我们刚才画的递归树(或者说图),是从上向下延伸,都是从⼀个规模较⼤的原问题⽐如说 f(20) ,向下逐渐分解规模,直到 f(1) 和 f(2) 触底,然后逐层返回答案,这就叫「⾃顶向下」。
-
动态规划:自底向上,反过来,我们直接从最底下,最简单,问题规模最⼩的
f(1) 和 f(2) 开始往上推,直到推到我们想要的答案 f(20) ,这就是动态规划的思路,这也是为什么动态规划⼀般都脱离了递归,⽽是由循环迭代完成计算。
3.1.3 dp 数组的迭代解法
把「备忘录」独⽴出来成为⼀张表,就叫做 DP table
int fib(int N) {
vector<int> dp(N + 1, 0);
// base case
dp[1] = dp[2] = 1;
for (int i = 3; i <= N; i++)
dp[i] = dp[i - 1] + dp[i - 2];
return dp[N];
}
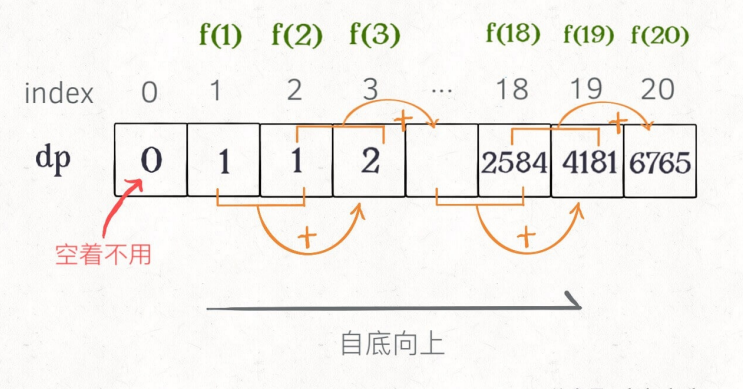
画个图就很好理解了,⽽且你发现这个 DP table 特别像之前那个「剪枝」后的结果,只是反过来算⽽已。实际上,带备忘录的递归解法中的「备忘录」,最终完成后就是这个 DP table,所以说这两种解法其实是差不多的,⼤部分情况下,效率也基本相同。
这⾥,引出状态转移⽅程这个名词,实际上就是描述问题结构的数学形
式:
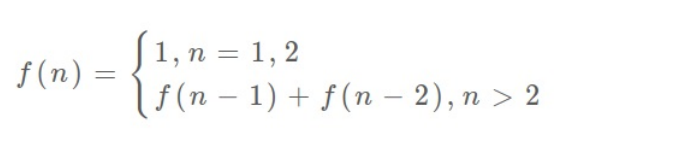
为啥叫「状态转移⽅程」?为了听起来⾼端。你把 f(n) 想做⼀个状态 n,这个状态 n 是由状态 n - 1 和状态 n - 2 相加转移⽽来,这就叫状态转移,仅此⽽已。列出状态转移方程很重要!!!
细节优化
根据斐波那契数列
的状态转移⽅程,当前状态只和之前的两个状态有关,其实并不需要那么⻓
的⼀个 DP table 来存储所有的状态,只要想办法存储之前的两个状态就⾏
了。所以,可以进⼀步优化,把空间复杂度降为 O(1):
int fib(int n) {
if (n == 2 || n == 1)
return 1;
int prev = 1, curr = 1;
for (int i = 3; i <= n; i++) {
int sum = prev + curr;
prev = curr;
curr = sum;
}
return curr;
}
3.2 凑零钱问题
题⽬:给你 k 种⾯值的硬币,⾯值分别为 c1, c2 … ck ,每种硬币的数量⽆限,再给⼀个总⾦额 amount ,问你最少需要⼏枚硬币凑出这个⾦额,如果不可能凑出,算法返回 -1 。算法的函数签名如下:
// coins 中是可选硬币⾯值,amount 是⽬标⾦额
int coinChange(int[] coins, int amount);
⽐如说 k = 3 ,⾯值分别为 1,2,5,总⾦额 amount = 11 。那么最少需要 3 枚硬币凑出,即 11 = 5 + 5 + 1。
3.2.1 暴力递归
⾸先,这个问题是动态规划问题,因为它具有「最优⼦结构」的。要符合「最优⼦结构」,⼦问题间必须互相独⽴。
核心问题:列出状态转移方程
1、 先确定「状态」,也就是原问题和⼦问题中变化的变量。由于硬币数量⽆
限,所以唯⼀的状态就是⽬标⾦额 amount 。
2、然后确定 dp 函数的定义:当前的⽬标⾦额是 n ,⾄少需要 dp(n) 个硬
币凑出该⾦额。
3、然后确定「选择」并择优,也就是对于每个状态,可以做出什么选择改变当
前状态。具体到这个问题,⽆论当的⽬标⾦额是多少,选择就是从⾯额列表
coins 中选择⼀个硬币,然后⽬标⾦额就会减少:
# 伪码框架
def coinChange(coins: List[int], amount: int):
# 定义:要凑出⾦额 n,⾄少要 dp(n) 个硬币
def dp(n):
# 做选择,选择需要硬币最少的那个结果
for coin in coins:
res = min(res, 1 + dp(n - coin))
return res
# 我们要求的问题是 dp(amount)
return dp(amount)
4、最后明确 base case,显然⽬标⾦额为 0 时,所需硬币数量为 0;当⽬标⾦额
⼩于 0 时,⽆解,返回 -1:
def coinChange(coins: List[int], amount: int):
def dp(n):
# base case
if n == 0: return 0
if n < 0: return -1
# 求最⼩值,所以初始化为正⽆穷
res = float('INF')
for coin in coins:
subproblem = dp(n - coin)
# ⼦问题⽆解,跳过
if subproblem == -1: continue
res = min(res, 1 + subproblem)
return res if res != float('INF') else -1
return dp(amount)
状态转移⽅程:
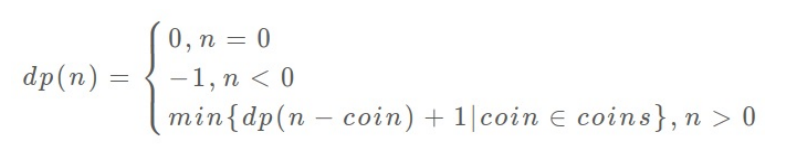
例如:amount = 11, coins = {1,2,5} 递归树:
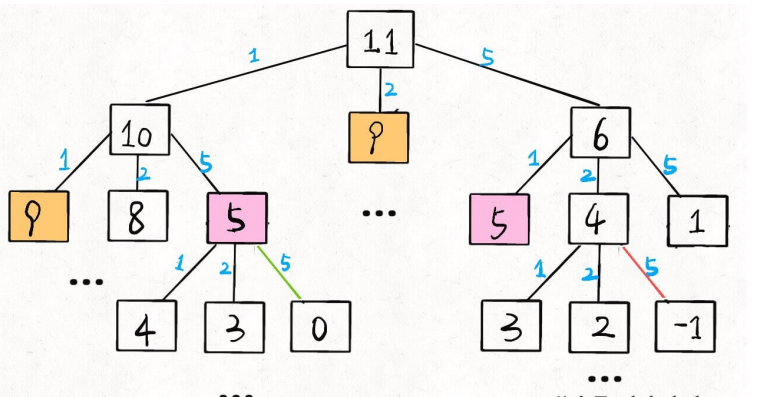
时间复杂度分析:⼦问题总数 x 每个⼦问题的时间。
⼦问题总数为 递归树节点个数,这个⽐较难看出来,是 O(n^k),总之是指数级别的。每个⼦问题中含有⼀个 for 循环,复杂度为 O(k)。所以总时间复杂度为 O(k * n^k),指数级别。
3.2.2 带备忘录的递归
通过备忘录消除⼦问题
def coinChange(coins: List[int], amount: int):
# 备忘录
memo = dict()
def dp(n):
# 查备忘录,避免重复计算
if n in memo: return memo[n]
if n == 0: return 0
if n < 0: return -1
res = float('INF')
for coin in coins:
subproblem = dp(n - coin)
if subproblem == -1: continue
res = min(res, 1 + subproblem)
# 记⼊备忘录
memo[n] = res if res != float('INF') else -1
return memo[n]
return dp(amount)
很显然「备忘录」⼤⼤减⼩了⼦问题数⽬,完全消除了⼦问题的冗余,所以⼦问题总数不会超过⾦额数 n,即⼦问题数⽬为 O(n)。处理⼀个⼦问题的时间不变,仍是 O(k),所以总的时间复杂度是 O(kn)。
3.2.3 dp 数组的迭代解法
以⾃底向上使⽤ dp table 来消除重叠⼦问题
dp[i] = x 表⽰,当⽬标⾦额为 i 时,⾄少需要 x 枚硬币。
int coinChange(vector<int>& coins, int amount) {
// 数组⼤⼩为 amount + 1,初始值也为 amount + 1
vector<int> dp(amount + 1, amount + 1);
// base case
dp[0] = 0;
for (int i = 0; i < dp.size(); i++) {
// 内层 for 在求所有⼦问题 + 1 的最⼩值
for (int coin : coins) {
// ⼦问题⽆解,跳过
if (i - coin < 0) continue;
dp[i] = min(dp[i], 1 + dp[i - coin]);
}
}
return (dp[amount] == amount + 1) ? -1 : dp[amount];
}
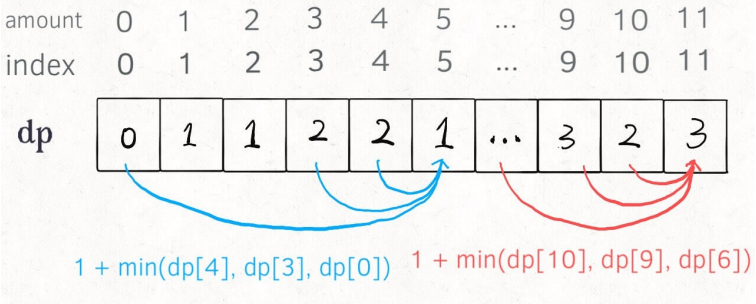
PS:为啥 dp 数组初始化为 amount + 1 呢,因为凑成 amount ⾦额的硬币数最多只可能等于 amount (全⽤ 1 元⾯值的硬币),所以初始化为amount + 1 就相当于初始化为正⽆穷,便于后续取最⼩值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号