JDK1.8源码(二)——java.util.LinkedList
LinkedList定义
LinkedList 是链表实现的线性表(双链表),元素有序且可以重复。
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
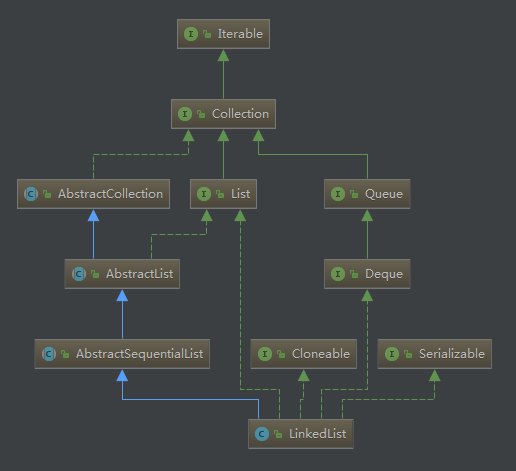
蓝色实线箭头是指Class继承关系
绿色实线箭头是指interface继承关系
绿色虚线箭头是指接口实现关系
由上可知LinkedList继承AbstractSequentialList并且实现了List和Deque,Cloneable, Serializable接口。
①、实现 List 接口
List 接口定义了实现该接口的类都必须要实现的一组方法,如下所示,下面我们会对这一系列方法的实现做详细介绍。
字段属性


//链表元素(节点)的个数 transient int size = 0; //第一个元素的指针 transient Node<E> first; //最后一个元素的指针 transient Node<E> last;
注意这里出现了一个 Node 类,这是 LinkedList 类中的一个内部类,集合里每一个元素就代表一个 Node 类对象,LinkedList 集合就是由许多个 Node 对象类似于手拉着手构成,由此可知,LinkedList是一个双向链表。
private static class Node<E> { E item;//存放业务数据 Node<E> next;//是该节点的上一个节点的引用 Node<E> prev;//是该节点的下一个节点的引用 Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }

如图所示:每个节点都prev都保存上一个节点的引用,next保存下一个节点的引用;

需要注意:第一个节点prev没有指向的节点,为null,最后一个节点next也没有指向的节点,也为null
构造函数
①、无参构造函数
public LinkedList() { }
注意:这里不需要初始化链表的大小,不像ArrayList,需要初始化数组的大小才能添加元素
②、泛型参数有参构造函数
public LinkedList(Collection<? extends E> c) { this(); addAll(c); }
将已有元素的集合Collection 的实例添加到 LinkedList 中,下面详细介绍
添加元素
①、add(E e)
public boolean add(E e) { //将元素添加到链表的尾部 linkLast(e); return true; } void linkLast(E e) { final Node<E> l = last;//先用变量存储链表尾部节点 final Node<E> newNode = new Node<>(l, e, null);//新添加一个元素,需要新增一个节点,元素内容为e,prev为当前last节点的地址引用,next为null last = newNode;//将链表尾部指向新节点 if (l == null) first = newNode;//如果链表为空,将这个新节点也设为头部节点,那么新增节点既是头节点也是尾节点,并且头节点的prev和next都是null else l.next = newNode;//链表不为空,将之前存储的原链表尾部节点的next指向新增节点 size++;//节点数加1 modCount++;//和ArrayList中一样,防止集合遍历时做元素的添加 }
此时需要注意,如果链表为空时,第一个元素的指针和最后一个元素的指针都指向当前节点
②、addFirst(E e)
public void addFirst(E e) { linkFirst(e); } private void linkFirst(E e) { final Node<E> f = first;//先用变量 f 存储链表头部节点 final Node<E> newNode = new Node<>(null, e, f);//将指定元素构造成一个新节点,元素内容为e,prev为null,next为当前first节点的地址引用, first = newNode;//将链表头部指向新节点 if (f == null) last = newNode;//如果链表为空,将这个新节点也设为尾节点,那么新增节点既是头节点也是尾节点 else f.prev = newNode;//如果链表不为空,讲原链表的头部节点 f 的上一个节点指向新节点 size++;//节点数加1 modCount++;//和ArrayList中一样,防止集合遍历时做元素的添加 }
③、addLast(E e)
public void addLast(E e) { linkLast(e); }
和add(E e) 实现相同,在链表尾部添加元素
④、public void add(int index, E element)
将元素插入指定位置
public void add(int index, E element) { //判断索引是否越界 return index >= 0 && index <= size; checkPositionIndex(index); if (index == size)//如果索引值等于链表大小 linkLast(element);//将节点直接插入链表尾部;上面已经分析过 else linkBefore(element, node(index)); } //根据索引获取节点,因为是链表,不像数组,在内存中并不是一块连续的位置存储,不能根据索引直接取到值,需要从头部或者尾部一个个向下找 Node<E> node(int index) { //size >> 1表示移位,指除以2的1次方 if (index < (size >> 1)) {//如果索引比链表的一半小 Node<E> x = first;//设x为头节点,表示从头节点开始遍历 for (int i = 0; i < index; i++)//因为只需要找到index处,所以遍历到index处就可以停止 x = x.next;//从第一个节点开始向后移动,直到移动到index前一个节点就能找到index处的节点 return x; } else {//如果索引比链表的一半大 Node<E> x = last;//设x为尾部节点,表示从最后一格节点开始遍历 for (int i = size - 1; i > index; i--) x = x.prev;//从最后一个节点开始向前移动,直到移动到index后一个节点就能找到index处的节点 return x; } } void linkBefore(E e, Node<E> succ) { final Node<E> pred = succ.prev;//获取index 节点的上一个节点 final Node<E> newNode = new Node<>(pred, e, succ);//构造新插入的节点,新节点pred设为原链表index的上一个节点,next处设为原始链表的index处的节点 succ.prev = newNode;//原始index处的节点的上一个几点引用设为新节点 if (pred == null)//如果插入节点的上一个节点引用为空 first = newNode;//头部节点设为新节点 else pred.next = newNode;//原始index的上一个节点的next 设为新节点 size++; modCount++; }
我们发现LinkedList 每次添加元素只是改变元素的上一个指针引用和下一个指针引用,而且没有扩容。对比于 ArrayList ,需要扩容,而且在中间插入元素时,后面的所有元素都要移动一位,两者插入元素时的效率差异很大
查找元素
①、get(int index)
public E get(int index) { //判断索引是否越界 return index >= 0 && index <= size; checkElementIndex(index); //node(index)上面已经讲过,这里获取节点的实际元素 return node(index).item; }
②、indexOf(Object o)
返回链表中第一个出现指定元素的索引
public int indexOf(Object o) { int index = 0; if (o == null) {//查找的元素为null for (Node<E> x = first; x != null; x = x.next) {//从头结点开始不断向下一个节点进行遍历 if (x.item == null) return index;//找到了则返回index index++; } } else {//查找的元素不为null for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item))//使用equals 比较 return index;//找到了则返回index index++; } } return -1;//找不到指定元素,则返回-1 }
修改元素
public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index);//获取指定索引处的节点 E oldVal = x.item;//获取指定索引处节点的实际元素 x.item = element;//将指定位置的节点元素替换成需要修改的元素 return oldVal;//返回索引处原来的节点的元素值 }
删除元素
①、通过索引位置删除
public E remove(int index) { checkElementIndex(index); //先获取指定位置的节点 return unlink(node(index)); } E unlink(Node<E> x) { final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) {//如果删除节点的上一个节点引用为null,表示删除节点为头节点 first = next;//将头节点设置为删除节点的下一个节点 } else { prev.next = next;//将删除节点的上一个节点的next指向删除节点的下一个节点 x.prev = null;//将删除节点的上一个节点引用设为null,否则链表就乱了 } if (next == null) {//如果删除节点的下一个节点引用为null,表示删除节点为尾部节点 last = prev;//将尾部节点设为删除节点的上一个节点 } else {//不是尾部节点 next.prev = prev;//将删除节点的下一个节点的prev指向删除节点的上一个节点 x.next = null;//将删除节点的下一个节点引用设为null } x.item = null;//将删除节点的实际元素设为null,便于垃圾回收 size--; modCount++; return element; }
与ArrayList比较而言,LinkedList的删除动作不需要“移动”很多数据,从而效率更高
总结
ArrayList和LinkedList在性能上各有优缺点:
1.对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对ArrayList而言,主要是在内部数组中增加一项,偶尔可能会导致对数组扩容;而对LinkedList而言,这个开销是统一的,都是新建一个Node对象节点。
2.在ArrayList的中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在LinkedList的中间插入或删除一个元素的开销是固定的,只需要改变元素邻近节点的上下引用地址。
3.LinkedList不支持高效的随机元素访问,因为需要从第一个元素或者最后一个元素开始遍历查找;ArrayList可以直接根据索引取到对应位置的元素。
4.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间,每个元素不仅保存了当前元素的实际内容,还有上一个节点和下一个节点的引用
所以在我们进行对元素的增删查操作的时候,进行查操作时用ArrayList,进行增删操作的时候最好用LinkedList。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号