

python爬取网易云飙升榜音乐
1、分析网页
找到.m4a的歌曲链接
去掉#号
2、添加UA
伪装成正常浏览器
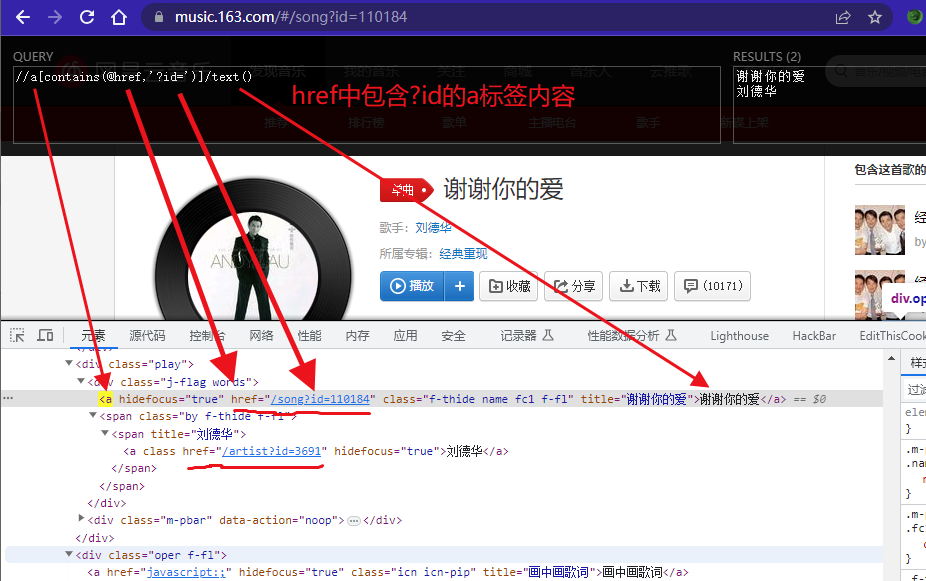
3、使用xpath筛选数据
用zip处理大内容列表为单独
4、保存文件
开发工具-网络-媒体里找到.m4a音频
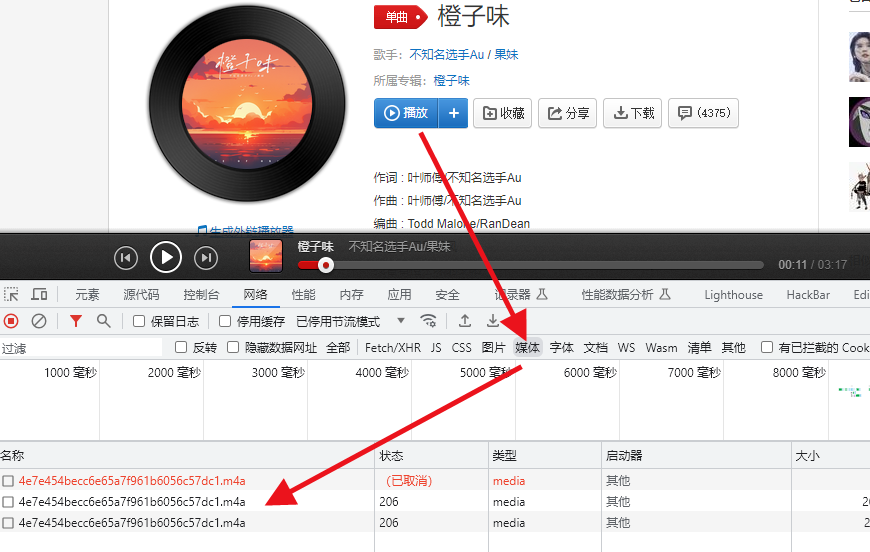
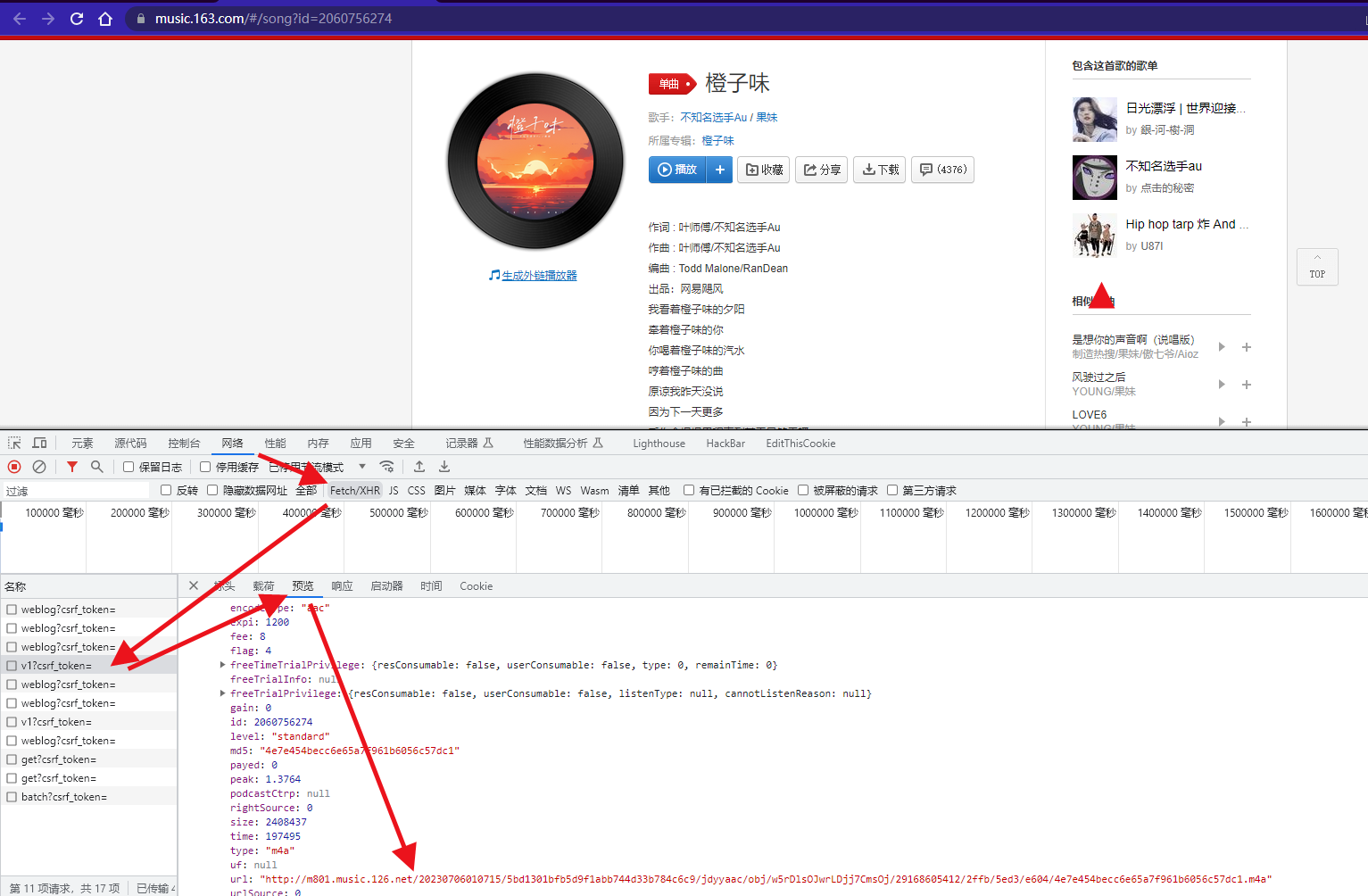
在XHR动态网页里找到.m4a音频真实url地址
官方插件下载xpath helper
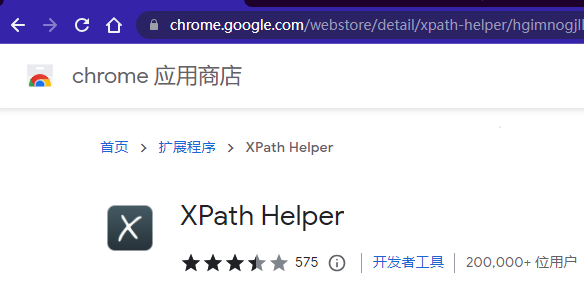
PS:重启浏览器使用
不知道为什么不太行(但是后面python程序执行不影响)
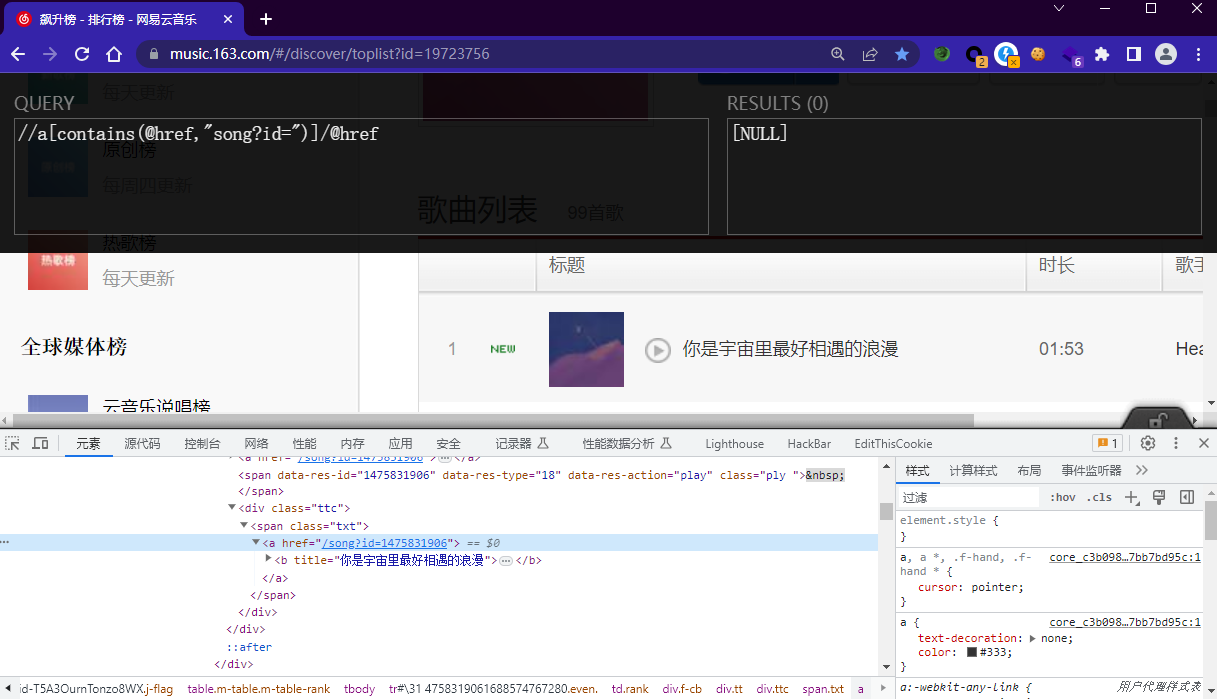
xpath语法格式对应规律
从列表中提取数据,使用zip

点击查看代码
# Author:Jasy
# 爬取网易云音乐飙升榜歌曲
import requests
from lxml import etree
# https://music.163.com/song/media/outer/url?id= 外链地址
# 1、确定网址
# url里的#号是网页访问第一道,不是最终网页url,要去掉 原url https://music.163.com/#/discover/toplist?id=19723756
url = 'https://music.163.com/discover/toplist?id=19723756'
base_url = 'https://music.163.com/song/media/outer/url?id='
# 2.1添加UA 伪装成正常浏览器
ua = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}
# 2.2请求
html_str = requests.get(url,headers=ua).text
# 3、筛选数据 (使用xpath 专门用来处理xml,html数据的,字符串的需要转换,就需要使用lxml工具,bs4现在用的少)
html = etree.HTML(html_str) # 使用lxml转换成真正的html类型
song_names = html.xpath('//a[contains(@href,"song?id=")]/text()') #xpath语法 //表示任意位置 @表示属性 contains内容
song_ids = html.xpath('//a[contains(@href,"song?id=")]/@href')
for song_id,song_name in zip(song_ids,song_names): #从列表中批量提取单个数据
song_id = song_id.strip('/song?id=') #用strip剥去song_id中的'/song?id='字符串
if '$' not in song_id: #去掉song_id中带$开头的字符串
song_url = base_url + song_id
print(song_url)
# 如果拿的是视频 音频 图片,用content
mp3 = requests.get(song_url,headers=ua).content
# 4、保存 注意绝对路径和相对路径(用./),我这里用的绝对路径
with open(f'E:/python爬虫练习/wangyiyun/{song_name}.mp3','wb') as f:
f.write(mp3)
MU5735 R.I.P

 浙公网安备 33010602011771号
浙公网安备 33010602011771号