NodeJS V8 GC概览
本文地址 http://www.cnblogs.com/jasonxuli/p/6041909.html
[A tour of V8: Garbage Collection]
基本是这篇文章的翻译,但是对上半部分结构做了改动,去掉了关系不太紧密的部分,调整了结构,增加了相关知识介绍。
背景知识:
1, 一个对象如果被根对象引用或者被另一个活对象引用,那它就是活的。其他的都是垃圾。
根对象是由V8或者浏览器引用的。例如,被本地变量引用的对象是根 对象,因为当前的栈被视为根对象;全局对象是根对象,因为他们总是可访问;浏览器对象例如DOM元素也是根对象,尽管某些情况下可能是被弱引用。
2, Heap是基于Page的。Page是连续的内存块,由OS根据类似mmap的方式分配。Page总是1MB大并且是1MB对齐,大对象空间(large-object-space)例外。
为了存储对象,Page包含一个含有各种tag和meta-data的header;一个标记位图(marking bitmap),用来显示存活的对象;以及一个分配在单独内存中的slots buffer,包含指向本Page中对象的对象列表,也称为rememberd set。
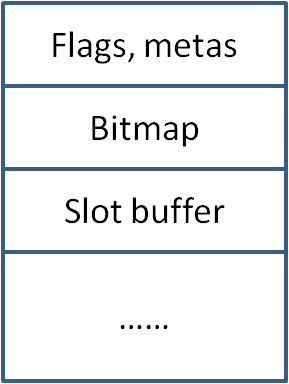
图1 Page结构
3, 代际回收:
类似二八法则,大多数对象生存期很短,少数对象生存期很长,因此将最常用的那部分Heap区域分为:
新区:又分为From 和 To; 大多数新对象都被配置在To区域,当To区域满了的时候,快速GC(scavenge)被触发。
老区:经过两次快速GC仍然存续的对象会被移动到老区。当老区达到阈值的时候,会触发主GC(mark-sweep 或 mark-compact)

图2 快速GC区域
4, Tagged Pointers:
需要编译器少量的支持,也就是需要在Pointer上做标记以区分某个字(word)是数据还是指针,这样GC扫描速度会加快。
快速GC:Scavenge
概要:
当To区域满了的时候,交换To和From区域,然后从From区域复制存活对象到To区域或者到老区。这个过程同时也压缩了To区域,因此改善了缓存局部性(cache locality),内存配置会保持快速简单。
详细:
在初始化算法时,复制新区中可从根到达的所有对象到一个队列。随后在主循环中保持两个指针:配置指针(allocationPtr)和扫描指针(scanPtr)。
配置指针指向下次配置对象的地址,扫描指针指向下一次扫描的对象。
在扫描指针之前的对象都已经被处理过了-- 它们和它们的临近对象都已经在To区域中,指针也已经被更新。
在两个指针中间的对象已经被复制到To区域,但是它们的内部指针仍然指向From区域中的对象。
可以认为在两个指针之间的是一个进行广度优先搜索(breadth-first-search)的队列。

图3 快速GC队列
每次从scanPtr处取一个对象obj,下移scanPtr,然后检查obj的内部指针。
1,如果某个指针没有指向From区域,那么肯定指向了老区。
2,如果发现某个指针指向了From区域的对象并且这个对象没有被复制到过(没有forwarding address),那么把它复制到To区域的最后(allocationPtr的位置),然后设置forwarding address到新的副本,并且下移allocationPtr。也因此是广度优先搜索,因为这个对象以后还会经历一次其内部指针的扫描。
3,如果发现某个老区的指针指向了这个对象,那么这显然是个仍然存活的对象。不过这种情况也带来下面一个问题。
算法的伪码:
def scavenge():
swap(fromSpace, toSpace)
allocationPtr = toSpace.bottom
scanPtr = toSpace.bottom
for i = 0..len(roots):
root = roots[i]
if inFromSpace(root):
rootCopy = copyObject(&allocationPtr, root)
setForwardingAddress(root, rootCopy)
roots[i] = rootCopy
while scanPtr < allocationPtr:
obj = object at scanPtr
scanPtr += size(obj)
n = sizeInWords(obj)
for i = 0..n:
if isPointer(obj[i]) and not inOldSpace(obj[i]):
fromNeighbor = obj[i]
if hasForwardingAddress(fromNeighbor):
toNeighbor = getForwardingAddress(fromNeighbor)
else:
toNeighbor = copyObject(&allocationPtr, fromNeighbor)
setForwardingAddress(fromNeighbor, toNeighbor)
obj[i] = toNeighbor
def copyObject(*allocationPtr, object):
copy = *allocationPtr
*allocationPtr += size(object)
memcpy(copy, object, size(object))
return copy
写屏障,神秘因素(Write barriers: the secret ingredient)
扫描From区域对象的时候,怎么快速发现是否有老区对象的指针指向了该对象呢?显然不能把老区扫描一遍。
为了解决这个问题,实际上在store buffer中维护了一份指针列表,包含老区指向新区对象的指针。(store buffer不知道是不是处理器架构中说的那个)
当一个对象刚被创建出来,并没有指针指向它。当老区里的对象的属性指向这个新区里的对象的时候,把这个字段的位置记录在store buffer中。为了做到这一点,我们在多数存储后执行一段探测和记录这些指针的代码,叫做write barriers。
写屏障会带来消耗,但并不太大,因为写不如读频繁。其他有些GC算法使用读屏障,需要硬件支持来减小代价。
还有一些优化措施来减小代价:
1,多数执行时间被用于Crankshaft生成的优化过的代码。很多时候,Crankshaft会静态的证明一个对象是在新区,写屏障也因此会省略。
2,Crankshaft有一项新的优化,当没有非本地(non-local)的引用关联到对象时,把对象配置在栈(stack)中。配置在栈中的存储显然不需要写屏障。
3,老区到新区的指针相对来说比较少,因此我们可以通过快速探测新区到新区和老区到老区的指针来针对这些常见的情况进行优化。每个Page都是1MB对其的,给定一个对象地址,我们可以通过mask掉低位20位来找到它所属的Page。Page的头包含了它们是在新区还是老区的信息,因此通过几个指令就能查到两个对象都是在新区或者老区。
4,一旦找到了老区到新区的指针,就把指针地址记录到store buffer的末尾。当store buffer满了的时候,进行整理,排序并去掉重复的,去掉已经被重写并且不再指向新区的记录。
标记-清除 标记-压缩
Scavenge算法可以对数量小的内存进行快速的回收和压缩,但空间占用太大,因此对动辄几百兆大小的老区不适用。针对老区,我们使用标记-清除和标记-压缩算法。
这两个算法分为两个阶段,标记阶段和清除/压缩阶段。
标记阶段,所有堆中的存活对象都被发现并标记。每个Page都包含一个标记位图(marking bitmap),一位(bit)标记一个可配置的字(word)。这是必须的,因为对象可以从任何字对齐的位置开始。显然,这会产生内存占用(32位系统是3.1%, 1/32;64位系统是1.6%,1/64),但所有的内存管理系统都有一些消耗,这是很合理的。 对象至少有两个字的长度,因此这些位(bit)肯定不会重叠。
有三种标记状态:
白色表示对象还没有被GC发现。
灰色表示对象已经被GC发现,但它的临近并没有被完全处理完。
黑色表示对象已经被发现,并且它所有的临近都已经被处理完。
标记算法是深度优先搜索(depth-first-search),你可以把堆想成一个由指针连接起来的对象图谱。
在标记轮的开始,标记位图是空的,所有的对象都是白色的。从根对象可抵达的对象被标记为灰色,然后压入标记队列——一个单独配置的缓冲区用来存储正在处理的对象。随后的每个步骤中,GC从队列中弹出一个对象,标记为黑色,标记其临近的白色对象为灰色,把它们压入队列。当队列空了,并且所有被GC发现的对象都被标记为黑色时,算法终止。
非常大的对象,比如长的数组,会被分开进行处理以减少队列溢出的几率。如果队列真的溢出了,对象仍然被标记为灰色,但是并不被压入队列。当队列空了的时候,GC必须扫描堆中的灰色对象,把它们压入队列,然后再开始标记。
当标记算法结束的时候,所有的存活对象都是黑色的,死对象仍然是白色的。这些结果随后被用于清除或者压缩阶段。
一旦标记阶段完成,就可以通过清除或者压缩来回收内存。这两种算法都工作在Page级别。(记住,V8的Page是1MB大小连续的块,这不同于虚拟内存的Page)。
清除算法扫描连续的死对象,转化为可用空间,并添加到可用列表。每个Page都维护独立的可用空间列表(Free lists),分为小区域(<256字),中区域(<2048字),大区域(<16384字)和极大区域(更大的)。
清除算法超级简单:它只是迭代Page的标记位图,寻找未标记的对象。可用空间列表(Free lists)主要被用于scavenge算法来提交存活对象到老区,但也用于压缩算法来重新配置对象。某些类型的对象只能被配置到老区,因此可用空间列表这时候也有用。
压缩算法通过把对象从碎片多的页(包含一些小的可用空间)移动到其他页的可用空间中来减少实际内存占用。如果需要,会配置到新的页。一旦某个页被腾空了,就可以把它释放给OS。
移动过程实际上是相当复杂的,这里不讲细节。基本上,每个待疏散页面的活对象会被配置到另一个页中。这些对象被复制到新分配的空间,原对象的第一个字中会被写入转移地址(forwarding address)。在疏散过程中,被疏散对象之间的指针会被记录下来,一旦疏散完成,V8会迭代这个记录指针位置的列表,用新的副本来更新指针。不同页的指针地址在标记阶段就被记录下来了,因此其他页的指针也在这时被更新。 注意,如果一个页变得太受欢迎,如,有太多其他页的指针指向该页的对象,那么这个页的指针位置记录就不可用了,这个页的疏散要等到下一次GC循环。
伪码:
markingDeque = []
overflow = false
def markHeap():
for root in roots:
mark(root)
do:
if overflow:
overflow = false
refillMarkingDeque()
while !markingDeque.isEmpty():
obj = markingDeque.pop()
setMarkBits(obj, BLACK)
for neighbor in neighbors(obj):
mark(neighbor)
while overflow
def mark(obj):
if markBits(obj) == WHITE:
setMarkBits(obj, GREY)
if markingDeque.isFull():
overflow = true
else:
markingDeque.push(obj)
def refillMarkingDeque():
for each obj on heap:
if markBits(obj) == GREY:
markingDeque.push(obj)
if markingDeque.isFull():
overflow = true
return
增量标记和懒清除 (Incremental marking and lazy sweeping)
你可能已经想到了,标记清除和标记压缩在处理活对象很多的很大的堆时是相当耗时的。当我开始工作于V8时,基本上很难见到因为GC导致的暂停落在500-1000ms之间的。这显然很难接受,即使是移动设备。
在2012年中,Google引入了两项改进,显著减少了GC暂停:增量标记和懒清除。
增量标记使得堆的标记在一系列小的暂停中进行,差不多每次5-10ms(移动设备中)。
增量标记在堆达到某个阈值时开始。每当一定量的内存被配置后,执行(execution)就暂停以进行增量标记。增量标记和常规标记一样,基本上是深度优先搜索,它使用同样的白灰黑系统来区分对象。区别是,增量标记过程中,因为不能一次处理完成,对象图谱是变化的!我们需要注意的主要问题是黑色对象创建的指向白色对象的指针。回想一下,黑色对象已经完全被GC扫描过了,不会被再次扫描,所以如果在两个小的增量GC之间,创建了一个黑色到白色的指针,GC的最终结果是我们把活对象当做了死对象。
写屏障会有一次拯救我们。它们不止记录了老区到新区的指针,还探测黑色到白色的指针。当探测到这样的指针时,黑色对象变为灰色对象并被压入标记队列。随后标记算法弹出并处理这个对象,它的(内部)指针会被重新扫描,于是白色对象被发现了。世界秩序得到了维护。。。
增量标记完成后,懒清除就开始了。内存清除不必须一次完成,延迟清除并不会真的影响到什么。所以GC会在需要的基础上进行清理知道最后完成全部工作。此时,GC循环完成了,增量标记也得到释放,可以开始下一次工作了。
Google最近增加了并行清除的支持。由于主执行线程不会涉及死对象,页的清除工作可以交给单独的线程以最小的同步来进行。还有一些关于并行标记的活动,但目前还是早期实验阶段。
附:store buffer 简介, 参考:http://www.tuicool.com/articles/a6Jnqm
SB 的作用是通过缓冲存储操作,从而加快存储操作。
其原理是这样的:当执行存储操作时,可能需要通过 WB_BIU 将要写的数据写入外部 Memory ,尤其是在通写法模式下,每次执行存储操作都要将数据写入外部 Memory ,这样会等待外部 Memory 完成存储操作,在此期间, CPU 处于暂停状态,降低了 CPU 的效率。
引入 SB后,如果是存储操作,那么 SB 模块将本次操作保存起来,同时立即向 DCache 返回一个存储完成信号( dcsb_ack_o 为 1 ),使得 CPU 可以继续执行,然后 SB 模块会接着完成被其保存起来的存储操作。在 SB 内部有一个 FIFO (先入先出队列)作为缓冲,如果是连续的多个存储操作,那么会将每个存储操作都存放在 FIFO 中,并向 DCache 返回存储完成信号,然后 SB 从 FIFO 中取出要保存的数据,完成存储操作。
博客地址:http://www.cnblogs.com/jasonxuli/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号