

【AI学习笔记5】用C语言实现一个最简单的MLP网络 A simple MLP Neural Network in C language
用C语言实现一个最简单的MLP网络 A simple MLP Neural Network in C language
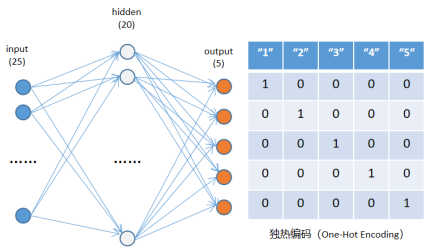
一、从图像中识别英文字母【1】
- 从图像中识别多个不同的数字,属于多分类问题;
- 每个图像是5*5的像素矩阵,分别包含1-5五个字母数字;

- 网络结构:一个隐藏层的MLP网络;
每个图像是5x5个像素,因此网络输入是25个节点;
输出是五分类,因此是5个节点;
隐藏层可以取20个节点,激活函数用sigmoid。
二、C语言代码实现MLP模型的训练(Training)【1】
#include "stdio.h"
#include "stdlib.h"
#include "math.h"
#define TRAIN_NUMS 5
#define TEST_NUMS 5
#define ROWS 5
#define COLS 5
#define INPUT_NUMS (ROWS * COLS)
#define HIDDEN_NUMS 20
#define OUTPUT_NUMS 5
#define LEARNING_RATE 0.01
#define EPOCHS 100000
// 训练数据
float train_inputs[TRAIN_NUMS][ROWS * COLS] = {
{0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0},
{1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1},
{1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1},
{1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0},
{1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1},
};
float train_labels[5] = { 1, 2, 3, 4, 5 };
// 测试数据
float test_inputs[TEST_NUMS][ROWS * COLS] = {
{1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1},
{1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1},
{1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0},
{0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0},
{1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1},
};
float test_labels[5] = { 3, 2, 4, 1, 5 };
float hiddens[HIDDEN_NUMS];
float outputs[OUTPUT_NUMS];
float weights0[INPUT_NUMS][HIDDEN_NUMS]; //input --> hidden
float weights1[HIDDEN_NUMS][OUTPUT_NUMS]; //hidden --> output
float errs_output[OUTPUT_NUMS], errs_hidden[HIDDEN_NUMS];
// sigmoid激活函数
double sigmoid(double x) {
return 1.0 / (1.0 + exp(-x));
}
// probnorm概率归一化函数
void probnorm(float* outputs, int n) {
float sum = 0.0;
float maxprob = 0.0, probsum = 0.0;
int maxid = 0;
for (int i = 0; i < n; i++) {
sum += outputs[i];
if (outputs[i] > maxprob) {
maxid = i;
maxprob = outputs[i];
}
}
for (int i = 0; i < n; i++) {
outputs[i] = outputs[i] / sum;
}
outputs[maxid] = 0.0;
probsum = 0.0;
for (int i = 0; i < n; i++) {
probsum += outputs[i];
}
outputs[maxid] = 1.0 - probsum;
}
// 前向传播函数
void forward(float* inputs) {
for (int i = 0; i < HIDDEN_NUMS; i++) {
float sum = 0.0;
for (int j = 0; j < INPUT_NUMS; j++) {
sum += inputs[j] * weights0[j][i];
}
hiddens[i] = sigmoid(sum);
}
for (int i = 0; i < OUTPUT_NUMS; i++) {
float sum = 0.0;
for (int j = 0; j < HIDDEN_NUMS; j++) {
sum += hiddens[j] * weights1[j][i];
}
outputs[i] = sigmoid(sum);
}
probnorm(outputs, OUTPUT_NUMS);
}
// 反向传播函数
void backward(float* inputs, float label) {
for (int i = 0; i < OUTPUT_NUMS; i++) {
errs_output[i] = ((i == (int)(label-1)) ? 1.0 : 0.0) - outputs[i];
}
for (int i = 0; i < HIDDEN_NUMS; i++) {
errs_hidden[i] = 0.0f;
for (int j = 0; j < OUTPUT_NUMS; j++) {
errs_hidden[i] += errs_output[j]*weights1[i][j];
}
}
for (int i = 0; i < INPUT_NUMS; i++) {
for (int j = 0; j < HIDDEN_NUMS; j++) {
weights0[i][j] += LEARNING_RATE * errs_hidden[j] * inputs[i];
}
}
for (int i = 0; i < HIDDEN_NUMS; i++) {
for (int j = 0; j < OUTPUT_NUMS; j++) {
weights1[i][j] += LEARNING_RATE * errs_output[j] * hiddens[i];
}
}
}
// 训练函数
void train() {
for (int i = 0; i < TRAIN_NUMS; i++) {
forward(train_inputs[i]);
backward(train_inputs[i], train_labels[i]);
}
}
// 测试函数
void test() {
int num_correct = 0;
for (int i = 0; i < TEST_NUMS; i++) {
forward(test_inputs[i]);
for (int k = 0; k < OUTPUT_NUMS; k++) {
printf("o[%d]=%f ", k, outputs[k]);
}
printf("\n");
int prediction = 0;
for (int j = 1; j < OUTPUT_NUMS; j++) {
if (outputs[j] > outputs[prediction]) {
prediction = j;
}
}
if (prediction == (test_labels[i]-1)) {
num_correct++;
}
printf("Prediction = %d\n", prediction+1);
}
double accuracy = (double)num_correct / TEST_NUMS;
printf("Test Accuracy = %f\n", accuracy);
}
int main() {
// 初始化权重
for (int i = 0; i < INPUT_NUMS; i++) {
for (int j = 0; j < HIDDEN_NUMS; j++) {
weights0[i][j] = (double)rand() / RAND_MAX - 0.5;
}
}
for (int i = 0; i < HIDDEN_NUMS; i++) {
for (int j = 0; j < OUTPUT_NUMS; j++) {
weights1[i][j] = (double)rand() / RAND_MAX - 0.5;
}
}
// 训练模型
for (int epoch = 0; epoch < EPOCHS; epoch++) {
train();
}
// 测试模型
test();
return 0;
}
三、推理结果(Inference)
在Cygwin环境下用gcc编译compile,然后训练,再执行推理,结果如下:
o[0]=0.000215 o[1]=0.000933 o[2]=0.998017 o[3]=0.000001 o[4]=0.000834
Prediction = 3
o[0]=0.000177 o[1]=0.998267 o[2]=0.000925 o[3]=0.000219 o[4]=0.000412
Prediction = 2
o[0]=0.000034 o[1]=0.000301 o[2]=0.000000 o[3]=0.999175 o[4]=0.000489
Prediction = 4
o[0]=0.999439 o[1]=0.000209 o[2]=0.000182 o[3]=0.000005 o[4]=0.000164
Prediction = 1
o[0]=0.000077 o[1]=0.000362 o[2]=0.000774 o[3]=0.000398 o[4]=0.998389
Prediction = 5
Test Accuracy = 1.000000
Accuracy为100%,是因为使用的test_inputs和train_inputs完全相同,如果test_inputs改为不同的5x5像素矩阵,则Accuracy会降低。要想提高准确率,则需要更多的训练数据(train_inputs)。
参考文献(References):
【1】 septemc 《使用C语言实现神经网络进行数字识别》
https://blog.csdn.net/Septem_ccn/article/details/132589351
posted on 2025-01-05 14:16 JasonQiuStar 阅读(20) 评论(0) 编辑 收藏 举报
