

pandas入门
一、pandas数据结构
pandas有两个主要数据结构:Series,DataFrame
import numpy as np
from pandas import Series, DataFrame
1、Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。
Series的字符串表现形式为:索引在左边,值在右边。
①用数组生成Series
②指定Series的index
③使用字典生成Series
④使用字典生成Series,并额外指定index,不匹配部分为NaN
⑤Series相加,相同索引部分相加
⑥指定Series及其索引的名字
⑦替换index


#!/usr/bin/evn python
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series
print ('①用数组生成Series')
obj = Series([4, 7, -5, 3])
print(obj)
print(obj.values)
print(obj.index)
print('=='*20)
print('②指定Series的index')
obj2 = Series([4, 7, -5, 3], index = ['d', 'b', 'a', 'c'])
print(obj2)
print(obj2.index)
print(obj2['a'])
obj2['d'] = 6
print(obj2[['c', 'a', 'd']])
print(obj2[obj2 > 0]) # 找出大于0的元素
print('b' in obj2) # 判断索引是否存在
print('e' in obj2)
print('=='*20)
print('③使用字典生成Series')
sdata = {'Ohio':45000, 'Texas':71000, 'Oregon':16000, 'Utah':5000}
obj3 = Series(sdata)
print(obj3)
print('=='*20)
print('④使用字典生成Series,并额外指定index,不匹配部分为NaN。')
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj4 = Series(sdata, index = states)
print(obj4)
print('=='*20)
print('⑤Series相加,相同索引部分相加。')
print(obj3 + obj4)
print('=='*20)
print('⑥指定Series及其索引的名字')
obj4.name = 'population'
obj4.index.name = 'state'
print(obj4)
print('=='*20)
#
print('⑦替换index')
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
print(obj)
2、DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
①用字典生成DataFrame,key为列的名字
②指定索引,在列中指定不存在的列,默认数据用NaN
③用Series指定要修改的索引及其对应的值,没有指定的默认数据用NaN
④赋值给新列,删除列
⑤DataFrame转置
⑥指定索引顺序,以及使用切片初始化数据
⑦指定索引和列的名称
#!/usr/bin/evn python # -*- coding: utf-8 -*- import numpy as np from pandas import Series, DataFrame print('①用字典生成DataFrame,key为列的名字。') data = {'state':['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'], 'year':[2000, 2001, 2002, 2001, 2002], 'pop':[1.5, 1.7, 3.6, 2.4, 2.9]} print(DataFrame(data)) print(DataFrame(data, columns = ['year', 'state', 'pop'])) # 指定列顺序 print('②指定索引,在列中指定不存在的列,默认数据用NaN。') frame2 = DataFrame(data, columns = ['year', 'state', 'pop', 'debt'], index = ['one', 'two', 'three', 'four', 'five']) print(frame2) print(frame2['state']) print(frame2.year) print(frame2.ix['three']) frame2['debt'] = 16.5 # 修改一整列 print(frame2) frame2.debt = np.arange(5) # 用numpy数组修改元素 print(frame2) print('③用Series指定要修改的索引及其对应的值,没有指定的默认数据用NaN。') val = Series([-1.2, -1.5, -1.7], index = ['two', 'four', 'five']) frame2['debt'] = val print(frame2) print('④赋值给新列') frame2['eastern'] = (frame2.state == 'Ohio') # 如果state等于Ohio为True print(frame2) print(frame2.columns) print('⑤DataFrame转置') pop = {'Nevada':{2001:2.4, 2002:2.9}, 'Ohio':{2000:1.5, 2001:1.7, 2002:3.6}} frame3 = DataFrame(pop) print(frame3) print(frame3.T) print('⑥指定索引顺序,以及使用切片初始化数据。') print(DataFrame(pop, index = [2001, 2002, 2003])) print(frame3['Ohio'][:-1]) print(frame3['Nevada'][:2]) pdata = {'Ohio':frame3['Ohio'][:-1], 'Nevada':frame3['Nevada'][:2]} print(DataFrame(pdata)) print('⑦指定索引和列的名称') frame3.index.name = 'year' frame3.columns.name = 'state' print(frame3) print(frame3.values) print(frame2.values)
可以输入给DataFrame构造器的数据
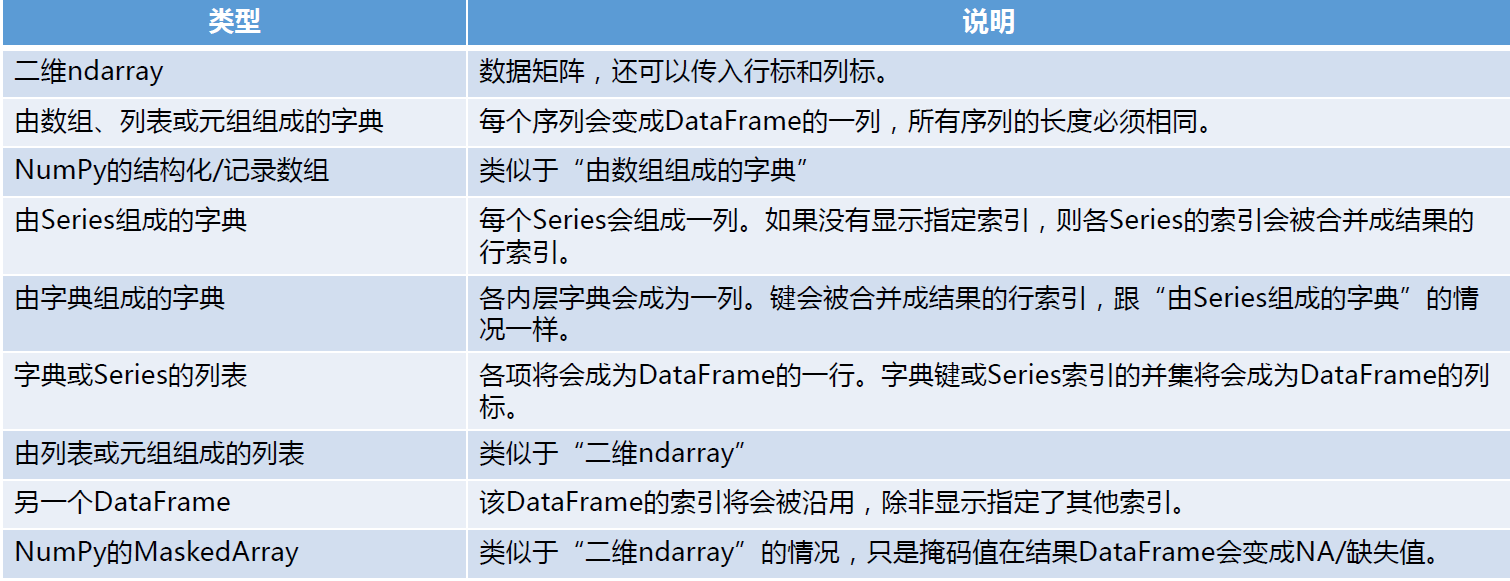
3、索引对象
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index:
①获取index
②使用Index对象
③判断列和索引是否存在
#!/usr/bin/evn python # -*- coding: utf-8 -*- import numpy as np import pandas as pd import sys from pandas import Series, DataFrame, Index print('①获取index') obj = Series(range(3), index = ['a', 'b', 'c']) index = obj.index print(index[1:]) try: index[1] = 'd' # index对象read only except: print(sys.exc_info()[0]) print('②使用Index对象') index = Index(np.arange(3)) obj2 = Series([1.5, -2.5, 0], index = index) print(obj2) print(obj2.index is index) print('③判断列和索引是否存在') pop = {'Nevada':{20001:2.4, 2002:2.9}, 'Ohio':{2000:1.5, 2001:1.7, 2002:3.6}} frame3 = DataFrame(pop) print('Ohio' in frame3.columns) print('2003' in frame3.index)
二、基本功能
1、重新索引
pandas对象的一个重要方法是reindex,其作用是创建一个适应新索引的新对象。
对于DataFrame,reindex可以修改(行)索引、列,或两个都修改。如果仅传入一个序列,则会重新索引行。
①重新指定索引及顺序
②重新指定索引并指定元素填充方法
③对DataFrame重新指定索引
④重新指定columns,使用columns关键字即可重新索引列
⑤对DataFrame重新指定索引(reindex,ix)并指定填元素充方法
#!/usr/bin/evn python # -*- coding: utf-8 -*- import numpy as np from pandas import DataFrame, Series print('①重新指定索引及顺序') obj = Series([4.5, 7.2, -5.3, 3.6], index = ['d', 'b', 'a', 'c']) print(obj) obj2 = obj.reindex(['a', 'b', 'd', 'c', 'e']) print(obj2) print(obj.reindex(['a', 'b', 'd', 'c', 'e'], fill_value = 0)) # 指定不存在元素的默认值 print('②重新指定索引并指定元素填充方法') obj3 = Series(['blue', 'purple', 'yellow'], index = [0, 2, 4]) print(obj3) print(obj3.reindex(range(6), method = 'ffill')) #ffill可以实现前向值填充 print('③对DataFrame重新指定索引') frame = DataFrame(np.arange(9).reshape(3, 3), index = ['a', 'c', 'd'], columns = ['Ohio', 'Texas', 'California']) print(frame) frame2 = frame.reindex(['a', 'b', 'c', 'd']) print(frame2) print('④重新指定column') states = ['Texas', 'Utah', 'California'] print(frame.reindex(columns = states)) print('⑤对DataFrame重新指定索引并指定填元素充方法') print(frame.reindex(index = ['a', 'b', 'c', 'd'], method = 'ffill', columns = states)) print(frame.ix[['a', 'b', 'd', 'c'], states])
reindex函数的参数

2、丢弃指定轴上的对象
方法很简单,只要有一个索引数组或者列表即可,drop方法返回的是一个在指定轴上删除了指定值的新对象。
①Series根据索引删除元素
②DataFrame删除元素,可指定索引或列
#!/usr/bin/evn python # -*- coding: utf-8 -*- import numpy as np from pandas import Series, DataFrame print('①Series根据索引删除元素') obj = Series(np.arange(5.), index = ['a', 'b', 'c', 'd', 'e']) new_obj = obj.drop('c') print(new_obj) print(obj.drop(['d', 'c'])) print('②DataFrame删除元素,可指定索引或列。') data = DataFrame(np.arange(16).reshape((4, 4)), index = ['Ohio', 'Colorado', 'Utah', 'New York'], columns = ['one', 'two', 'three', 'four']) print(data) print(data.drop(['Colorado', 'Ohio'])) print(data.drop('two', axis = 1)) print(data.drop(['two', 'four'], axis = 1))
3、索引、选取和过滤
- Series索引(obj[...])的工作方式类似于NumPy数组的索引,只不过Series的索引值不只是整数。
- 利用标签的切片运算与普通的Python切片运算不同,其末端是包含的(inclusive)。
- 对DataFrame进行索引其实就是获取一个或多个列。
- 为了在DataFrame的行上进行标签索引,引入了专门的索引字段ix。
①Series的索引,默认数字索引可以工作
②Series的数组切片
③DataFrame的索引
④根据条件选择
#!/usr/bin/evn python # -*- coding: utf-8 -*- import numpy as np from pandas import Series, DataFrame print('①Series的索引,默认数字索引可以工作。') obj = Series(np.arange(4.), index = ['a', 'b', 'c', 'd']) print(obj) print(obj['b']) print(obj[3]) print(obj[[1, 3]]) print(obj[obj < 2]) print('②Series的数组切片') print(obj['b':'c']) # 闭区间,这一点和python不同 obj['b':'c'] = 5 print(obj) print('③DataFrame的索引') data = DataFrame(np.arange(16).reshape((4, 4)), index = ['Ohio', 'Colorado', 'Utah', 'New York'], columns = ['one', 'two', 'three', 'four']) print(data) print(data['two']) # 打印列 print(data[['three', 'one']]) print(data[:2]) print(data.ix['Colorado', ['two', 'three']]) # 指定索引和列 print(data.ix[['Colorado', 'Utah'], [3, 0, 1]]) print(data.ix[2]) # 打印第2行(从0开始) print(data.ix[:'Utah', 'two']) # 从开始到Utah,第2列。 print('④根据条件选择') print(data[data.three > 5]) print(data < 5) # 打印True或者False data[data < 5] = 0 print(data)
DataFrame的索引选项

4、算术运算和数据对齐
- 对不同的索引对象进行算术运算
- 自动数据对齐在不重叠的索引处引入了NA值,缺失值会在算术运算过程中传播
- 对于DataFrame,对齐操作会同时发生在行和列上
- fill_value参数
- DataFrame和Series之间的运算
①Series的加法
②DataFrame加法,索引和列都必须匹配
③数据填充
④DataFrame与Series之间的操作
#!/usr/bin/evn python # -*- coding: utf-8 -*- import numpy as np from pandas import Series, DataFrame print('①Series的加法') s1 = Series([7.3, -2.5, 3.4, 1.5], index = ['a', 'c', 'd', 'e']) s2 = Series([-2.1, 3.6, -1.5, 4, 3.1], index = ['a', 'c', 'e', 'f', 'g']) print(s1) print(s2) print(s1 + s2) print('②DataFrame加法,索引和列都必须匹配。') df1 = DataFrame(np.arange(9.).reshape((3, 3)), columns = list('bcd'), index = ['Ohio', 'Texas', 'Colorado']) df2 = DataFrame(np.arange(12).reshape((4, 3)), columns = list('bde'), index = ['Utah', 'Ohio', 'Texas', 'Oregon']) print(df1) print(df2) print(df1 + df2) print('③数据填充') df1 = DataFrame(np.arange(12.).reshape((3, 4)), columns = list('abcd')) df2 = DataFrame(np.arange(20.).reshape((4, 5)), columns = list('abcde')) print(df1) print(df2) print(df1.add(df2, fill_value = 0)) print(df1.reindex(columns = df2.columns, fill_value = 0)) print('④DataFrame与Series之间的操作') arr = np.arange(12.).reshape((3, 4)) print(arr) print(arr[0]) print(arr - arr[0]) frame = DataFrame(np.arange(12).reshape((4, 3)), columns = list('bde'), index = ['Utah', 'Ohio', 'Texas', 'Oregon']) series = frame.ix[0] print(frame) print(series) print(frame - series) series2 = Series(range(3), index = list('bef')) print(frame + series2) series3 = frame['d'] print(frame.sub(series3, axis = 0)) # 按列减

