

知识图谱介绍 (1)
大家好,我是一名知识图谱领域在读博士生。从这篇文章开始,我将陆续写一系列系统介绍知识图谱的文章,另外也写一些自己读到或者学到的其他有意思的东西。 写文章的目的有两个:1. 记录和分享自己的学习;2. 希望帮到想了解知识图谱的朋友,同时缓解自己意义感焦虑。 因为刚开始写,我尽量做到内容可信。有什么问题和建议,希望大家关注公号后私信我。
本文内容预告
知识图谱历史和定义,三国演义知识图谱,有了 chatgpt 为什么还需要知识图谱。
知识图谱是什么
“知识图谱” 术语最先由 Google 公司在 2012 年提出,指一种通用知识库 (knowledge base)。但它并不是什么新概念,早在上世纪 60 年代,Allan M. Collins, M. Ross Quillian, Elizabeth F. Loftus 等人就提出了语义网络 (Semantics Networks) 用于建模实体,概念,及它们之间的关系。专家系统 (Expert System) 由 Feigenbaum 等人在 1984 年提出,该系统使用领域知识和规则进行推理来帮助做决策。 Semantic Web 在 2004 年,Semantic Web 等提出了 Semantics Web 概念,作为 W3C 的标准用于规范网页数据便于机器处理。
Formal 定义:知识图谱是一个用于表示 数据 和 元数据 的图数据结构,用于建模专业领域的知识 (验证为真的信息)。 其中 数据 (Data) 包括了:
- 实体 (entity),实体的属性 (attribute),和实体之间的关系 (relation)。实体是一个具体对象。比如某个人物:特朗普,某个地方:德国,还可以是某个电影,某本书等等。 元数据 (Metadata) 包括了所有描述数据的数据:
- 实体的类别 (Type):特朗普的类别为人,美国人。
- 本体 (Ontology): 包含某个领域的概念抽象表示:类 (Class) ,属性 (Property)的定义。以及类之间的关系,属性之间的关系的定义。比如 “人” 类,“女人“ 类;”年龄“属性;”女人“是”人“的子类 (”女人“是”人“的子类)。
- 出处信息 (Provenance): 比如知识图谱的创建者,创建时间,该知识图谱的唯一标识符。
- 数据来源 (Sources): 描述这个知识图谱中的数据来源。比如某本书的信息来自豆瓣。
三国演义知识图谱
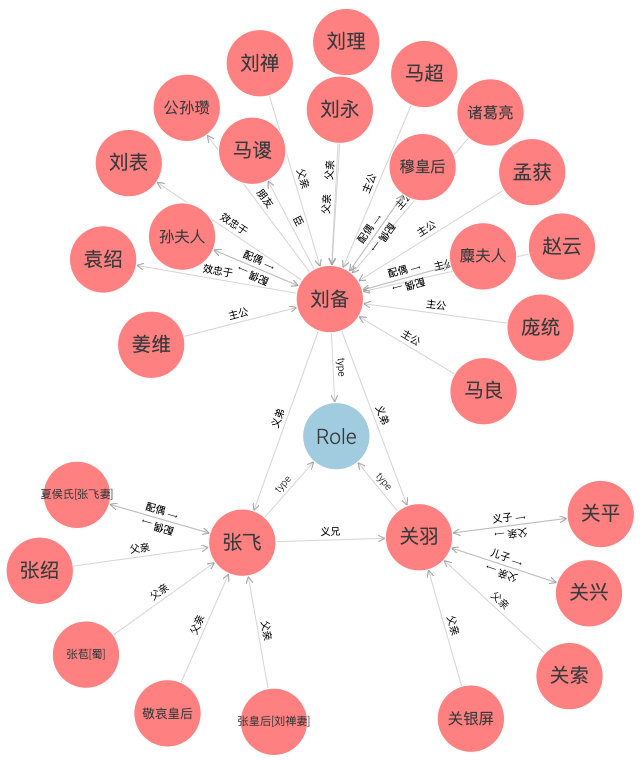
上面就这个真实知识图谱来具体说知识图谱里面包含的东西:
数据部分:
- 上面所有的红色节点都是实体,即某个具体的人物。
- 还有节点之间的具体的边,即实体之间的关系。
元数据部分:
- Role 就是一个实体类别。
- 这个图没有展示本体的所有内容,我们可以猜想到的有
- 类:"Role" (人物) 是一个类;
- 关系属性 (Object Property):"义兄","臣","主公","配偶" 等;
- 属性之间的关系:我能可以猜想到 ”臣“ 与 "主公” 之间存在反向 (inverse of) 关系。
- 该知识图谱出自中文开放知识图谱:http://openkg.cn/dataset/sanguoyanyi,创建于 2021年十一月29号。
为什么需要知识图谱
从数据模型层面来说为什么我们需要知识图谱?
我们其实已经有了关系数据模型 (Relational Data Model),对就是我们学过的数据库里面讲的那些表,属性,主/外键,还有关系代数。而知识图谱背后的数据模型是 RDF (Resource Description Framework)。它们的差别在哪呢?
| RDF 模型 | 关系数据模型 |
|---|---|
| 数据建模为三元组 | 数据建模为关系的集合 |
| semi-structured: 可以存在没有类型的数据,数据扩展很灵活。 | strict-typed: 任何数据需要预先定义类型: INT, CHAR, VARCHAR 等;强制性满足数据完整性限制:key constraints |
| 可以建模存在变量为 Blank Node,和 NULL 的含义区分 | NULL 的语义不清晰: “不知道”和“不存在”混淆,比如某个人的父亲为 NULL 对比他的孩子为 NULL意义是不一样的,他一定存在一个“不知道”的父亲,但他可能“不存在”孩子 |
| RDF 模型基于开放世界假设,模型内没有的数据可能为真 | 关系数据模型基于封闭世界假设,模型内没有的数据都为假 |
总结来说,知识图谱数据模型更灵活,易于扩展,语义比关系数据模型丰富。
与大语言模型区别
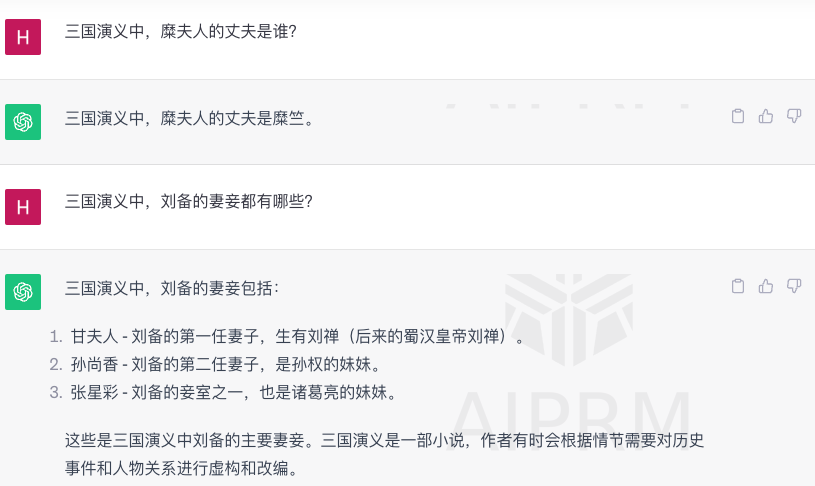
- 我们先问下 chatgpt 两个问题:(1) 糜夫人的丈夫是谁?;(2) 刘备的妻妾都有哪些?
- 然后我们到 DBpeida 知识图谱上查询
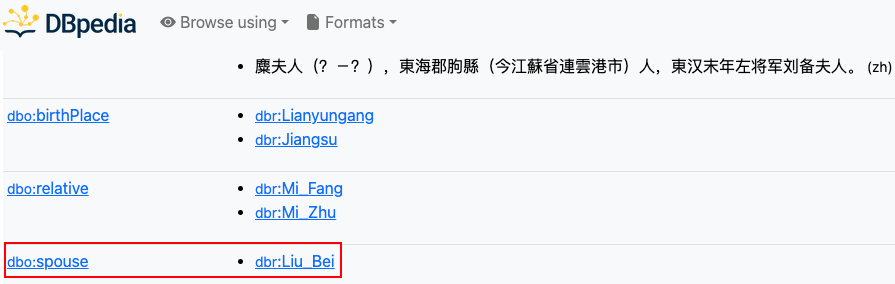
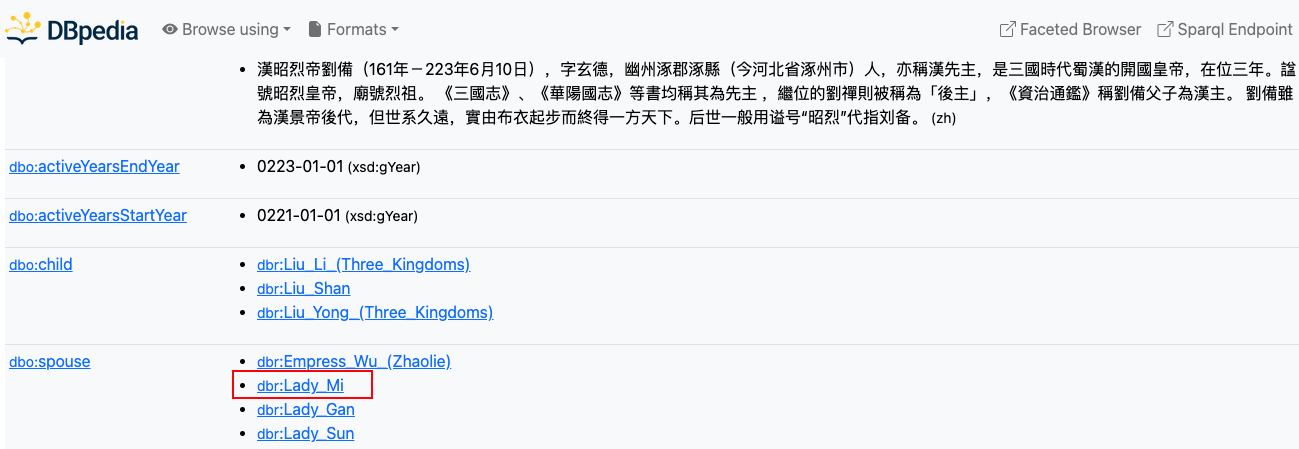 通过对比,我们可以发现,chatgpt 的第一个答案是错误的,第二个答案中的 “张彩星” 根本不是三国演义中的人物,而是在《三国杀》《真三国无双》等网络游戏中的人物。chatgpt 这类联结主义方法并不是所有问题都能正确回答,它不具备很好的逻辑推理能力 (找的证据有时看起来像那么回事,实际是错误的),对低频实体(糜夫人)的理解效果差,但是推理速度很快。而知识图谱构建的是知识 (验证为真的信息),并且具备一定的逻辑推理能力,数据透明,可以提供可靠的解释,但是它的推理速度慢,可回答的问题受限于建模的知识数量。
通过对比,我们可以发现,chatgpt 的第一个答案是错误的,第二个答案中的 “张彩星” 根本不是三国演义中的人物,而是在《三国杀》《真三国无双》等网络游戏中的人物。chatgpt 这类联结主义方法并不是所有问题都能正确回答,它不具备很好的逻辑推理能力 (找的证据有时看起来像那么回事,实际是错误的),对低频实体(糜夫人)的理解效果差,但是推理速度很快。而知识图谱构建的是知识 (验证为真的信息),并且具备一定的逻辑推理能力,数据透明,可以提供可靠的解释,但是它的推理速度慢,可回答的问题受限于建模的知识数量。
关注不走丢,欢迎反馈、点赞、加星

参考
- Scientific Data Management & Knowledge Graph, by Maria-Esther Vidal
- Chaudhri, Vinay, et al. "Knowledge graphs: introduction, history and, perspectives." AI Magazine 43.1 (2022): 17-29.
- 三国演义数据来源1: https://github.com/wcswcswcs/sgyy
- 三国演义数据来源2: http://openkg.cn/dataset/sanguoyanyi


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现