记一次面试题
题目: 简单表设计并且写出sql语句,购物订单系统里面“所有订单”功能,一个订单包含多个产品,一个产品也可能被不同的订单包含,请写出针对于产品名称搜索的订单分页sql,包含订单详情,按照创建订单时间倒叙排列(用mysql数据库写)
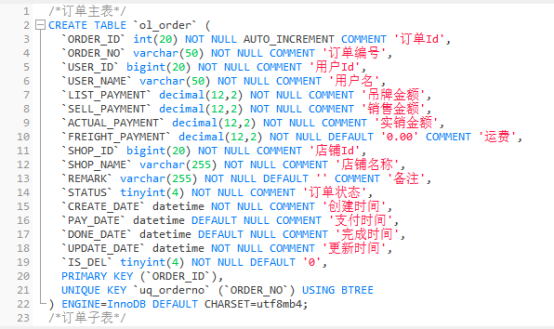
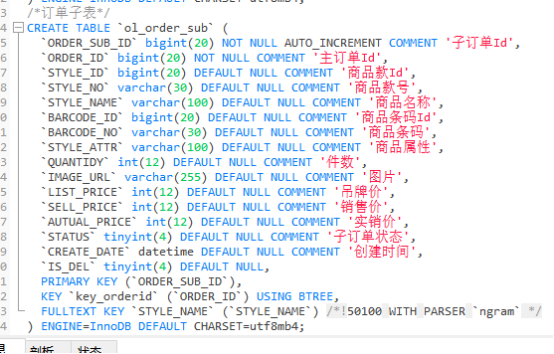
- 根据业务分析,由于订单与商品为一对多的关系 需创建订单主表和订单子表。
- 订单主表需要订单编号保证唯一性(防止重复建单),所以需要将ORDER_NO设置为唯一索引
- 订单子表需要根据商品名称模糊查询,根据索引的最左匹配原则,like无法满足此种需求场景( style_name like “%测试%” 无法命中索引,全表扫描),所以我选择用倒排索引的方式,为style_name字段创建全文索引,存在根据ORDER_ID查询子表的场景,所以也为ORDER_ID创建索引。
- 生成40万条测试数据。
- 在假设根据 ORDER_ID 和 CREATE_DATE 排序的语义相同的情况下,我执行了三次测试。
- 当存在匹配结果1000条的情况下,查询时间:70ms左右
- 当存在匹配结果20万条的情况下,查询时间:2s左右
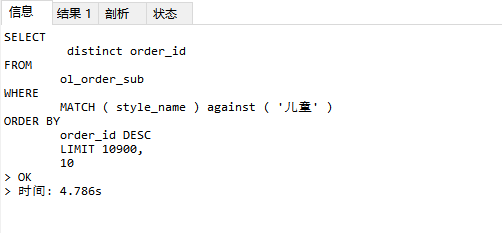
- 当存在匹配结果40万条的情况下,查询时间:5s左右
结论:经过测试结果得出使用倒排索引的方式,查询时间会随着匹配结果数量的增加而增长。但在实际的生产环境,考虑到是客服人员使用, 如果大多数查询字符串的匹配结果都在1万以下的情况的前提下,此方案是完全可行的。(如果追求更效率的查询速度可以使用Elasticsearch集群的方案。)
创建测试表
初始化数据

使用存储过程 初始化401000条订单数据。
第一次测试
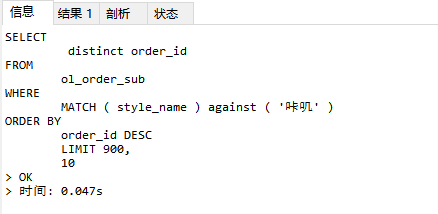
查询商品名称含有 “咔叽”的数据。表中含有1000条咔叽的数据,我直接查询最后面几页的数据,可以看到三条sql的执行时间为69ms(0.047+0.014+0.008)
- 首先利用 全文索引 根据商品名称模糊匹配获取符合条件主订单Id,
2.根据order_id分别在主订单表和子订单表查询出详情数据(此步执行时间可忽略不记)
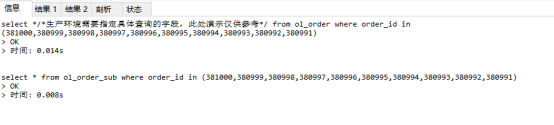
3.客户端负责将数据组装。
第二次测试
查询商品名称含有 “英语”的数据。表中含有20万条英语的数据,我直接查询最后面几页的数据,可以看到该条sql时间为1.97s,查询详情的sql与第一次测试结果相同时间可以忽略。

第三次测试
查询商品名称含有 “儿童”的数据。表中含有40万条英语的数据,我直接查询最后面几页的数据,可以看到该条sql时间为4.78s,查询详情的sql与第一次测试结果相同时间可以忽略。
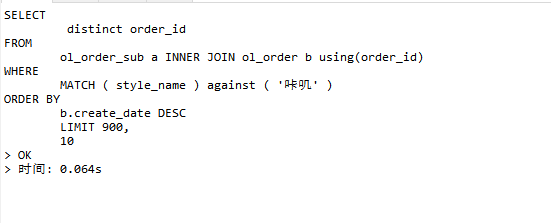
以下是使用CREATE_DATE排序的情况,但不建议为了 CREATE_DATE排序使用join的方式查询,如果ORDER_ID与CREATE_DATE排序的语义不同,建议CREATE_DATE由客户端生成,订单子表与订单主表的CREATE_DATE保持一致,然后直接通过订单子表CREATE_DATE进行排序

 浙公网安备 33010602011771号
浙公网安备 33010602011771号