


redis的缓存更新策略,缓存粒度控制
一、缓存的更新策略
缓存中的数据有生命周期,需要定期更新和删除以保证内存空间的合理使用以及缓存数据与数据库数据的一致性。
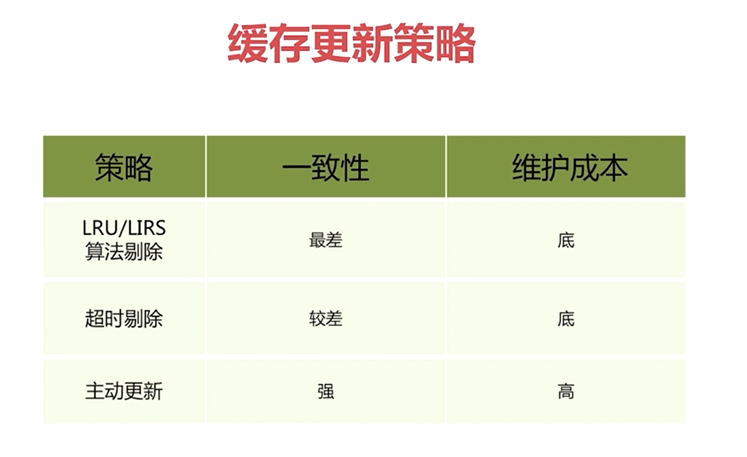
缓存数据需要根据合理的数据更新策略更新缓存中的数据,有如下三种策略:
(1)LRU/LFU/FIFO算法剔除:Redis使用maxmemory-policy,即Redis中的数据占用的内存超过设定的最大内存时的操作策略
(2)超时剔除:对缓存的数据设置过期时间,超过过期时间自动删除缓存数据,然后再次进行缓存,保证与数据库中的数据一致
(3)主动更新:开发者控制key的更新周期,当key在后端数据库中发生更新时,向Redis主动发送消息,Redis接收到消息对key进行更新或删除
# 根据LRU算法删除过期的key
volatile-lru -> remove the key with an expire set using an LRU algorithm
# 根据LRU算法删除一些key
allkeys-lru -> remove any key according to the LRU algorithm
# 随机删除一些设置了过期时间的key
volatile-random -> remove a random key with an expire set
# 从所有的key中随机删除一些key
allkeys-random -> remove a random key, any key
# 删除一些快过期的key
volatile-ttl -> remove the key with the nearest expire time (minor TTL)
# 不删除任何key,在向Redis写入key时返回一个错误,这将会占用更多的内存
noeviction -> don't expire at all, just return an error on write operations
需要注意的是:with any of the above policies, Redis will return an error on write operations, when there are no suitable keys for eviction。
即在上面的六种策略中,如果没有key可以被删除时,向Redis中写入数据会返回一个error异常。
缓存更新策略对比如下图所示:
二、缓存粒度控制

上图中,使用Redis来做缓存,底层使用MySQL来做数据存储源,这种架构下大部分请求由Redis处理,少部分请求到达MySQL。从MySQL中获取一个用户的所有信息,然后缓存到Redis的数据结构中。
此时需要面对一个问题:缓存这个用户的所有数据信息,还是缓存用户需要的用户信息字段。
可以从三个角度来考虑:
(1)通用性:从通用性角度考虑,缓存全量属性更好。
因为当用户数据表字段发生改变时,不需要修改程序就可以直接同步修改之后的用户信息到Redis缓存中供用户使用,但是这样会占用更多的内存空间。
(2)占用空间:从占用空间的角度考虑,缓存部分属性更好。
因为当用户数据表字段发生改变时而用户需要这个字段信息时,就需要修改程序源代码来把修改之后的用户信息同步缓存到Redis中,这种情况下占用的内存空间比全量属性占用的内存空间要少。
(3)代码维护:从代码维护角度考虑,表面上缓存全量属性更好。
因为不管数据源中的数据表结构如何改变,都会把所有的数据同步到Redis缓存中,而不需要修改程序源代码,但是在大多数情况下,并不会使用到全量数据,只需要缓存需要的数据就可以了。因此从内存空间消耗及性能方面考虑,缓存部分属性更好。
综合以上3点原因得出:在选择缓存属性时,需要综合考虑缓存全量属性还是部分属性。
后续待写。。。
参考博文:
(1) https://www.cnblogs.com/renpingsheng/p/10202914.html
(2) https://youzhixueyuan.com/design-performance-and-application-of-redis-cache.html (redis系列文章)
(3) https://segmentfault.com/a/1190000022029639 (Redis 缓存雪崩、击穿、穿透)

