
http协议
Http即超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP),用来在网页间传输超文本的一种协议。在这里需要了解三个内容:1、html;2、URL;3、http。
1、HTML(HyperText Markup Language),超文本标记语言;
2、URI,统一资源标识符,互联网上所有的资源都有其唯一的URI;
3、HTTP,超文本传输协议。
在开始http真正的内容之前,我们还需要了解一下什么是uri、url以及urn。因为我们几乎所有的http请求都是通过url来完成的。
URI(Uniform Resource Identifier)统一资源标志符,是一个用于标识某一互联网资源名称的字符串。HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来建立连接和传输数据。
URL(Uniform Resource Locator)统一资源定位符,如同在网络上的门牌,是因特网上标准的资源的地址,它是一种特殊类型的URI,包含了用于查找某个资源的足够的信息。
URN(Uniform Resource Name),期望为资源提供持久的、位置无关的标识方式,并允许简单地将多个命名空间映射到单个URN命名空间。
以下面这个URL为例,介绍下普通URL的各部分组成:http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
①协议部分:该URL的协议部分为http:,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP,HTTPS等。本例中使用的是HTTP协议,在HTTP后面的//为分隔符。
②域名部分:该URL的域名部分为www.aspxfans.com。一个URL中,也可以使用IP地址作为域名使用。
③端口部分:跟在域名后面的是端口,域名和端口之间使用:作为分隔符。端口不是一个URL必须的部分,如果省略端口部分将采用默认端口。
④虚拟目录部分:从域名后的第一个/开始到最后一个/为止是虚拟目录部分。本例中的虚拟目录是/news/。
⑤文件名部分:从域名后的最后一个/开始到?为止是文件名部分,如果没有?,则是从域名后的最后一个/开始到#为止,如果没有?和#,那么从域名后的最后一个/开始到结束都是文件名部分。本例中的文件名是index.asp。
⑥锚部分:从#开始到最后都是锚部分。本例中的锚部分是name。
⑦参数部分:从?开始到#为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为boardID=5&ID=24618&page=1。参数可以允许有多个参数,参数与参数之间用&作为分隔符。
一、http协议
http是Hypertext Transfer Protocol 的缩写,意为超文本传输协议。HTTP是基于TCP/IP协议的应用层协议。它不涉及数据包(packet)传输,也不关心数据传输的细节,主要规定了客户端和服务器之间的通信格式规则,默认使用80端口。简单点说就是浏览器和服务器之间进行“沟通”的一种规则协议。HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。
HTTP与HTTPS的联系与区别:HTTP协议的数据传输是明文的,是不安全的,而HTTPS使用了SSL(secure socket layer)/TLS协议进行了加密处理,是安全的协议。
https与http的主要区别:
1,https协议需要到CA机构申请ssl证书,而http协议不用认证;
2,http是超文本传输协议,信息是明文传输,而https则是具有安全性的ssl加密传输协议;
3,http和https使用不同的连接方式,用的端口也不一样,http端口是80,https端口是443;
4,http是不安全的协议,而https是由ssl+http构建的安全的协议,比http更加安全可靠。
http协议的特征:1,支持客户/服务器模式;2,简单快速;3,灵活;4,无状态。
附上一张七层网络模型图:
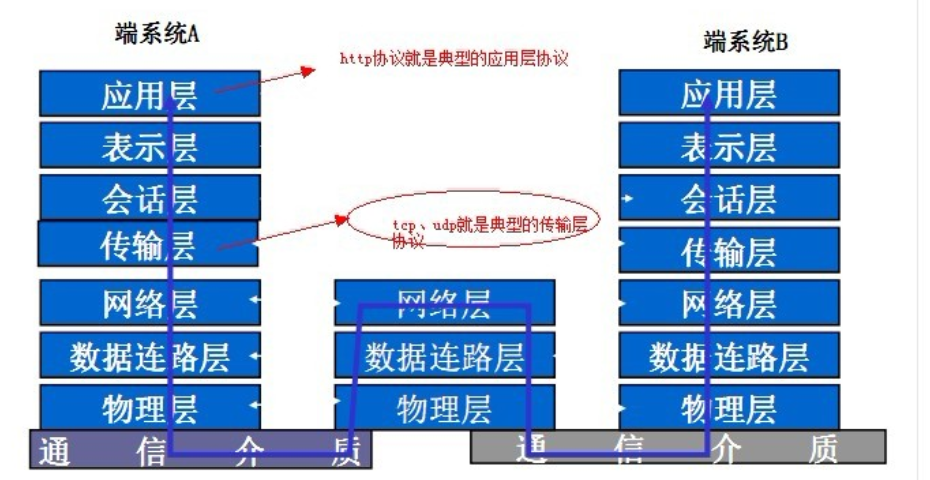
二、http协议优点
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
- 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- HTTP 0.9和1.0使用非持续连接:限制每次连接只处理一个请求,服务器处理完客户的请求,并收到客户的应答后,即断开连接。HTTP 1.1使用持续连接:不必为每个web对象创建一个新的连接,一个连接可以传送多个对象,采用这种方式可以节省传输时间。
- 无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。解决办法:1,通过cookie解决;2,通过session会话保存。
- 支持B/S和C/S模式。
三、http请求消息
一个http请求代表客户端浏览器向服务器发送的数据。一个完整的http请求消息,包含一个请求行,若干个消息头(请求头),换行,实体内容。
请求行:描述客户端的请求方式、请求资源的名称、http协议的版本号。 例如: GET/BOOK/JAVA.HTML HTTP/1.1
请求头(消息头)包含(客户机请求的服务器主机名,客户机的环境信息等):
Accept:用于告诉服务器,客户机支持的数据类型 (例如:Accept:text/html,image/*)
Accept-Charset:用于告诉服务器,客户机采用的编码格式
Accept-Encoding:用于告诉服务器,客户机支持的数据压缩格式
Accept-Language:客户机语言环境
Host:客户机通过这个服务器,想访问的主机名
If-Modified-Since:客户机通过这个头告诉服务器,资源的缓存时间
Referer:客户机通过这个头告诉服务器,它(客户端)是从哪个资源来访问服务器的(防盗链)
User-Agent:客户机通过这个头告诉服务器,客户机的软件环境(操作系统,浏览器版本等)
Cookie:客户机通过这个头,将Coockie信息带给服务器
Connection:告诉服务器,请求完成后,是否保持连接
Date:告诉服务器,当前请求的时间
(空行)
实体内容:就是指浏览器端通过http协议发送给服务器的实体数据。例如:name=dylan&id=110(get请求时,通过url传给服务器的值。post请求时,通过表单发送给服务器的值)
四、HTTP响应消息
一个http响应代表服务器端向客户端回送的数据,它包括:一个状态行,若干个消息头,空行以及实体内容。
状态行:例如:HTTP/1.1 200 OK (协议的版本号是1.1 响应状态码为200 响应结果为OK)
响应头(消息头)包含:
Location:这个头配合302状态吗,用于告诉客户端找谁
Server:服务器通过这个头,告诉浏览器服务器的类型
Content-Encoding:告诉浏览器,服务器的数据压缩格式
Content-Length:告诉浏览器,回送数据的长度
Content-Type:告诉浏览器,回送数据的类型
Last-Modified:告诉浏览器当前资源缓存时间
Refresh:告诉浏览器,隔多长时间刷新
Content-Disposition:告诉浏览器以下载的方式打开数据。例如: context.Response.AddHeader("Content-Disposition","attachment:filename=aa.jpg"); context.Response.WriteFile("aa.jpg");
Transfer-Encoding:告诉浏览器,传送数据的编码格式
ETag:缓存相关的头(可以做到实时更新)
Expries:告诉浏览器回送的资源缓存多长时间。如果是-1或者0,表示不缓存
Cache-Control:控制浏览器不要缓存数据 no-cache
Pragma:控制浏览器不要缓存数据 no-cache
Connection:响应完成后,是否断开连接。 close/Keep-Alive
Date:告诉浏览器,服务器响应时间
(空行)
实体内容(实体头):响应包含浏览器能够解析的静态内容,例如:html,纯文本,图片等等信息。
五、http响应状态码
状态代码由三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息--表示请求已接收,继续处理。
2xx:成功--表示请求已被成功接收、理解、接受。
3xx:重定向--要完成请求必须进行更进一步的操作。
4xx:客户端错误--请求有语法错误或请求无法实现。
5xx:服务器端错误--服务器未能实现合法的请求。
常见状态码:
200 OK:表示请求成功,请求被正确处理。
204:请求被受理,但是没有资源可以返回。
206:客户端只是请求资源的一部分,服务器只对请求的部分资源执行get方法,相应报文中通过Context-Range指定范围的资源。
301:永久性重定向。
302:临时重定向。
303:与302状态码有相似功能,只是它希望客户端在请求一个URI的时候,能通过get方法重定向到另一个URI上。
304:发送附带条件的请求时,条件不满足时返回,与重定向无关。
307:临时重定向,与302相似,只是强制要求使用post方法。
400 Bad Request:客户端请求有语法错误,不能被服务器理解。
403:请求的资源被禁止访问。
404 Not Found:请求资源不存在。
500 Internal Server Error:服务器发生了不可预期的错误。
503 Server Unavailable:服务器当前不可用,一段时间后可能恢复正常。
其他常见状态码参见: https://help.aliyun.com/knowledge_detail/36393.html?spm=5176.13910061.0.0.ec456a13R6ymNK
301:永久性重定向。该状态码表示请求的资源已被分配了新的URI,以后应使用资源现在所指的URI。也就是说,如果已经把资源对应的URI保存为书签了,这时应该按Location首部字段提示的URI重新保存。老地址无法再访问。
302:临时性重定向。该状态码表示请求的资源已被分配了新的URI,希望用户(本次)能使用新的URI访问,但老的地址仍然可以访问。
重定向原因:1、网站调整(如改变网页目录结构);2、网页被移到一个新地址;3、网页扩展名改变(如应用需要把.php改成.Html或.shtml)。
这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问客户得到一个404页面错误信息,访问流量白白丧失;再者某些注册了多个域名的网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点等。
什么时候进行301或者302跳转?
当一个网站或者网页24~48小时内临时移动到一个新的位置,这时候就要进行302跳转,而使用301跳转的场景就是之前的网站因为某种原因需要移除掉,然后要到新的地址访问,是永久性的。
使用301跳转的大概场景如下:1、域名到期不想续费(或者发现了更适合网站的域名),想换个域名。2、在搜索引擎的搜索结果中出现了不带www的域名,而带www的域名却没有收录,这个时候可以用301重定向来告诉搜索引擎我们目标的域名是哪一个。3、空间服务器不稳定,换空间的时候。
六、http请求方法
1.GET:获取资源
GET方法用来请求访问已被URI识别的资源。也就是指定了服务器处理请求之后响应的内容。
2.POST:传输实体主体
POST方法用来传输实体主体。一般采用表单传输数据。
3.PUT:传输文件
PUT方法用来传输文件。类似FTP协议,文件内容包含在请求报文的实体中,然后请求保存到URL指定的服务器位置。
4.HEAD:获得报文首部
HEAD方法类似GET方法,但是不同的是HEAD方法不要求返回数据。用于确认URI的有效性及资源更新时间等。
5.DELETE:删除文件
DELETE方法用来删除文件,是与PUT相反的方法。DELETE是要求返回URL指定的资源。
6.OPTIONS:询问支持的方法
因为并不是所有的服务器都支持规定的方法,为了安全有些服务器可能会禁止掉一些方法例如DELETE、PUT等。那么OPTIONS就是用来询问服务器支持的方法。
7.TRACE:追踪路径
TRACE方法是让Web服务器将之前的请求通信环回给客户端的方法。这个方法并不常用。
8.CONNECT:要求用隧道协议连接代理
CONNECT方法要求在与代理服务器通信时建立隧道,实现用隧道协议进行TCP通信。主要使用SSL/TLS协议对通信内容加密后传输。
汇总:

七、http工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
1、客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。
2、发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3、服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4、释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5、客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
总的来说就是浏览器先向服务器发送请求,服务器接收到请求后,做相应的处理,然后封装好响应报文,再回送给浏览器。浏览器拿到响应报文后,再通过浏览器引擎去渲染网页,解析DOM树,javascript引擎解析并执行脚本操作,最后以网页的形式展现在用户面前。
八、get和post的区别
1、get请求重点在从服务器上获取资源,而post请求重点在向服务器发送数据。
2、get传输数据是通过URL请求,以字段=value的形式,用?连接置于URL之后,多个请求数据之间用&连接,这个过程用户可见,因此是不安全的。post传输数据是通过http的post机制,将字段与对应值封存在请求实体中发送给服务器,这个过程用户不可见,因此是安全的。
3、get提交的数据大小有限制(因为浏览器对URL的长度有限制),但是效率高;而post方法提交的数据没有限制,可以传输大量数据,所以传输文件时只能使用post,但是效率较低。请求较多时可能形成一个请求队列。
4、get方式需要使用Request.QueryString来取得变量的值,而post方式通过Request.Form来获取变量的值。
5、get方式只支持ASCII字符,因此向服务器传输中文有可能出现乱码;而post支持标准字符集,可以正确传递中文字符。
九、总结
http协议就是c/s和b/s模式下,客户端或者浏览器跟服务器进行数据传输的一种协议,由客户端向服务器端发起一个请求,服务器端接收请求并且进行处理,然后以一个响应报文的形式返回给客户端,客户端解析响应报文中的响应主体,最后在展现在页面上。
十、参考博文
(1) https://www.cnblogs.com/haiyan123/p/7777924.html
(2) https://www.cnblogs.com/qdhxhz/p/8468913.html
(3) http://www.ruanyifeng.com/blog/2016/08/http.html
(4) https://www.cnblogs.com/wxisme/p/6212797.html
(5) https://www.cnblogs.com/ranyonsue/p/5984001.html
(6) https://blog.csdn.net/weixin_41910244/java/article/details/80011849
(7) https://blog.csdn.net/zhouchangshun_666/article/details/79354193 (重定向问题)
(8) https://www.seozac.com/seo/url-canonicalization/ (网址规范化问题)
(9) https://blog.csdn.net/Crazypokerk_/article/details/89416546 (重定向问题)

