

oracle 分区表
1、分区表的概述
- 分区表就是通过使用分区技术,将一张大表,拆分成多个表分区(独立的segment),从而提升数据访问的性能,以及日常的可维护性。
- 分区表中,每个分区的逻辑结构必须相同。如:列名、数据类型。
- 分区表中,每个分区的物理存储参数可以不同。如:各个分区所在的表空间。
- 对于应用而言完全透明,分区前后没有变化,不需要进行修改。
需要注意:虽然各个分区可以存放在不同的表空间中,但这些表空间所使用的块大小(block_size)必须一致。
需要注意:除了包含LONG以及LONG RAW字段的表无法使用分区外,其他表均可以使用分区,包括含有LOB字段的表。
2、分区表的优点
- 在维护性方面,可以在分区级别,针对单独的分区,进行索引的维护、数据的加载以及备份恢复等操作。大大降低了维护时长。
- 在可用性方面,由于各个分区相对独立,当一个分区处于维护或者出现故障时,不会影响到其他分区的正常使用。
- 在性能方面,oracle对于用户的请求,只检索需要的分区,从而提升性能。
- 在其他方面,由于分区表对于用户是透明的,因此,不需要在分区后,对代码进行修改。
3、分区键的简介
- 分区键就是决定表中的数据行,属于哪一个分区的一组数据列。在执行DML操作时,ORACLE会根据分区键选择分区。
4.1、常用分区表简介及使用方法(含注意事项)
范围分区(range partition)
范围分区特点:
范围分区主要依据分区键定义时给出的键值范围,根据实际的取值,进行分区的选择,进而在相应分区中存储数据。
范围分区比较合适存在以数字为导向,方便进行数字范围划分的数据列。如:员工表的雇佣日期列、工资列等。
范围分区的数据分布可能不均匀。
范围分区定义规则:
1、在定义范围分区时,每个分区定义必须使用 values less than(value)子句。其中(value)表示该分区的上限值。
2、在定义范围分区时,最后一个分区可以是values less than(maxvalue)。其中(maxvalue)表示该分区存储高于其他分区上限值的数据行。
3、每一个分区都必须有一个VALUES LESS THEN子句,它指定了一个不包括在该分区中的上限值。分区键的任何值等于或者大于这个上限值的记录都会被加入到下一个高一些的分区中。
4、所有分区,除了第一个,都会有一个隐式的下限值,这个值就是此分区的前一个分区的上限值。
下面采用范围分区的方法创建分区,并将emp表的数据导入该分区表。
这里,使用HIREDATE列作为分区键进行分区操作。
建议,使用dbms_metadata.get_ddl的方法进行emp表结构创建语法的提取工作,并进而修改。

create table EMP_RANGE ( empno NUMBER(4) not null, ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2) not null, comm NUMBER(7,2), deptno NUMBER(2) ) partition by range (HIREDATE) ( partition P_HIREDATE_1 values less than (TO_DATE(' 1981-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')) tablespace TBS_CLPC_META pctfree 10 initrans 1 maxtrans 255, partition P_HIREDATE_2 values less than (TO_DATE(' 1982-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')) tablespace TBS_CLPC_META pctfree 10 initrans 1 maxtrans 255, partition P_HIREDATE_3 values less than (MAXVALUE) tablespace TBS_CLPC_META pctfree 10 initrans 1 maxtrans 255 );
insert into emp_range select * from emp;
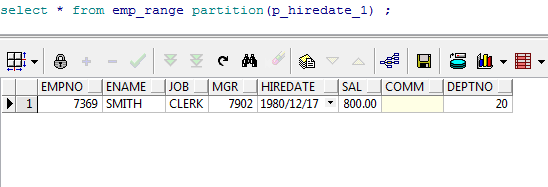
select * from emp_range partition(p_hiredate_1) ;
--查询分区数据
4.2、列表分区(list partition)
列表分区特点:
列表分区主要依据分区键定义时给出的取值列表,根据实际的取值,进行分区的选择,进而在相应分区中存储数据。
列表分区比较合适列唯一取值有限,且较为固定的数据列。如:员工表的部门列。
列表分区的数据分布可能不均匀。
列表分区定义规则:
1、在定义范围分区时,每个分区定义必须使用 values('value01','value02'....)子句。表示该分区存储包含相关value值的数据行。
2、在定义范围分区时,最后一个分区可以是values(DEFAULT)。表示该分区存储未在其他分区定义的数据行。
示例:
本示例数据来源,与上一节相同,均为emp表。
本示例中,将使用JOB列作为分区键进行分区操作。
首先,看一下JOB列中,目前涉及的工作分类有哪些。
Yumiko@sunny >select job,count(*) job from emp group by job ; JOB JOB --------- ---------- CLERK 4 SALESMAN 4 PRESIDENT 1 MANAGER 3 ANALYST 2
从上面的信息可以看出,目前涉及五种职位。
下面采用列表分区的方法进行分区表的创建,并倒入emp中的数据。其中,
涉及PRESIDENT,MANAGER以及ANALYST三种职位的数据,存放在分区一;
涉及CLERK职位的数据,存放在分区二;
涉及SALESMAN职位的数据,以及未来可能出现的新职位的数据,存放在分区三;
create table EMP_LIST ( empno NUMBER(4) not null, ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2) not null, comm NUMBER(7,2), deptno NUMBER(2) ) partition by list(job) ( partition p_job1 values('PRESIDENT','MANAGER','ANALYST'), partition p_job2 values('CLERK'), partition p_job3 values(default) );
insert into emp_list select * from emp;
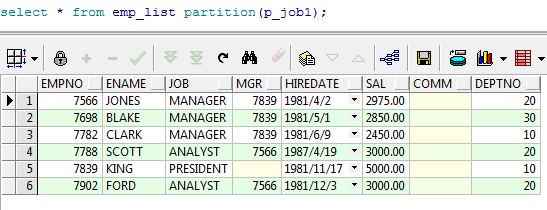
select * from emp_list partition(p_job1);
--查询分区数据
4.3、HASH分区(hash partition)
HASH分区特点:
HASH分区主要通过hash算法确定相应数据行应该被存放到哪个分区中。
HASH分区比较适合列差异值很多的数据列。
HASH分区的注意事项:
对于HASH分区,无法控制一条数据在分区间的具体分布。具体分布由hash算法决定。
对于HASH分区,如果更改分区的数量,将导致所有数据在分区间的重新分布。
HASH分区定义规则:
hash分区最主要的机制是根据hash算法来计算具体某条纪录应该插入到哪个分区中,hash算法中最重要的是hash函数,
Oracle中如果你要使用hash分区,只需指定分区的数量即可。建议分区的数量采用2的n次方,这样可以使得各个分区间数据分布更加均匀。
在定义HASH分区时,其分区数量应为2的N次方,如:2,4,8,16等
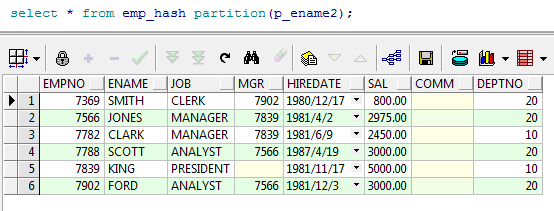
create table EMP_HASH ( empno NUMBER(4) not null, ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2) not null, comm NUMBER(7,2), deptno NUMBER(2) ) partition by hash(ENAME) ( partition p_ename1 tablespace tbs_clpc_meta, partition p_ename2 tablespace tbs_clpc_meta ); insert into emp_hash select * from emp; select * from emp_hash partition(p_ename2);
--查询分区数据
5.组合分区
组合分区的特点:
组合分区中,主要通过在不同列上,使用“范围分区”、“列表分区”以及“HASH分区”不同组合方式,进而实现组合分区。
组合分区中,分区本身没有相应的segment,可以认为是一个逻辑容器,只有子分区拥有实际的segment,用于存放数据。
组合分区的注意事项:
在11g以前,组合分区主要有两种组合方式:“RANGE-HASH”以及“RANGE-LIST”。
在11g以后,组合分区新增了四种组合方式:“RANGE-RANGE”、“LIST-RANGE”、“LIST-HASH”以及“LIST-LIST”。
create table emp_composite ( empno NUMBER(4) not null, ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2) not null, comm NUMBER(7,2), deptno NUMBER(2) ) partition by list(deptno) subpartition by range(hiredate) ( partition p_deptno_10 values(10) ( subpartition p_hiredate_1_10 values less than (to_date('1980-01-01','yyyy-mm-dd')), subpartition p_hiredate_2_10 values less than (maxvalue) ), partition p_deptno_20 values(20) ( subpartition p_hiredate_1_20 values less than (to_date('1981-01-01','yyyy-mm-dd')), subpartition p_hiredate_2_20 values less than (maxvalue) ) );
5.1.SET SUBPARTITION_TEMPLATE
在创建组合分区的时候,若指定template 模板,则子分区会根据这个模板来自定添加,后期不需要维护子分区,除非需要变更子分区
5.1.1 template 组合分区
--1.创建分区表
-- Create table create table STRIPE_REGIONAL_SALES ( deptno NUMBER, item_no VARCHAR2(20), txn_amount NUMBER, state VARCHAR2(2) ) partition by range (TXN_AMOUNT) subpartition by list (STATE) ( partition Q1_2010 values less than (100) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q1_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q1_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q2_2010 values less than (200) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q2_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q2_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q3_2010 values less than (300) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q3_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q3_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q4_2010 values less than (400) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q4_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q4_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ) );
--2.添加分区,子分区为创建的模板子分区,分区创建,子分区自动添加
alter table STRIPE_REGIONAL_SALES add partition Q5_8888 values less than (600);
--3.查看已经添加的分区,Q5_8888 子分区自动添加
-- Create table create table STRIPE_REGIONAL_SALES ( deptno NUMBER, item_no VARCHAR2(20), txn_amount NUMBER, state VARCHAR2(2) ) partition by range (TXN_AMOUNT) subpartition by list (STATE) ( partition Q1_2010 values less than (100) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q1_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q1_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q2_2010 values less than (200) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q2_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q2_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q3_2010 values less than (300) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q3_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q3_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q4_2010 values less than (400) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q4_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q4_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q5_8888 values less than (600) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q5_8888_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q5_8888_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ) );
--4.修改子分区模板,并添加分区
--修改子分区名及子分区值 ALTER TABLE STRIPE_REGIONAL_SALES SET SUBPARTITION TEMPLATE (SUBPARTITION WEST VALUES ('NY','TY'), SUBPARTITION EAST VALUES ('LA','NT')); --添加分区 alter table STRIPE_REGIONAL_SALES add partition Q6_9999 values less than (700);
查看已经创建的分区表
-- Create table create table STRIPE_REGIONAL_SALES ( deptno NUMBER, item_no VARCHAR2(20), txn_amount NUMBER, state VARCHAR2(2) ) partition by range (TXN_AMOUNT) subpartition by list (STATE) ( partition Q1_2010 values less than (100) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q1_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q1_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q2_2010 values less than (200) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q2_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q2_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q3_2010 values less than (300) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q3_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q3_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q4_2010 values less than (400) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q4_2010_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q4_2010_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q5_8888 values less than (600) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q5_8888_NORTH values ('OR', 'WA') tablespace TBS_INSIGHT_DEV, subpartition Q5_8888_SOUTH values ('AZ', 'UT', 'NM') tablespace TBS_INSIGHT_DEV ), partition Q6_9999 values less than (700) tablespace TBS_INSIGHT_DEV pctfree 10 initrans 1 maxtrans 255 ( subpartition Q6_9999_WEST values ('NY', 'TY') tablespace TBS_INSIGHT_DEV, subpartition Q6_9999_EAST values ('LA', 'NT') tablespace TBS_INSIGHT_DEV ) );
6.相关查询
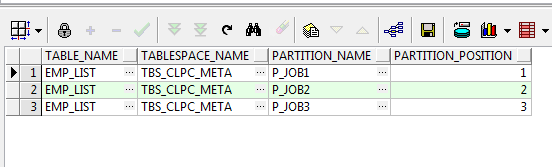
--查询表上有多少个分区
select t.table_name, t.tablespace_name, t.partition_name, t.partition_position from user_tab_partitions t where t.table_name = 'EMP_LIST';
--查询子分区
select t.table_name, t.tablespace_name, t.partition_name, t.subpartition_name, t.subpartition_position from user_tab_subpartitions t where t.table_name = 'EMP_COMPOSITE';
--显示当前用户所有分区表的详细分区信息: select * from user_tab_partitions; --显示当前用户所有分区表的信息: select * from user_part_tables; --显示当前用户所有分区表的分区列信息: select * from user_part_key_columns; --显示当前用户所有分区表的子分区列信息: select * from user_subpart_key_columns; --怎样查询出oracle数据库中所有的的分区表 select * from user_tables a where a.partitioned='YES'; --分区表相关索引信息 select * from user_part_indexes; select * from user_ind_partitions;
7.分区表维护操作
7.1.添加分区
以下代码给SALES表添加了一个P3分区
ALTER TABLE SALES ADD PARTITION P3 VALUES LESS THAN(TO_DATE('2003-06-01','YYYY-MM-DD'));
-- range partitioned table ALTER TABLE range_example ADD PARTITION part04 VALUES LESS THAN (TO_DATE('2008-10-1 00:00:00','yyyy-mm-ddhh24:mi:ss')); --list partitioned table ALTER TABLE list_example ADD PARTITION part04 VALUES('TE'); --Adding Values for a List Partition ALTER TABLE list_example MODIFY PARTITION part04 ADD VALUES('MIS'); --Dropping Values from a List Partition ALTER TABLE list_example MODIFY PARTITION part04 DROP VALUES('MIS'); --hash partitioned table ALTER TABLE hash_example ADD PARTITION part03; --增加subpartition ALTER TABLE range_hash_example MODIFY PARTITION part_1 ADD SUBPARTITION part_1_sub_4; 注:hash partitioned table新增partition时,现有表的中所有data都有重新计算hash值,然后重新分配到分区中,所以被重新分配的分区的indexes需要rebuild 。
7.2.删除分区
ALTER TABLE SALES DROP PARTITION P3;
ALTER TABLE SALES DROP SUBPARTITION P4SUB1;
注意:如果删除的分区是表中唯一的分区,那么此分区将不能被删除,要想删除此分区,必须删除表。
7.3.截断分区
截断某个分区是指删除某个分区中的数据,并不会删除分区,也不会删除其它分区中的数据。当表中即使只有一个分区时,也可以截断该分区。通过以下代码截断分区:
ALTER TABLE SALES TRUNCATE PARTITION P2; ALTER TABLE SALES TRUNCATE SUBPARTITION P2SUB2;
7.4.合并分区
合并分区是将相邻的分区合并成一个分区,结果分区将采用较高分区的界限,值得注意的是,不能将分区合并到界限较低的分区。
ALTER TABLE SALES MERGE PARTITIONS P1,P2 INTO PARTITION P2 UPDATE INDEXES;
如果省略update indexes子句的话,必须重建受影响的分区的index;
ALTER TABLE range_example MODIFY PARTITION part02 REBUILD UNUSABLE LOCAL INDEXES;
7.5拆分分区
ALTER TABLE SALES SBLIT PARTITION P2 AT(TO_DATE('2003-02-01','YYYY-MM-DD')) INTO (PARTITION P21,PARTITION P22);
注意:如果是RANGE类型的,使用at,LIST类型的使用values。
7.6.接合分区
分区接合是针对散列分区或者*-散列子分区的,目的是减少分区数。当某个散列分区接合后,Oracle将其分区的数据分散到其它分区中。被接合的分区是由数据库选择的,接合完成后该分区会被删除,且如果没有使用UPDATE INDEX子句,本地索引和全局索引均将变成不可用,一般需要重建索引。
--散列分区表的散列分区接合 ALTER TABLE table_name COALESCE PARTITION; --散列分区表的散列子分区接合 ALTER TABLE table_name MODIFY PARTITION partition_name COALESCE SUBPARTITION;
7.7.重命名分区
ALTER TABLE table_name RENAME PARTITION old_name TO new_name;
ALTER TABLE table_name RENAME SUBPARTITION old_name TO new_name;
7.8.交换分区
ALTER TABLE table_name EXCHANGE PARTITION partition_name WITH TABLE nonpartition_name;
7.9.移动分区
alter table custaddr move partition P_OTHER tablespace system;
alter table custaddr move partition P_OTHER tablespace icd_service;
分区移动会自动维护局部分区索引,oracle不会自动维护全局索引,所以需要我们重新rebuild分区索引,具体需要rebuild哪些索引,
可以通过dba_part_indexes,dba_ind_partitions去判断。
Select index_name,status From user_indexes Where table_name='CUSTADDR';
7.10.分区表和索引
2)建立本地分区索引
create index local_index_range_example_id on range_example(id) local;
create index gidx_range_example_id on range_example(id) GLOBAL partition by range(id) ( part_01 values less than(1000), part_02 values less than(MAXVALUE) );
对于分区索引的删除,local index 不能指定分区名称,单独的删除分区索引。local index 对应的分区会伴随着data分区的删除而一起被删除。
global partition index 可以指定分区名称,删除某一分区。但是有一点要注意,如果该分区不为空,则会导致更高一级的索引分区被置为UNUSABLE 。
ALTER INDEX gidx_range_exampel_id drop partition part_01 ;
此句将导致part_02 状态为UNUSABLE
--移动分区 SELECT 'alter table ' || TABLE_NAME || ' move PARTITION ' || PARTITION_NAME || ' tablespace tbs_insight_sit;' FROM USER_TAB_PARTITIONS WHERE TABLESPACE_NAME <> 'TBS_INSIGHT_SIT'; ALTER TABLE T_ITF_KPI_INFO MOVE PARTITION P_L_CLIC TABLESPACE TBS_INSIGHT_SIT; ----移动子分区 SELECT 'alter table ' || TABLE_NAME || ' move subPARTITION ' || SUBPARTITION_NAME || ' tablespace tbs_insight_sit;' FROM USER_TAB_SUBPARTITIONS WHERE TABLESPACE_NAME <> 'TBS_INSIGHT_SIT'; --修改母分区属性 SELECT 'ALTER TABLE ' || TABLE_NAME || ' MODIFY DEFAULT ATTRIBUTES FOR PARTITION ' || PARTITION_NAME || ' TABLESPACE TBS_INSIGHT_SIT;' FROM USER_TAB_PARTITIONS WHERE TABLESPACE_NAME = 'TBS_INSIGHT_SIT';
8.分区常见错误示例:
8.1.ORA-14621: cannot add subpartition when DEFAULT subpartition exists
[oracle@ccc200 insight_data_pump]$ oerr ora 14621 14621, 00000, "cannot add subpartition when DEFAULT subpartition exists" // *Cause: An ADD SUBPARTITION operation cannot be executed when a // subpartition with DEFAULT values exists // *Action: Issue a SPLIT of the DEFAULT subpartition instead
解决方法:
ALTER TABLE t_tmp_kpi_info SPLIT SUBPARTITION SYS_SUBP4447 VALUES ('201801') INTO ( SUBPARTITION P_L_CPIC_L_201801 TABLESPACE TBS_INSIGHT_DEV, SUBPARTITION SYS_SUBP4447 TABLESPACE TBS_INSIGHT_DEV);
转:https://www.cnblogs.com/yumiko/p/6095036.html


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步