
DPM(Deformable Parts Model)
Reference:
Object detection with discriminatively trained partbased models. IEEE Trans. PAMI, 32(9):1627–1645, 2010.
"Support Vector Machines for Multiple-Instance Learning,"Proc. Advances in Neural Information Processing Systems,2003.
作者主页:http://www.cs.berkeley.edu/~rbg/latent/index.html
补充 and 修正:
DPM是一个非常成功的目标检测算法,连续获得VOC(Visual Object Class)07,08,09年的检测冠军。目前已成为众多分类器、分割、人体姿态和行为分类的重要部分。2010年Pedro Felzenszwalb被VOC授予"终身成就奖"。DPM可以看做是HOG(Histogrrams of Oriented Gradients)的扩展,大体思路与HOG一致。先计算梯度方向直方图,然后用SVM(Surpport Vector Machine )训练得到物体的梯度模型(Model)。有了这样的模板就可以直接用来分类了,简单理解就是模型和目标匹配。DPM只是在模型上做了很多改进工作。
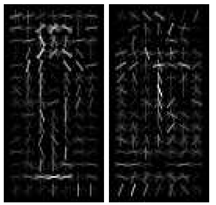
上图是HOG论文中训练出来的人形模型。它是单模型,对直立的正面和背面人检测效果很好,较以前取得了重大的突破。也是目前为止最好的的特征(最近被CVPR20 13年的一篇论文 《Histograms of Sparse Codes for Object Detection》 超过了)。但是, 如果是侧面呢?所以自然我们会想到用多模型来做。DPM就使用了2个模型,主页上最新版本Versio5的程序使用了12个模型。


上图就是自行车的模型,左图为侧面看,右图为从正前方看。好吧,我承认已经面目全非了,这只是粗糙版本。训练的时候只是给了一堆自行车的照片,没有标注是属于component 1,还是component 2.直接按照边界的长宽比,分为2半训练。这样肯定会有很多很多分错了的情况,训练出来的自然就失真了。不过没关系,论文里面只是把这两个Model当做初始值。重点就是作者用了多模型。

上图右边的两个模型各使用了6个子模型,白色矩形框出来的区域就是一个子模型。基本上见过自行车的人都知道这是自行车。之所以会比左边好辨识,是因为分错component类别的问题基本上解决了,还有就是图像分辨率是左边的两倍,这个就不细说,看论文。
有了多模型就能解决视角的问题了,还有个严重的问题,动物是动的,就算是没有生命的车也有很多款式,单单用一个Model,如果动物动一下,比如美女搔首弄姿,那模型和这个美女的匹配程度就低了很多。也就是说,我们的模型太死板了,不能适应物体的运动,特别是非刚性物体的运动。自然我们又能想到添加子模型,比如给手一个子模型,当手移动时,子模型能够检测到手的位置。把子模型和主模型的匹配程度综合起来,最简单的就是相加,那模型匹配程度不就提高了吗?思路很简单吧!还有个小细节,子模型肯定不能离主模型太远了,试想下假如手到身体的位置有两倍身高那么远,那这还是人吗?也许这是个检测是不是鬼的好主意。所以我们加入子模型与主模型的位置偏移作为Cost,也就是说综合得分要减去偏移Cost.本质上就是使用子模型和主模型的空间先验知识。

好了,终于来了一张合影。最右边就是我们的偏移Cost,圆圈中心自然就是子模型的理性位置,如果检测出来的子模型的位置恰好在此,那Cost就为0,在周边那就要减掉一定的值,偏离的越远减掉的值越大。
其实,Part Model 早在1973年就被提出参见《The representation and matching of pictorial structures》(木有看……)。
另外HOG特征可以参考鄙人博客:Opencv HOG行人检测 源码分析,SIFT特征与其很相似,本来也想写的但是,那时候懒,而且表述比较啰嗦,就参考一位跟我同一届的北大美女的系列博客吧。【OpenCV】SIFT原理与源码分析
总之,DPM的本质就是弹簧形变模型,参见 1973年的一篇论文 The representation and matching of pictorial structures
2.检测
检测过程比较简单:
综合得分:
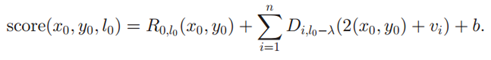
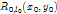 是rootfilter (我前面称之为主模型)的得分,或者说是匹配程度,本质就是
是rootfilter (我前面称之为主模型)的得分,或者说是匹配程度,本质就是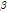 和
和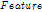 的卷积,后面的partfilter也是如此。中间是n个partfilter(前面称之为子模型)的得分。
的卷积,后面的partfilter也是如此。中间是n个partfilter(前面称之为子模型)的得分。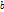 是为了component之间对齐而设的rootoffset.
是为了component之间对齐而设的rootoffset.
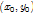 为rootfilter的left-top位置在root feature map中的坐标,
为rootfilter的left-top位置在root feature map中的坐标,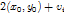 为第
为第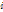 个partfilter映射到part feature map中的坐标。
个partfilter映射到part feature map中的坐标。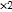 是因为part feature map的分辨率是root feature map的两倍,
是因为part feature map的分辨率是root feature map的两倍,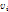 为相对于rootfilter left-top 的偏移。
为相对于rootfilter left-top 的偏移。
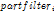 的得分如下:
的得分如下:
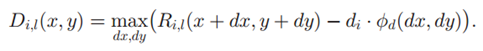
上式是在patfilter理想位置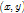 ,即anchor position的一定范围内,寻找一个综合匹配和形变最优的位置。
,即anchor position的一定范围内,寻找一个综合匹配和形变最优的位置。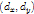 为偏移向量,
为偏移向量,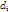 为偏移向量
为偏移向量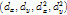 ,
,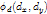
 为偏移的Cost权值。比如
为偏移的Cost权值。比如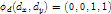 则
则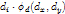
 即为最普遍的欧氏距离。这一步称为距离变换,即下图中的transformed response。这部分的主要程序有train.m、featpyramid.m、dt.cc.
即为最普遍的欧氏距离。这一步称为距离变换,即下图中的transformed response。这部分的主要程序有train.m、featpyramid.m、dt.cc.
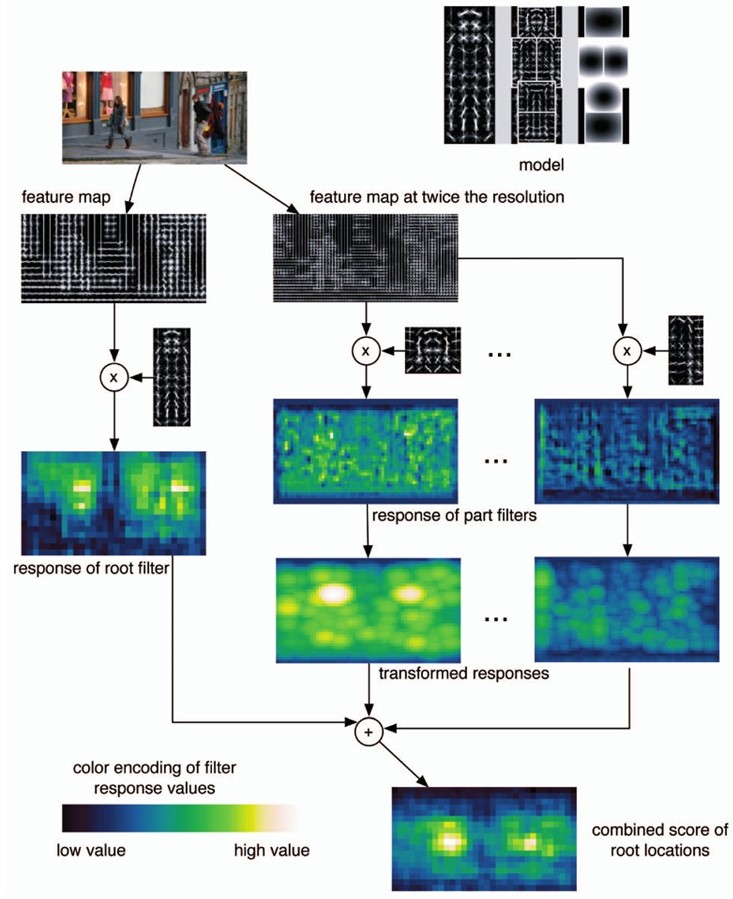
3.训练
3.1多示例学习(Multiple-instance learning)
3.1.1 MI-SVM
一般机器学习算法,每一个训练样本都需要类别标号(对于二分类:1/-1)。实际上那样的数据其实已经经过了抽象,实际的数据要获得这样的标号还是很难,图像就是个典型。还有就是数据标记的工作量太大,我们想偷懒了,所以多只是给了正负样本集。负样本集里面的样本都是负的,但是正样本里面的样本不一定都是正的,但是至少有一个样本是正的。比如检测人的问题,一张天空的照片就可以是一个负样本集;一张某某自拍照就是一个正样本集(你可以在N个区域取N个样本,但是只有部分是有人的正样本)。这样正样本的类别就很不明确,传统的方法就没法训练。
疑问来了,图像的不是有标注吗?有标注就应该有类别标号啊?这是因为图片是人标的,数据量特大,难免会有些标的不够好,这就是所谓的弱监督集(weakly supervised set)。所以如果算法能够自动找出最优的位置,那分类器不就更精确吗? 标注位置不是很准确,这个例子不是很明显,还记得前面讲过的子模型的位置吗?比如自行车的车轮的位置,是完全没有位置标注的,只知道在bounding box区域附件有一个车轮。不知道精确位置,就没法提取样本。这种情况下,车轮会有很多个可能的位置,也就会形成一个正样本集,但里面只有部分是包含轮子的。
针对上述问题《Support Vector Machines for Multiple-Instance Learning》提出了MI-SVM。本质思想是将标准SVM的最大化样本间距扩展为最大化样本集间距。具体来说是选取正样本集中最像正样本的样本用作训练,正样本集内其它的样本就等候发落。同样取负样本中离分界面最近的负样本作为负样本。因为我们的目的是要保证正样本中有正,负样本不能为正。就基本上化为了标准SVM。取最大正样本(离分界面最远),最小负样本(离分界面最近):
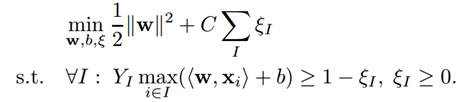
对于正样本: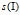 为正样本集中选中的最像大正样本的样本。
为正样本集中选中的最像大正样本的样本。
对于负样本:可以将max展开,因为最小的负样本满足的话,其余负样本就都能满足,所以任意负样本有:

目标函数:
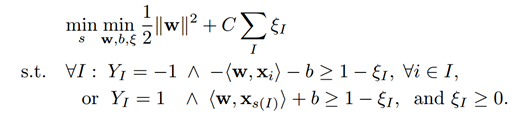
也就是说选取正样本集中最大的正样本,负样本集中的所有样本。与标准SVM的唯一不同之处在于拉格朗日系数的界限。
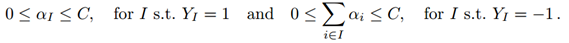
而标准SVM的约束是:
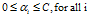
最终化为一个迭代优化问题:

思想很简单:第一步是在正样本集中优化;第二步是优化SVM模型。与K-Means这类聚类算法一样都只是简单的两步,却爆发了无穷的力量。
这里可以参考一篇博客Multiple-instance learning。
关于SVM的详细理论推导就不得不推荐我最为膜拜的MIT Doctor pluskid: 支持向量机系列
关于SVM的求解:SVM学习——Sequential Minimal Optimization
SVM学习——Coordinate Desent Method
此外,与多示例学习对应的还有多标记学习(multi-lable learning)有兴趣可以了解下。二者联系很大,多示例是输入样本的标记具有歧义(可正可负),而多标记是输出样本有歧义。
3.1.2 Latent SVM
1)我觉得MI-SVM可以看成 Latent-SVM的一种特殊情况。首先解释下Latent变量,MI-SVM决定正样本集中哪一个样本作为正样本的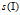 就是一个latent变量。不过这个变量是单一的,比较简单,取值只是正样本集中的序号而已。而LSVM 的latent变量就特别多,比如bounding box的实际位置x,y,在HOG特征金字塔中的某level中,样本component ID。也就是说我们有了一张正样本的图片,标注了bounding box,我们要在某一位置,某一尺度,提取出一个区域作为某一component 的正样本。
就是一个latent变量。不过这个变量是单一的,比较简单,取值只是正样本集中的序号而已。而LSVM 的latent变量就特别多,比如bounding box的实际位置x,y,在HOG特征金字塔中的某level中,样本component ID。也就是说我们有了一张正样本的图片,标注了bounding box,我们要在某一位置,某一尺度,提取出一个区域作为某一component 的正样本。
直接看Latent-SVM的训练过程:

这一部分还牵扯到了Data-minig。先不管,先只看循环中的3-6,12.
3-6就对于MI-SVM的第一步。12就对应了MI-SVM的第二步。作者这里直接用了梯度下降法,求解最优模型β。
2)现在说下Data-minig。作者为什么不直接优化,还搞个Data-minig干嘛呢?因为,负样本数目巨大,Version3中用到的总样本数为2^28,其中Pos样本数目占的比例特别低,负样本太多,直接导致优化过程很慢,因为很多负样本远离分界面对于优化几乎没有帮助。Data-minig的作用就是去掉那些对优化作用很小的Easy-examples保留靠近分界面的Hard-examples。分别对应13和10。这样做的的理论支撑证明如下:

3)再简单说下随机梯度下降法(Stochastic Gradient Decent):
首先梯度表达式:

梯度近似:
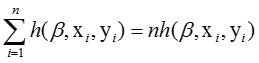
优化流程:

这部分的主要程序:pascal_train.m->train.m->detect.m->learn.cc
3.2 训练初始化
LSVM对初始值很敏感,因此初始化也是个重头戏。分为三个阶段。英语方面我就不班门弄斧了,直接上截图。





下面稍稍提下各阶段的工作,主要是论文中没有的Latent 变量分析:
Phase1:是传统的SVM训练过程,与HOG算法一致。作者是随机将正样本按照aspect ration(长宽比)排序,然后很粗糙的均分为两半训练两个component的rootfilte。这两个rootfilter的size也就直接由分到的pos examples决定了。后续取正样本时,直接将正样本缩放成rootfilter的大小。
Phase2:是LSVM训练。Latent variables 有图像中正样本的实际位置包括空间位置(x,y),尺度位置level,以及component的类别c,即属于component1 还是属于 component 2。要训练的参数为两个 rootfilter,offset(b)
Phase3:也是LSVM过程。
先提下子模型的添加。作者固定了每个component有6个partfilter,但实际上还会根据实际情况减少。为了减少参数,partfilter都是对称的。partfilter在rootfilter中的锚点(anchor location)在按最大energy选取partfilter的时候就已经固定下来了。
这阶段的Latent variables是最多的有:rootfilter(x,y,scale),partfilters(x,y,scale)。要训练的参数为 rootfilters, rootoffset, partfilters, defs(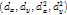 的偏移Cost)。
的偏移Cost)。
这部分的主要程序:pascal_train.m
4.1轮廓预测(Bounding Box Prediction)


仔细看下自行车的左轮,如果我们只用rootfilter检测出来的区域,即红色区域,那么前轮会被切掉一部分,但是如果能综合partfilter检测出来的bounding box就能得到更加准确的bounding box如右图。
这部分很简单就是用最小二乘(Least Squres)回归,程序中trainbox.m中直接左除搞定。
4.2 HOG
作者对HOG进行了很大的改动。作者没有用4*9=36维向量,而是对每个8x8的cell提取18+9+4=31维特征向量。作者还讨论了依据PCA(Principle Component Analysis)可视化的结果选9+4维特征,能达到HOG 4*9维特征的效果。
这里很多就不细说了。开题一个字都还没写,要赶着开题……主要是features.cc。有了下面这张图,自己慢慢研究下:
源码分析:
DPM(Defomable Parts Model) 源码分析-检测
DPM(Defomable Parts Model) 源码分析-训练
from: http://blog.csdn.NET/ttransposition/article/details/12966521

 浙公网安备 33010602011771号
浙公网安备 33010602011771号