prometheus告警 Alermanager组件
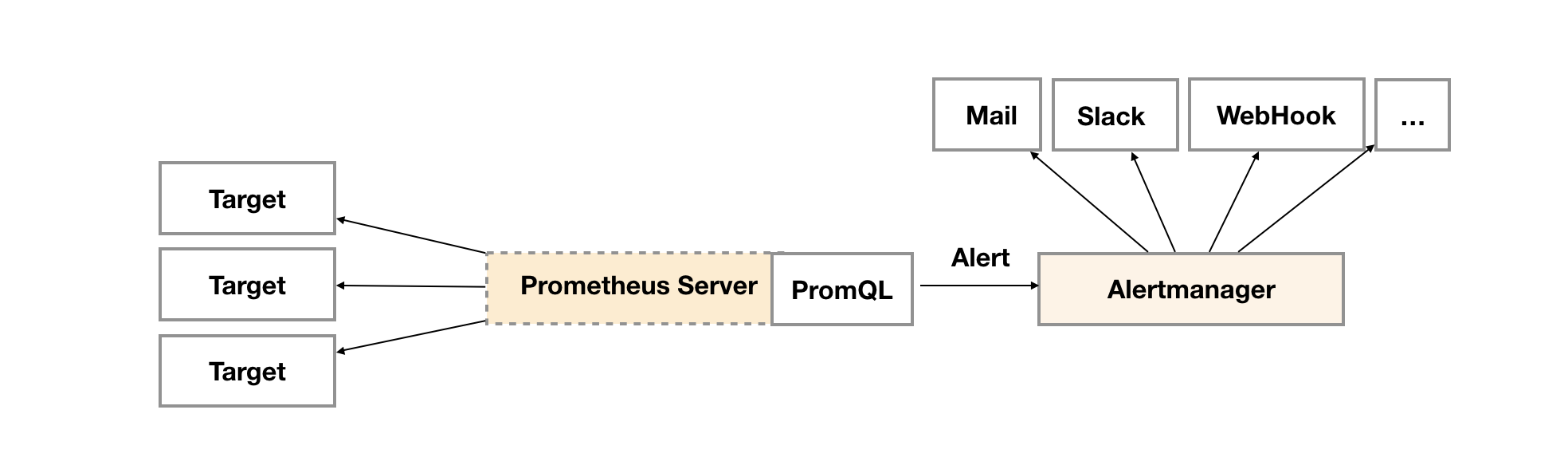
Alermanager特性
Alermanager除了提供基本的告警通知能力外,还提供了 分组,一直,静默等告警特性
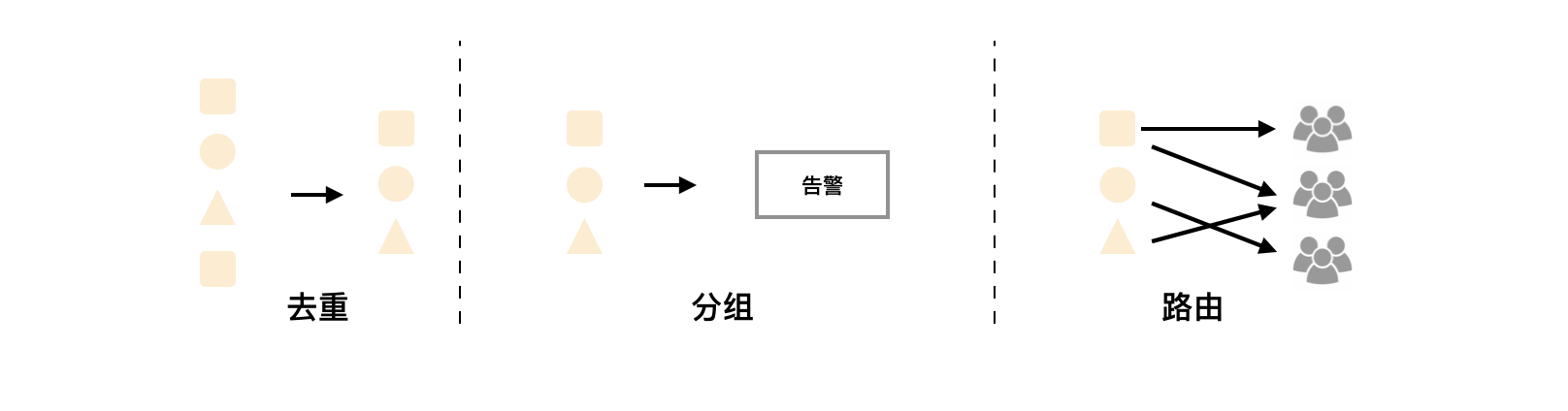
分组
分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。
例如,当集群中有数百个正在运行的服务实例,并且为每一个实例设置了告警规则。假如此时发生了网络故障,可能导致大量的服务实例无法连接到数据库,结果就会有数百个告警被发送到Alertmanager。
而作为用户,可能只希望能够在一个通知中中就能查看哪些服务实例收到影响。这时可以按照服务所在集群或者告警名称对告警进行分组,而将这些告警内聚在一起成为一个通知。
告警分组,告警时间,以及告警的接受方式可以通过Alertmanager的配置文件进行配置。
抑制
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
例如,当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与该集群有关的其它所有告警。这样可以避免接收到大量与实际问题无关的告警通知。
抑制机制同样通过Alertmanager的配置文件进行设置。
静默
静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。
静默设置需要在Alertmanager的Werb页面上进行设置。
自定义告警规则
定义告警规则
**groups:
- name: example
rules:
- alert: HighErrorRate
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
description: description info**
- alert:告警规则的名称。
- expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
实操,定义主机监控告警实例
修改Prometheus配置文件prometheus.yml,添加以下配置:
rule_files:
- /etc/prometheus/rules/*.rules
在目录/etc/prometheus/rules/下创建告警文件hoststats-alert.rules内容如下:
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
编辑完成后需要重启prometheus server进程
通过web查看
http://127.0.0.1:9090/rules 查看当前以加载的规则文件
http://127.0.0.1:9090/alerts 查看当前告警的活动状态
人为制造负载高 触发告警
cat /dev/zero>/dev/null
可以观察alerts页面,state的状态由 pending转变为 firting发射状态
部署altermanager
Alertmanager最新版本的下载地址可以从Prometheus官方网站https://prometheus.io/download/获取。
默认的配置文件
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
配置文件解读:
配置主要包含两部分: 路由(route)和接收器(receivers)。
所有的告警信息都会从配置中的顶级路由进入路由树,根据路由规则将告警信息发送给相应的接收器。
启动
./alertmanager
通过web查看
关联Prometheus与Alertmanager
配置文件prometheus.yml,并添加以下内容
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
重启Prometheus服务
通过 尝试手动拉高系统CPU使用率
cat /dev/zero>/dev/null
WEB查看
查看Alertmanager UI此时可以看到Alertmanager接收到的告警信息。
alertmanager 配置描述
- 全局配置(global):用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容;
- 模板(templates):用于定义告警通知时的模板,如HTML模板,邮件模板等;
- 告警路由(route):根据标签匹配,确定当前告警应该如何处理;
- 接收人(receivers):接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者Webhook等,接收人一般配合告警路由使用;
- 抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生
global:
[ resolve_timeout: <duration> | default = 5m ]
[ smtp_from: <tmpl_string> ]
[ smtp_smarthost: <string> ]
[ smtp_hello: <string> | default = "localhost" ]
[ smtp_auth_username: <string> ]
[ smtp_auth_password: <secret> ]
[ smtp_auth_identity: <string> ]
[ smtp_auth_secret: <secret> ]
[ smtp_require_tls: <bool> | default = true ]
[ slack_api_url: <secret> ]
[ victorops_api_key: <secret> ]
[ victorops_api_url: <string> | default = "https://alert.victorops.com/integrations/generic/20131114/alert/" ]
[ pagerduty_url: <string> | default = "https://events.pagerduty.com/v2/enqueue" ]
[ opsgenie_api_key: <secret> ]
[ opsgenie_api_url: <string> | default = "https://api.opsgenie.com/" ]
[ hipchat_api_url: <string> | default = "https://api.hipchat.com/" ]
[ hipchat_auth_token: <secret> ]
[ wechat_api_url: <string> | default = "https://qyapi.weixin.qq.com/cgi-bin/" ]
[ wechat_api_secret: <secret> ]
[ wechat_api_corp_id: <string> ]
[ http_config: <http_config> ]
templates:
[ - <filepath> ... ]
route: <route>
receivers:
- <receiver> ...
inhibit_rules:
[ - <inhibit_rule> ... ]
基于标签的告警路由
告警分组
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by: [cluster, alertname]
routes:
- receiver: 'database-pager'
group_wait: 10s
match_re:
service: mysql|cassandra
- receiver: 'frontend-pager'
group_by: [product, environment]
match:
team: frontend
内置高进过期接收器Receiver
name: <string>
email_configs:
[ - <email_config>, ... ]
hipchat_configs:
[ - <hipchat_config>, ... ]
pagerduty_configs:
[ - <pagerduty_config>, ... ]
pushover_configs:
[ - <pushover_config>, ... ]
slack_configs:
[ - <slack_config>, ... ]
opsgenie_configs:
[ - <opsgenie_config>, ... ]
webhook_configs:
[ - <webhook_config>, ... ]
victorops_configs:
[ - <victorops_config>, ... ]
目前官方内置的第三方通知集成包括:邮件、 即时通讯软件(如Slack、Hipchat)、移动应用消息推送(如Pushover)和自动化运维工具(例如:Pagerduty、Opsgenie、Victorops)。Alertmanager的通知方式中还可以支持Webhook,通过这种方式开发者可以实现更多个性化的扩展支持
具体细节参考 https://www.prometheus.wang/alert/alert-manager-use-receiver.html 定义的不同媒介
自定义告警模板
- 第一种,基于模板字符串。用户可以直接在Alertmanager的配置文件中使用模板字符串
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'
text: 'https://internal.myorg.net/wiki/alerts/{{ .GroupLabels.app }}/{{ .GroupLabels.alertname }}'
- 第二种方式,自定义可复用的模板文件。例如,可以创建自定义模板文件custom-template.tmpl,如下所示
cat /etc/alertmanager/templates/myorg.tmpl
{{ define "slack.myorg.text" }}https://internal.myorg.net/wiki/alerts/{{ .GroupLabels.app }}/{{ .GroupLabels.alertname }}{{ end}}
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'
text: '{{ template "slack.myorg.text" . }}'
templates:
- '/etc/alertmanager/templates/myorg.tmpl'
屏蔽告警通知
Alertmanager提供了方式可以帮助用户控制告警通知的行为,包括预先定义的抑制机制和临时定义的静默规则。
抑制机制
eg.
- source_match:
alertname: NodeDown
severity: critical
target_match:
severity: critical
equal:
- node
例如当集群中的某一个主机节点异常宕机导致告警NodeDown被触发,同时在告警规则中定义了告警级别severity=critical。由于主机异常宕机,该主机上部署的所有服务,中间件会不可用并触发报警。根据抑制规则的定义,如果有新的告警级别为severity=critical,并且告警中标签node的值与NodeDown告警的相同,则说明新的告警是由NodeDown导致的,则启动抑制机制停止向接收器发送通知。
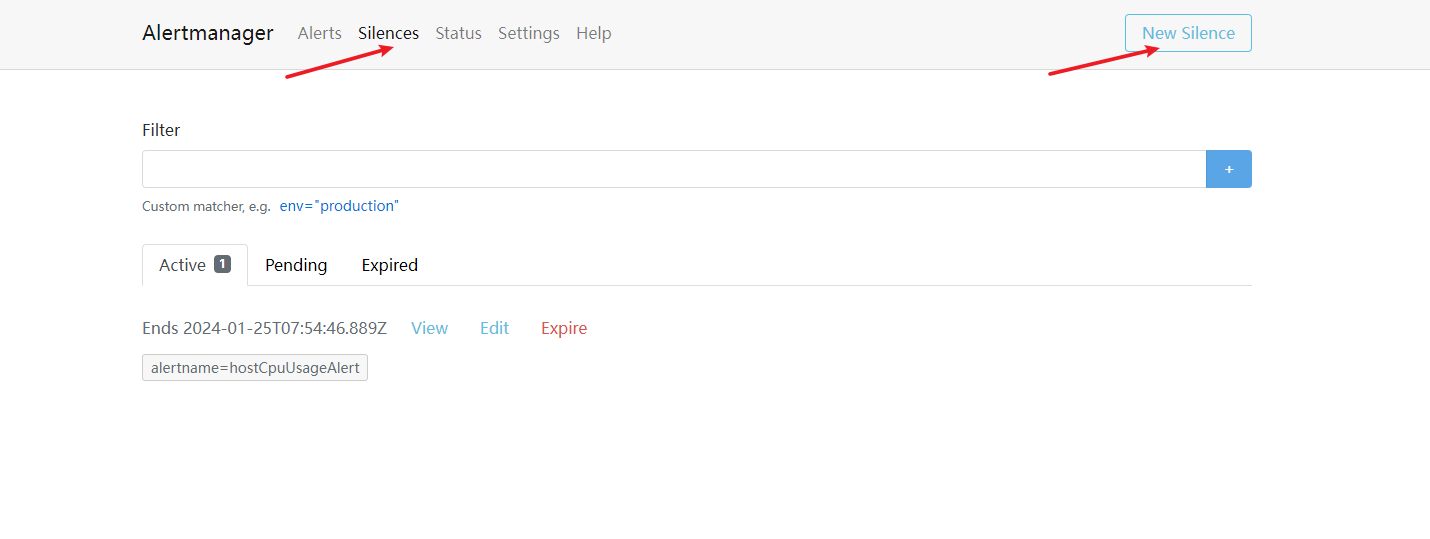
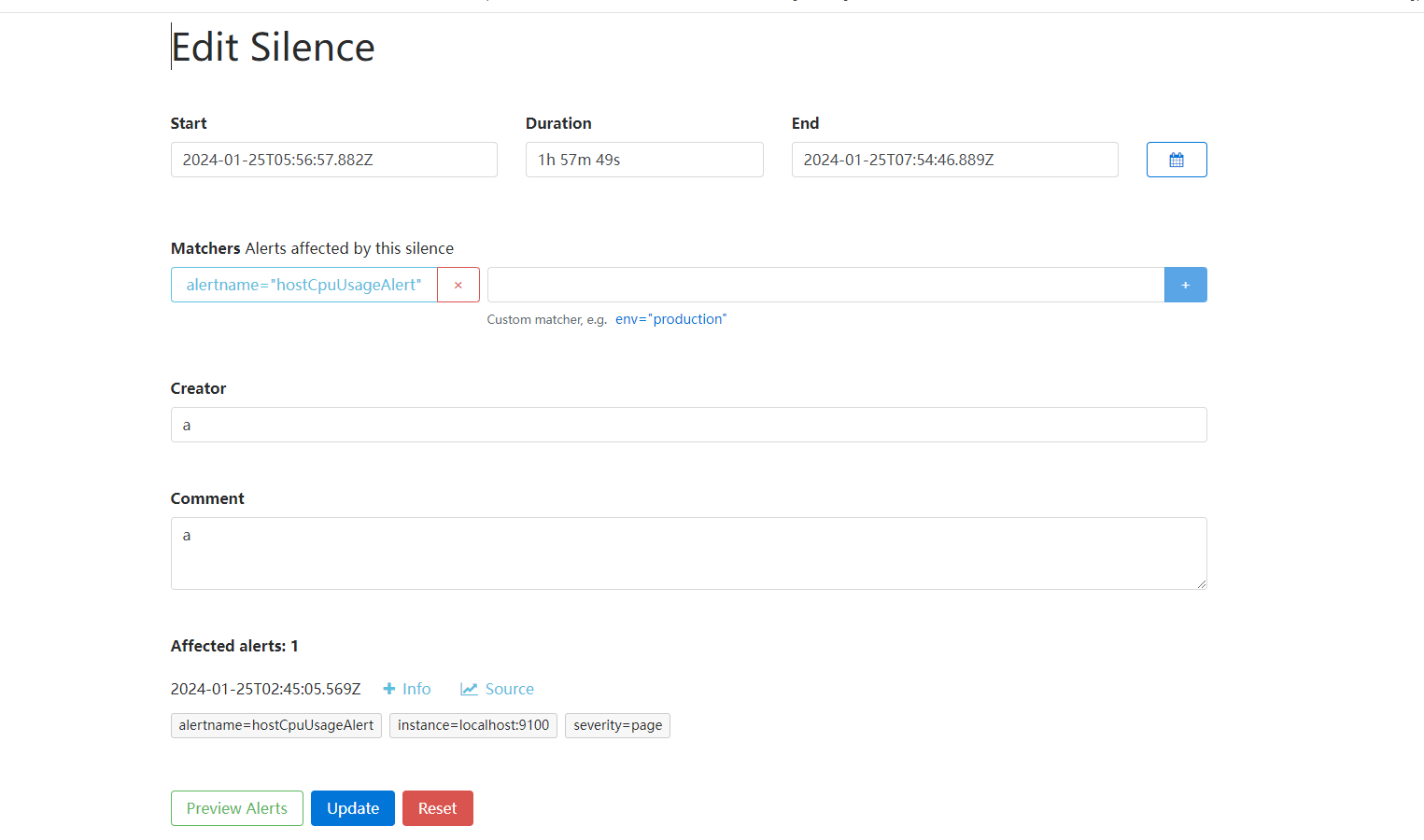
临时静默
web操作


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?