生成聊天记录词云 o(* ̄▽ ̄*)ブ收藏时光印记
前几天不小心把和npy的纪念日忘记了...(直女本质)虽然他并没有说啥,但是心里还是过意不去,于是打算做一个小小的补偿。
于是我就做了一个聊天记录的词云hiahiahia
过程非常的简单,这里总结一下,需要的朋友拿去用噢~
一、导出QQ聊天记录
网上有很多教程,大致分为两类:
(1)从手机导出文件
扔一个链接:https://jingyan.baidu.com/article/e9fb46e1db39cf3520f7660c.html
大致过程就是打开聊天框的聊天记录,点击右下角“导出“按钮,即可导出文件。可能由于我的QQ版本问题,没有那个导出按钮,所以没有采用此方法。
(2)从手机导入电脑,再从电脑导出
a.打开电脑QQ的设置

b.安全设置——消息记录——勾选“登录QQ时同步最近聊天记录”
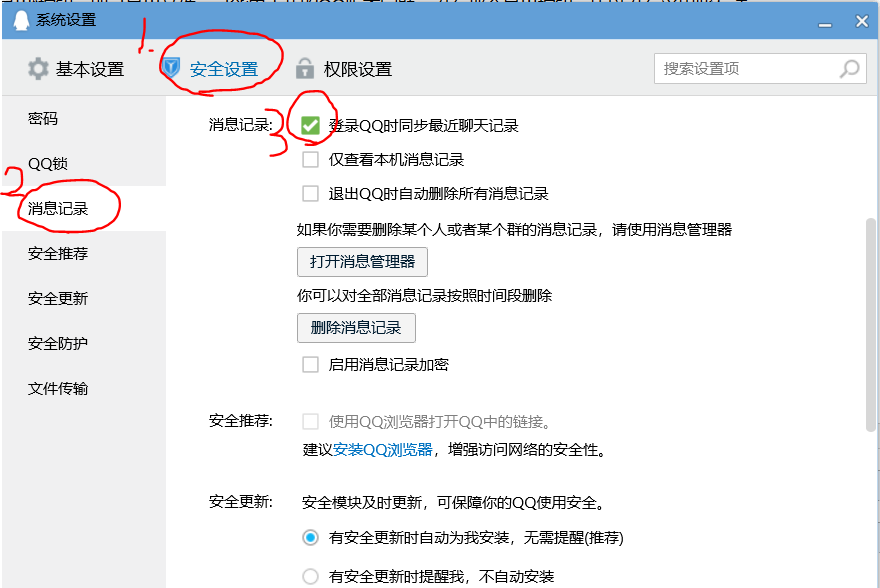
c.打开消息管理器
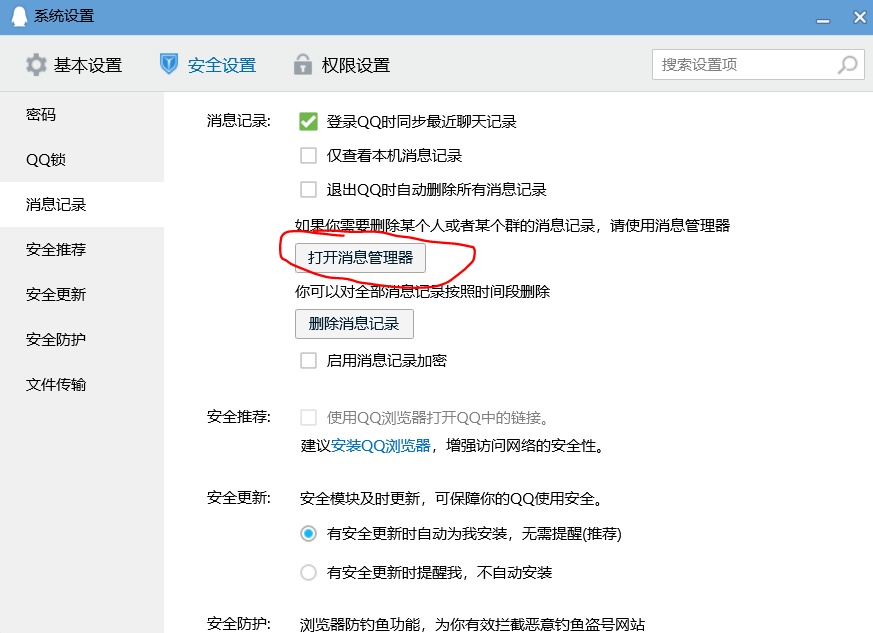
d.右键选择相应的联系人,点击“导出消息记录”,文件格式可以选择txt,这样可以用记事本打开。
二、聊天记录处理
导出的文本中有很多冗余内容需要去掉,比如时间,昵称,还有聊天内容中无意义的词,比如“可能”,“有点”,“今天”等等,可以写个程序处理一下。
这里是去掉无意义词汇的函数,类似的方法可以去掉时间,昵称等。很简单就不一一罗列了。
1 void RemoveIt(){ 2 string Words[18]={"我们","觉得","一个","自己","应该","今天","明天","还是","这个","可能","就是","没有","有点","你们","感觉","所以","什么","可以"}; 3 string temp; 4 while(getline(cin,temp)){ 5 for(auto i:Words){ 6 int pos=0; 7 while((pos=temp.find(i))!=-1){ 8 temp.erase(pos,4); 9 } 10 } 11 } 12 cout<<temp<<endl; 13 }
三、生成词云
主要参考了这篇博客https://blog.csdn.net/ydydyd00/article/details/80665028
需要提前安装wordcloud,PIL,numpy,jieba,具体方法不说明了,请参考我的另一篇博客:https://www.cnblogs.com/jasmine-/p/11569159.html
然后下载一个词云轮廓的图片

代码
1 from wordcloud import WordCloud 2 import PIL.Image as image 3 import numpy as np 4 import jieba 5 6 7 # 分词 8 def trans_CN(text): 9 # 接收分词的字符串 10 word_list = jieba.cut(text) 11 # 分词后在单独个体之间加上空格 12 result = " ".join(word_list) 13 return result 14 15 16 with open('WithZGpost.txt',encoding='ANSI') as fp: 17 text = fp.read() 18 # print(text) 19 # 将读取的中文文档进行分词 20 text = trans_CN(text) 21 mask = np.array(image.open("love.png")) 22 wordcloud = WordCloud( 23 # 添加遮罩层 24 mask=mask, 25 # 生成中文字的字体,必须要加,不然看不到中文 26 font_path="C:\Program Files\Microsoft Office//root//vfs\Fonts\private\FZSTK.TTF", 27 background_color="white",width=1000,height=880 28 ).generate(text) 29 image_produce = wordcloud.to_image() 30 image_produce.show()
文件路径请自行更改,选择字体的时候要去C盘里的font文件夹里找,文件后缀名.TTF。看自己电脑里有什么字体,也可以从网上下载一些喜欢的字体。推荐一个软件Everything,寻找文件非常方便快速。
贴一张根据余光中先生的《听听那冷雨》生成的词云

好啦,以上就是全部内容啦。最近每天呆在家,今天终于想起来把这篇写完了。希望疫情快快过去吧!

