cs231n学习笔记——Lecture 3 Loss Functions and Optimiz
该博客主要用于个人学习记录,部分内容参考自 李飞飞笔记、cs231n 第三章 损失函数和最优化、超详细斯坦福CS231n课程笔记(第三课)——损失函数和优化损失函数、【cs231n】lecture 3损失函数和优化、CS231n笔记二:损失函数和优化介绍、CS231n学习笔记——损失函数
一、损失函数 Loss function
-
在线性分类中,W的每一行对应一个分类模板,它给出图像所属类别的可能的得分,得分越高说明该图片中的物体属于这一类别的可能性越大,因此我们需要选择一个分类效果最优的W,W来自于数据集的训练。
损失函数就是用来度量某个W好坏的,输入为W,得到一个分数,定量估计W的好坏,这个函数即为损失函数。 -
给定样本数据集: \({(x_i,y_i)}_1^N\)
-
样本数据集上的损失函数公式: \(L=\frac{1}{N}\sum_iL_i(f(x_i,W),y_i)\)
在一个训练集中,通常有N个样本,每个样本包括若干个\(x_i\)和\(y_i\),其中\(x_i\)表示输入数据,在图像分类问题中,这些\(x_i\)是图像的实际像素值,\(y_i\)表示标签label或目标target,在图像分类中即为正确类别所对应的那个整数。损失函数记为Li,输入为\(f(x_i,W)\)和\(y_i\),以定量描述训练样本预测出的W的好坏。最终损失函数L是N个样本的\(L_i\)的平均值。最终目的是找到使损失函数L最小的参数矩阵W。
二、多分类SVM损失函数 Multiclass SVM loss
1、Hinge Loss
(1)SVM损失函数
给定一个样本\((x_i,y_i)\),SVM损失函数为
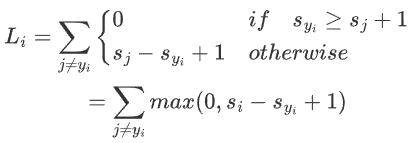
-
\(x_i\):输入的图像
-
\(y_i\):该样本正确分类的标签
-
\(s_i:分类器预测的分数,\)s=f(x_i,W)$
-
\(s_j\):所有对\(x_i\)来说错误分类的标签(即除了\(y_i\))的分数
-
\(s_{y_i}\):正确分类的分数
对于每一个错误分类的标签,比较其分数与正确分类的分数,若正确分类的分数比错误分类的分数≥1(也就是说,此时1是安全距离),则取0,否则,取\(s_j - s_{y_i} + 1\)
(2)图像
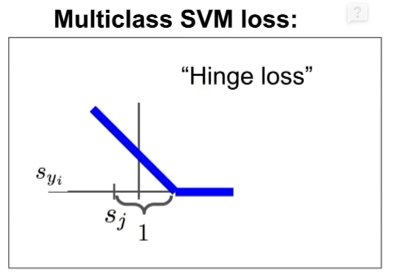
上图中x轴表示\(s_{y_i}\),y轴是损失值\(L_i\),随着\(s_{y_i}\)的增加,\(L_i\)先是线性减小,之后当\(s_{y_i}\)到达一个阈值分数后,损失函数变成了0,说明\(s_{y_i}\)已经和\(s_j\)拉开了足够的安全距离,此时分类是正确的。
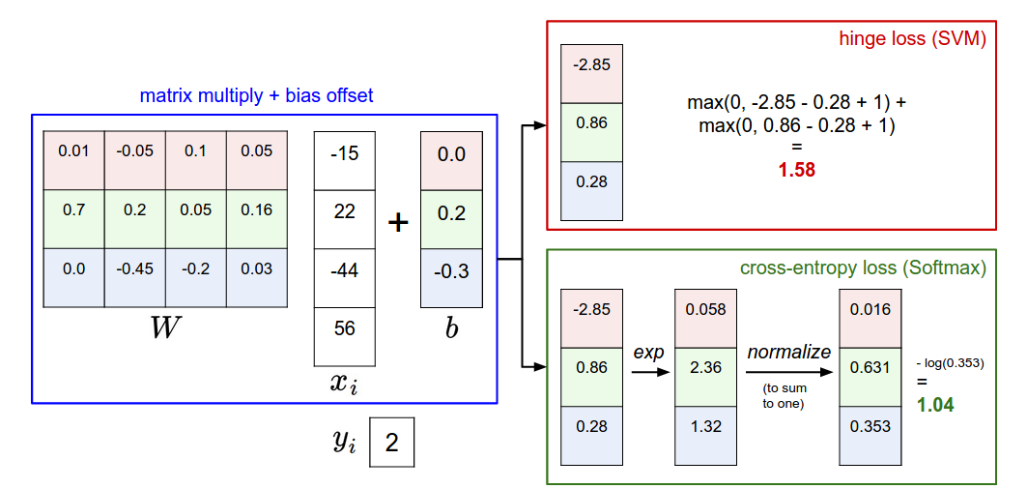
(3)一个计算例子

总的loss越大表明参数W的表现越差。
(4)使用numpy实现的多类别SVM损失函数的示例代码
\(L_i=\sum_{j\not=y_i}max(0,s_i-s_{y_i}+1)\)
def L_i_vectorized(x, y, W):
scores = W.dot(x)
margins = np.maximum(0, scores - scores[y] + 1)
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
(5)注意
- 如果对于每一项\(L_i\) ,我们使用的是求平均而不是求和,结果不会改变,只是损失函数缩小了一个倍数,对于结果没有什么影响;
- SVM损失函数可能的最小值是0,最大值是无穷大;
- 使得\(L_i=0\)的W是最优的,但不是唯一的,对这个W进行成倍数缩放(2W,3W......),这一项的损失函数值仍然为0;
- SVM损失函数希望正确类\(y_i\)的分数至少比不正确类的分数大Δ (delta)。如果不是这样,我们的损失就会越来越大。
- 如果我们改变损失函数的公式,在max上加一个平方,这将称为另外一个分类算法,从一个线性的变为一个更强烈的算法,有的时候平方max的方法可能会更好。
2、加入正则项 regularization loss : L= \(\frac{1}{N}\sum_iL_i(f(x_i,W),y_i)+\lambda R(W)\)
(1)正则项
-
如无必要,勿增实体”,这是著名的奥卡姆剃刀原则Occam's Razor。他的意思就是切勿浪费较多东西去做,用较少的东西,同样可以做好的事情。
-
我们在构造机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好的表现。当你用比较复杂的模型比如神经网络,去拟合数据时,很容易出现过拟合现象(训练集表现很好,测试集表现较差),这会导致模型的泛化能力下降,这时候,我们就需要使用正则化,降低模型的复杂度。添加正则项可以防止模型在训练集上表现的太好而导致其的模型泛化能力不强。
-
正则化,就是给损失函数加一个正则化项,相当于给它一个惩罚。标准的损失函数由两部分组成:数据损失项和惩罚项。超参数\(\lambda\)是用来平衡这两个项的。
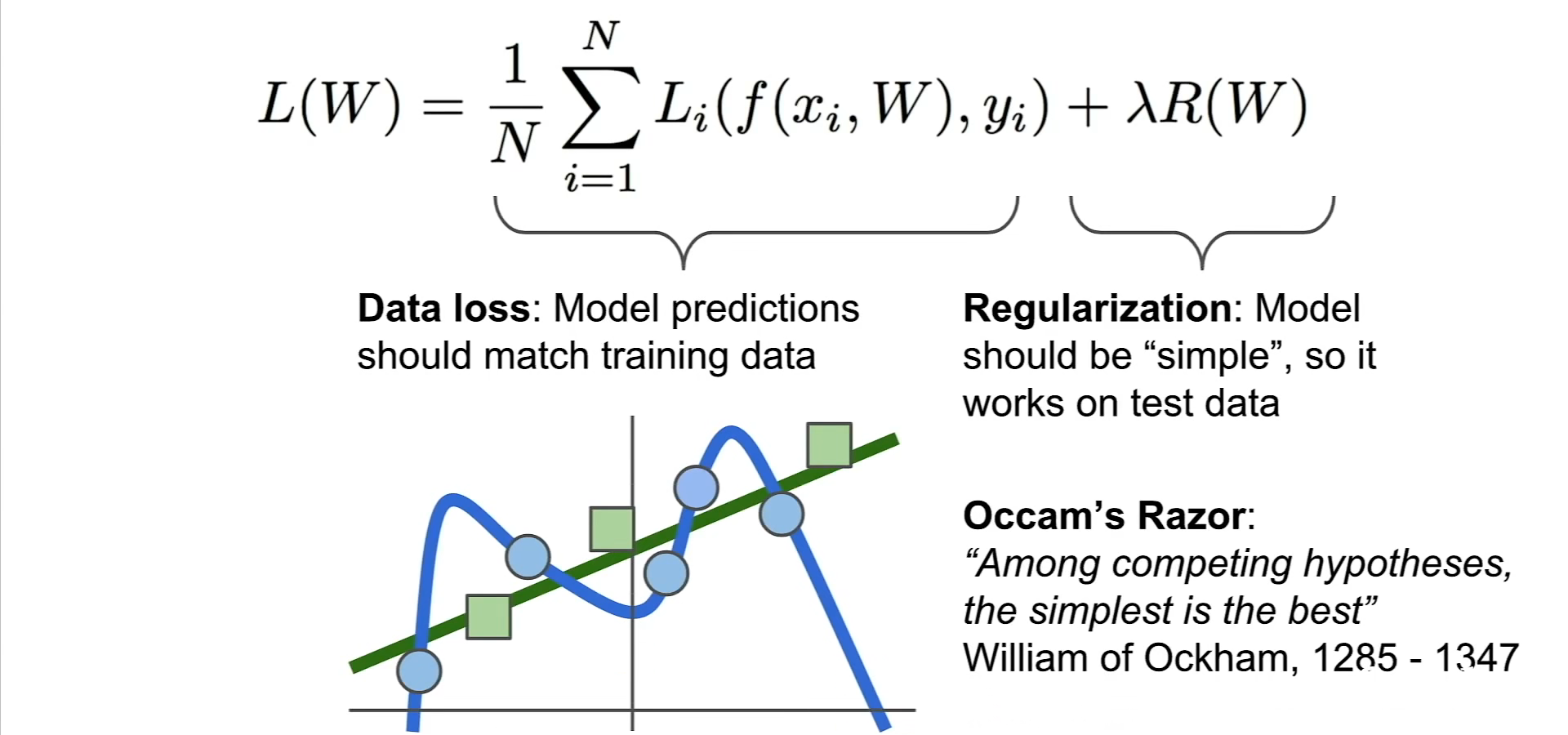
(2)几个常用的正则化
-
L2 正则化: \(R(W) = \sum_k\sum _l W^2_{k,l}\)
- L2正则化是模型各个参数的平方值。
- 使用L2可以得到平滑的权值
- 倾向于将影响力分散到X中所有不同的值上,可以防止模型过拟合
-
L1 正则化: \(R(W) = \sum_k\sum _l |W_{k,l}|\)
- L1正则化是模型各个参数的绝对值之和。
- 使用L1可以得到稀疏的权值
- 输出具有稀疏性,即产生一个稀疏模型
-
弹性网络(L1 + L2): \(R(W) = \sum_k\sum _l \beta W_{k,l}^2+ |W_{k,l}|\)
-
最大范数正则化max norm regularization
-
除了这些比较简单的正则化外,我们还有:Dropout、Batch normalization、Stochastic depth等等较为复杂的正则化方法。
三、Softmax 分类器 (多项式 Logistic 回归)
-
SVM损失函数,对于多类别分类,我们只给出了分数,没有解释这些得分的含义
Softmax函数,将这些分数指数化并归一化,整理成概率分布,这样对于所有类别我们都有了相应概率,每个概率都介于0和1之间,所有类别的概率和等于1。\(P(Y=k|X=x_i)=\frac{e^{s_k}}{\sum_je^{s_j}}\) where \(s=f(x_i;W)\)
公式P求出来的是输入\(x_i\)属于类别k的概率,s是类别的得分,我们希望真实类别所求得的概率比较高并接近于1,所以损失函数就是真实类别概率的对数再取负值。当概率为1时,损失为0,概率越接近0,损失越大。
\(L_i=-logP(Y=y_i|X=x_i)=-s_i+log\sum_je^s_j\)

-
一个例子

-
softmax损失函数的最小值是0,最大值是无穷。
如果所有的s都很小并接近于0,那么损失函数的值为-log(1/N),这个也可以作为一种纠错机制。 -
Softmax VS SVM
- 二者都属于线性分类问题,不同在于二者解释得分s的方式。
- 多分类SVM损失函数,例如对样本中的一个车的图像做预测,只要车的分类的分值比其他不正确分类的分值要高,即使车的分值稍微有所变化,也并不会对结果产生根本改变,因为对SVM损失函数来说,唯一关心的是正确的分值要比不正确分值高出一个安全边界。
- 但是,softmax的目标不同,它计算的是概率值,要使softmax loss尽可能小,正确分类的概率尽可能大,所以你给正确分类再高的分值,同时给不正确分类再低的分值,softmax依然会在正确的分类上,将正确的分值推向无穷大,将不正确的分值推向无穷小。
- SVM得到一个数据点高于阙值放弃继续优化了,而Softmax会追求完美.
四、梯度下降
1、定义
- 假设我们在山顶,现在要以最快的速度下山,我们可以每一次都沿着最陡峭的方向走一步,这样一直走到山底。在数学中,我们可以用梯度这个概念来表示最陡的方向,梯度指向函数增加最快的方向,负梯度就是函数减小最快的方向。
- 一维函数的求导公式: $\frac{df(x)}{dx}= lim_{h \to + 0}\frac{f(x+h)-f(x)}{h} $
多元函数下的导数概念就是梯度,梯度就是偏导数组成的向量,任何方向的斜率都是方向与梯度的点积。同时梯度下降法的方向是负梯度因为正的梯度是向上的,我们需要求loss的最小值所以是用的负梯度。
2、计算梯度
(1)数值梯度(有限差分法)
对于每一个维度在原始数值上加上一个很小的h,然后求出这个维度上的偏导,最后组合在一起得到梯度grad。这种方式计算比较繁琐,参数更新比较慢。


def eval_numerical_gradient(f, x):
"""
a naive implementation of numerical gradient of f at x
- f should be a function that takes a single argument
- x is the point (numpy array) to evaluate the gradient at
"""
fx = f(x) # evaluate function value at original point
grad = np.zeros(x.shape)
h = 0.00001
# iterate over all indexes in x
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
# evaluate function at x+h
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # increment by h
fxh = f(x) # evalute f(x + h)
x[ix] = old_value # restore to previous value (very important!)
# compute the partial derivative
grad[ix] = (fxh - fx) / h # the slope
it.iternext() # step to next dimension
return grad
(2)解析梯度
直接使用微积分的知识,写下梯度的表达式,这里梯度的表达式就是每个参数的偏导数,每次计算只需要带入公式即可。从W开始,计算dW或每一步的梯度。
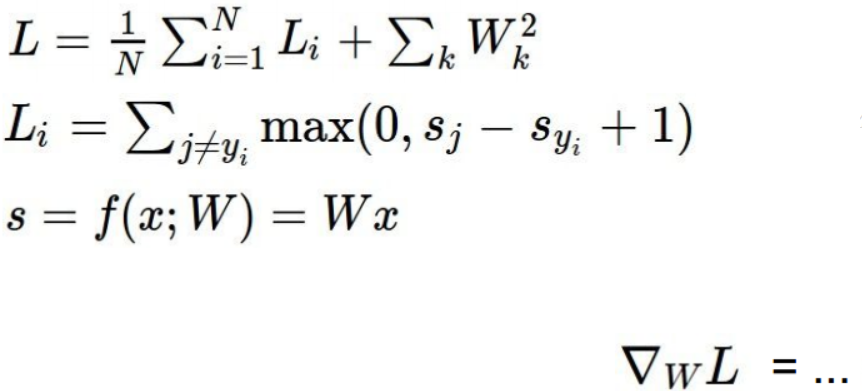

(3)总结
- 数值梯度:计算简单,但非常慢,但它是很好的调试工具
- 解析梯度:准确,快速,但容易出错
- 在实践中,通常使用解析梯度,但使用数值梯度检查,确保解析梯度正确
3、梯度下降Gradient descent
# Vanilla Gradient Descent
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # perform parameter update
-
在梯度下降算法中,首先我们初始化W为随机值,当为真时,我们计算损失和梯度,然后向着梯度相反的方向更新权重W值。每次更新的步长是一个超参数,又叫学习率,就相当于每次选择最陡峭的方向走一步,这一步走多长。
-
我们定义数据的损失值是所有训练集损失值的平均值,但实际上N会很大,那么计算该损失值的计算成本会很高,需要很长一段时间来跟新W。所以实际操作中我们往往使用随机梯度下降法,它并非计算整个训练集的误差和梯度值。而是在每次迭代时选取一小部分训练样本成为minibatch(小批量),利用minibatch来估算误差总和以及实际梯度。每次迭代minibatch都是随机选取的。

# Vanilla Minibatch Gradient Descent
while True:
data_batch = sample_training_data(data, 256) # sample 256 examples
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad # perform parameter update
五、图像特征Image Feature
1、特征提取
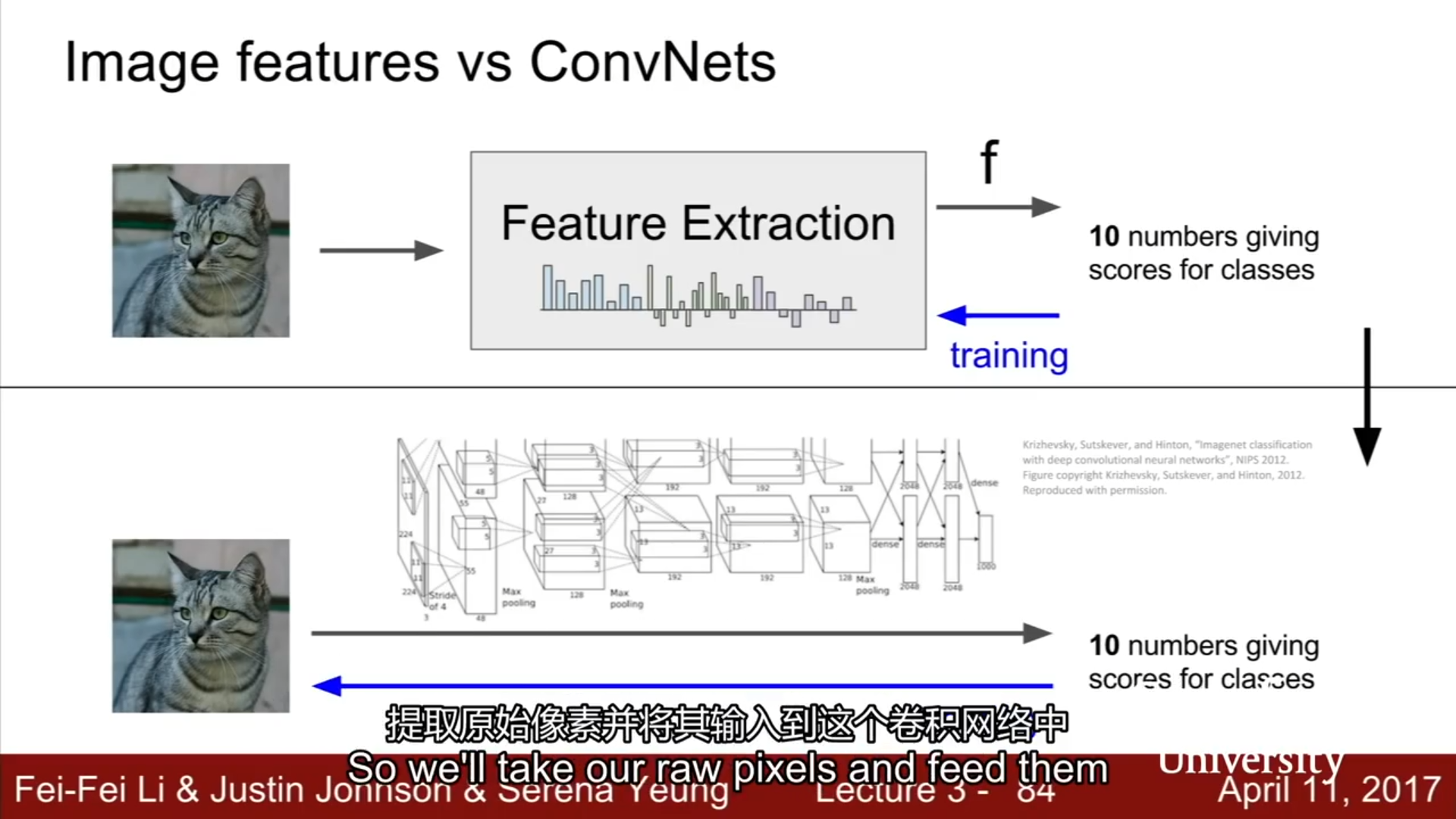
线性分类器就是将图像的原始像素取出,然后直接传入线性分类器,但是这样做效果并不好,所以在深度神经网络大规模运用之前,常用的方法就是首先计算原始图片的各种特征代表,比如说计算与图片形象有关的数值,然后将不同的特征向量组合到一块儿,得到图像的特征表述,最后将这一特征表述传入到线性分类器,而不是将原始像素传入到线性分类器。
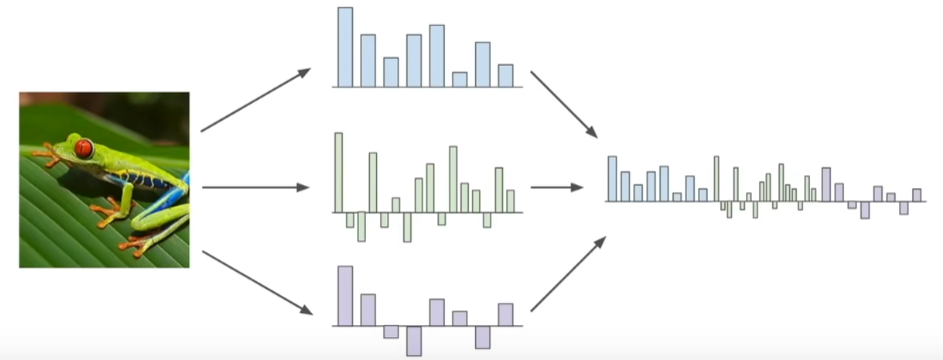
2、特征提取的动机
对于左图的点的分布不能用一个线性决策边界来划分点的种类。但是我们采用一个特征转换(此处使用极坐标转换),得到一个转换特征,就可以把一个复杂的数据集转化成线性可分的。

3、常见的图像特征
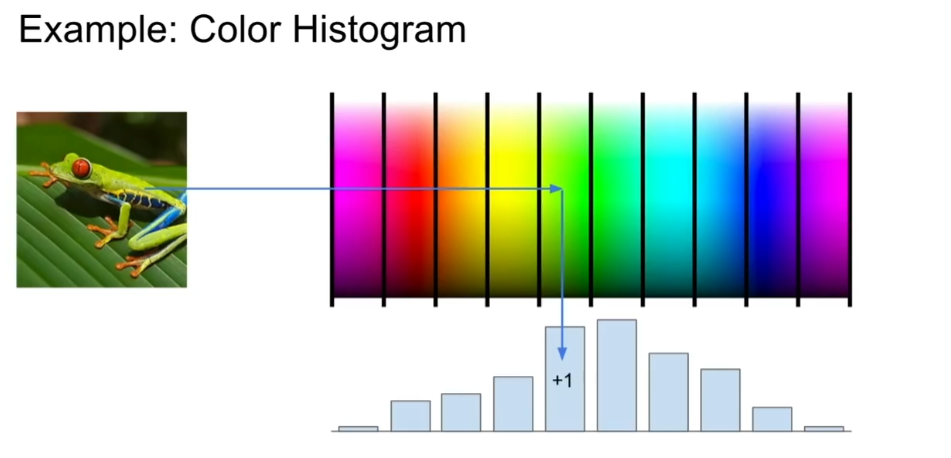
(1)颜色直方图
获取每个像素值对应的光谱,计算每个像素点出现的次数,从全局上告诉我们图像中的有哪些颜色
(2)HOG梯度方向直方图Histogram of Oriented Gradients
HOG特征是通过计算和统计图像局部区域的梯度方向直方图来构成的特征。
将图像划分为8×8像素的小区域,然后在每一个8×8像素区域内,计算每个像素的主要边缘方向,将这些边缘方向量化为几个桶,然后在每个区域内,计算这些不同边缘方向的直方图。现在,完整特征向量将图像中所有不同的8×8区域的边缘方向的不同的柱状图。

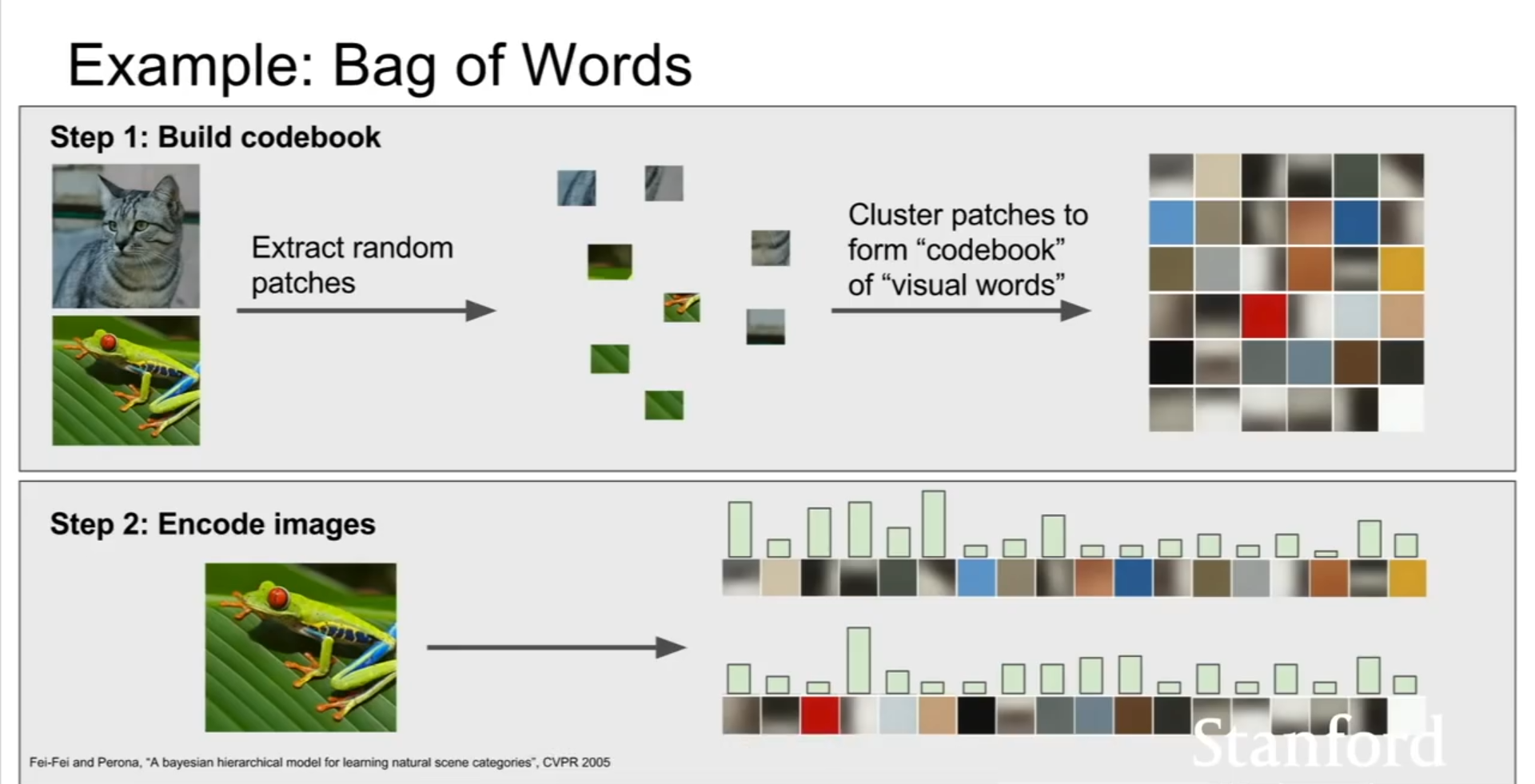
(3)词袋Bag of Words
首先获得一堆图像,然后从这些图像中进行小的随机块的采样,然后采用k均值等方法将他们聚合成簇,从而得到不同的簇中心,这些簇中心可能代表了图像中不同类型的视觉单词。这些视觉单词就像一个码本,用这些视觉单词对图像进行编码,看这些视觉单词在图像中出现过多少次。
4、图像特征vs卷积神经网络(Image features vs ConvNets)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号