第一次个人编程作业github链接
一、PSP表格
| PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
| Planning |
计划 |
|
|
| · Estimate |
· 估计这个任务需要多少时间 |
15 |
15 |
| Development |
开发 |
|
|
| · Analysis |
· 需求分析 (包括学习新技术) |
360 |
420 |
| · Design Spec |
· 生成设计文档 |
30 |
30 |
| · Design Review |
· 设计复审 |
30 |
40 |
| · Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 |
25 |
| · Design |
· 具体设计 |
80 |
90 |
| · Coding |
· 具体编码 |
800 |
1200 |
| · Code Review |
· 代码复审 |
90 |
100 |
| · Test |
· 测试(自我测试,修改代码,提交修改) |
120 |
150 |
| Reporting |
报告 |
|
|
| · Test Repor |
· 测试报告 |
50 |
60 |
| · Size Measurement |
· 计算工作量 |
30 |
25 |
| · Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
60 |
60 |
| |
· 合计 |
1685 |
2070 |
二、计算模块接口
1.计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
1.1函数构成:七个函数
- def __init__(self): 初始化
- def analyze(self, path): 分析处理每行敏感词,调用handle_sensitivewords函数和create_sensitivewordsmap(self, words)函数来实现
- def handle_sensitivewords(self, line0, bushoupath1): 处理敏感词,先匹配中文部首,再获取拼音并组合
- def transform(self, words, bs, bsflag): 将每个敏感词转化为拼音,并进行排列组合
- def combine_char(self, cnt, wordslen, ch, value, swlist): 通过递归将完整拼音和首字母做排列组合,得到类似['xiej','xjiao']
- def create_sensitivewordsmap(self, words): 创建敏感词树trie
- def match_sensitivewords(self, text, linecnt1): 匹配敏感词
|
1.2流程图
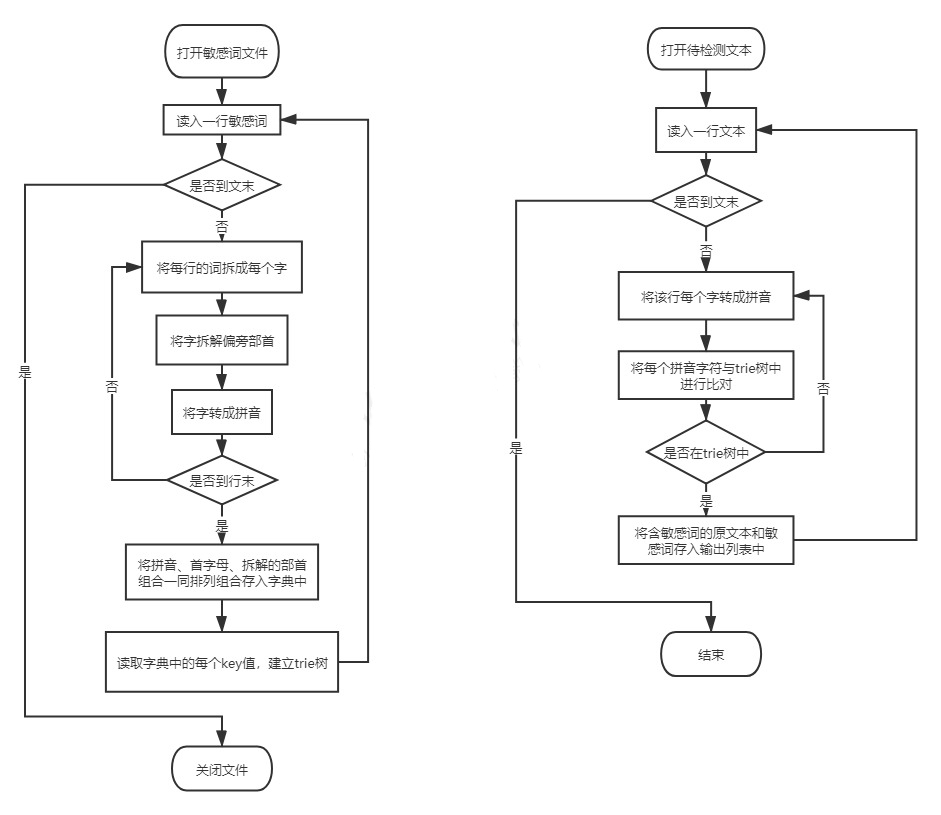
1.3核心算法
DFA算法:基本思想是基于状态转移来检索敏感词,只需要扫描一次待检测文本,就能对所有敏感词进行检测。
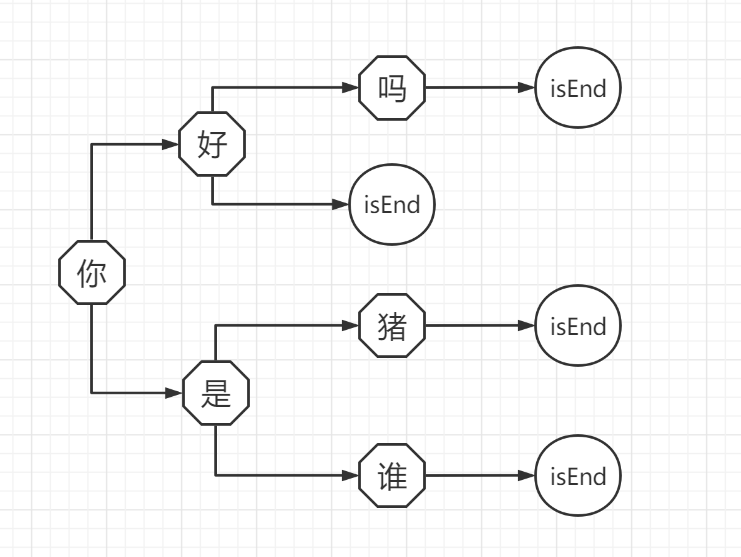
把敏感词排列成树形结构,可以减少搜索次数。我们只需要遍历一次待检测文件,然后搜索有没有对应的子树。如果没有对应的子树,说明不是敏感词,则继续检测下一个字符;如果有相应的子树,就检测下一个字符在不在子树的子树中,如果整个词检测完都满足,就说明是敏感词。我们用字典来存储上述树形结构,在词末记录一个结束标志isEnd。
|
1.4设计思路
{'nihao': '你好',
'nih': '你好',
'nhao': '你好',
'nh': '你好',
'亻尔hao': '你好',
'亻尔h': '你好',
'亻尔女子': '你好',
'ni女子': '你好',
'n女子': '你好'}
|
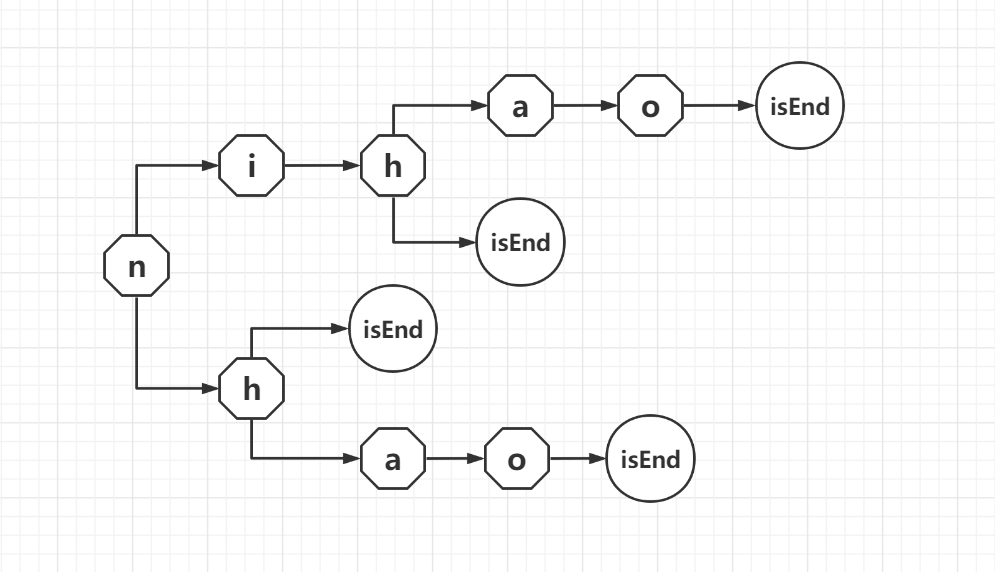
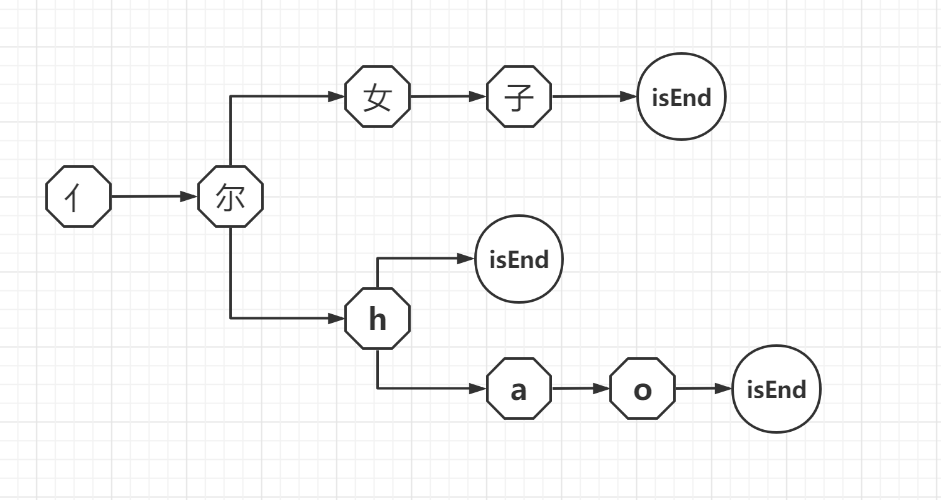
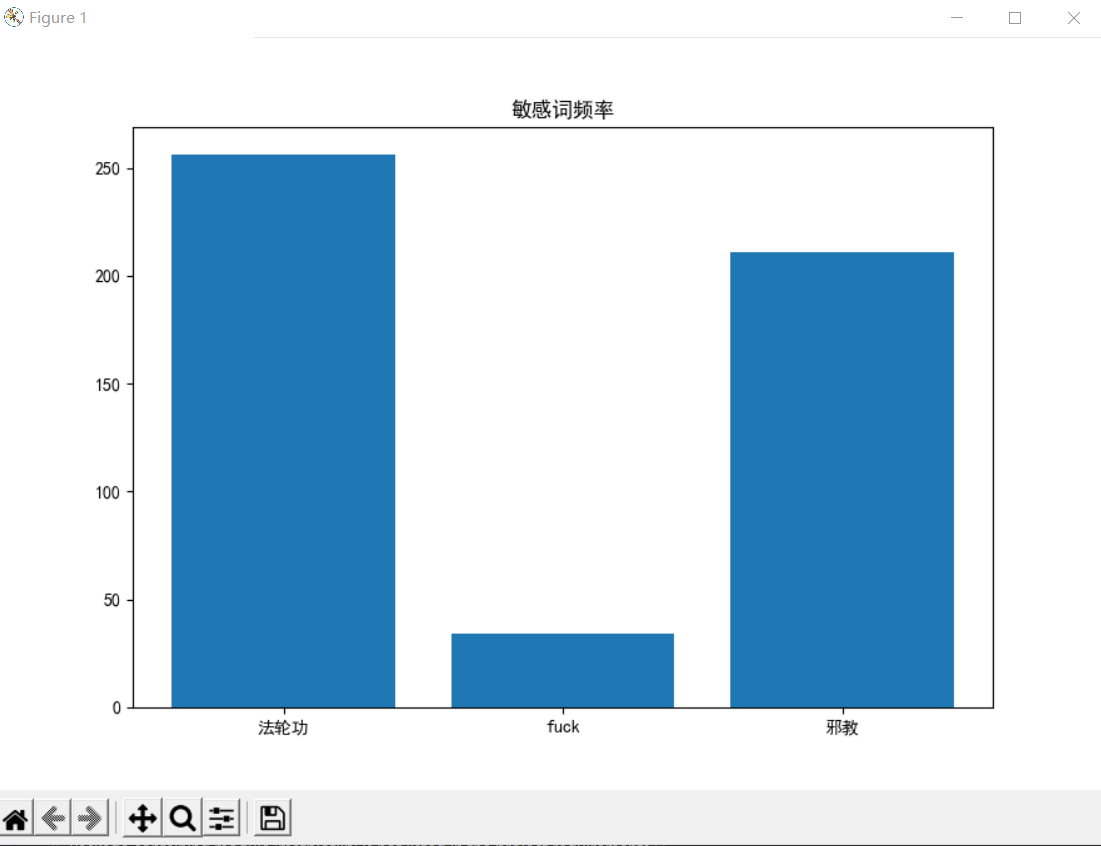
1.5输出可视化:生成统计图(利用matplotlib)
2.计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
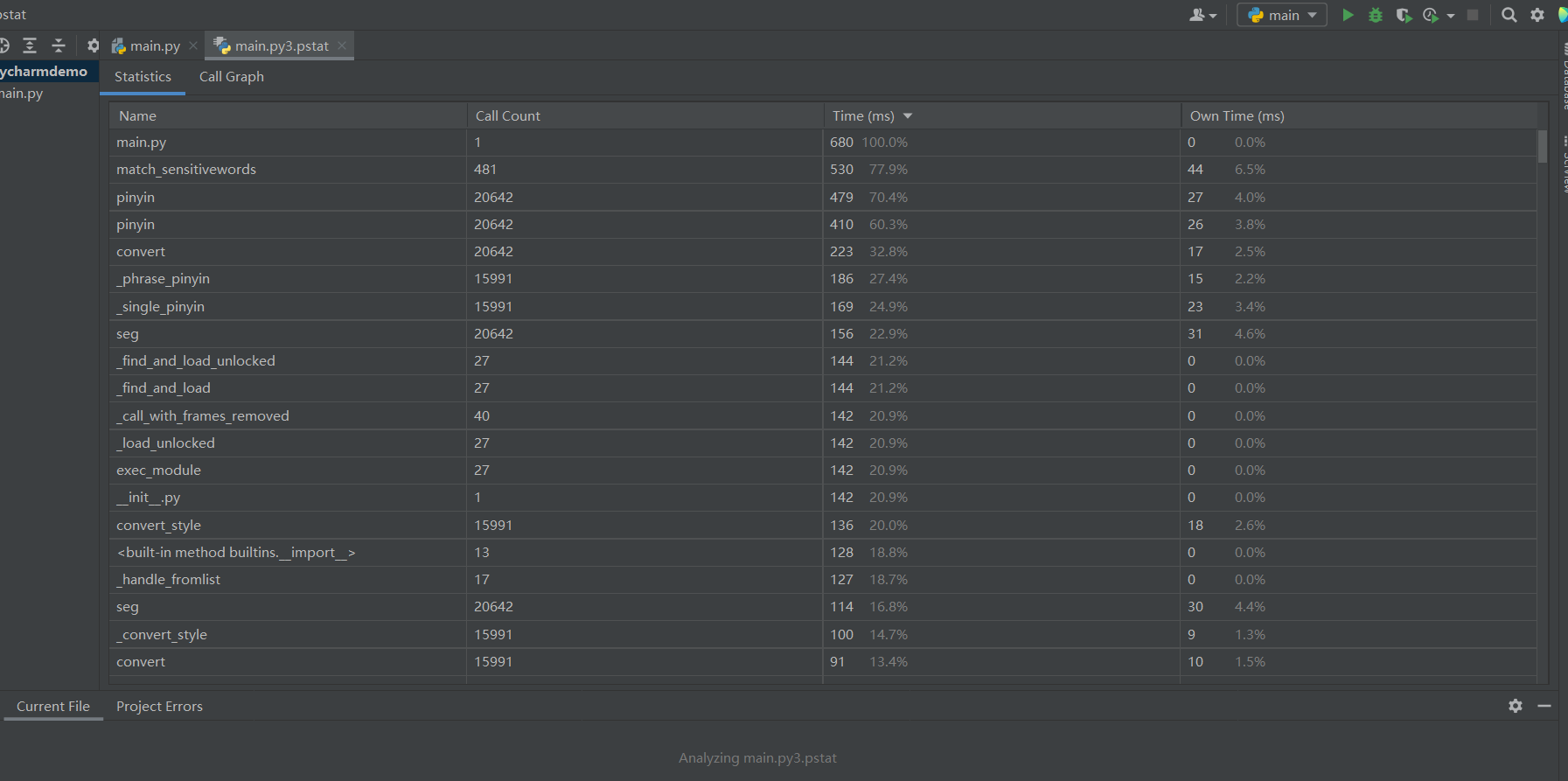
- 从图中可见,match_sensitivewords,即匹配敏感词函数耗时最多,该函数如下
# 匹配敏感词
def match_sensitivewords(self, text, linecnt1):
# text = text.strip() # 敏感词去除首尾空格和换行
ptr = 0 # 索引
# 整行
while ptr < len(text):
nowmap = self.SenWordMap
signflag = 0 # 判断符号是否夹在敏感词中
swwords = "" # 存入敏感词词库中的value
cnt = 0
# print("cnt===%d" % cnt)
exitflag = 0
# 对整行处理
# print(text[ptr:])
for char in text[ptr:]: # 遍历每个词
pinyinstr = ""
for item0 in pypinyin.pinyin(char, style=pypinyin.NORMAL):
pinyinstr += "".join(item0)
# print("ptr=%d,string=%s" % (ptr, pinyinstr))
# 符号夹在敏感词中
if signflag == 1 and pinyinstr[0] in sign:
cnt += 1
# print("cnt==%d" % cnt)
continue
# 数字夹在夹在敏感词中
if signflag == 1 and pinyinstr[0].isdigit():
cnt += 1
# print("cnt==%d" % cnt)
continue
start = ptr # 记录下敏感词在原文中匹配到的起始位置
for ch in pinyinstr:
ch = ch.lower() # 若碰到大写,先转化为小写
# 如果该字符在链表中
if ch in nowmap:
signflag = 1
swwords += ch
# 如果匹配到不是词尾,就进入子链表
if self.delimit not in nowmap[ch]:
nowmap = nowmap[ch]
# 如果匹配到是词尾,就退出循环
else:
self.totalwords += 1 # 敏感词总数加一
ptr += cnt # 更新索引
end = ptr + 1 # 记录下敏感词在原文中匹配到的终止位置
textswwords = text[start:end] # 原文敏感词
# 将三个值存为一行字符串,便于输出
answer.append("Line%d: <%s>%s" % (linecnt1, SenWordDict[swwords], textswwords))
signflag = 0
exitflag = 1
break
# 如果该字符不在,就不匹配,退出循环
else:
# swwords = ""
exitflag = 1
break
if exitflag == 1:
break
cnt += 1
ptr += 1
return self.totalwords
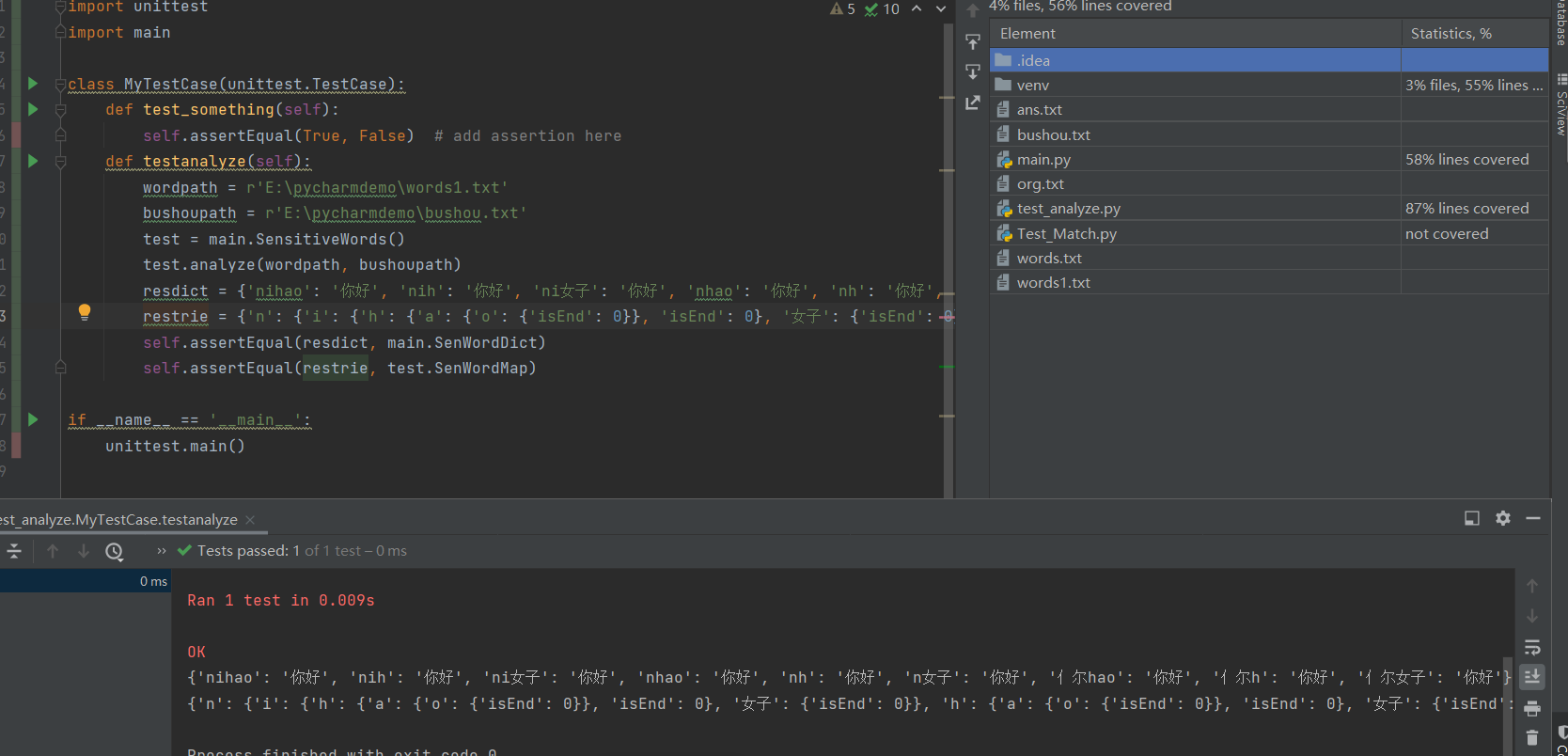
3.计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
单元测试一:match_sensitivewords
- 利用assertEqual函数测试不同组合形式的敏感词
import unittest
import main
class MyTestCase(unittest.TestCase):
def test_something(self):
self.assertEqual(True, False) # add assertion here
def test_match(self):
text = """城市如何留住daxuesheng,是这几年备受关注的公共话题。
日**前,有媒体报道,2017年提出“百万大#%$#学生留汉创业就业计划”的武汉,又明确在“十四五”期间,每年留住30万名大$%学生,5年留住150万名大xs。
日//前安徽省人社厅在答复政协委员“留住大xue生”的提案中提出,将实施在皖大學生婚姻帮扶工程。
"""
res=["Line1: <大学生>daxuesheng", "Line2: <日前>日**前", "Line2: <大学生>大#%$#学生", "Line2: <大学生>大$%学生", "Line2: <大学生>大xs", "Line3: <日前>日//前", "Line3: <大学生>大xue生", "Line3: <大学生>大學生"]
test = main.SensitiveWords()
wordpath = r'E:\pycharmdemo\words1.txt'
bushoupath = r'E:\pycharmdemo\bushou.txt'
test.analyze(wordpath, bushoupath)
linecnt = 1
for line in text.splitlines():
total = test.match_sensitivewords(line, linecnt)
linecnt += 1
self.assertEqual(res, main.answer)
if __name__ == '__main__':
unittest.main()

单元测试二:analyze
- 利用assertEqual函数测试是否能生成对应的字典和trie树
import unittest
import main
class MyTestCase(unittest.TestCase):
def test_something(self):
self.assertEqual(True, False) # add assertion here
def testanalyze(self):
wordpath = r'E:\pycharmdemo\words1.txt'
bushoupath = r'E:\pycharmdemo\bushou.txt'
test = main.SensitiveWords()
test.analyze(wordpath, bushoupath)
resdict = {'nihao': '你好', 'nih': '你好', 'ni女子': '你好', 'nhao': '你好', 'nh': '你好', 'n女子': '你好', '亻尔hao': '你好', '亻尔h': '你好', '亻尔女子': '你好'}
restrie = {'n': {'i': {'h': {'a': {'o': {'isEnd': 0}}, 'isEnd': 0}, '女子': {'isEnd': 0}}, 'h': {'a': {'o': {'isEnd': 0}}, 'isEnd': 0}, '女子': {'isEnd': 0}}, '亻尔': {'女子': {'isEnd': 0}}}
self.assertEqual(resdict, main.SenWordDict)
self.assertEqual(restrie, test.SenWordMap)
if __name__ == '__main__':
unittest.main()
4.计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
- IO异常处理:在读取文件时做了异常处理,如果打开失败了输出"Not Found:",成功则输出"Success"
def test_ioerror(self):
try:
f = open('words.txt', encoding='utf-8')
except IOError:
print("Not Found:'words.txt'")
else:
print("Success")
f.close()
def test_canshu(self):
if len(sys.argv)!=3:
print("Error")
else:
return
三、心得
- 刚看到题目的时候完全不懂要怎么处理,脑子非常懵,啊怎么办啊,我不会啊,我可能最后只能拿到写博客的12分吧。后来开始上网搜索,发现敏感词的过滤可以由好几种方法实现,有正则表达式、DFA算法、AC自动机算法,但是经过广泛地搜索以及学习这三个算法的基本知识以后,我了解到正则表达式对于处理大量的文本数据时会耗费大量的时间,检索效率低,而AC自动机算法对我来说有点难理解,而DFA算法只需要扫描一次待检测文本,就能对所有敏感词进行检测,所以效率比较高,所以最终选择用DFA算法实现。
- 但是选择了以后,要怎么办,我要怎么做,我要从哪里入手,我要用什么语言来完成。浏览了网络上的大量资料后,我发现用python来处理文件好像比较容易,于是就确定用python来完成。因为我的python基础也不扎实,所以在编程时总是要搜索或者尝试。在完成任务的过程中,我感觉我的效率非常低,感觉每天都有花大把的时间做,但是感觉每天都没有做出什么东西来,还是毫无进展。除此之外,我感觉自己搜索资料的能力好像和别人差距很大,别人很容易就能搜到的东西,我要搜索很久才能找到。而且,我经常这调调那改改,但是最终不是这里错就是那里错,设置了一堆的辅助输出,一个一个看,一个一个地跟着代码走找问题,中间一度感觉很崩溃很心累,完全没有开始任务前的那种勇往直前,每天都会思考人生,思考为什么当时选课的时候这么义无反顾,思考这个课到底值不值得我花这么多的时间去研究,太难受了,更加坚定了我以后一定不要当开发型的程序员的想法。与舍友选择了不同的老师,于是就有了每天看着舍友做着为期10天的自我介绍作业,而我这10天做的是焦头烂额的敏感词过滤的编程作业,他们每日清闲,而我每天对着代码发愣,不禁感叹,为什么同是一门课区别竟会如此之大。
- 在最后一天上传最终代码的时候,不小心把整个仓库删除了,心态崩了,反应过来,幸好之前有存一些过程代码在博客园草稿箱中,不然就完蛋了。
- 不过这10天下来,我还是有所收获的。我的python能力得到了极大的提升,我发现python可以引用好多库好方便啊哈哈,搜索资料的能力大大提高,编程思维也有所提升。最终虽然成果不如别人的完整,但是也算是实现了,完成了一个我十天前觉得完全不可能完成的任务。
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号