
1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
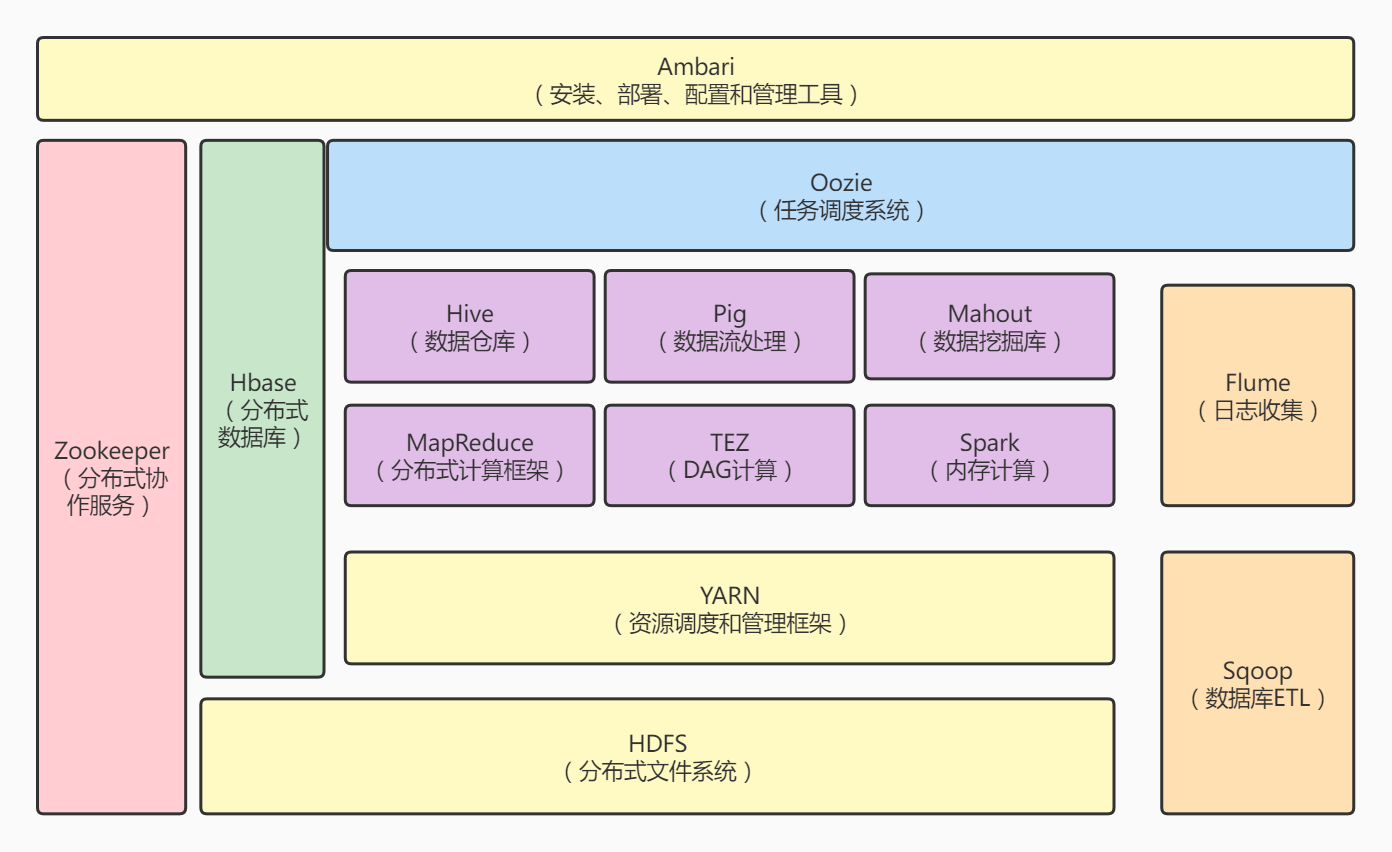
一、HDFS:它是Hadoop两大核心组成部分之一,提供了在廉价服务器集群中进行大规模分布式文件存储的能力。它具有很好的容错能力,可以兼容廉价的硬件设备。它采用了主从结构模型,一个HDFS集群包括一个名称节点和若干个数据节点。
二、MapReduce:它是一种分布式并行编程模型,用于大规模数据集(数据量>1TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度抽象到两个函数:Map和Reduce。它便利了分布式编程工作,编程人员可以将程序运行在分布式系统上,完成海量数据集的计算。
三、YARN:它是负责集群资源调度管理的组件。YARN为计算框架提供统一的资源调度管理服务(包括 CPU、内存等资源),并且能够根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性收缩。
四、Hbase:它是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。它可以支持超大规模数据存储。
HBase利用MapReduce来处理HBase中的海量数据,实现高性能计算;利用 Zookeeper 作为协同服务,实现稳定服务和失败恢复;使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力。
HBase也可以在单机模式下使用,直接使用本地文件系统而不用 HDFS 作为底层数据存储方式。为了提高数据可靠性和系统的健壮性,发挥HBase处理大量数据等功能,一般都使用HDFS作为HBase的底层数据存储方式。
此外,为了方便在HBase上进行数据处理,Sqoop为HBase提供了高效、便捷的RDBMS数据导入功能,Pig和Hive为HBase提供了高层语言支持。
五、Hive:它是一个基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。它提供了类似于关系数据库SQL语言的查询语言HiveQL。
六、Sqoop:它是SQL-to-Hadoop的缩写,主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。通过Sqoop,可以方便地将数据从MySQL、Oracle、PostgreSQL等关系数据库中导入Hadoop(导入到HDFS、HBase或Hive中),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。
七、Oozie:它是一个基于工作流引擎的开源框架,它能够提供对Hadoop MapReduce和Pig Jobs的任务调度与协调。Oozie需要部署到Java Servlet容器中运行。
八、Pig:它是一种数据流语言和运行环境,适合于使用HadooP和MapReduce平台来查询大型半结构化数据集。
九、Mahout:它提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序:Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。
十、Zookeeper:它是高效和可靠的协同工作系统,提供分布式锁之类的基本服务,用于构建分布式应用,减轻分布式应用程序所承担的协调任务。
十一、Ambari:它是一种基于Web的工具,支持ApacheHadoop集群的安装、部署、配置和管理。目前支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、HBase、Zookeeper、Sqoop等。
十二、Flume:它是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。它支持在日志系统中定制各类数据发送方,用于数据收集;同时,Flume提供对数据进行简单处理并写到各种数据接受方的能力。
十三、Spark:它是一种快速、通用、可扩展的分布式大数据分析引擎,能处理大规模数据。Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。其核心技术为弹性分布式数据集,此外还包括 Spark有向无环图 DAG,Spark部署模式以及Spark架构。
十四、TEZ:它是一个apache的开源项目,旨在构建一个应用框架,能通过复杂任务的DAG来处理数据。它是基于当前的hadoop yarn之上。
2.对比Hadoop与Spark的优缺点。
1.数据的存储和处理
- hadoop
Hadoop实质上更多是一个分布式系统基础架构: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,同时还会索引和跟踪这些数据,大幅度提升大数据处理和分析效率。Hadoop 可以独立完成数据的存储和处理工作,因为其除了提供HDFS分布式数据存储功能,还提供MapReduce数据处理功能。
- spark
Spark是一个专门用来对那些分布式存储的大数据进行处理的工具,没有提供文件管理系统,自身不会进行数据的存储。它必须和其他的分布式文件系统进行集成才能运作。可以选择Hadoop的HDFS,也可以选择其他平台。
2.处理速度
-
hadoop
Hadoop是磁盘级计算,计算时需要在磁盘中读取数据;其采用的是MapReduce的逻辑,把数据进行切片计算用这种方式来处理大量的离线数据.
-
spark
它会在内存中以接近“实时”的时间完成所有的数据分析。Spark的批处理速度比MapReduce快近10倍,内存中的数据分析速度则快近100倍。
比如实时的市场活动,在线产品推荐等需要对流数据进行分析场景就要使用Spark。
3.灾难恢复功能
-
hadoop
Hadoop将每次处理后的数据写入磁盘中,对应对系统错误具有天生优势。
-
spark
Spark的数据对象存储在弹性分布式数据集(RDD:)中。“这些数据对象既可放在内存,也可以放在磁盘,所以RDD也提供完整的灾难恢复功能。
3.如何实现Hadoop与Spark的统一部署?
由于Hadoop和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号