
集合类(Collection和Map接口)简介
集合分为Collection和Map,详细分类如下图所示:
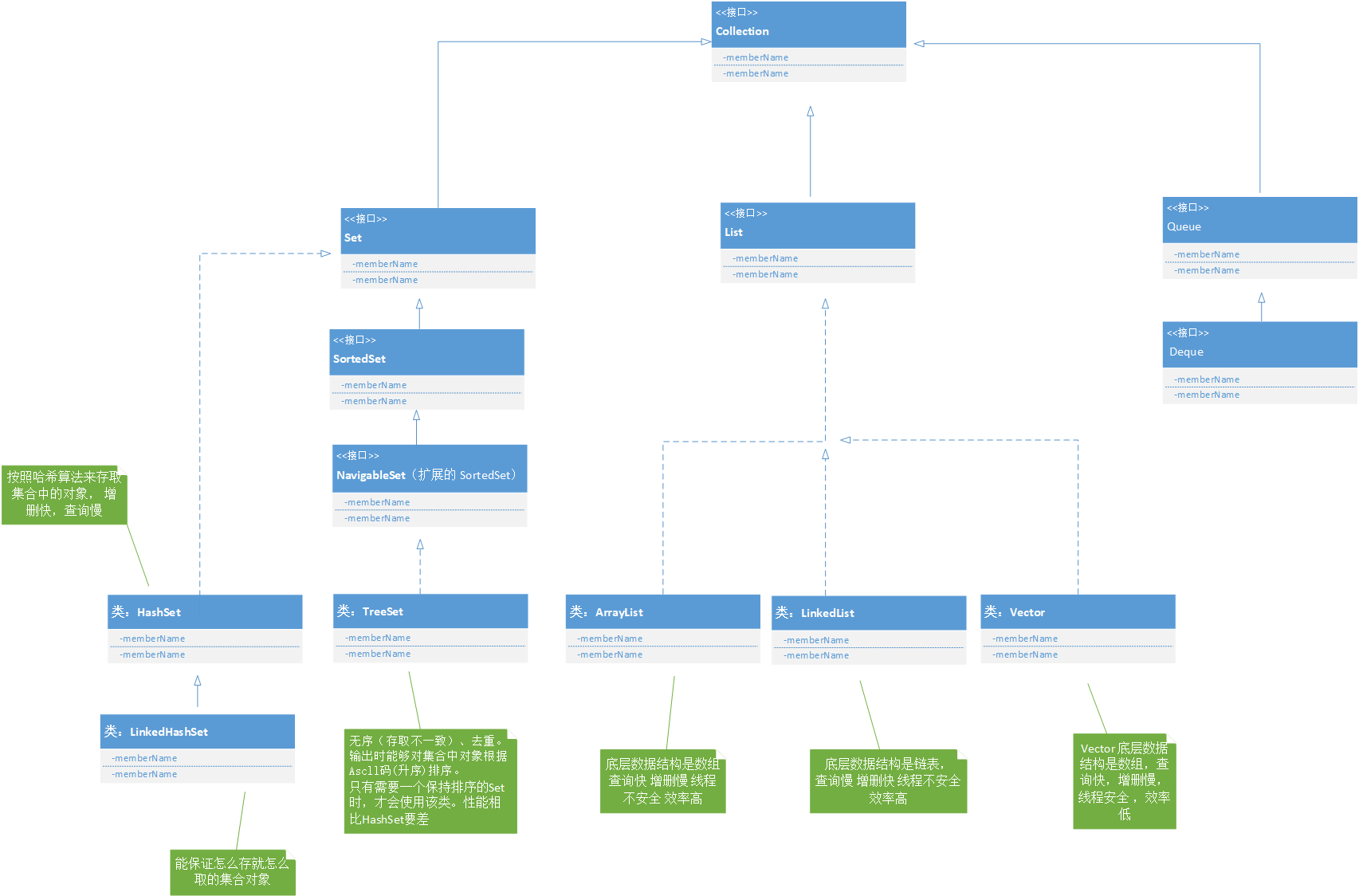
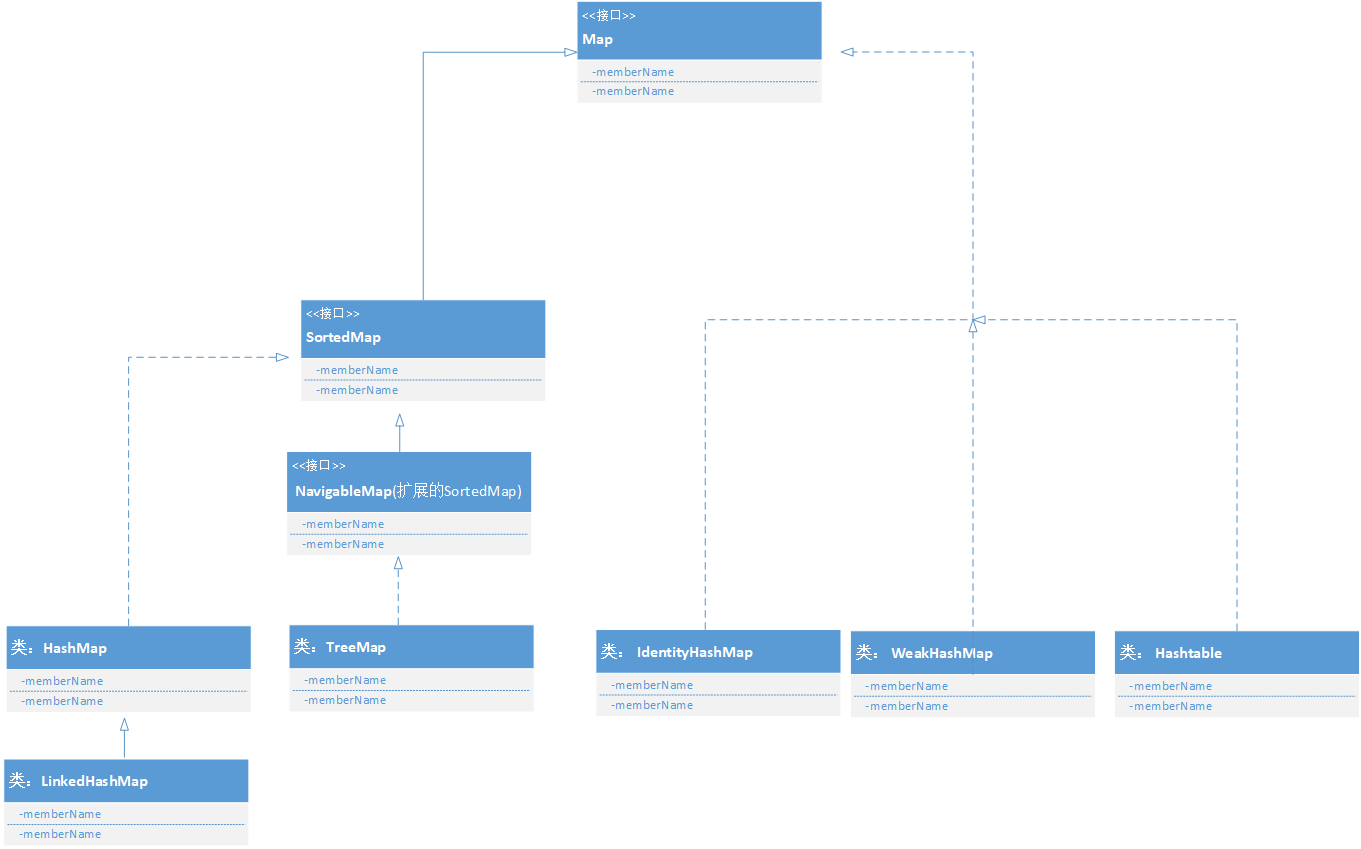
以下是测试验证代码:
//HashSet,无序(存取不一致)、去重 Set set_H = new HashSet(); set_H.add(8); set_H.add(3); set_H.add("Hello"); set_H.add(5); set_H.add(5); System.out.println(set_H);
输出结果:[3, Hello, 5, 8]
//LinkedHashSet能保证怎么存就怎么取的集合对象 ,有序(存取一致)、去重 Set set_L = new LinkedHashSet(); set_L.add(8); set_L.add(3); set_L.add("Hello"); set_L.add(5); set_L.add(5); System.out.println(set_L);
输出结果:[8, 3, Hello, 5]
//TreeSet 能够对集合中对象进行排序,无序(存取不一致)、去重 //排序规则:根据ASCII表大小升序排序 //只能对存储同一种类型的数据才能排序 Set set_T = new TreeSet(); set_T.add("wo"); set_T.add("ai"); set_T.add("study"); set_T.add("java"); set_T.add("java"); System.out.println(set_T);
输出结果:[ai, java, study, wo]
//ArrayList,有序(存取一致)、不去重 //查询快,增删慢 List list_A = new ArrayList(); list_A.add(8); list_A.add(3); list_A.add(1); list_A.add("hello"); list_A.add("world"); list_A.add("world"); System.out.println(list_A);
输出结果:[8, 3, 1, hello, world, world]
//LinkedList,有序(存取一致)、不去重 //查询慢,增删快 List list_L = new ArrayList(); list_L.add(8); list_L.add(3); list_L.add(1); list_L.add("hello"); list_L.add("world"); list_L.add("world"); System.out.println(list_A);
输出结果:[8, 3, 1, hello, world, world]
//HashMap,键无序(存取不一致)、在Map 中插入、删除和定位元素,HashMap 是最好的选择 Map map_H = new HashMap(); map_H.put(452,"张三"); map_H.put(285,"李四"); map_H.put(689,"王五"); map_H.put(968,"赵六"); System.out.println(map_H);
输出结果:{689=王五, 452=张三, 968=赵六, 285=李四}
//LinkedHashMap,键保存了插入的顺序,怎么存就怎么取 Map map_L = new LinkedHashMap(); map_L.put(452,"张三"); map_L.put(285,"李四"); map_L.put(689,"王五"); map_L.put(968,"赵六"); System.out.println(map_L);
输出结果:{452=张三, 285=李四, 689=王五, 968=赵六}
//TreeMap,按键的升序排序
//排序前提:键必须是同一种类型
Map map_T = new TreeMap(); map_T.put(452,"张三"); map_T.put(285,"李四"); map_T.put(689,"王五"); map_T.put(968,"赵六"); System.out.println(map_T);
输出结果:{285=李四, 452=张三, 689=王五, 968=赵六}
总结:
1* 基于array的集合适合查询,而基于linked(链表)的集合则适合添加和删除操作,基于哈希的集合介入二者之间。
即:Array读快改慢,Linked改快读慢,Hash两者之间
2* 在各种Lists中,最好的做法是以ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList();Vector总是比ArrayList慢,所以要尽量避免使用。
3* 在各种Sets中,HashSet通常优于TreeSet(插入、查找)。只有当需要产生一个经过排序的序列,才用TreeSet。TreeSet存在的唯一理由:能够维护其内元素的排序状态。
4* 在各种Maps中HashMap用于快速查找。
5* 当元素个数固定,用Array,因为Array效率是最高的。
结论:最常用的是ArrayList,HashSet,HashMap,Array。而且,我们也会发现一个规律,用TreeXXX都是排序的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号