eBPF学习笔记(一)概述:eBPF架构图、虚拟机架构图、生命周期图
eBPF技术简述
eBPF(extended Berkeley Packet Filter) 是起源于内核的革命性技术,从 2011 年开发至今,eBPF 社区依然非常活跃 。eBPF 可以通过热加载的sandbox程序到内核中而不需要insmod module的方式,避免内核模块的方式可能会引入宕机风险,并具备堪比原生代码的执行效率。eBPF程序不会引起系统宕机,Just-In-Time (JIT) compiler编译器假设代码是安全但有 verification engine从汇编语言级别检查程序的有效性,程序中规定了内存范围、有限的循环、bpf_spin_lock()不会死锁、不可以在free之后使用、不可以有内存泄露等。
使用eBPF技术可以应用在很多场景中:
- 在现代数据中心和云原生环境中提供高性能的网络和负载平衡
- 以低开销提取细粒度的安全可观察数据,帮助应用程序开发人员跟踪应用程序,提供性能故障排除、应用程序和容器运行时安全实施的见解
等等,可能性是无限的。
eBPF架构图
图1 简易的eBPF程序架构图
图1是一个简易的eBPF程序架构图,它描述了一个eBPF程序的主要构成部分和程序编译、运行顺序。先来看一个eBPF程序的主要构成部分:
1. 用户空间的BPF字节码:图1中用户空间绿色的部分,用户空间的BPF程序,文件名一般是xxx.bpf.c,由该文件生成BPF字节码
2. 用户空间的程序代码:图1中用户空间紫色的部分,表述从内核获取数据后的处理逻辑。当程序挂载的系统调用被触发,就会把相应的事件数据传输到perf_event data中,由用户空间的代码来分析行为。
3. 内核空间的verifier: 验证器确保了eBPF程序可以安全运行。它验证程序是否满足几个条件,例如:
- 加载eBPF程序的流程拥有所需的功能(特权)
- 程序不会崩溃或以其他方式损害系统
- 程序不能使用任何未初始化的变量或越界访问内存
- 程序必须符合系统的尺寸要求,不可能加载任意大的eBPF程序
- 程序必须具有有限的复杂性。验证者将评估所有可能的执行路径,并且必须能够在配置的复杂度上限范围内完成分析
- 程序总是运行到结束,即没有死循环
4. 内核空间的JIT Compiler:即时(JIT)编译步骤将程序的通用字节码转换为特定于机器的指令集,以优化程序的执行速度。这使得eBPF程序可以像本地编译的内核代码或作为内核模块加载的代码一样高效地运行。
5. 内核空间的BPF沙箱程序:这是整个程序的核心部分,BPF程序可以被挂载到多种系统点:kprobe、uprobe、tracepoint和perf_events. 至于你关注的系统调用属于那种系统hook点,可以用 bpftrace -l 命令来查询。当程序挂载的系统调用被触发,就会把相应的事件数据传输到perf_event data中.
6. 内核空间的MAPS:eBPF非常重要的能力是能分享收集到的信息并存储状态。为了达到这个目的,eBPF使用maps来存储数据。这些数据可以是各种各样的struct. Maps中的数据可以被用户空间的程序通过系统调用读取。
然后再来看一个eBPF程序的主要流程:
1. 编写BPF代码,生成字节码
2. 加载BPF字节码到内核上
3. 异步读取maps数据
4. 系统事件触发,用户空间接收到事件信息开始处理分析逻辑
eBPF沙箱架构图

图2 eBPF沙箱架构图
如上图2所示,它是一副eBPF沙箱架构图,都是在内核中的。这个图中较为具体的展示了BPF虚拟机的构造以及其和外部组件的关系。eBPF虚拟机是一个RISC指令, 带有寄存器的虚拟机, 内部有11个64位寄存器, 一个程序计数器(PC), 以及一个512字节的固定大小的栈。这里有图1没有显示出来的 BPF Helpers函数和十一个寄存器。你可以通过 `bpftool feature probe ` 查看支持的helpers函数。这里稍微展开说一下这11个寄存器:
r0: 保存函数调用和当前程序退出的返回值r1~r5: 作为函数调用参数, 当程序开始运行时,r1包含一个指向context参数的指针。r6~r9: 在内核函数调用之间得到保留r10: 只读的指向512字节栈的栈指针
对于eBPF到eBPF, eBPF到内核, 每个函数调用最多5个参数, 保存在寄存器r1~r5中. 并且传递参数时, 寄存器r1~r5只能保存常数或者指向堆栈的指针, 不能是任意内存的指针. 所有的内存访问必须先把数据加载到eBPF堆栈中, 然后才能使用. 这样的限制简化内存模型, 帮助eBPF验证器进行正确性检查。
其中,Tail-calls允许 eBPF 程序传入新的eBPF程序。已突破eBPF programs 必须小于等于 4096 bytes的限制.
下面再看一张我自己总结的图,表明了eBPF相关模块间数据传递的关系。
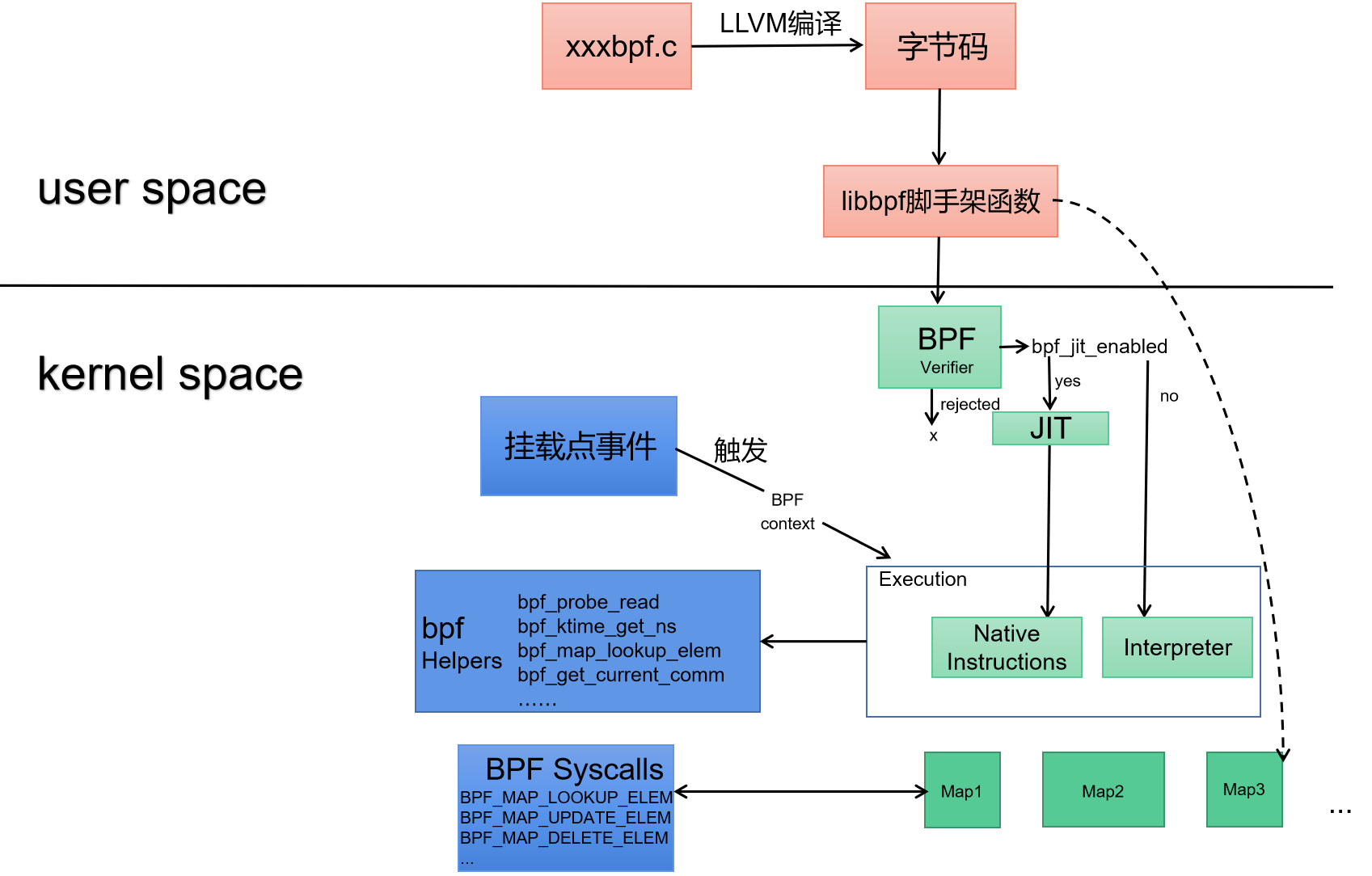
这张图里面,在用户空间编写好一个C源代码,然后用LLVM编译成字节码,然后调用libbpf脚手架函数对字节码进行验证。如果通过验证字节码会被JIT编译成本地机器指令加载到内核钩子函数上。因为机器码在内核中所以可以方便的读取内核参数,但并不是可以随意读取。这里在C源代码中已经用BPF系统调用写好了需要读取的参数。这些BPF系统调用函数也被称作eBPF辅助函数或者Helpers函数。
eBPF程序的一个重要方面是共享收集到的信息和存储状态的能力。为此,eBPF程序可以利用eBPF Maps的概念在广泛的数据结构集中存储和检索数据。可以通过系统调用从eBPF程序和用户空间中的应用程序访问eBPF Maps. Maps数据类型支持但不限于Hash tables,Arrays,LRU (Least Recently Used),Ring Buffer,Stack Trace,LPM (Longest Prefix match) 等等。在用户空间编写的生成字节码的C源文件中使用BPF系统调用定义Maps并最终传入内核空间。当钩子函数触发时,读取相关数据到Maps中,用户空间通过libbpf库函数可以读取到这些值。如果不使用libbpf接口,例如使用BCC可以通过BCC封装的python API来验证、加载eBPF程序到内核空间并读取Maps数据。原理是类似的。
eBPF开发工具链
eBPF程序开发常使用的方法分为bcc、bpftrace、eBPF Go Library和libbpf.
- BCC:BCC是一个框架,该框架使得用户可以写python程序来和eBPF内核函数交互,这些python程序内嵌了eBPF程序。运行python程序就可以生成eBPF字节码并把它们加载到内核。
- bpftrace:bpftrace是一种用于Linux eBPF的高级跟踪语音,在4.x及以上的内核中可用。bpftrace使用LLVM作为后端来编译脚本成eBPF字节码并使用BCC来和Linux eBPF子系统进行交互。bpftrace语言的灵感来自awk、C以及DTrace和SystemTap等早期跟踪程序。
- eBPF Go Library:eBPF Go库提供了一个通用的eBPF库,它将获取eBPF字节码的过程与eBPF程序的加载和管理分离开来。eBPF程序通常是通过编写高级语言创建的,然后使用clang/LLVM编译器编译成eBPF字节码。
- libbpf Library:libbpf 库是基于 C/C++ 的通用 eBPF 库,可以帮助把从clang/LLVM编译器生成的eBPF对象文件的加载解耦到内核,它通过为应用程序提供易于使用的API库来抽象化和BPF系统调用的交互操作。例如开源项目tracee就是使用的libbpf进行开发的,它使用的libbpfgo其实是对libbpf用go语言进行的封装。
以上四种方法只是书写eBPF程序和生成eBPF字节码的方式不同,也就是图1的第一个步骤不同,其他的都是一致的。
eBPF对象的生命周期
请您尝试回答一个问题: eBPF用户态程序与内核态程序交互,加载BPF字节码后,能退出吗?退出后,内核hook的BPF函数还工作吗?创建的map是否还存在?如果要回答这些问题,不得不提BPF程序的加载机制,BPF对象生命周期。
用户态程序通过文件描述符FD来访问BPF对象(progs、maps、调试信息),每个对象都有一个引用计数器。用户态打开、读取相应FD,对应计数器会增加。若FD关闭,引用计数器减少,当refcnt为0时,内核会释放BPF对象,那么这个BPF对象将不再工作。
在安全场景里,用户态的后门进程若退出后,后门的eBPF程序也随之退出。在做安全检查时,这可以作为一个有利特征,查看进程列表中是否包含可疑进程。
但并非所有BPF对象都会随着用户态进程退出而退出。从内核原理来看,只需要保证refcnt大于0,就可以让BPF对象存活,让后门进程持续工作了。其实在BPF的程序类型中,像XDP、TC和基于CGROUP的钩子是全局的,不会因为用户态程序退出而退出。相应FD会由内核维护,保证refcnt计数器不为零,从而继续工作。
溯源
安全工程师经常需要根据不同场景作不同的溯源策略。本文给的溯源方式中,都使用了eBPF的相关接口,这意味着:如果恶意程序比检查工具运行的早,那么对于结果存在伪造的可能。
短生命周期 BPF程序类型代表
k[ret]probe
u[ret]probe
tracepoint
raw_tracepoint
perf_event
socket filters
so_reuseport
特点是基于FD管理,内核自动清理,对系统稳定性更好。这种程序类型的后门,在排查时特征明显,就是用户态进程。并且可以通过系统正在运行的BPF程序列表中获取。
长生命周期 BPF程序类型代表
XDP
TC
LWT
CGROUP


参考文献
1. https://ebpf.io/what-is-ebpf/
2. https://www.anquanke.com/post/id/263988
3. https://facebookmicrosites.github.io/bpf/blog/2018/08/31/object-lifetime.html
4. https://blogs.igalia.com/dpino/2019/01/07/introduction-to-xdp-and-ebpf/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号