golang语言中的意想不到
堆与栈
编译器会自动选择在栈上还是在堆上分配局部变量的存储空间,但可能令人惊讶的是,这个选择并不是由用var还是new声明变量的方式决定的。在Go语言规范中甚至故意没有讲到栈和堆的概念。我们无法知道函数参数或局部变量到底是保存在栈中还是堆中,编译器和运行时会帮我们搞定这个变量是在;同样不要假设变量在内存中的位置是固定不变的,指针随时可能会变化,特别是在你不期望它变我们只需要知道它们能够正常工作就可以了。看看下面这个例子:
var global *int
func f() {
var x int
x = 1
global = &x
}
func g() {
y := new(int)
*y = 1
}
f函数里的x变量必须在堆上分配,因为它在函数退出后依然可以通过包一级的global变量找到,虽然它是在函数内部定义的;用Go语言的术语说,这个x局部变量从函数f中逃逸了。相反,当g函数返回时,变量 *y 将是不可达的,也就是说可以马上被回收的。因此, *y 并没有从函数g中逃逸,编译器可以选择在栈上分配 *y 的存储空间(译注:也可以选择在堆上分配,然后由Go语言的GC回收这个变量的内存空间),虽然这里用的是new方式。其实在任何时候,你并不需为了编写正确的代码而要考虑变量的逃逸行为,要记住的是,逃逸的变量需要额外分配内存,同时对性能的优化可能会产生细微的影响。Go语言的自动垃圾收集器对编写正确的代码是一个巨大的帮助,但也并不是说你完全不用考虑内存了。你虽然不需要显式地分配和释放内存,但是要编写高效的程序你依然需要了解变量的生命周期。例如,如果将指向短生命周期对象的指针保存到具有长生命周期的对象中,特别是保存到全局变量时,会阻止对短生命周期对象的垃圾回收(从而可能影响程序的性能)。
sync.Pool的实现原理和应用场景
众所周知,go是自动垃圾回收的(garbage collector),这大大减少了程序编程负担。但gc是一把双刃剑,带来了编程的方便但同时也增加了运行时开销,使用不当甚至会严重影响程序的性能。因此性能要求高的场景不能任意产生太多的垃圾,如何解决呢?那就是要重用对象了,我们可以简单的使用一个chan把这些可重用的对象缓存起来,但如果很多goroutine竞争一个chan性能肯定是问题.....由于golang团队认识到这个问题普遍存在,为了避免大家重造车轮,因此官方统一出了一个包Pool。放到sync包里面大概是因为它也是基于共享变量的并发方法之一。Pool的使用方法如下:
package main
import(
"fmt"
"sync"
)
func main() {
p := &sync.Pool{
New: func() interface{} {
return 0
},
}
a := p.Get().(int)
p.Put(1)
b := p.Get().(int)
fmt.Println(a, b)
}
上面创建了一个缓存int对象的一个pool,先从池获取一个对象然后放进去一个对象再取出一个对象,程序的输出是0 1。创建的时候可以指定一个New函数,获取对象的时候如何在池里面找不到缓存的对象将会使用指定的new函数创建一个返回,如果没有new函数则返回nil.既然是缓存的Pool,那么这个Pool的缓存有没有长度限制?是否是线程安全的呢?开销如何呢?
- 创建pool的时候是不能指定大小的,所有sync.Pool的缓存对象数量是没有限制的,只受限于内存。因此使用sync.pool是没办法做到控制缓存对象数量的个数的。另外sync.pool缓存对象的期限是很诡异的,先看一下src/pkg/sync/pool.go里面的一段实现代码:
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
可以看到pool包在init的时候注册了一个poolCleanup函数,它会清除所有的pool里面的所有缓存的对象,该函数注册进去之后会在每次gc之前都会调用,因此sync.Pool缓存的期限只是两次gc之间这段时间。例如我们把上面的例子改成下面这样之后,输出的结果将是0 0。正因gc的时候会清掉缓存对象,也不用担心pool会无限增大的问题。
a := p.Get().(int)
p.Put(1)
runtime.GC()
b := p.Get().(int)
fmt.Println(a, b)
这是很多人错误理解的地方,正因为这样,我们是不可以使用sync.Pool去实现一个socket连接池的。
- 缓存对象的开销
如何在多个goroutine之间使用同一个pool做到高效呢?官方的做法就是尽量减少竞争,因为sync.pool为每个P(对应cpu,golang的调度模型G-P-M)都分配了一个子池,如下图:
![]()
当执行一个pool的get或者put操作的时候都会先把当前的goroutine固定到某个P的子池上面,然后再对该子池进行操作。每个子池里面有一个私有对象和共享列表对象,私有对象是只有对应的P能够访问,因为一个P同一时间只能执行一个goroutine,因此对私有对象存取操作是不需要加锁的。共享列表是和其他P分享的,因此操作共享列表是需要加锁的。
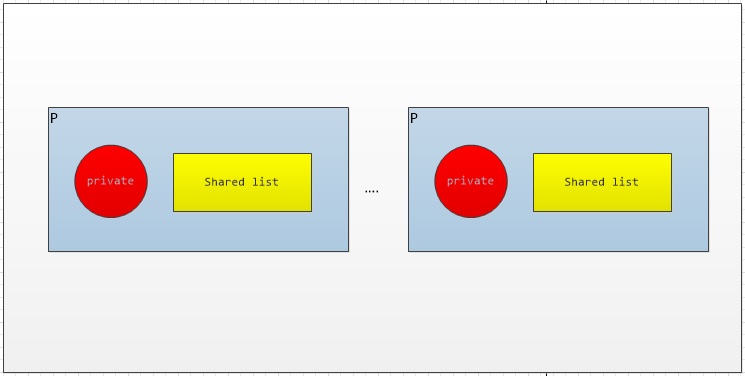
获取对象过程是:
- 固定到某个P,尝试从私有对象获取,如果私有对象非空则返回该对象,并把私有对象置空;
- 如果私有对象是空的时候,就去当前子池的共享列表获取(需要加锁);
- 如果当前子池的共享列表也是空的,那么就尝试去其他P的子池的共享列表偷取一个(需要加锁);
- 如果其他子池都是空的,最后就用用户指定的New函数产生一个新的对象返回。
可以看到一次get操作最少0次加锁,最大N(N等于MAXPROCS)次加锁。
归还对象的过程:
- 固定到某个P,如果私有对象为空则放到私有对象;
- 否则加入到该P子池的共享列表中(需要加锁)。
可以看到一次put操作最少0次加锁,最多1次加锁。
由于goroutine具体会分配到那个P执行是golang的协程调度系统决定的,因此在MAXPROCS>1的情况下,多goroutine用同一个sync.Pool的话,各个P的子池之间缓存的对象是否平衡以及开销如何是没办法准确衡量的。但如果goroutine数目和缓存的对象数目远远大于MAXPROCS的话,概率上说应该是相对平衡的。
总的来说,sync.Pool的定位不是做类似连接池的东西,它的用途仅仅是增加对象重用的几率,减少gc的负担,而开销方面也不是很便宜的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号