云计算底层技术-虚拟网络设备(Bridge,VLAN,VxLan)
转自:https://opengers.github.io/openstack/openstack-base-virtual-network-devices-bridge-and-vlan/
openstack底层技术-各种虚拟网络设备一(Bridge,VLAN)
openstack底层技术-各种虚拟网络设备二(tun/tap,veth)
IBM网站上有一篇高质量文章Linux 上的基础网络设备详解。本文会参考文章部分内容,本系列介绍OpenStack使用的这些网络设备包括Bridge,VLAN,tun/tap, veth,vxlan/gre。本篇先介绍Bridge和VLAN相关,其它在下一篇中介绍
OpenStack一般分为计算,存储,网络三部分。考虑构建一个灵活的可扩展的云网络环境,而物理网络架构一般是固定和难于扩展的,因此虚拟网络将更有优势。Linux平台上实现了各种不同功能的虚拟网络设备,包括Bridge,Vlan,tun/tap,veth pair,vxlan/gre,...,这些虚拟设备就像一个个积木块一样,被OpenStack组合用于构建虚拟网络。 还有火热的Docker,docker容器的隔离技术实现脱胎于Linux平台上的namspace,以及更早的chroot。
文中会牵涉虚拟机,所以文中出现的”主机”一词明确表示一台物理机,”接口”指挂载到网桥上的网络设备,环境如下:
CentOS Linux release 7.3.1611 (Core)
Linux controller 3.10.0-514.16.1.el7.x86_64 #1 SMP Wed Apr 12 15:04:24 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
OpenStack社区版 Newton
Linux Bridge
内核模块bridge
[root@controller ~]# modinfo bridge
filename: /lib/modules/3.10.0-514.16.1.el7.x86_64/kernel/net/bridge/bridge.ko
Bridge是Linux上工作在内核协议栈二层的虚拟交换机,虽然是软件实现的,但它与普通的二层物理交换机功能一样。可以添加若干个网络设备(em1,eth0,tap,..)到Bridge上(brctl addif)作为其接口,添加到Bridge上的设备被设置为只接受二层数据帧并且转发所有收到的数据包到Bridge中(bridge内核模块),在Bridge中会进行一个类似物理交换机的查MAC端口映射表,转发,更新MAC端口映射表这样的处理逻辑,从而数据包可以被转发到另一个接口/丢弃/广播/发往上层协议栈,由此Bridge实现了数据转发的功能。如果使用tcpdump在Bridge接口上抓包,是可以抓到桥上所有接口进出的包
跟物理交换机不同的是,运行Bridge的是一个Linux主机,Linux主机本身也需要IP地址与其它设备通信。但被添加到Bridge上的网卡是不能配置IP地址的,他们工作在数据链路层,对路由系统不可见。不过Bridge本身可以设置IP地址,可以认为当使用brctl addbr br0新建一个br0网桥时,系统自动创建了一个同名的隐藏br0网络设备。br0一旦设置IP地址,就意味着br0可以作为路由接口设备,参与IP层的路由选择(可以使用route -n查看最后一列Iface)。因此只有当br0设置IP地址时,Bridge才有可能将数据包发往上层协议栈。
根据下图来具体分析下Bridge工作过程
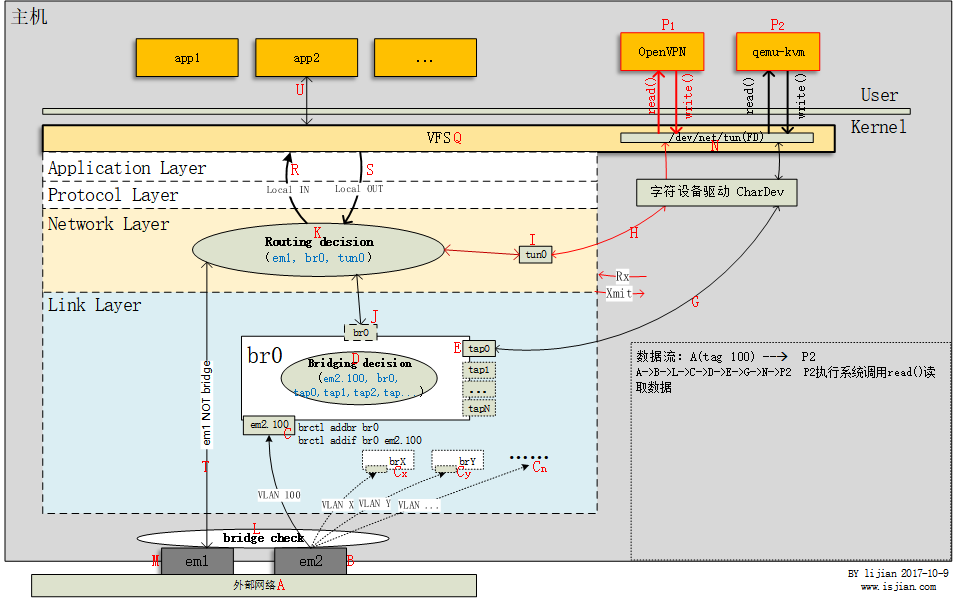
上图主机有em1和em2两块网卡,有网桥br0。用户空间进程有app1,app2等普通网络应用,还有OpenVPN进程P1,以及一台或多台kvm虚拟机P2(kvm虚拟机实现为主机上的一个qemu-kvm进程,下文用qemu-kvm进程表示虚拟机)。此主机上使用到了多种虚拟网络设备,在具体介绍某个虚拟网络设备时,我们可以忽略其它网络设备工作细节,只专注于当前网络设备。下面来具体分析网桥br0
Bridge处理数据包流程
图中可以看到br0有N个tap类型接口(tap0,..,tapN),tap设备名称可能不同,例如tap45400fa0-9c或vnet*,但都是tap设备。一个”隐藏”的br0接口(可设置IP),以及物理网卡em2的一个VLAN子设备em2.100(这里简单看作有一个网卡桥接到br0上即可,VLAN下面会讲),他们都工作在链路层(Link Layer)。
来看数据从外部网络(A)发往虚拟机(P2)qemu-kvm这一过程,首先数据包从em2(B)物理网卡进入,之后em2将数据包转发给其vlan子设备em2.100,经过Bridge check(L)发现子设备em2.100属于网桥接口设备,因此数据包不会发往协议栈上层(T),而是进入bridge代码处理逻辑,从而数据包从em2.100接口(C)进入br0,经过Bridging decision(D)发现数据包应当从tap0(E)接口发出,此时数据包离开主机网络协议栈(G),发往被用户空间进程qemu-kvm打开的字符设备/dev/net/tun(N),qemu-kvm进程执行系统调用read(fd,...)从字符设备读取数据。 这个过程中,外部网络A发出的数据包是不会也没必要进入主机上层协议栈的,因为A是与主机上的P2虚拟机通信,主机只是起到一个网桥转发的作用
作为网桥的对比,如果是从网卡em1(M)进入主机的数据包,经过Bridge check(L)后,发现em1非网桥接口,则数据包会直接发往(T)协议栈IP层,从而在Routing decision环节决定数据包的去向(A –> M –> T –> K)
Bridging decision
上图中网桥br0收到数据包后,根据数据包目的MAC的不同,Bridging decision环节(D)对数据包的处理有以下几种:
- 包目的MAC为Bridge本身MAC地址(当
br0设置有IP地址),从MAC地址这一层来看,收到发往主机自身的数据包,交给上层协议栈(D –> J) - 广播包,转发到Bridge上的所有接口(br0,tap0,tap1,tap…)
- 单播&&存在于MAC端口映射表,查表直接转发到对应接口(比如 D –> E)
- 单播&&不存在于MAC端口映射表,泛洪到Bridge连接的所有接口(br0,tap0,tap1,tap…)
- 数据包目的地址接口不是网桥接口,桥不处理,交给上层协议栈(D –> J)
Bridge与netfilter
Linux防火墙是通过netfiler这个内核框架实现,netfiler用于管理网络数据包。不仅具有网络地址转换(NAT)的功能,也具备数据包内容修改、以及数据包过滤等防火墙功能。利用运作于用户空间的应用软件,如iptables/firewalld/ebtables等来控制netfilter。Netfilter在内核协议栈中指定了五个处理数据包的钩子(hook),分别是PRE_ROUTING、INPUT、OUTPUT、FORWARD与POST_ROUTING,通过iptables/firewalld/ebtables等用户层工具向这些hook点注入一些数据包处理函数,这样当数据包经过相应的hook时,处理函数就被调用,从而实现包过滤功能。这些用户层工具中,iptables工作在IP层,只能过滤IP数据包;ebtables工作在数据链路层,只能过滤以太网帧(比如更改源或目的MAC地址)
当主机上没有Bridge存在时,从网卡进入主机的数据包会依次穿过主机内核协议栈,最后到达应用层交给某个应用程序处理。这样我们可以很方便的使用iptables设置本主机的防火墙规则。进入数据包流向对应下图路径A --> L --> T --> ...
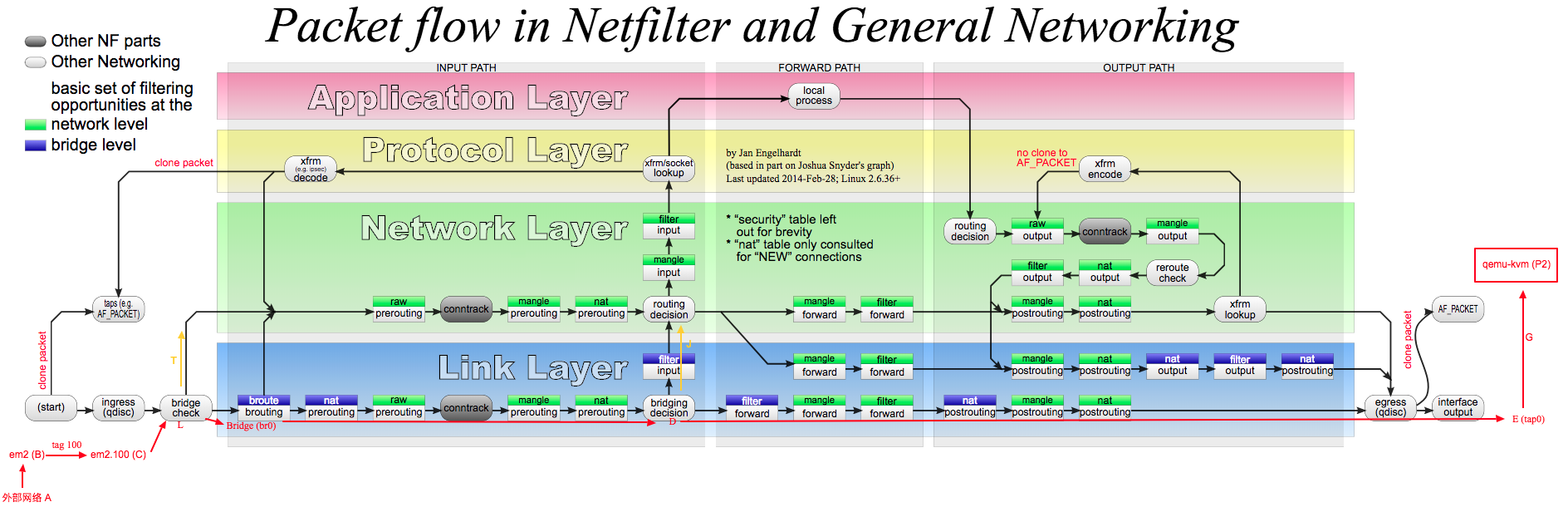
Bridge的出现使Linux上设置防火墙变得复杂,因为此时从物理网卡进入主机的数据包目的地可能是其上运行的一台虚拟机。上图是上面介绍的数据从外部网络(A)发往虚拟机(P2)这一过程中数据包所经过的防火墙链(文中的两张图可以对比来看)。物理网卡em2子设备em2.100从外部网络A收到二层数据包,经过bridge check后进入br0并穿越一系列防火墙链L --> D --> E,最终从Bridge上的另一个接口tap0发出。上图红色导向线可以很清楚看到整个过程中数据包是没有进入主机内核协议栈的,因此位于主机IP层(Network Layer)的iptables根本无法过滤L --> D --> E这一路径的数据包。那有没有办法使iptables能够过滤Bridge中的数据包呢?
-
ebtables只可以简单过滤二层以太网帧,无法过滤ipv4数据包。
-
当然也可以在虚拟机内使用iptables,但是一般不会这么玩,特别是在云平台环境。 一个原因是如果一台主机上运行有10台虚拟机,那就需要分别登录这10台虚拟机设置其iptables规则,工作量会多很多。而且这么做意味着云平台必须要能够登录用户的虚拟机来设置iptables规则。 OpenStack中安全组也是iptables实现,我们在虚拟机内部并没有发现有iptables规则存在。
-
解决办法就是下文要讲的
bridge_netfilter
What is bridge-nf?
It is the infrastructure that enables {ip,ip6,arp}tables to see bridged IPv4, resp. IPv6, resp. ARP packets. Thanks to bridge-nf, you can use these tools to filter bridged packets, letting you make a transparant firewall. Note that bridge-nf is also referred to as bridge-netfilter and br-nf, the term bridge-nf should be preferred.
来自:Bridge-nf Frequently Asked Questions
为了解决上面提到的问题,Linux内核引入了bridge_netfilter,简称bridge_nf。bridge_netfilter在链路层Bridge代码中插入了几个能够被iptables调用的钩子函数,Bridge中数据包在经过这些钩子函数时,iptables规则被执行(上图中最下层Link Layer中的绿色方框即是iptables插入到链路层的chain,蓝色方框为ebtables chain)。这就使得{ip,ip6,arp}tables能够”看见”Bridge中的IPv4,ARP等数据包。这样不管此数据包是发给主机本身,还是通过Bridge转发给虚拟机,iptables都能完成过滤。
如何使用bridge_nf
从Linux 2.6.1内核开始,可以通过设置内核参数开启bridge_netfilter机制。看名字就很容易知道具体作用
[root@controller ~]# sysctl -a |grep 'bridge-nf-'
net.bridge.bridge-nf-call-arptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
...
然后在iptables中使用-m physdev引入相应模块,以文中第一张图上的虚拟机P2为例,它的虚拟网卡tap0桥接在br0上。我们在主机上设置如下iptables规则:丢弃从网桥br0的tap0接口进入的数据包。
#查看网桥
#brctl show
bridge name bridge id STP enabled interfaces
br0 8000.f8bc1212c3a0 no em1
tap
#操作对象是tap0
#ptables -t raw -A PREROUTING -m physdev --physdev-in tap0 -j DROP
注意iptables -m physdev操作对象是Bridge上的某个接口,因此规则的有效范围是针对从此接口进出Bridge的数据包
还需要注意一点,这条命令是在主机上执行的,从主机角度看,主机收到从tap0接口进入的数据包,因此使用--physdev-in。但是从虚拟机P2角度来看,它发出了数据包,发给主机上的网桥br0。因此上面这条iptables命令实际的作用是丢弃虚拟机P2发出的数据包,也就是禁止虚拟机P2访问外网。方向要分清,后面讲到/tun/tap设备时会细说
上面介绍了使用iptables过滤Bridge中数据包的方法,实际中如果直接使用iptables命令显然太繁琐,而且如果主机上有多台虚拟机的话,网桥接口就会变多导致容易出错,需要依靠工具去做这些。
使用libvirt提供的virsh工具
libvirt的virsh nwfilter-*系列命令提供了设置虚拟机防火墙的功能,它其实是封装了iptables过滤Bridge中数据包的命令(-m physdev)。它使用多个xml文件,每个xml文件中都可以定义一系列防火墙规则,然后把某个xml文件应用到某虚拟机的某张网卡(Bridge中的接口),这样就完成了对此虚拟机的这张网卡的防火墙设置。当然可以把一个定义好防火墙规则的xml文件应用到多台虚拟机。
#查看用于设置
# virsh --help |grep nwfilter
nwfilter-define define or update a network filter from an XML file
nwfilter-dumpxml network filter information in XML
nwfilter-edit edit XML configuration for a network filter
nwfilter-list list network filters
nwfilter-undefine undefine a network filter
# 定义有防火墙规则的xml文件
# virsh nwfilter-dumpxml centos6.3_filter
<filter name='centos6.3_filter' chain='root'>
<uuid>b1fdd87c-a44c-48fb-9a9d-e30f1466b720</uuid>
<rule action='accept' direction='in' priority='400'>
<tcp dstportstart='8000' dstportend='8002'/>
</rule>
<rule action='accept' direction='in' priority='400'>
<tcp srcipaddr='172.16.1.0' srcipmask='24'/>
</rule>
</filter>
#查看定义的防火墙xml文件
# virsh nwfilter-list
UUID Name
------------------------------------------------------------------
69754f43-0325-453f-bd53-4a6e3ab5d456 centos6.3_filter
#在虚拟机xml文件中应用centos6.3_filter
<interface type='bridge'>
<mac address='f8:c9:79:ce:60:01'/>
<source bridge='br0'/>
<model type='virtio'/>
<filterref filter='centos6.3_filter'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
</interface>
openstack中的安全组
像openstack等很多云平台在web控制台中都会提供有设置虚拟机防火墙功能(安全组),可以很方便的添加应用防火墙规则到云主机
在OpenStack部署中,若使用Bridge实现虚拟网络,其安全组功能就是依靠bridge_nf实现,计算节点上iptables才能”看见”并过滤发往其上instance的数据包,如下是OpenStack计算节点上部分iptables规则,当启用安全组时,OpenStack会自动设置net.bridge.bridge-nf-call-iptables = 1等内核参数,不用再明确设置。 tap10f15e45-aa为该计算节点上某instance网卡(tap设备)
...
#针对虚拟网卡tap10f15e45-aa的部分规则
-A neutron-filter-top -j neutron-linuxbri-local
-A neutron-linuxbri-FORWARD -m physdev --physdev-out tap10f15e45-aa --physdev-is-bridged -m comment --comment "Direct traffic from the VM interface to the security group chain." -j neutron-linuxbri-sg-chain
-A neutron-linuxbri-FORWARD -m physdev --physdev-in tap10f15e45-aa --physdev-is-bridged -m comment --comment "Direct traffic from the VM interface to the security group chain." -j neutron-linuxbri-sg-chain
...
Bridge+netfilter内容很多,下次有时间会专门用一篇文章介绍OpenStack中的安全组实现,关键字 iptables+bridge+netfilter+conntrack
Linux上还有一款虚拟交换机OVS,主要区别是OVS支持vlan tag以及流表(例如openflow)等一些高级特性,Bridge只是单纯二层交换机也不支持vlan tag,OVS具体介绍参考这里openstack底层技术-使用openvswitch
VLAN
上面简单介绍过Bridge和OVS区别,要在Linux上实现一个带VLAN功能的虚拟交换机,OVS可以通过给不同port打不同tag实现vlan功能,而Bridge需要结合VLAN设备才能实现。
这部分先介绍VLAN设备原理及配置,然后介绍VLAN在openstack中的应用
VLAN设备原理及配置
VLAN又称虚拟网络,其基本原理是在二层协议里插入额外的VLAN协议数据(称为 802.1.q VLAN Tag),同时保持和传统二层设备的兼容性。Linux里的VLAN设备是对 802.1.q 协议的一种内部软件实现,模拟现实世界中的 802.1.q 交换机。详细介绍参考文章开头给出的IBM文章中”VLAN device for 802.1.q”部分,这里不再重复
下面使用VLAN结合Bridge实现文中第一张图上的多个VLAN子设备VLAN 100, VLAN X, VLAN Y, ...以及多个网桥br0, brX, brY, ...(X Y都是小于2048的正整数)。前提是此主机上有一块网卡设备比如em2,不管em2为物理网卡或虚拟网卡,em2所连接的交换机端口必须设置为trunk。
添加VLAN子设备VLAN 100, VLAN X, VLAN Y, ...
#cat /etc/sysconfig/network-scripts/ifcfg-em2
TYPE=Ethernet
BOOTPROTO=none
IPV4_FAILURE_FATAL=no
NAME=em2
UUID=4f2cfd28-ba78-4f25-afa1-xxxxxxxxxxxxx
DEVICE=em2
ONBOOT=yes
#添加vlan子设备em2.100
#cat /etc/sysconfig/network-scripts/ifcfg-em2.100
DEVICE=em2.100
BOOTPROTO=static
ONBOOT=yes
VLAN=yes
#可以继续添加多个带不同vlan tag的子设备,比如VLAN X, VLAN Y, VLAN ...
#vlan子设备em2.X
#cat /etc/sysconfig/network-scripts/ifcfg-em2.X
#DEVICE=em2.X
#BOOTPROTO=static
#ONBOOT=yes
#VLAN=yes
#vlan子设备em2.Y
#cat /etc/sysconfig/network-scripts/ifcfg-em2.Y
#DEVICE=em2.Y
#BOOTPROTO=static
#ONBOOT=yes
#VLAN=yes
#...
#重启网络
service network restart
查看子设备em2.100,可以看到,其driver为VALN
#ethtool -i eth1.101
driver: 802.1Q VLAN Support
version: 1.8
...
添加网桥br0, brX, brY, ...
#添加br0网桥
brctl addbr br0
#br0添加em2.100子设备 凡是桥接到br0上的数据包都会带上tag 100
brctl addif br0 em2.100
#可以继续添加多个网桥brX, brY, ...
#brctl addbr brX
#凡是桥接到brX上的数据包都会带上tag X
#brctl addif brX em2.X
#brctl addbr brY
#brctl addif brY em2.Y
#...
#brctl show
bridge name bridge id STP enabled interfaces
br0 8000.525400315e23 no em2.100
tap0
VLAN设备的作用是建立一个个带不同vlan tag的子设备,它并不能建立多个可以交换转发数据的接口,因此需要借助于Bridge,把VLAN建立的子设备例如em2.100桥接到网桥例如br0上,这样凡是桥接到br0上的设备就自动加入了vlan 100子网。对比一台带有两个vlan 100,X的物理交换机,这里br0网桥上所连接的接口相当于物理交换机上那些划分到vlan 100的端口,而brX所连接的接口相当于物理交换机上那些划分到vlan X的端口。因此Bridge加VLAN能在功能层面完整模拟现实世界里的802.1.q交换机。
参考文中第一张图,我们从网桥br0上tap0接口(E)角度,来看下具体的数据收发流程:
- 数据从tap0接口进入,发往外部网络A
tap0收到的数据被发送给br0(E) --> D --> br0把数据从em2.100接口发出(C) --> 母设备em2收到em2.100发来的数据(B) --> 母设备em2给数据打上100的vlan tag(因为来自em2.100) --> em2将带有100 tag的数据发出到外部网络(A) --> em2所连接的交换机收到数据(trunk口)
- 数据从em2网卡进入,发往tap0
em2从所连接的交换机收到tag 100的数据 --> em2发现此数据带有tag 100,移除数据包中tag --> 不带tag的数据发给em2.100子设备 --> br0收到从em2.100进入的数据包 --> D --> br0转发数据到tap0
上面忽略了对于数据包是否带tag,以及数据包所带tag的子设备是否存在的检查。这些属于vlan基础知识
VLAN在openstack中的应用
openstack中虚拟机网络使用VLAN模式的话,就会用到VLAN设备。openstack中配置vlan+bridge模式如下
#neutron-server节点(网络节点)配置
#cat /etc/neutron/plugins/ml2/ml2_conf.ini
[ml2]
#neutron-server启动时,加载flat,vlan两种网络类型驱动
type_drivers = flat,vlan
#vlan模式不需要tenant_network,留空
tenant_network_types =
#neutron-server启动时加载linuxbridge和openvswitch网桥驱动
mechanism_drivers = linuxbridge,openvswitch
[ml2_type_flat]
#在命令行或控制台新建flat类型网络时需要指定的名称,此名称会配置映射到计算节点上某块网卡,下面会设置
flat_networks = proext
[ml2_type_vlan]
#在命令行或控制台新建vlan类型网络时需要指定的名称,此名称会配置映射到计算节点上某块网卡,下面会设置
network_vlan_ranges = provlan
#重启neutron-server服务
#使用Bridge+vlan网络模式的nova-compute节点(计算节点)配置
#cat /etc/neutron/plugins/ml2/linuxbridge_agent.ini
[linux_bridge]
#provlan名称映射到此计算节点eth2网卡,因为使用vlan模式,eth2需要设置为trunk
#proext名称映射到此计算节点eth3网卡,我这个环境下eth3网卡为虚拟机连接外网接口
physical_interface_mappings = provlan:eth2,proext:eth3
#重启此计算节点nova-compute服务
#配置中只需要指定vlan要用的母设备eth2,后续控制台新建带tag的网络时,neutron会自动建立eth2.{TAG}子设备并加入到网桥
在控制台新建一个vlan tag为1023的Provider network: subvlan-1023,使用此subvlan-1023网络新建几台虚拟机,看下计算节点上网桥配置
[root@compute03 neutron]# brctl show
bridge name bridge id STP enabled interfaces
brq82405415-7a 8000.52540048b1a9 no eth2.1023
tap10f15e45-aa
tapa659a214-b1
brqf5808b72-44 8000.5254001ac83d no eth3
tapd3388a60-ae
[root@compute03 neutron]# virsh domiflist instance-00000145
Interface Type Source Model MAC
-------------------------------------------------------
tapa659a214-b1 bridge brq82405415-7a virtio fa:16:3e:bc:c9:e0
虚拟机instance-00000145的网卡tapa659a214-b1桥接到brq82405415-7a。跟上面介绍的类似,桥接到brq82405415-7a上的接口设备就自动加入了vlan 1023子网,因此从instance-00000145发出的数据包会带有tag 1023(eth2.1023的母设备eth2负责添加或移除tag)
假如在控制台或命令行再新建一个tag为1024的子网,则网桥配置如下
[root@compute03 neutron]# brctl show
bridge name bridge id STP enabled interfaces
brq82405415-7a 8000.52540048b1a9 no eth2.1023
tap10f15e45-aa
tapa659a214-b1
brq7d59440b-cc 8000.525400aabbcc no eth2.1024
tap20ffafb2-1b
brqf5808b72-44 8000.5254001ac83d no eth3
tapd3388a60-ae
[root@compute03 neutron]# virsh domiflist instance-00000147
Interface Type Source Model MAC
-------------------------------------------------------
tap20ffafb2-1b bridge brq7d59440b-cc virtio fa:16:3e:bd:12:40
虚拟机instance-00000147的网卡tap20ffafb2-1b桥接到brq7d59440b-cc,instance-00000147属于vlan 1024子网,这就实现了属于不同vlan子网的instance-00000145与instance-00000147的隔离性。他们虽然在同一台计算节点上,但彼此不互通,除非设置为两个VLAN可以互通
感谢Bridge和VLAN设备,他们让openstack配置vlan网络成了可能,BUT!, Bridge+VLAN不是唯一的选择,openstack也支持OVS,OVS中是靠给不同instance接口打不同tag来实现instance的多vlan环境,OVS模式除了配置部分跟Bridge+VLAN不同之外,使用上并没有什么区别,这里的设置mechanism_drivers = linuxbridge,openvswitch加载相应驱动,屏蔽掉了底层操作的差别
与Bridge中provlan,proext映射到计算节点网卡的配置不同,OVS配置文件中映射关系为vlan类型网络provlan映射到网桥br-vlan,flat类型网络proext映射到网桥br-ext。至于br-vlan桥接eth2网卡,br-ext桥接eth3网卡则需要预先手动配置好,来看一个使用OVS的计算节点网桥
[root@compute01 neutron]# ovs-vsctl show
dd7ccaae-6a24-4d28-8577-9e5e6b5dfbd3
Manager "ptcp:6640:127.0.0.1"
is_connected: true
Bridge br-ext
Controller "tcp:127.0.0.1:6633"
is_connected: true
fail_mode: secure
Port phy-br-ext
Interface phy-br-ext
type: patch
options: {peer=int-br-ext}
Port br-ext
Interface br-ext
type: internal
Port "eth3"
Interface "eth3"
Bridge br-vlan
Controller "tcp:127.0.0.1:6633"
is_connected: true
fail_mode: secure
Port br-vlan
Interface br-vlan
type: internal
Port phy-br-vlan
Interface phy-br-vlan
type: patch
options: {peer=int-br-vlan}
Port "eth2"
Interface "eth2"
Bridge br-int
Controller "tcp:127.0.0.1:6633"
is_connected: true
fail_mode: secure
Port int-br-ext
Interface int-br-ext
type: patch
options: {peer=phy-br-ext}
Port br-int
Interface br-int
type: internal
Port int-br-vlan
Interface int-br-vlan
type: patch
options: {peer=phy-br-vlan}
Port "qvo7d59440b-cc"
tag: 1
Interface "qvo7d59440b-cc"
ovs_version: "2.5.0"
[root@compute01 neutron]# brctl show
bridge name bridge id STP enabled interfaces
qbr7d59440b-cc 8000.26d03016fcf6 no qvb7d59440b-cc
tap7d59440b-cc
#查看虚拟机网卡
[root@compute01 neutron]# virsh domiflist instance-00000149
Interface Type Source Model MAC
-------------------------------------------------------
tap7d59440b-cc bridge qbr7d59440b-cc virtio fa:16:3e:12:ba:e6
instance-00000149出数据流向为tap7d59440b-cc --> qbr7d59440b-cc --> qvo7d59440b-cc(tag 1) --> br-int --> br-vlan --> eth2。qvb7d59440b-cc 与 qvo7d59440b-cc 为一对veth设备
这其中牵涉OVS流表和OVS内外部tag转换问题,又足够写一篇文章来介绍了,本文暂不继续介绍。还有一点,在使用OVS做网桥的同时又开启安全组功能时,会多出一个Bridge网桥用于设置安全组,如上面的qbr7d59440b-cc, 因为目前iptables不支持OVS,只能在虚拟机与OVS网桥之间加进一个Bridge网桥用于设置iptables规则.
VxLan
VXLAN(Virtual Extensible LAN)虚拟可扩展局域网,是一种 overlay 网络技术,将原始2层以太帧进行UDP封装 (MAC-in-UDP),增加8字节 VXLAN头部,8字节 UDP头部, 20字节 IP 头部和14字节以太网头部,共50字节。
VXLAN与VLAN相比能够提供更好的扩展性和灵活性,主要有以下特点:
应用灵活部署: 通过VXLAN封装后的2层以太网帧可以跨3层网络边界,让组网以及应用部署变得更加灵活,同时解决多租户网络环境中IP地址冲突问题。
更好的扩展性: 传统 VLANID字段为12-bit,VLAN数量最大为4096;VXLAN使用24-bit VNID (VXLAN network identifier),最大支持 16,000,000 逻辑网络。
提高网络利用率: 传统以太网使用 STP预防环路, STP导致网络冗余路径处于阻塞状态, VXLAN报文基于 3层 IP报头传输,能有效利用网络路径,支持 ECMP(equal-cost multipath )和链路聚合协议。
(1) 应用灵活部署
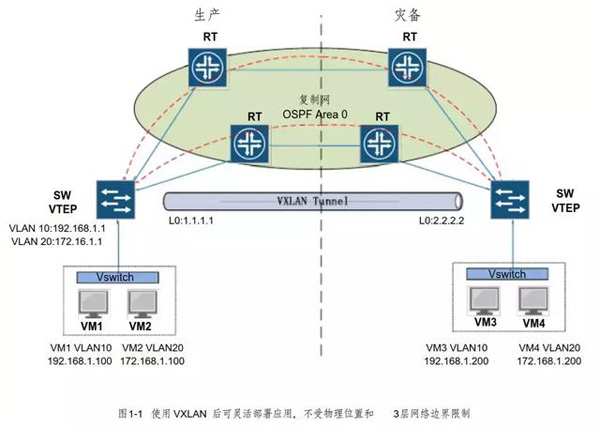
如图 1-1 所示,在 VXLAN环境中应用部署不受物理位置和3层网络边界限制,例如某应用的地址段为 192.168.1.0/24,在传统网络中所有该应用服务器或者虚拟机必须在同一 3层网络内部署,否则会产生路由或者地址冲突问题。
(2) 更好的扩展性
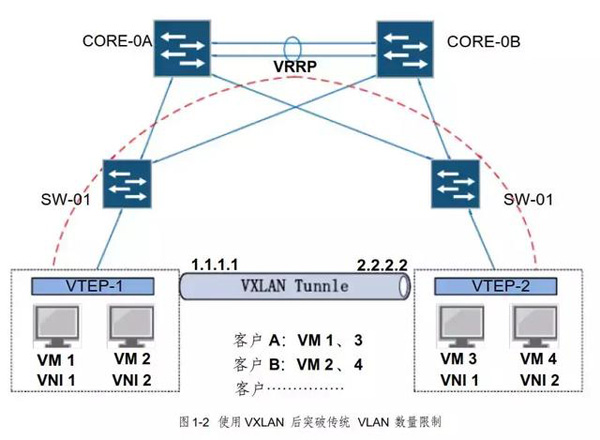
传统网络通过 VLAN将客户网络逻辑隔离, VLAN ID字段为 12-bit ,VLAN数量最大为 4096;VXLAN使用 24-bit VNID ( VXLAN network identifier ),最大支持16,000,000 逻辑网络,扩展性得到极大增强。
(3) 提高网络利用率
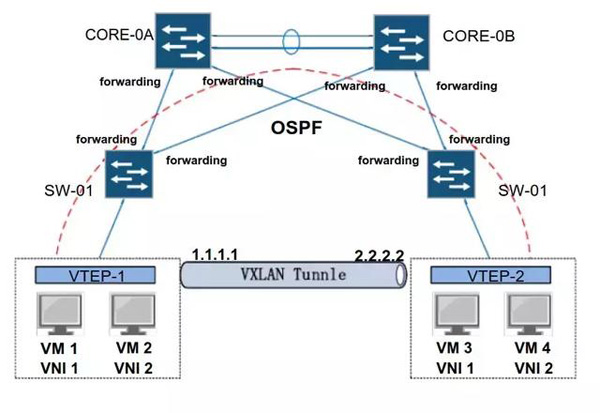
图 1-3 使用 VXLAN 后使用三层接口互联消除生成树阻塞端口
传统以太网帧无法穿越三层网络,部署 VXLAN后, VTEP之间数据基于三层寻址,网络互联接口不再是二层接口, 可以将交换机之间互联接口部署为三层模式,消除生成树阻塞端口,提高网络利用率,支持 ECMP(equal-cost multipath )和链路聚合协议。
二、VXLAN术语
1. VTEP
VXLAN Tunnel Endpoint (VTEP)。VXLAN使用VTEP设备对VXLAN报文进行封装与解封装,包括ARP请求报文和正常的VXLAN数据报文,VTEP将原始以太网帧通过VXLAN封装后发送至对端 VTEP设备,对端VTEP接收到 VXLAN报文后解封装然后根据原始 MAC进行转发,VTEP可以是物理交换机、物理服务器或者其他支持 VXLAN的硬件设备或软件来实现。
2. VNI
Virtual Network ID ( VNI), VNI封装在 VXLAN头部,共 24-bit ,最大支持16,000,000 逻辑网络。
3. VXLAN 网关
VXLAN网关用于连接 VXLAN网络和传统 VLAN网络,VXLAN网关实现 VNI和VLAN ID 之间的映射, VXLAN 网关实际上也是一台 VTEP设备。
4. 组播组
VTEP设备要加入相同的组播组,主要用于控制平面地址学习。
三、VXLAN封装
VXLAN使用 UDP封装完整的以太网帧 (MAC-in-UDP),共 50 字节的封装报文头。具体的报文格式如下:
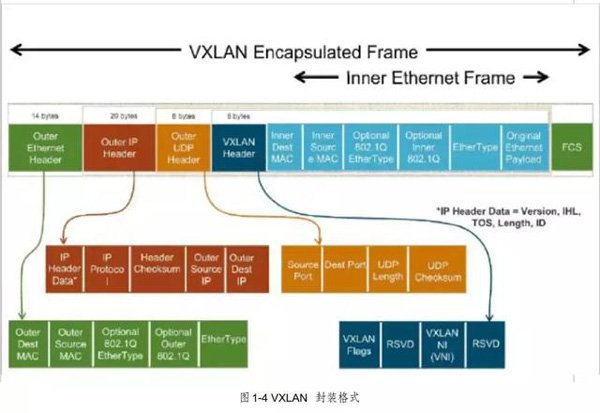
1. Inner MAC
Inner MAC,内层 MAC是原始以太网帧的 MAC地址。
2. VXLAN Header
共 8 个字节,目前使用的是 Flags 中的一个 8bit 的标识位和 24bit 的VNI(Vxlan Network identifier) ,其余部分没有定义,但是在使用的时候必须设置为 0x0000。
3. Outer UDP Header
共8个字节,IANA分配的标准目的端口使用 4798,但是各厂商可以根据需要进行修改,同时UDP的校验和必须设置成全 0。
4. Outer IP Header
共20个字节,目的IP地址可以是单播地址,也可以是多播地址。 单播情况下,目的IP地址是目的VTEP的 IP地址;当用于VXLAN控制平面时会使用多播地址。
Outer IP: 外层IP地址是经过VTEP封装后的3层IP地址,源IP是本端VTEP设备IP,用于控制平面时目的 IP 可以是多播地址,用于转发平面时目的 IP是远端 VTEP设备 IP。
5. Outer Ethernet Header
共计14个字节,外层以太网帧头部。Outer MAC,外层 MAC是经过 VTEP封装后的二层 MAC,源 MAC是本端 VTEP设备MAC,目的 MAC可以是远端 VTEP设备MAC或者传输路径中间 3 层网络设备 MAC。
四、VXLAN数据转发
1. 控制平面
在 VXLAN的实现中, 当通过组播实现控制平面路径发现时, VTEP设备之间使用无状态 tunnel ,VTEP设备之间不会维持状态化的长连接。 VXLAN需要通过控制平面学习远端设备地址信息, 在本地构建控制平面表项。 控制平面表项由 VNI、Inner Source MAC 、Outer Source IP 三元组组成。
2. 转发平面
控制平面学习地址映射信息后, 转发平面负责实际数据的转发。 VTEP为原始数据帧增加 UDP报头,新的报头到达目的 VTEP后才会被去掉,中间路径的网络设备只会根据外层包头内的目的地址进行数据转发。
3. VXLAN ARP请求
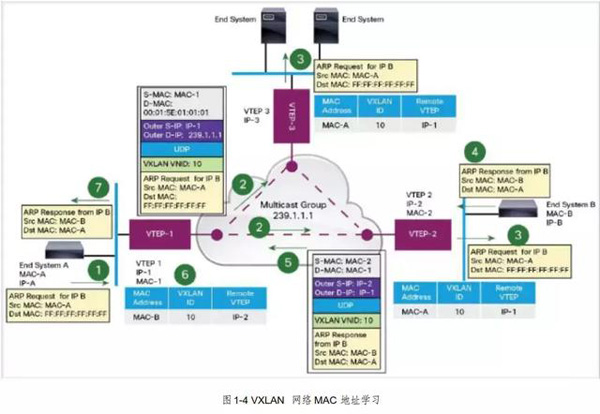
如上图所示,终端设备 A需要和终端设备 B通信, ARP请求过程如下:
终端设备 A 发送 ARP请求,请求终端设备 B 的 MAC地址;
VTEP-1收到终端设备 A发送的 ARP请求,此时 VTEP-1还没有终端设备 B对应的地址映射表项, VTEP-1将 ARP请求进行 VXLAN封装, VNI 设置为10,outer-src-ip 是 VTEP-1的 IP ,outer-dst-ip 是加入的组播组地址,封装完成后转发至 VXLAN组播组;
VTEP-2、VTEP3加入相同的组播组,所有组成员都会收到 VTEP-1发送的组播报文,解封装后检查 VNI 与本地 VNI 是否匹配,如匹配将 ARP请求发送至本地网络,同时记录 VNI、inner MAC、outer IP 的对应关系,构建控制平面地址映射表项。如 VNI 不匹配则丢弃数据包。
终端设备 B 收到 ARP请求后以单播方式发送 ARP响应;
VTEP-2收到终端设备 B 的 ARP响应后进行 VXLAN封装,此时 VTEP-2已经构建控制平面地址映射表项,通过 VXLAN封装后以单播方式发送。Outer-src-ip 是 VTEP-2的 IP 地址,outer-dst-ip 是 VTEP-1的 IP 地址;
VTEP-1收到封装后的 ARP响应后,解封装比对 VNI,如匹配将 ARP响应发送至终端设备 A,同时记录 VNI、inner MAC、 outer IP 的对应关系,构建控制平面表项;
此时 VTEP-1、VTEP-2均已成功构建控制平面地址映射信息,后续 VXLAN数据使用单播在 VTEP-1和 VTEP-2之间传输。
4. VXLAN 数据传输
ARP请求完成后,终端设备 A 向终端设备 B 发送数据, VTEP-1收到数据中查找地址映射表项,将原始数据进行 VXLAN封装后转发至 VTEP-2;
VTEP-2收到 VXLAN数据包后检查 VNI 是否与本地 VNI 匹配, 如匹配则解封装后将原始以太网帧转发至终端设备 B。
五、VXLAN部署
六、补充:
在进行 ARP处理时,为了将广播通过多播进行传输,必须要设置VNI 到多播组的映射,这种映射属于管理层,用于建立VTEP之间的管理通道。未知的目的 MAC(unknown MAC destination )同样会进行组播封装,处理方式和广播相同。
VXLAN报文不能进行分片处理,中间的设备可能会将 VXLAN报文分片,但是VTEP会将分片后的报文丢弃,为了确保 VXLAN报文不被分片处理,需要修改沿途所以设备的 MTU。RFC文档没有阐述为什么 VTEP必须丢弃分片后的报文。
在封装和解封装时 VLAN TAG信息都会被剥离,除非另有特殊配置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号