found_rows()使用
【转】https://blog.csdn.net/myweishanli/article/details/40584597
在mysql中 FOUND_ROWS()与COUNT(*)都可以统计记录,如果都一样为什么会有两个这样的函数呢,下面我来介绍SELECT FOUND_ROWS()与COUNT(*)用法区别
SELECT语句中经常可能用LIMIT限制返回行数。有时候可能想要知道如果没有LIMIT会返回多少行,但又不想再执行一次相同语句。那么,在SELECT查询中包含SQL_CALC_FOUND_ROWS选项,然后执行FOUND_ROWS()就可以了:
-
mysql> SELECT SQL_CALC_FOUND_ROWS * FROM tbl_name
-
-> WHERE id > 100 LIMIT 10;
-
mysql> SELECT FOUND_ROWS();
COUNT(*) 的稍微不同之处在于,它返回检索行的数目, 不论其是否包含 NULL值。
SELECT 从一个表中检索,而不检索其它的列,并且没有 WHERE子句时, COUNT(*)被优化到最快的返回速度。例如:
mysql> SELECT COUNT(*) FROM tablename;
这个优化仅适用于 MyISAM表, 原因是这些表类型会储存一个函数返回记录的精确数量,而且非常容易访问。对于事务型的存储引擎(InnoDB, BDB), 存储一个精确行数的问题比较多,原因是可能会发生多重事物处理, 而每个都可能会对行数产生影响。
COUNT(DISTINCT expr,[expr...])
返回不同的非NULL值数目。
若找不到匹配的项,则COUNT(DISTINCT)返回 0 。
-
-
$sql = "select count(*) from t";
-
$res = mysql_query($sql);
-
$num = mysql_result($res,0);
-
$sql = "select topic,detail from t limit 5";
-
//***以下我就不写了
-
然而用mysql自带函数found_rows();
也可以快速求出总数
-
-
-
$sql = "select sql_calc_found_rows topic,detail from t limit 5";
-
$sql = "select found_rows()";
-
$num = mysql_result($res,0);
-
这种方法使用时所要注意的问题
引用:
1 必须以select sql_calc_found_rows 开头
2 这时found_rows() 为 没有limite 时的行数
以下为一个演示 希望大家看了更加明白
-
mysql> select count(*) from zd_sort2;
-
+----------+
-
| count(*) |
-
+----------+
-
| 20 |
-
+----------+
-
1 row in set (0.14 sec)
-
-
mysql> select sql_calc_found_rows st2_id from zd_sort2 limit 3;
-
+--------+
-
| st2_id |
-
+--------+
-
| 1 |
-
| 6 |
-
| 12 |
-
+--------+
-
3 rows in set (0.00 sec)
-
-
mysql> select found_rows();
-
+--------------+
-
| found_rows() |
-
+--------------+
-
| 20 |
-
+--------------+
-
1 row in set (0.00 sec)
-
-
mysql>
----------------------------------分割线-------------------------------------
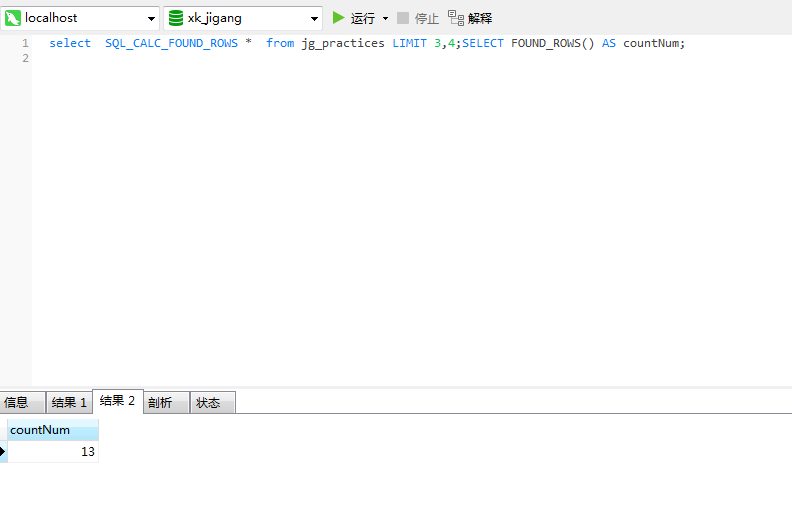
测试:
查询结果1显示查询的数据,查询结果2显示当前where 条件内的总条数