

【Node Weekly】 How we 30x'd our Node parallelism by Evan Limanto
【Node Weekly】 How we 30x'd our Node parallelism by Evan Limanto
How We 30x-ed Our Node Parallelism
安全地提高生产节点服务的并行性的最佳方法是什么?这是几个月前我的团队需要回答的问题。
我们为我们的银行集成服务运行4000个节点容器(或“工人”)。该服务最初的设计使每个工作人员一次只能处理一个请求。这种设计减少了意外阻塞事件循环的集成的影响,并允许我们忽略不同集成中资源使用的可变性。但是,由于我们的总容量被限制在4000个并发请求,所以系统没有适当地扩展。大多数请求都是网络绑定的,所以如果我们能找出如何安全地提高并行性,就可以提高我们的容量和成本。
在我们的研究中,我们找不到一个好的剧本来描述节点服务从“无并行”到“大量并行”。因此,我们制定了自己的计划,它依赖于仔细的计划、良好的工具和可观察性,以及健康的调试。最终,我们能够将并行度提高30倍,这相当于每年节省约30万美元的成本。这篇文章将概述我们如何提高节点工作人员的性能和效率,并描述我们在这个过程中吸取的教训。
为什么我们投资并行
如果我们不使用并行性就走到了这一步,这可能会让人惊讶——我们是如何做到的?只有10%的Plaid的数据拉涉及到一个用户谁在场,并将他们的帐户链接到一个应用程序。其余的是在用户不在场的情况下进行的定期事务更新。通过在负载平衡层中添加逻辑,将用户当前请求优先于事务更新,我们可以以牺牲事务新鲜度为代价处理1000%或更多的API峰值。
虽然这种权宜之计已经奏效了很长时间,但我们知道,有几个痛点最终会影响我们的服务可靠性:
1. 来自我们客户的API请求峰值越来越大,我们担心一个协调的流量峰值会耗尽我们的工作人员的能力。
2. 银行请求的延迟峰值同样导致我们的工作人员容量下降。由于银行基础设施的可变性,我们对出站请求设置了保守的超时,完整的数据拉取可能需要几分钟。如果一家大型银行的延迟时间猛增,就会有越来越多的员工被困在等待回应。
3. ECS的部署时间变得非常缓慢,即使我们提高了部署速度,我们也不想进一步增加集群的大小。
我们认为提高并行性是消除应用程序瓶颈和提高服务可靠性的最佳方法。作为副作用,我们相信我们可以降低基础设施成本,实施更好的可观测性和监测,这两项措施都将在未来带来回报。
我们如何可靠地推出更改
工具和可观测性
我们有一个自定义的负载平衡器,它将请求路由到我们的节点工作器。每个节点工作机运行一个gRPC服务器来处理请求,并使用Redis将其可用性通告回负载平衡器。这意味着添加并行性就像更改几行逻辑一样简单:工人应该继续公布可用性,直到处理N个正在运行的请求(每个请求都有自己的承诺),而不是在接到任务后立即报告不可用。
不过,事情没那么简单。我们的首要目标是在任何一次发布中保持可靠性,我们不能仅仅增加并行性。我们预计这次发布将特别危险:它将以难以预测的方式影响我们的CPU使用率、内存使用率和任务延迟。由于Node的V8运行时在事件循环上处理任务,我们主要关心的是,我们可能在事件循环上做了太多的工作,从而降低了吞吐量。
为了降低这些风险,我们确保在第一个并行工作人员部署到生产环境之前,已经准备好了以下工具和可观察性:
1. 我们现有的麋鹿堆栈有足够的现有日志进行特别的调查。
2. 我们添加了一些普罗米修斯指标,包括:
- 使用process.memoryUsage()的V8堆大小
- 使用gc stats包的垃圾收集统计信息
- Task latency statistics任务延迟统计信息,按银行集成类型和并行级别分组,以可靠地测量并行性如何影响我们的吞吐量。
3. 我们创建了Grafana仪表板来测量并行性的效果。
4. 更改应用程序行为而不必重新部署我们的服务是非常关键的,因此我们创建了一组启动功能标志来控制各种参数。以这种方式调整每个工作人员的最大并行度,最终使我们能够快速迭代并找到最佳并行度值——在一分钟内。
5. 为了了解应用程序各个部分的CPU时间分布,我们在生产服务中构建了flamegraphs。
- 我们使用了0x包,因为节点检测很容易集成到我们的服务中,生成的HTML可视化是可搜索的,并且提供了很好的详细程度。
- 我们添加了一个分析模式,其中一个工作人员将开始启用0x,并将产生的痕迹写入S3退出。然后,我们可以从S3下载这些日志,并在本地使用x查看它们—仅可视化。/flamegraph
- 我们一次只运行一个工人的配置文件。CPU分析提高了资源利用率并降低了性能,我们希望将此影响隔离到单个工作进程。
启动卷展栏
在这项初步工作完成之后,我们为我们的“并行工作者”创建了一个新的ECS集群。这些是使用SunCurkLy特征标志来动态设置它们的最大并行性的工作者。
我们的推出计划包括逐渐将越来越多的流量从旧集群路由到新集群,同时密切监视新集群的性能。在每个通信量级别上,我们将调整每个工作机上的并行性,直到它尽可能高,而不会导致任务延迟或其他指标的任何降级。如果我们发现问题,我们可以在几秒钟内动态地将流量路由回旧集群。
正如所料,在这一过程中出现了一些挑战。我们需要调查和解决这些棘手的问题,以便有意义地提高我们的并行性。这才是真正有趣的开始!
部署,调查,重复
增加节点的最大堆大小
当我们开始推出过程时,我们开始得到警告,我们的任务已经退出了一个非零代码-一个吉祥的开始。我们深入基巴纳发现了相关的log (associated log):
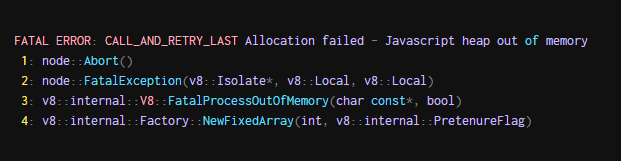
这让我们想起了过去我们经历过的内存泄漏,其中V8在吐出类似的错误信息后会意外地退出。它有很多意义:更大的任务并行性导致更高的内存使用率。
我们假设从默认1.7GB增加节点最大堆大小可能会有所帮助。为了解决这个问题,我们开始运行最大堆大小设置为6GB(--max old space size=6144命令行标志)的节点,这是一个任意较高的值,仍然适合我们的EC2实例。令我们高兴的是,这修复了生产中的“分配失败”消息。
识别内存瓶颈
随着内存分配问题的解决,我们开始看到并行工作机上的任务吞吐量很低。我们仪表盘上的一张图表立刻就很显眼。这是并行工作进程的每个进程堆使用情况:
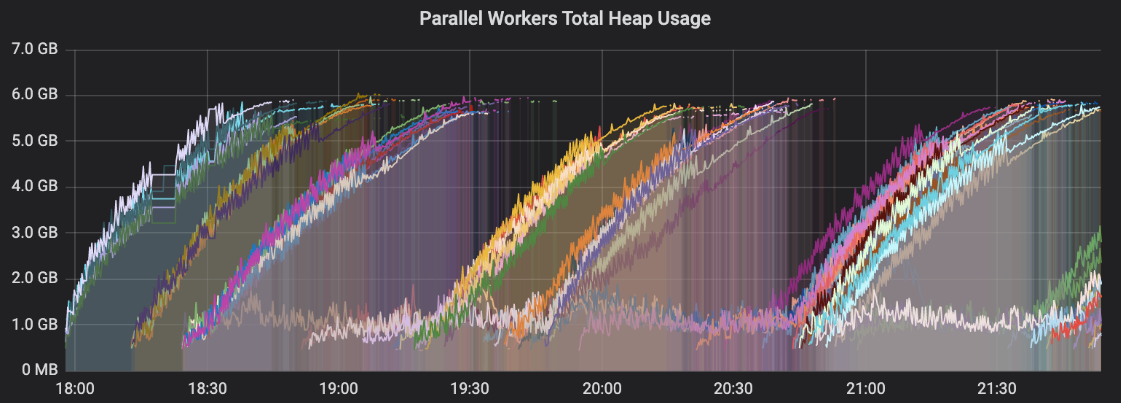
其中一些线不断增长直到它们达到最大堆尺寸-坏消息!
我们在Prometheus中使用了系统度量来排除文件描述符或网络套接字泄漏是根本原因。我们最好的猜测是,GC在旧对象上发生的频率不够,导致工作进程在处理更多任务时积累更多分配的对象。我们假设这会降低我们的吞吐量,如下所示:
- 工人接收新任务并执行某些工作
- 在执行任务时,一些对象被分配到堆上
- 由于(尚未确定)激发和忘记操作未完成,在任务完成后将维护对象引用
- 垃圾收集变得更慢,因为V8需要扫描堆上的更多对象
- 由于V8实现了一个stop-the-world GC,新任务不可避免地将获得更少的CPU时间,从而降低工作线程的吞吐量
我们搜索了我们的代码 for fire-and-forget operations,也被称为“浮动承诺”。这很简单:我们只是在代码行中寻找禁用了无浮动承诺linter规则的代码行。有一种方法特别吸引了我们的注意。它生成了一个叫compressandploaddingpayload的调用,不用等待结果。这个调用似乎很容易在任务完成后很长时间内继续运行。
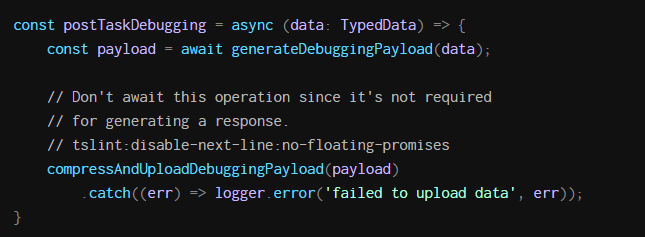
我们想验证我们的假设,即这些浮动承诺(floating promises)是瓶颈的主要来源。假设我们跳过了这些对系统正确性并不重要的调用,那么任务延迟会得到改善吗?以下是临时删除对postTaskDebugging的调用后堆的使用情况
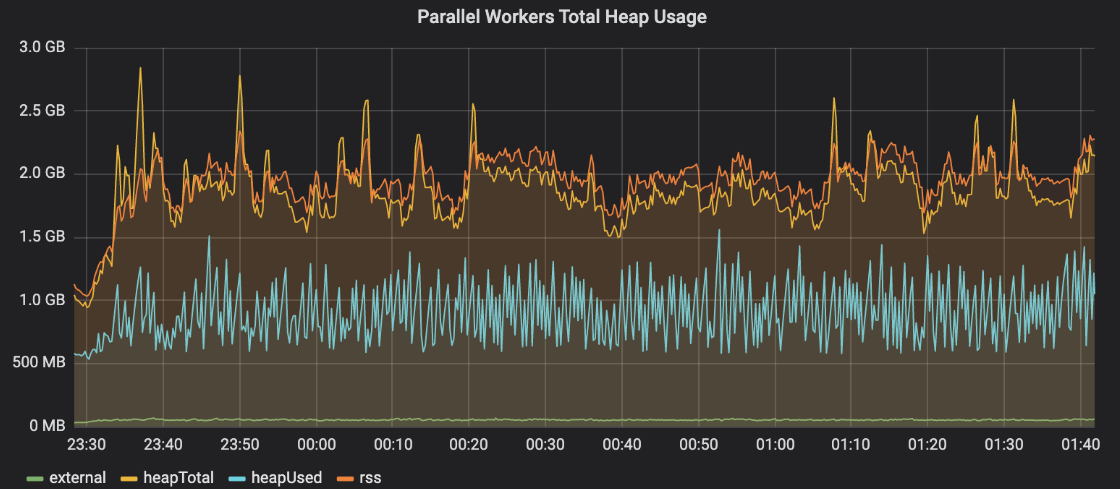
答对 了!我们的并行工作线程上的堆使用现在在很长一段时间内保持稳定。
似乎有一个compressandploaddingpayload调用的“backlog”,随着相关任务的完成,这个调用会慢慢建立起来。如果一个worker接收任务的速度超过了它修剪这个backlog的速度,那么在内存中分配的任何对象都将永远不会被垃圾收集,从而导致我们在前面的图中观察到的堆饱和。
我们开始怀疑是什么让这些浮动的承诺如此缓慢。我们不愿意从代码中永久删除compressandploaddingpayload,因为这对于帮助工程师调试本地机器上的生产任务至关重要。从技术上讲,我们可以在完成任务之前等待此调用,从而消除浮动承诺,从而解决问题。然而,这会给我们正在处理的每个任务增加一个非常重要的延迟量。
保留这个潜在的解决方案作为备份计划,我们决定研究代码优化。我们怎么能加快行动?
修复S3瓶颈
compressandploaddingpayload中的逻辑很容易理解。我们压缩调试数据,因为它包含网络流量,所以可能会非常大。然后我们将压缩数据上传到S3。
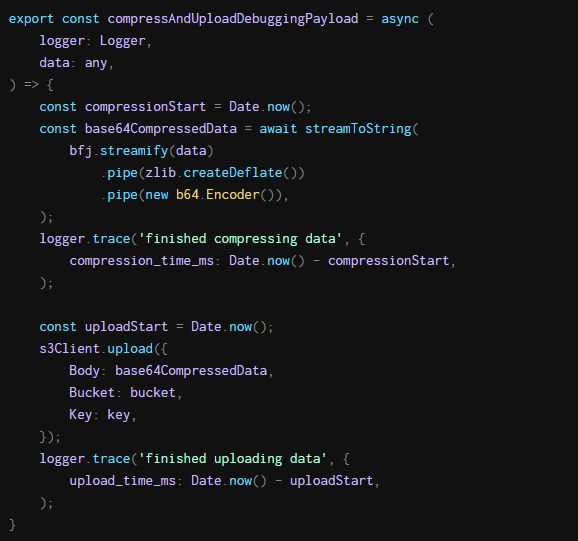
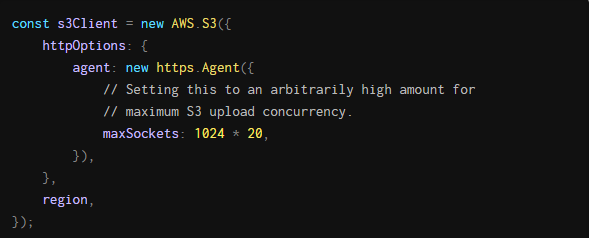
不认为套接字是瓶颈,因为Node的默认HTTPS代理将maxSockets设置为无穷大。然而,我们最终在AWS节点文档中发现了一些令人惊讶的东西:S3客户端将maxSockets从无穷大减少到了50。不用说,这不是最直观的行为。
由于我们已经让我们的工人完成了50个并发任务,上传步骤在等待S3的套接字时遇到了瓶颈。通过对S3客户端初始化的以下更改,我们改进了上载延迟:
加快JSON序列化
我们的S3改进减缓了堆大小的增加,但并没有完全解决问题。另一个明显的罪魁祸首是:根据我们的计时指标,前面代码中的压缩步骤有时会长达4分钟。这比每个任务平均4秒的延迟要长得多。不相信这一步会花这么长时间,我们决定运行本地基准测试并优化这段代码。
压缩包括三个步骤(使用节点流限制内存使用):JSON字符串化、zlib压缩和base64编码。我们怀疑我们使用的第三方字符串库——bfj——可能是问题所在。我们编写了一个脚本,在各种基于流的字符串库上执行一些基准测试(请参见此处的代码)。结果发现,这个包的名字是大友好JSON,它毕竟不是很友好。看看我们从实验中得到的两个结果:

结果令人吃惊。即使是最小的测试,bfj也比另一个包JSONStream慢5倍左右。我们很快用JSONStream替换了bfj,并立即观察到性能的显著提高。
减少垃圾收集时间
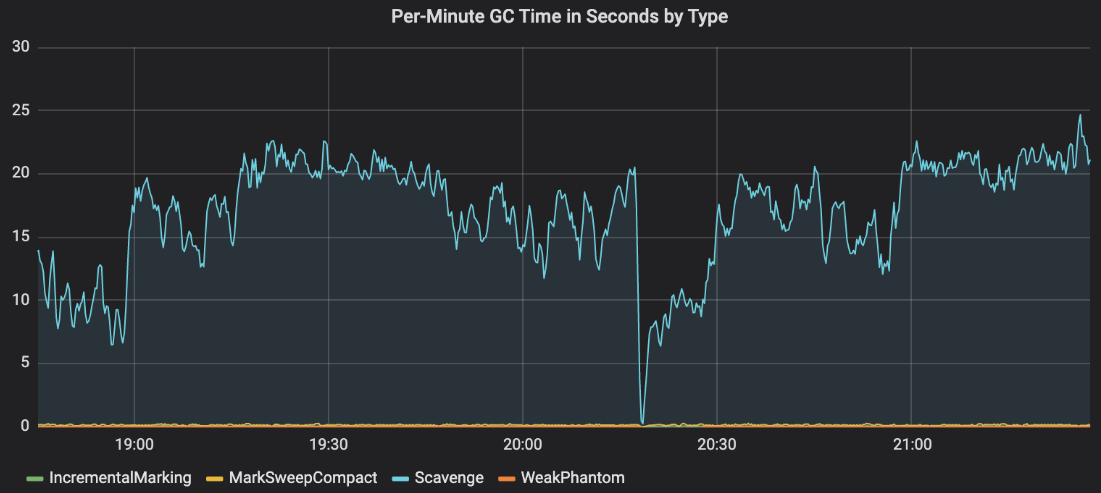
随着我们的记忆问题的解决,我们开始关注在相同类型的银行集成中,并行工作人员和单个工作人员之间的任务延迟比率。这是一个苹果对苹果的比较,我们的平行工人是如何表现的,所以一个接近1的比率给了我们信心,进一步推出交通的平行工人。在这一点上,我们的Grafana仪表盘是这样的:

注意,有些比率高达8:1,即使是在相当低的平均并行度下(此时大约为30)。我们知道,我们的银行集成没有执行CPU密集型工作,我们的容器也没有受到任何其他瓶颈的限制,我们可以想到。由于没有更多的线索,我们寻找在线资源来优化节点的性能。尽管这类文章很少,但我们偶然发现这篇博客文章详细介绍了作者如何在一个节点进程上达到60万个并发websocket连接。
尤其是--nouse idle通知的特殊用法引起了我们的注意。我们的节点进程是否花费了太多时间来执行GC?方便的是,gc stats包让我们可以看到垃圾收集的平均时间:
讨论Node中不同类型GC的技术细节,但这是一个很好的参考资料。实质上,清理经常运行,以清理堆中节点“新空间”区域中的小对象。
因此,垃圾收集在我们的节点进程上运行得太频繁了。我们可以禁用V8垃圾收集并自己运行它吗?有没有办法减少垃圾收集的频率?原来前者是不可能的,但后者是!我们可以通过在节点中突破“半空间”的限制来增加新空间的大小(--max semi space size=1024命令行标志)。这允许在V8运行清理之前分配更多的短期对象,从而减少GC的频率:
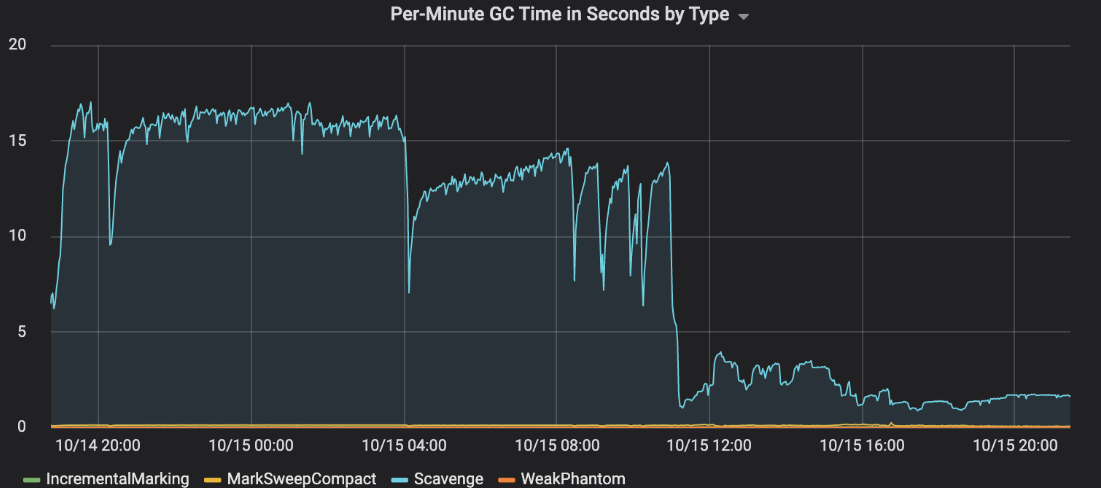
又一次胜利!增加新的空间大小导致垃圾回收时间急剧下降,从30%下降到2%。
优化CPU使用
经过这些工作,我们对结果感到满意。在并行工作机上运行的任务的延迟几乎与在大约20个并行工作机上运行的任务的延迟相等。在我们看来,我们已经解决了所有的瓶颈问题,但我们仍然不完全知道生产中的哪些操作实际上在减缓我们的速度。由于我们没有悬而未决的成果,我们决定调查分析我们工人的CPU使用情况。
我们在一个并行工作器上生成了一个flamegraph,瞧,我们得到了一个整洁的交互式viz,我们可以在本地使用它。花边新闻:它占用磁盘60MB!下面是我们在x火焰图中搜索“logger”时看到的:
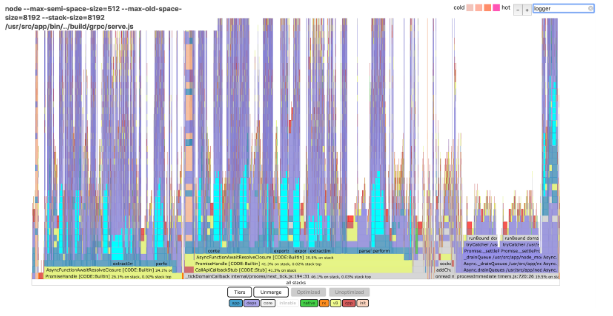
teal突出显示的条表示至少15%的CPU时间用于生成工作日志。我们最终将这一时间减少了75%——尽管我们是如何做到的,这是一个值得再发表一篇博文的话题。(提示:它涉及正则表达式和大量属性枚举。)
在这最后一点优化之后,我们能够支持每个工人最多30个并行任务,而不会影响任务延迟!
成果和教训
迁移到并行工作器使我们每年的EC2实例开销减少了大约30万美元,并大大简化了我们的体系结构。我们现在在生产中运行的容器减少了大约30倍,而且我们的系统对于来自客户的外部请求延迟或API流量峰值的增加更加健壮。
我们在并行化银行集成服务时学到了很多:
1. 永远不要低估系统低层次度量的重要性。在发布过程中能够监控GC和内存统计是非常重要的。
2. Flamegraphs火焰图太棒了!现在我们已经检测了它们,我们可以轻松诊断系统中的其他性能瓶颈。
3. 理解节点运行时使我们能够编写更好的应用程序代码。例如,了解V8对象分配和垃圾收集模型是尽可能重用对象的一个动机。有时需要直接与V8交互或使用节点命令行标志来开发一个强大的心智模型。
4. 确保阅读系统每一层的文档!我们信任maxSockets上的节点文档,但在我们发现AWS包重写了默认节点行为之前,我们花了很多时间研究。每一个基础设施项目似乎都有这样一个“抓住”的时刻。
我们希望这篇博客文章为优化节点并行性和安全地推出基础设施迁移提供了一些有用的策略。如果你对这类具有挑战性的工程项目感兴趣,我们将招聘!

